彭思雨20190912-3词频统计
作业要求 20180912-3 词频统计
该作业的要求参见:https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583
代码地址:https://e.coding.net/xintongxue123/cipin.githttps://e.coding.net/xintongxue123/cipin.githttps://e.coding.net/xintongxue123/cipin.git
一、程序完成
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
希望实现以下效果。以下效果中数字纯属编造。
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
为了评估老五的词汇量而不是阅读量,total一项中相同的单词不重复计数数,出现2
次的very计数1次。
因为用过控制台和命令行,你早就知道,上面的">"叫做命令提示符,是操作系统的一部分,而不是你的程序的一部分。
此功能完成后你的经验值+10.
重点难点:这个功能相对简单,主要是要考虑小文件中存在的英文标点符号,我做的是遇到标点符号就替换为空格,然后以空格进行分割,读取文件内容,不区分大小写,单词相同时,count+1。
代码展示:
1 System.out.println("是一个文件\n"); 2 try{ 3 BufferedReader reader = new BufferedReader(new FileReader(file));//文件存放位置 4 //reader.readLine(); 5 String line = null; 6 while ((line = reader.readLine()) != null) { //按行读取,每一行为一个字符串 7 String a = line.replace(".", " "); //遍历文本,将文本中的标点符号用空格替代 8 String b = a.replace(",", " "); 9 String c = b.replace("!", " "); 10 String d = c.replace("?", " "); 11 String e =d.replace(";", " "); 12 String f =e.replace("$", " "); 13 String g =f.replace("*", " "); 14 String h =g.replace("#", " "); 15 String l =h.replace("&", " "); 16 String k =l.replace("\"", " "); 17 String m =k.replace("\'", " "); 18 String[] arr = m.split(" "); 19 for (int i =0;i<arr.length;i++){ //判断map中是否包含这个单词,没有就添加(单词,1)否则就value+1 20 if(!map.containsKey(arr[i])){ 21 map.put(arr[i],1L); 22 }else { 23 Long x = map.get(arr[i]); 24 map.put(arr[i],++x); 25 } 26 } 27
运行截图:
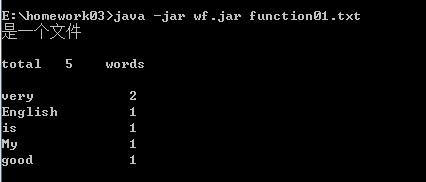
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
此功能完成后你的经验值+30. 输入文件最大不超过40MB. 如果你的程序中途崩
了,会被老五打脸,不增加经验值。
重点难点:统计一本书中的每个单词出现的次数,单词量比较多,我认为比较困难,我是把要读取的文件全部放到指定E盘文件中,重点还是要区分标点符号(我标点符号这块代码没有考虑完全,只是常见的列出并替代),这个功能我做的和功能3十分相似,可以一起读好几个文件,只是功能3我将合并读的文件放入文件夹了。
关键代码:
1 //外部传参,传入几个读取几个 2 File file = new File("E:\\homework03\\"+args[j]); 3 if(file.isDirectory()){ 4 File[] list = file.listFiles(); 5 for(File fi : list){ 6 try{ 7 int q = fi.toString().lastIndexOf("\\"); 8 String split = fi.toString().substring(q+1); 9 System.out.println(split); 10 BufferedReader reader = new BufferedReader(new FileReader(fi));//文件存放位置 11 String line = null; 12 while ((line = reader.readLine()) != null) { //按行读取,每一行为一个字符串 13 String a = line.replace(".", " "); //遍历文本,将文本中的标点符号用空格替代 14 String b = a.replace(",", " "); 15 String c = b.replace("!", " "); 16 String d = c.replace("?", " "); 17 String e =d.replace(";", " "); 18 String n =e.replace("$", " "); 19 String g =n.replace("*", " "); 20 String h =g.replace("#", " "); 21 String l =h.replace("&", " "); 22 String k =l.replace("\"", " "); 23 String m =k.replace("\'", " "); 24 String[] arr = m.split(" "); 25 for (int i =0;i<arr.length;i++){ //判断map中是否包含这个单词,没有就添加(单词,1)否则就value+1 26 27 if(!map.containsKey(arr[i])){ 28 map.put(arr[i],1L); 29 }else { 30 Long x = map.get(arr[i]); 31 map.put(arr[i],++x); 32 } 33 } 34
运行截图:
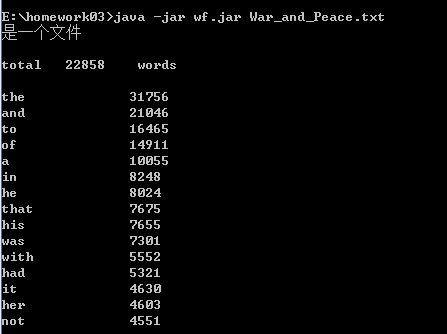
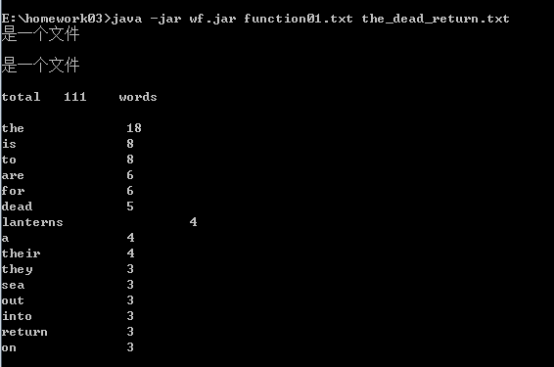
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
重点难点:做批量处理,就是不用在控制台中输入某一个具体的英文作品名,只通过文件路径,就能遍历到文件夹中所含的所有英文作品,然后排序汇总。
在功能2的基础上多一个判断和遍历文件夹。
关键代码:
1 if(file.isDirectory()){ 2 File[] list = file.listFiles(); 3 for(File fi : list){ 4 try{ 5 int q = fi.toString().lastIndexOf("\\"); 6 String split = fi.toString().substring(q+1); 7 System.out.println(split); 8 }
运行截图:
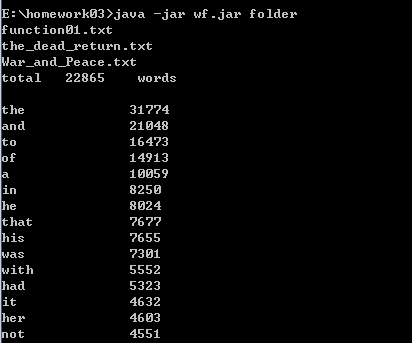
因为单词量巨大,只列出出现次数最多的10个单词。
此功能完成后你的经验值+8.
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
重点难点:理解重定向的含义。
运行截图:

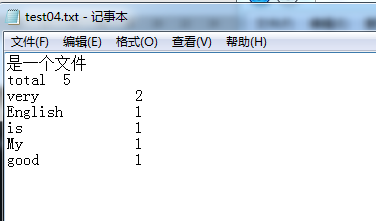
排序:
代码:
//对map集合value进行排序。 public static <K, V extends Comparable<? super V>> Map<K, V> sortByValue(Map<K, V> map, boolean isDesc) { Map<K, V> result = Maps.newLinkedHashMap(); if (isDesc) {//降序 map.entrySet().stream().sorted(Map.Entry.<K, V>comparingByValue().reversed()) .forEach(e -> result.put(e.getKey(), e.getValue())); } else { map.entrySet().stream().sorted(Map.Entry.<K, V>comparingByValue()) .forEachOrdered(e -> result.put(e.getKey(), e.getValue())); } return result; }
二、 PSP阶段表格
|
类别 |
预计花费时间min |
实际花费时间min |
时间差min |
|
功能1 |
100 |
66 |
34 |
|
功能2 |
100 |
98 |
2 |
|
功能3 |
100 |
129 |
29 |
|
功能4 |
100 |
37 |
63 |
|
测试 |
15 |
22 |
7 |
原因分析:对java语言没有完全掌握,遗漏的知识点很多。而且刚开始是每个功能模块分开写的,后来做到功能3,发现代码与功能2的交集很多,就合并了,合并时候出现一些问题,中间也有很长时间的间隔,也就导致整体用时拉长,总之还是没有做好充分的需求分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号