
翻译自:https://webaudioapi.com/book/Web_Audio_API_Boris_Smus_html/ch03.html
一旦我们准备好播放一个声音,无论是从AudioBuffer还是从其他来源,我们可以改变的一个最基本的参数就是声音的响度。
影响声音响度的主要方法是使用GainNodes。如前所述,这些节点有一个增益参数,作为传入声音缓冲区的乘数。默认的增益值是1,这意味着输入的声音不受影响。0到1之间的值会降低响度,而大于1的值会放大响度。负的增益(值小于0)会颠倒波形(即振幅被翻转)。
音量、增益和响度
让我们从一些定义开始。响度是对我们的耳朵感知声音的强烈程度的主观衡量。音量是对声波的物理振幅的测量。增益是指在处理声音时,影响其振幅的一个比例乘数。
换句话说,当经历了一个增益,声波的振幅被缩放,增益值被用作一个乘数。例如,虽然增益值为1不会影响声波,但图3-1说明了如果你将声波送入一个2的增益系数,会发生什么。
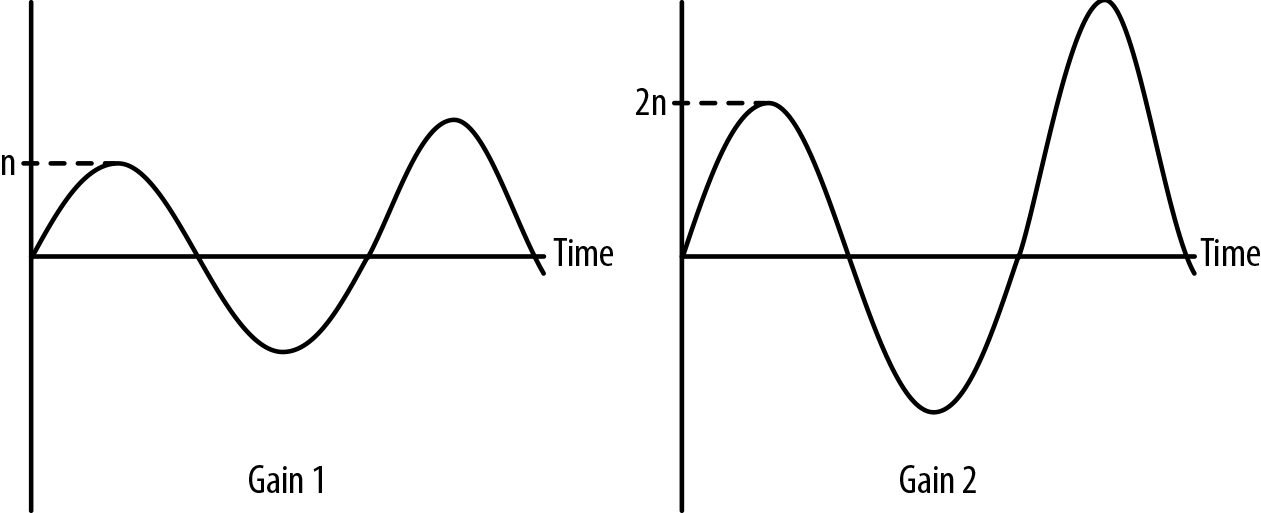
Figure 3-1. Original soundform on the left, gain 2 soundform on the right
一般来说,波的功率是以分贝(缩写为dB)来衡量的,即十分之一Bel,以Alexander Graham Bell命名。分贝是一个相对的、对数单位,它将被测量的水平与某个参考点进行比较。有许多不同的参考点来测量分贝,每个参考点在单位上都有一个后缀表示。如果没有参考点,说一个信号是某个数字的分贝是毫无意义的。例如,dBV、dBu和dBm对测量电信号都很有用。由于我们正在处理数字音频,我们主要关注两种测量方法:dBFS和dBSPL。
第一个是dBFS,即满刻度分贝。音频设备产生的声音的最高水平是0dBFS。所有其他水平都是用负数表示。
dBFS在数学上被描述为。
dBFS = 20 * log( [采样电平] / [最大电平] )
在一个16位的音频系统中,最大的dBFS值是。
max = 20 * log(1111 1111 1111 1111/1111 1111 1111) = log(1) = 0
请注意,根据定义,最大的dBFS值将永远是0,因为log(1)=0。 同样,在同一系统中的最小dBFS值是
min = 20 * log(0000 0000 0000 0001/1111 1111 1111) = -96 dBFS
dBFS是增益的衡量标准,而不是音量。你可以在立体声增益设置很低的情况下通过立体声播放一个0-dBFS的信号,但几乎听不到任何声音。相反,你可以把立体声增益调到最大,播放一个-30dBFS的信号,把你的耳膜炸开。
也就是说,你可能听过有人用分贝来描述一个声音的音量。从技术上讲,他们指的是dBSPL,或相对于声压级的分贝。在这里,参考点是0.000002牛顿/平方米(大约是一只蚊子在3米外飞行的声音)。dBSPL没有上限,但在实践中,我们希望保持低于耳朵损伤的水平(~120 dBSPL)和远低于疼痛的阈值(~150 dBSPL)。Web Audio API不使用dBSPL,因为声音的最终音量取决于操作系统的增益和扬声器的增益,而且只处理dBFS。
