NLP(二十) 利用词向量实现高维词在二维空间的可视化
原文链接:http://www.one2know.cn/nlp20/
- 准备
Alice in Wonderland数据集可用于单词抽取,结合稠密网络可实现其单词的可视化,这与编码器-解码器架构类似。 - 代码
from __future__ import print_function
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
import matplotlib.pyplot as plt
import nltk
import numpy as np
import pandas as pd
import random
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
import string
from nltk import pos_tag
from nltk.stem import PorterStemmer
def preprocessing(text):
text2 = " ".join("".join([" " if ch in string.punctuation else ch for ch in text]).split())
tokens = [word for sent in nltk.sent_tokenize(text2) for word in nltk.word_tokenize(sent)]
tokens = [word.lower() for word in tokens]
stopwds = stopwords.words('english')
tokens = [token for token in tokens if token not in stopwds]
tokens = [word for word in tokens if len(word)>=3]
stemmer = PorterStemmer()
tokens = [stemmer.stem(word) for word in tokens]
tagged_corpus = pos_tag(tokens)
Noun_tags = ['NN','NNP','NNPS','NNS']
Verb_tags = ['VB','VBD','VBG','VBN','VBP','VBZ']
lemmatizer = WordNetLemmatizer()
def prat_lemmatize(token,tag):
if tag in Noun_tags:
return lemmatizer.lemmatize(token,'n')
elif tag in Verb_tags:
return lemmatizer.lemmatize(token,'v')
else:
return lemmatizer.lemmatize(token,'n')
pre_proc_text = " ".join([prat_lemmatize(token,tag) for token,tag in tagged_corpus])
return pre_proc_text
lines = []
fin = open("alice_in_wonderland.txt", "r") # fin = open("alice_in_wonderland.txt", "rb")
for line in fin:
# line = line.strip().decode("ascii", "ignore").encode("utf-8")
if len(line) == 0:
continue
lines.append(preprocessing(line))
fin.close()
import collections
counter = collections.Counter()
for line in lines:
for word in nltk.word_tokenize(line):
counter[word.lower()]+=1
word2idx = {w:(i+1) for i,(w,_) in enumerate(counter.most_common())}
idx2word = {v:k for k,v in word2idx.items()}
xs = []
ys = []
for line in lines:
embedding = [word2idx[w.lower()] for w in nltk.word_tokenize(line)]
triples = list(nltk.trigrams(embedding))
w_lefts = [x[0] for x in triples]
w_centers = [x[1] for x in triples]
w_rights = [x[2] for x in triples]
xs.extend(w_centers)
ys.extend(w_lefts)
xs.extend(w_centers)
ys.extend(w_rights)
