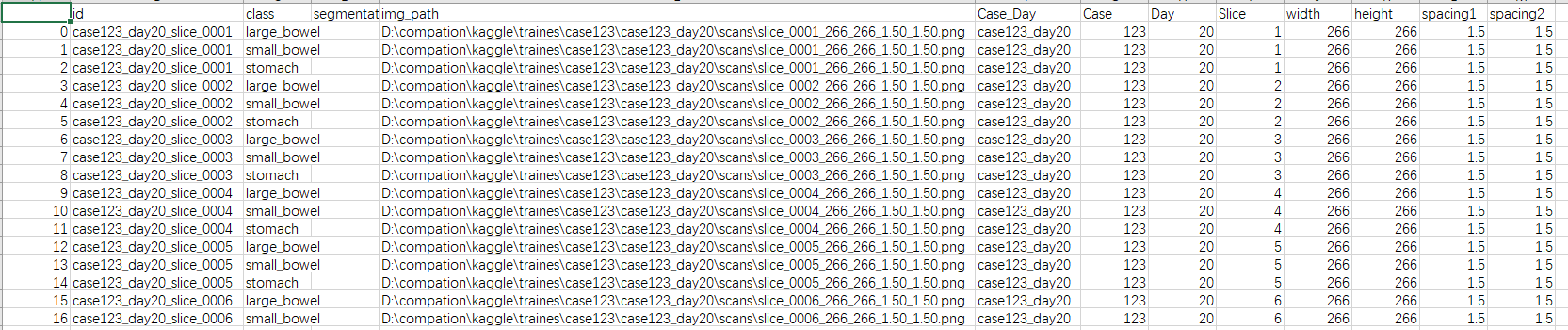
利用csv文件信息,将图片名信息保存到csv文件当中
我们可以利用train.csv文件信息, 再结合给定的文件路径(path)信息,可以将给定字目录下的图片名信息整合到scv文件当中。
train.csv文件格式:
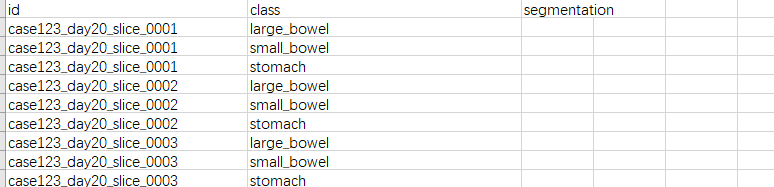
图片名信息:
代码如下:
from glob import glob import pandas as pd import os def enrich_data(df, sdir="train"): imgs = glob(os.path.join(DATASET_FOLDER, sdir, "case*", "case*_day*", "scans", "*.png")) img_folders = [os.path.dirname(p).split(os.path.sep) for p in imgs] img_names = [os.path.splitext(os.path.basename(p))[0].split("_") for p in imgs] img_keys = [f"{f[-2]}_slice_{n[1]}" for f, n in zip(img_folders, img_names)] # print(img_keys[:5]) df["img_path"] = df["id"].map({k: p for k, p in zip(img_keys, imgs)}) df["Case_Day"] = df["id"].map({k: f[-2] for k, f in zip(img_keys, img_folders)}) df["Case"] = df["id"].apply(lambda x: int(x.split("_")[0].replace("case", ""))) df["Day"] = df["id"].apply(lambda x: int(x.split("_")[1].replace("day", ""))) df["Slice"] = df["id"].map({k: int(n[1]) for k, n in zip(img_keys, img_names)}) df["width"] = df["id"].map({k: int(n[2]) for k, n in zip(img_keys, img_names)}) df["height"] = df["id"].map({k: int(n[3]) for k, n in zip(img_keys, img_names)}) df["spacing1"] = df["id"].map({k: float(n[4]) for k, n in zip(img_keys, img_names)}) df["spacing2"] = df["id"].map({k: float(n[5]) for k, n in zip(img_keys, img_names)}) if __name__ == "__main__": # df_ssub = pd.read_csv(os.path.join(DATASET_FOLDER, "sample_submission.csv")) DATASET_FOLDER = "D:\compation\kaggle" df_ssub = pd.read_csv(os.path.join(DATASET_FOLDER, "train.csv","traines.csv")) enrich_data(df_ssub,"traines") df_ssub.to_csv("df.csv") print(df_ssub["Case_Day"][4])
结果: