彭思雨20190919-3效能分析
此作业参加:https://edu.cnblogs.com/campus/nenu/2019fall/homework/7628
• 要求0 以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数
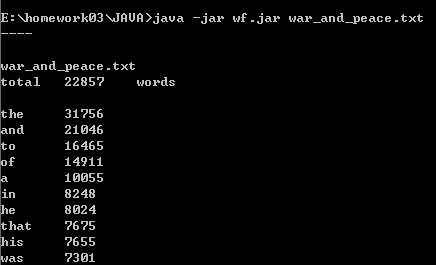
第一次运行:
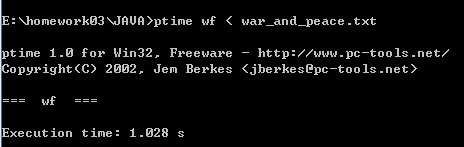
第二次运行:
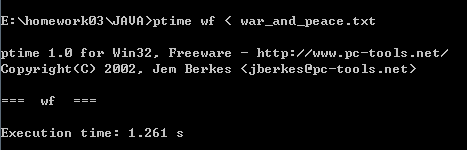
第三次运行:

CPU参数:Intel(R) Core(TM) i5-4300U CPU @ 1.90GHz 2.50 GHz
第三次运行时间:1.028s
第三次运行时间:1.261s
第三次运行时间:1.245s
平均运行时间:1.178s
• 要求1 给出你猜测程序的瓶颈。
功能3在进行文件批量统计的时候,首先是遍历文件夹下的文件,然后再分别对每一个文件进行词频统计,针对单个文件词频统计时也比较耗费时间,因为要将所有标点符号替换为空格,然后再将空格删掉,再对重复出现的单词进行计数统计,还要给出不重复单词的总的个数,并且还需要对计算出来的单词的个数进行降序排序。由此可分析,该程序在遍历文件夹和对文件夹中单个文件进行词频统计并排序比较浪费时间,我猜测是该程序的瓶颈。
代码如下:
1 //对map集合value进行排序。 2 public static <K, V extends Comparable<? super V>> Map<K, V> sortByValue(Map<K, V> map, boolean isDesc) { 3 Map<K, V> result = Maps.newLinkedHashMap(); 4 if (isDesc) {//降序 5 map.entrySet().stream().sorted(Map.Entry.<K, V>comparingByValue().reversed()) 6 .forEach(e -> result.put(e.getKey(), e.getValue())); 7 } else { 8 map.entrySet().stream().sorted(Map.Entry.<K, V>comparingByValue()) 9 .forEachOrdered(e -> result.put(e.getKey(), e.getValue())); 10 } 11 return result; 12 }
1 List<Map.Entry<String, Long>> list = new ArrayList<Map.Entry<String,Long>>((Collection<? extends Entry<String, Long>>) map.entrySet()); 2 int num = 0; 3 // 排序 4 Collections.sort(list,valueComparator); 5 for(Entry<String, Long> a : list) { 6 System.out.println(a.getKey()+"\t"+a.getValue()); 7 ++num; 8 if(num==15){ 9 break; 10 } 11 } 12 System.out.println("\n"); 13 }
• 要求2 通过 profile 找出程序的瓶颈。
多次尝试用JProfiler进行效能分析,但出来的却是如下画面:

经过多次找问题,多次尝试都没有出现要求的结果。又选择用Java自带的visuaiVM,在Eclipse中运行wf.java程序后,在java visualVM中显示出我刚才运行的demo.wf,但是CPU不支持,进行上网查询问题解决办法,未果。因此,要求2、3、4未能实现。

• 要求3 根据瓶颈,"尽力而为"地优化程序性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号