

监督学习与非监督学习的区别
以下是摘抄自知乎上对监督学习与非监督学习的总结,觉得写得很形象,于是记下:
这个问题可以回答得很简单:是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习,没标签则为无监督学习
首
先看什么是学习(learning)?一个成语就可概括:举一反三。此处以高考为例,高考的题目在上考场前我们未必做过,但在高中三年我们做过很多很多题
目,懂解题方法,因此考场上面对陌生问题也可以算出答案。机器学习的思路也类似:我们能不能利用一些训练数据(已经做过的题),使机器能够利用它们(解题
方法)分析未知数据(高考的题目)?
最简单也最普遍的一类机器学习算法就是分类(classification)。对于分类,输入的训练
数据有特征(feature),有标签(label)。所谓的学习,其本质就是找到特征和标签间的关系(mapping)。这样当有特征而无标签的未知数
据输入时,我们就可以通过已有的关系得到未知数据标签。
在上述的分类过程中,如果所有训练数据都有标签,则为有监督学习(supervised learning)。如果数据没有标签,显然就是无监督学习(unsupervised learning)了,也即聚类(clustering)。
(但有监督学习并非全是分类,还有回归(regression),此处不细说。(哇擦,贵圈太乱,逼着我用了这么多括号))
目
前分类算法的效果普遍还是不错的,相对来讲,聚类算法就有些惨不忍睹了。确实,无监督学习本身的特点使其难以得到如分类一样近乎完美的结果。这也正如我们在高中做题,答案(标签)是非常重要的,假设两个完
全相同的人进入高中,一个正常学习,另一人做的所有题目都没有答案,那么想必第一个人高考会发挥更好,第二个人会发疯。
这时各位可能要
问,既然分类如此之好,聚类如此之不靠谱,那为何我们还可以容忍聚类的存在?因为在实际应用中,标签
的获取常常需要极大的人工工作量,有时甚至非常困难。例如在自然语言处理(NLP)中,Penn Chinese
Treebank在2年里只完成了4000句话的标签……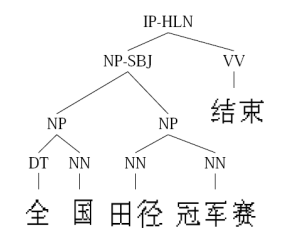
这
时有人可能会想,难道有监督学习和无监督学习就是非黑即白的关系吗?有没有灰呢?Good
idea。灰是存在的。二者的中间带就是半监督学习(semi-supervised
learning)。对于半监督学习,其训练数据的一部分是有标签的,另一部分没有标签,而没标签数据的数量常常极大于有标签数据数量(这也是符合现实情
况的)。隐藏在半监督学习下的基本规律在于:数据的分布必然不是完全随机的,通过一些有标签数据的局部特征,以及更多没标签数据的整体分布,就可以得到可
以接受甚至是非常好的分类结果。(此处大量忽略细节:
因此,learning家族的整体构造是这样的:
有监督学习(分类,回归)
↕
半监督学习(分类,回归),transductive learning(不懂怎么翻译,直推式学习?)(分类,回归)
↕
半监督聚类(有标签数据的标签不是确定的,类似于:肯定不是xxx,很可能是yyy)
↕
无监督学习(聚类)