print (len(word2idx))
vocab_size = len(word2idx)+1
ohe = OneHotEncoder(n_values=vocab_size)
X = ohe.fit_transform(np.array(xs).reshape(-1, 1)).todense()
Y = ohe.fit_transform(np.array(ys).reshape(-1, 1)).todense()
Xtrain, Xtest, Ytrain, Ytest,xstr,xsts = train_test_split(X, Y,xs, test_size=0.3,random_state=42)
print(Xtrain.shape, Xtest.shape, Ytrain.shape, Ytest.shape)
from keras.layers import Input,Dense,Dropout
from keras.models import Model
np.random.seed(1)
BATCH_SIZE = 128
NUM_EPOCHS = 1
input_layer = Input(shape = (Xtrain.shape[1],),name="input")
first_layer = Dense(300,activation='relu',name = "first")(input_layer)
first_dropout = Dropout(0.5,name="firstdout")(first_layer)
second_layer = Dense(2,activation='relu',name="second")(first_dropout)
third_layer = Dense(300,activation='relu',name="third")(second_layer)
third_dropout = Dropout(0.5,name="thirdout")(third_layer)
fourth_layer = Dense(Ytrain.shape[1],activation='softmax',name = "fourth")(third_dropout)
history = Model(input_layer,fourth_layer)
history.compile(optimizer = "rmsprop",loss="categorical_crossentropy",metrics=["accuracy"])
history.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE,epochs=NUM_EPOCHS, verbose=1,validation_split = 0.2)
# Extracting Encoder section of the Model for prediction of latent variables
encoder = Model(history.input,history.get_layer("second").output)
# Predicting latent variables with extracted Encoder model
reduced_X = encoder.predict(Xtest)
final_pdframe = pd.DataFrame(reduced_X)
final_pdframe.columns = ["xaxis","yaxis"]
final_pdframe["word_indx"] = xsts
final_pdframe["word"] = final_pdframe["word_indx"].map(idx2word)
rows = random.sample(list(final_pdframe.index), 100)
vis_df = final_pdframe.loc[rows]
labels = list(vis_df["word"])
xvals = list(vis_df["xaxis"])
yvals = list(vis_df["yaxis"])
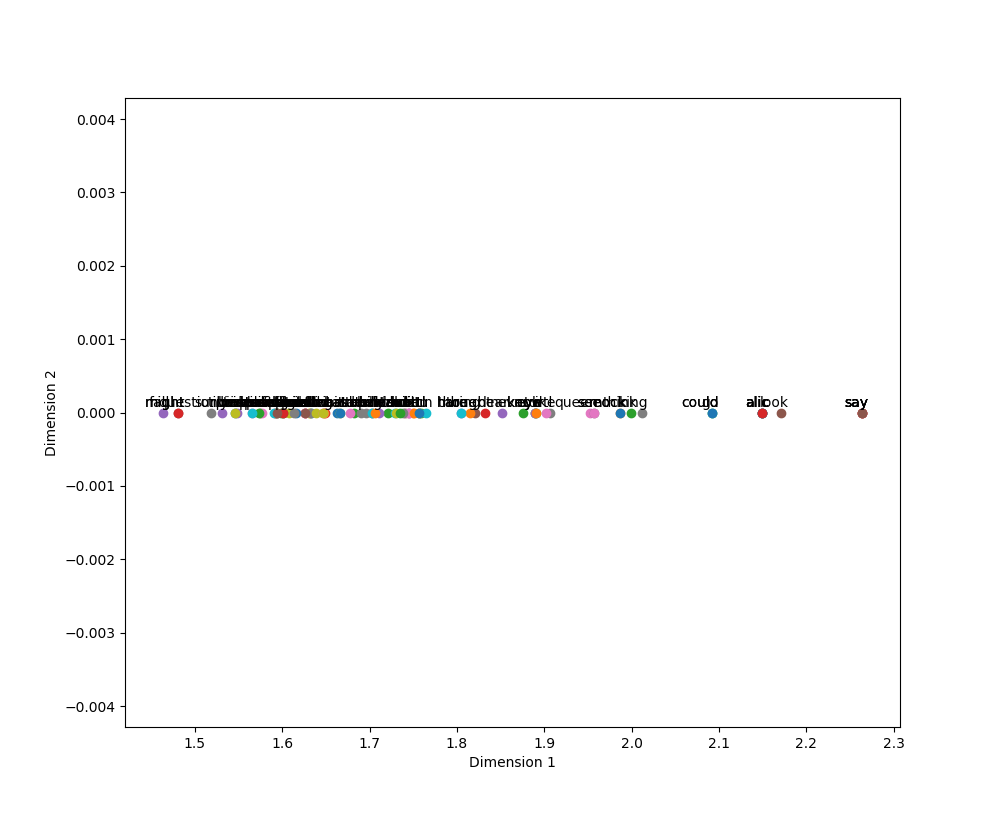
plt.figure(figsize=(10, 10))
for i, label in enumerate(labels):
x = xvals[i]
y = yvals[i]
plt.scatter(x, y)
plt.annotate(label,xy=(x, y),xytext=(5, 2),textcoords='offset points',ha='right',va='bottom')
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()
输出:不是二维的,为什么!!!看了两天不明白!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号