分贝的对数定义在某种程度上与我们的耳朵感知响度的方式相关,但响度仍然是一个非常主观的概念。比较一个声音的分贝值和同一声音的2倍增益,我们可以看到,我们获得了大约6分贝。
diff = 20 * log(2/2^16) - 20 * log(1/2^16) = 6.02 dB
每增加6分贝左右,我们实际上就把信号的振幅提高了一倍。将摇滚音乐会的声音(~110 dBSPL)与你的闹钟(~80 dBSPL)相比较,两者之间的差别是(110 - 80)/6 dB,或者大约5倍的声音,增益倍数为2^5 = 32倍。因此,立体声的音量旋钮也被校准为以指数形式增加振幅。换句话说,转动音量旋钮3个单位,信号的振幅就会增加2^3倍或8倍。在实践中,这里描述的指数模型只是对我们的耳朵感知响度的一种近似,音频设备制造商往往有自己的定制增益曲线,既不是线性的,也不是指数的。
等功率交变
通常在游戏环境中,你会遇到这样的情况:你想在两个有不同声音的环境之间交叉淡化。然而,什么时候交叉渐变以及交叉渐变的程度是事先不知道的;也许它随着游戏头像的位置而变化,而游戏头像是由玩家控制的。在这种情况下,我们不能做一个自动的斜坡。
一般来说,做一个直接的、线性的淡入淡出会导致以下的图形。它听起来可能不平衡,因为在两个样本之间有一个音量凹陷,如图3-2所示。
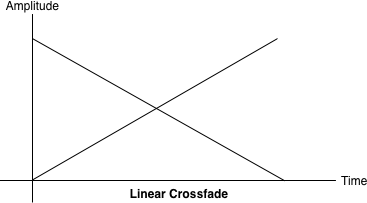
Figure 3-2. A linear crossfade between two tracks
为了解决这个问题,我们采用了等功率曲线,其中相应的增益曲线既不是线性的,也不是指数的,而是在一个较高的振幅处相交(图3-3)。这有助于避免在交叉渐变的中间部分出现音量下降的情况,此时两种声音被平均混合在一起。
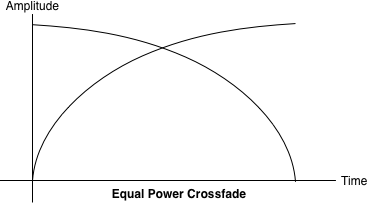
Figure 3-3. An equal power crossfade sounds much better
图3-3中的图表可以通过一些数学方法生成:
function equalPowerCrossfade(percent) {
// 使用一个等功率的交叉渐变曲线。
var gain1 = Math.cos( percent * 0.5*Math.PI);
var gain2 = Math.cos((1.0 - percent) * 0.5*Math.PI);
this.ctl1.gainNode.gain.value = gain1。
this.ctl2.gainNode.gain.value = gain2。
}
剪切和测光
就像图像超过画布的边界一样,如果波形超过其最大水平,声音也会被剪断。这产生的明显失真显然是不可取的。音频设备通常有显示音频电平大小的指示器,以帮助工程师和听众产生不剪辑的输出。这些指示器被称为仪表(图3-4),通常有一个绿色区域(无削波)、黄色区域(接近削波)和红色区域(削波)。

Figure 3-4. A meter in a typical receiver
阉割的声音在监视器上看起来很糟糕,听起来也不会好到哪里去。重要的是要听出刺耳的失真,或者反过来说,过于压抑的混音,迫使你的听众提高音量。如果你处于这两种情况中,请继续阅读!
使用测量仪来检测和防止削波
由于同时播放的多个声音是相加的,没有电平降低,你可能会发现自己处于一个超过扬声器能力的阈值的情况。对于16位音频来说,声音的最大电平是0dBFS,即2^16。在浮点信号中,这些比特值被映射到[-1,1]。被削掉的声音的波形看起来像图3-5。在Web Audio API的上下文中,如果发送到目标节点的值超出了范围,声音就会被剪断。在你的最终混音中留出一些空间(称为净空)是个好主意,这样你就不会太接近削波阈值了。
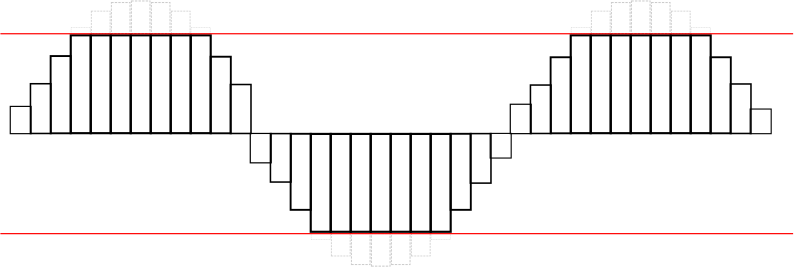
Figure 3-5. A diagram of a waveform being clipped
除了仔细聆听外,你还可以通过把脚本处理器节点放到音频图中,以编程方式检查你的声音是否被剪掉了。如果任何一个PCM值超出了可接受的范围,就可能发生削波。在这个例子中,我们同时检查左、右声道的削波,如果检测到削波,就保存最后的削波时间。
function onProcess(e) {
var leftBuffer = e.inputBuffer.getChannelData(0);
var rightBuffer = e.inputBuffer.getChannelData(1);
checkClipping(leftBuffer);
checkClipping(rightBuffer);
}
function checkClipping(buffer) {
var isClipping = false;
// 遍历缓冲区,检查是否有任何|值|超过1。
for (var i = 0; i < buffer.length; i++) {
var absValue = Math.abs(buffer[i])。
if(absValue >= 1.0) {
isClipping = true。
break
}
}
this.isClipping = isClipping。
if(isClipping) {
lastClipTime = new Date();
}
}
计量的另一种实现可以在渲染时轮询音频图中的实时分析器以获取浮动频率数据,这由requestAnimationFrame决定(见分析和可视化)。这种方法更有效,但会错过很多信号(包括可能出现剪辑的地方),因为渲染的速度是每秒60次,而音频信号的变化要快得多。
防止削波的方法是降低信号的整体电平。如果你正在削波,在主音频增益节点上应用一些零星的增益,将你的混音降到防止削波的水平。一般来说,你应该调整增益来预测最坏的情况,但要做到这一点,与其说是科学,不如说是一门艺术。在实践中,由于在你的游戏或交互式应用程序中播放的声音可能取决于在运行时决定的大量因素,因此很难在所有情况下挑选防止削波的主增益值。对于这种不可预知的情况,可以寻求动态压缩,这在动态压缩中讨论。
了解动态范围
在音频中,动态范围是指声音中最大声和最安静的部分之间的差异。音乐作品的动态范围的大小因体裁的不同而有很大的差异。古典音乐有很大的动态范围,经常有非常安静的部分,然后是相对响亮的部分。许多流行的音乐类型,如摇滚和电子音乐,往往有一个小的动态范围,由于明显的竞争(被称为 "响度战争"),增加曲目的响度,以满足消费者的需求,所以是一致的响度。这种统一的响度通常是通过使用动态范围压缩实现的。
也就是说,压缩有许多合法用途。有时,录制的音乐有一个很大的动态范围,有些部分听起来非常安静或响亮,听众需要不断地用手指按住音量旋钮。压缩可以使响亮的部分安静下来,同时使安静的部分清晰可闻。图3-6显示了一个波形(上图),然后是同一波形的压缩(下图)。你可以看到,声音整体上更响亮了,而且振幅的变化也更小。
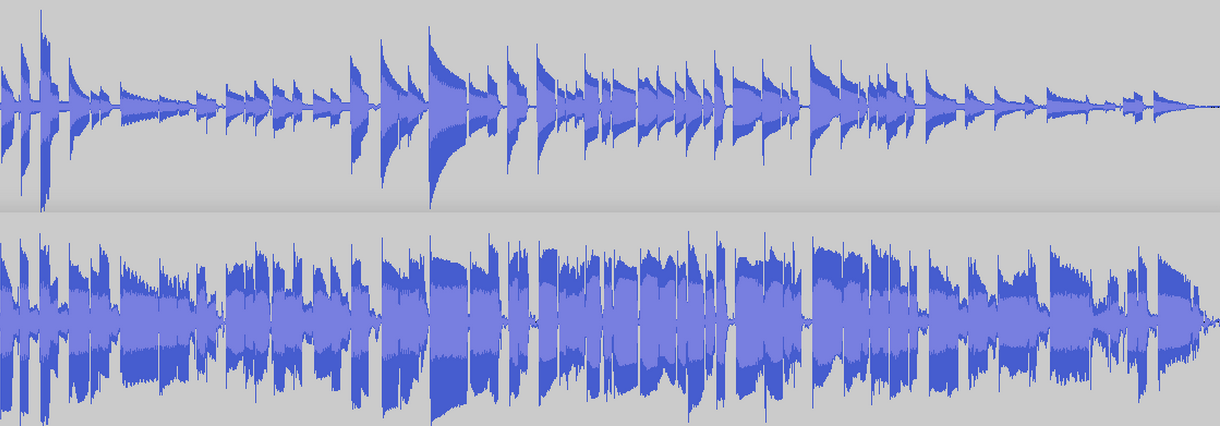
Figure 3-6. The effects of dynamics compression
对于游戏和互动应用,你可能事先不知道你的声音输出会是什么样子。由于游戏的动态特性,你可能会有非常安静的时期(例如隐秘的潜行),然后是非常响亮的时期(例如战区)。压缩器节点在突然出现的嘈杂情况下,可以帮助减少削波的可能性[见削波和计量]。
压缩器可以用一个带有几个参数的压缩曲线来建模,所有这些参数都可以用Web Audio API来调整。压缩器的两个主要参数是阈值和比率。阈值指的是压缩器开始减少动态范围的最低音量。比率决定了压缩器对增益的降低程度。图3-7说明了阈值和各种压缩比对压缩曲线的影响。
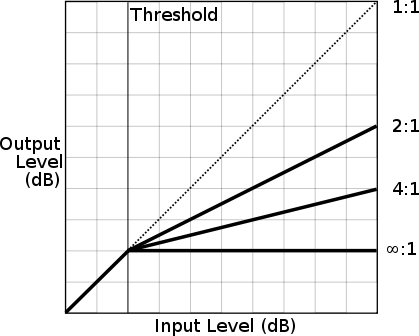
Figure 3-7. A sample compression curve with basic parameters
动态压缩
压缩器在Web Audio API中对应DynamicsCompressorNodes。在混音中使用适量的动态压缩通常是个好主意,特别是在游戏环境中,如前所述,你不知道到底什么声音会在什么时候播放。有一种情况应该避免使用压缩,那就是在处理精心制作的音轨时,这些音轨已经被调整得 "恰到好处",而且没有与任何其他音轨混合。
在Web Audio API中实现动态压缩,只需在音频图中加入一个动态压缩器节点,一般作为目的地之前的最后一个节点。
var compressor = context.createDynamicsCompressor()
mix.connect(compressor)
compressor.connect(context.destination)
如理论部分所述,该节点可以配置一些额外的参数,但默认值对大多数用途来说是相当不错的。关于配置压缩曲线的更多信息,请参阅Web Audio API规范。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号