

决策树
决策树
决策树又称为判定树,是运用于分类的一种树结构,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,叶节点代表某个类或类的分布。
决策树的决策过程需要从决策树的根节点开始,待测数据与决策树中的特征节点进行比较,并按照比较结果选择选择下一比较分支,直到叶子节点作为最终的决策结果。

决策树的学习过程
- 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
- 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止声场。
- 剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
实现决策树的算法包括ID3、C4.5算法等。
ID3算法
ID3算法是由Ross Quinlan提出的决策树的一种算法实现,以信息论为基础,以信息熵和信息增益为衡量标准,从而实现对数据的归纳分类。
ID3算法是建立在奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。
奥卡姆剃刀(Occam's Razor, Ockham's Razor),又称“奥坎的剃刀”,是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出,他在《箴言书注》2卷15题说“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事情’。简单点说, 便是:be simple。
算法缺陷
ID3算法可用于划分标准称型数据,但存在一些问题:
- 没有剪枝过程,为了去除过渡数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点;
- 信息增益的方法偏向选择具有大量值的属性,也就是说某个属性特征索取的不同值越多,那么越有可能作为分裂属性,这样是不合理的;
- 只可以处理离散分布的数据特征
属性选择
ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
信息熵(entropy)是用来衡量一个随机变量出现的期望值。如果信息的不确定性越大,熵的值也就越大,出现的各种情况也就越多。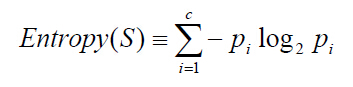
其中,S为所有事件集合,p为发生概率,c为特征总数。注意:熵是以2进制位的个数来度量编码长度的,因此熵的最大值是log2C。
信息增益(information gain)是指信息划分前后的熵的变化,也就是说由于使用这个属性分割样例而导致的期望熵降低。也就是说,信息增益就是原有信息熵与属性划分后信息熵(需要对划分后的信息熵取期望值)的差值,具体计算法如下:
其中,第二项为属性A对S划分的期望信息。
基本思想
- 初始化属性集合和数据集合
- 计算数据集合信息熵S和所有属性的信息熵,选择信息增益最大的属性作为当前决策节点
- 更新数据集合和属性集合(删除掉上一步中使用的属性,并按照属性值来划分不同分支的数据集合)
- 依次对每种取值情况下的子集重复第二步
- 若子集只包含单一属性,则为分支为叶子节点,根据其属性值标记。
- 完成所有属性集合的划分
注意:该算法使用了贪婪搜索,从不回溯重新考虑之前的选择情况。
(2)C4.5算法
C4.5是ID3算法的改进版,ID3使用信息增益比,但是信息增益有个缺点就是会偏向选择取值较多的特征,这样会造成数据过拟合。所以C4.5通过改进ID3使用信息增益率为特征选择准则。就是信息增益g(D,A)与训练数据集D有关于特征A的值得熵之比。
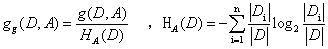
其他的步骤和ID3一样。
(3)CART算法
CART(classification and regression tree),分类与回归树。既可以用于分类也可以用于回归。
步骤:
- 决策树的生成,基于训练数据集,生成的决策树要尽量大;
- 决策树的剪枝,用验证集对生成树进行剪枝验证,选取最好的决策树。用损失函数最小作为剪枝的标准。
对决策树(CART)的生成其实就是递归的构建二叉树的过程,对回归树用平方误差最小原则,对分类树采用基尼系数(Gini index)原则.
(1) 回归树
问题,如何对输入空间进行划分?
这里采用启发式的方法:选择第j个变量的x(j)和它的取值s作为切变量和切分点对数据进行划分,然后需找最优的s和j。具体求解:
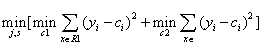
遍历所有输入变量,寻找最优切分遍历,依此将空间划分为两个空间。通常称为最小二乘回归树。
(2)分类树
利用基尼指数选择最优特征。基尼指数其实就代表了集合的不确定性,基尼指数越大,样本集合的不确定性也就越大,这一点与熵相似。基尼指数的曲线趋势和分类误差率差不多。
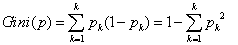 ,表示有K个类别,以及样本属于第K类的概率PK.
,表示有K个类别,以及样本属于第K类的概率PK.
选择基尼指数最小的特征及其对应的切分点作为最优特征和最优切分点。
(4)Random Forest算法
核心:其实就是集成学习的概念包括(bagging,boosting),通过集成投票的方式提高预测精度。
数据的选择:
(1)使用bootstrap重复有放回采样获取数据,这样可以避免数据的过拟合。这样就获取了很多训练数据集合,而且它们是相互独立,并且可以并行的。
(2)随机的抽取m个特征值与获取到的采样样本通过CART构建决策树。
(3)构建多棵决策树,用这些决策树进行投票预测
我们可以看出来,基分类器(即每一棵树)它们的训练数据不一样,它们的属性集合也不一样,这样就可以构建出许多有差异性的分类器出来,通过集成可以获取很好的预测精度。
就是一片树林里种植好多棵树,用这片森林来预测数据。
博客来自于 learn more and more
