

java集合框架
转载:https://www.cnblogs.com/yangliguo/p/7476788.html
部分修改自其它博主,地址找不到了,望见谅!
集合
集合与数组
数组(可以存储基本数据类型)是用来存现对象的一种容器,但是数组的长度固定,不适合在对象数量未知的情况下使用。
集合(只能存储对象,对象类型可以不一样)的长度可变,可在多数情况下使用。
集合中接口和类的关系
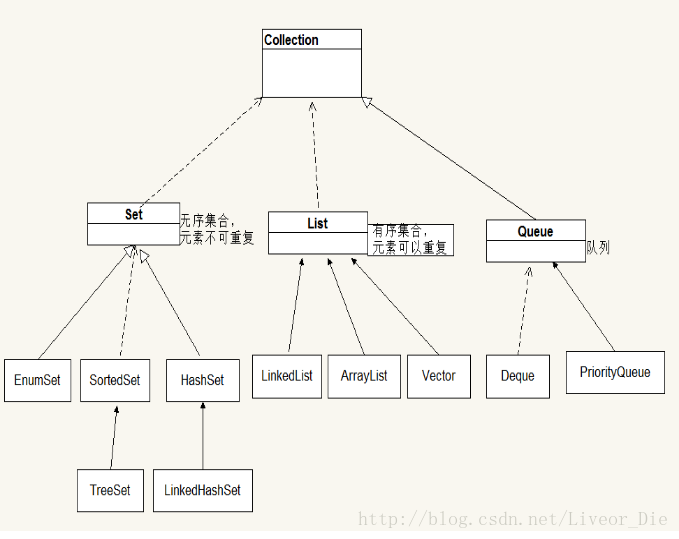
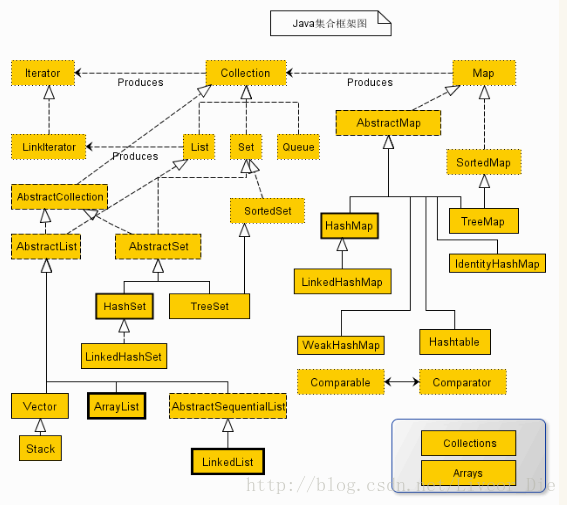
1、Collection接口是集合类的根接口,Java中没有提供这个接口的直接的实现类。但是却让其被继承产生了两个接口,就是Set和List。Set中不能包含重复的元素。List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式。
2、Map是Java.util包中的另一个接口,它和Collection接口没有关系,是相互独立的,但是都属于集合类的一部分。Map包含了key-value对。Map不能包含重复的key,但是可以包含相同的value。
3、Iterator所有的集合类,都实现了Iterator接口,这是一个用于遍历集合中元素的接口,主要包含以下三种方法:
- hasNext()是否还有下一个元素。
- next()返回下一个元素。
- remove()删除当前元素。
list:(有序、可重复)
ArrayList:(有序)
ArrayList是基于数组的,初始化时,他会自动的构建空数组,提供一个sort()方法,如果需要对ArrayList进行排序,只需要调用这个方法,提供Comparator比较器即可

1 @Override 2 @SuppressWarnings("unchecked") 3 public void sort(Comparator<? super E> c) { 4 final int expectedModCount = modCount; 5 Arrays.sort((E[]) elementData, 0, size, c); 6 if (modCount != expectedModCount) { 7 throw new ConcurrentModificationException(); 8 } 9 modCount++; 10 }
add操作:
1)如果是第一次添加元素,数组的长度被扩容到默认的capacity,也就是10.
2) 当发觉同时添加一个或者是多个元素,数组长度不够时,就扩容,这里有两种情况:
只添加一个元素,例如:原来数组的capacity为10,size已经为10,不能再添加了。需要扩容,新的capacity=old capacity+old capacity>>1=10+10/2=15.即新的容量为15。
当同时添加多个元素时,原来数组的capacity为10,size为10,当同时添加6个元素时。它需要的min capacity为16,而按照capacity=old capacity+old capacity>>1=10+10/2=15。new capacity小于min capacity,则取min capacity。
1 private void grow(int minCapacity) { 2 // 获取到ArrayList中elementData数组的内存空间长度 3 int oldCapacity = elementData.length; 4 // 扩容至原来的1.5倍 5 int newCapacity = oldCapacity + (oldCapacity >> 1); 6 // 再判断一下新数组的容量够不够,够了就直接使用这个长度创建新数组, 7 // 不够就将数组长度设置为需要的长度 8 if (newCapacity - minCapacity < 0) 9 newCapacity = minCapacity; 10 //若预设值大于默认的最大值检查是否溢出 11 if (newCapacity - MAX_ARRAY_SIZE > 0) 12 newCapacity = hugeCapacity(minCapacity); 13 // 调用Arrays.copyOf方法将elementData数组指向新的内存空间时newCapacity的连续空间 14 // 并将elementData的数据复制到新的内存空间 15 elementData = Arrays.copyOf(elementData, newCapacity); 16 }
对于添加,如果不指定下标,就直接添加到数组后面,不涉及元素的移动,如果要添加到某个特定的位置,那需要将这个位置开始的元素往后挪一个位置,然后再对这个位置设置。
Remove操作:
Remove提供两种,按照下标和value。
1)remove(int index):首先需要检查Index是否在合理的范围内。其次再调用System.arraycopy将index之后的元素向前移动。
2)remove(Object o):首先遍历数组,获取第一个相同的元素,获取该元素的下标。其次再调用System.arraycopy将index之后的元素向前移动。
Get操作:
这个比较简单,直接对数组进行操作即可。
LinkedList(有序)
LinkedList是基于链表的,它是一个双向链表,每个节点维护了一个prev和next指针。同时对于这个链表,维护了first和last指针,first指向第一个元素,last指向最后一个元素。LinkedList是一个有序的链表,按照插入的先后顺序排序,不提供sort方法对内部元素排序。
Add元素:
LinkedList提供了几个添加元素的方法:addFirst、addLast、addAll、add等,时间复杂度为O(1)。
Remove元素:
LinkedList提供了几个移除元素的方法:removeFirst、removeLast、removeFirstOccurrence、remove等,时间复杂度为O(1)。
Get元素:
根据给定的下标index,判断它first节点、last直接距离,如果index<size(数组元素个数)/2,就从first开始。如果大于,就从last开始。这个和我们平常思维不太一样,也许按照我们的习惯,从first开始。这也算是一点小心的优化吧。
Vector:
是一个可以自行扩展大小的容器,可以在里面存放任何对象,实现了一个动态数组,和ArrayList类似,但是两者是不同的:
- Vector是同步访问的。
- Vector包含了许多传统的方法,这些方法都不属于框架。
1 | public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable |
构造方法
1 public vector() 2 public vector(int initialcapacity,int capacityIncrement) 3 public vector(int initialcapacity)
使用第一种方法系统会自动对向量进行管理,若使用后两种方法,则系统将根据参数,initialcapacity设定向量对象的容量(即向量对象可存储数据的大小),当真正存放的数据个数超过容量时。系统会扩充向量对象存储容量。
参数capacityincrement给定了每次扩充的扩充值。当capacityincrement为0的时候,则每次扩充一倍,利用这个功能可以优化存储
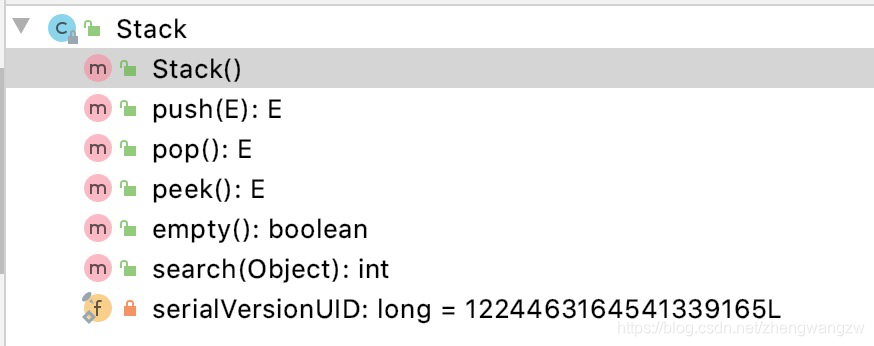
Stack:
Stack翻译过来是栈,栈最大的特点就是先进后出,Stack继承自Vector,因此和Vector一样,底层数据结构也是数组,除了Vector 提供的方法,Stack 提供了栈需要的一些方法。
遍历
在类集中提供了以下四种的常见输出方式:
1)Iterator:迭代输出,是使用最多的输出方式。
2)ListIterator:是Iterator的子接口,专门用于输出List中的内容。
3)foreach输出:JDK1.5之后提供的新功能,可以输出数组或集合。
4)for循环
代码示例如下:
for的形式:for(int i=0;i<arr.size();i++){...}
foreach的形式: for(int i:arr){...}
iterator的形式:
Iterator it = arr.iterator();
while(it.hasNext()){ object o =it.next(); ...}
Set(无序、不能重复)
Set集合类似于一个罐子,程序可以依次把多个对象“丢进”Set集合,而Set集合通常不能记住元素的添加顺序,Set集合不允许包含相同的元素,如果试图把两个相同元素加入同一个Set集合中,则添加操作失败,add()方法返回false,且新元素不会被加入。
HashSet
HashSet是基于HashMap来实现的,操作很简单,更像是对HashMap做了一次“封装”,而且只使用了HashMap的key来实现各种特性,而HashMap的value始终都是PRESENT。
HashSet不允许重复(HashMap的key不允许重复,如果出现重复就覆盖),允许null值,非线程安全。
HashSet是Set接口的典型实现,大多数时候使用Set集合时就是使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。底层数据结构是哈希表。
HashSet具有以下特点:
-
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也可能发生变化;
- HashSet不是同步的;
- 集合元素值可以是null;
内部存储机制
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。如果有两个元素通过equals方法比较true,但它们的hashCode方法返回的值不相等,HashSet将会把它们存储在不同位置,依然可以添加成功。也就是说。HashSet集合判断两个元素的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode方法返回值也相等。
构造方法
**HashSet() **
构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。
**HashSet(Collection<? extends E> c) **
构造一个包含指定 collection 中的元素的新 set。
**HashSet(int initialCapacity) **
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
HashSet(int initialCapacity, float loadFactor)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。
方法
boolean add(E e) **
如果此 set 中尚未包含指定元素,则添加指定元素。
void clear()
从此 set 中移除所有元素。
** Object clone() **
返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。
** boolean contains(Object o) **
如果此 set 包含指定元素,则返回 true。
** boolean isEmpty()
如果此 set 不包含任何元素,则返回 true。
** Iterator iterator() **
返回对此 set 中元素进行迭代的迭代器。
** boolean remove(Object o) **
如果指定元素存在于此 set 中,则将其移除。
** int size()**
返回此 set 中的元素的数量(set 的容量)。
LinkedHashSet类
HashSet还有一个子类LinkedList、LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说当遍历集合LinkedHashSet集合里的元素时,集合将会按元素的添加顺序来访问集合里的元素。
输出集合里的元素时,元素顺序总是与添加顺序一致。但是LinkedHashSet依然是HashSet,因此它不允许集合重复。
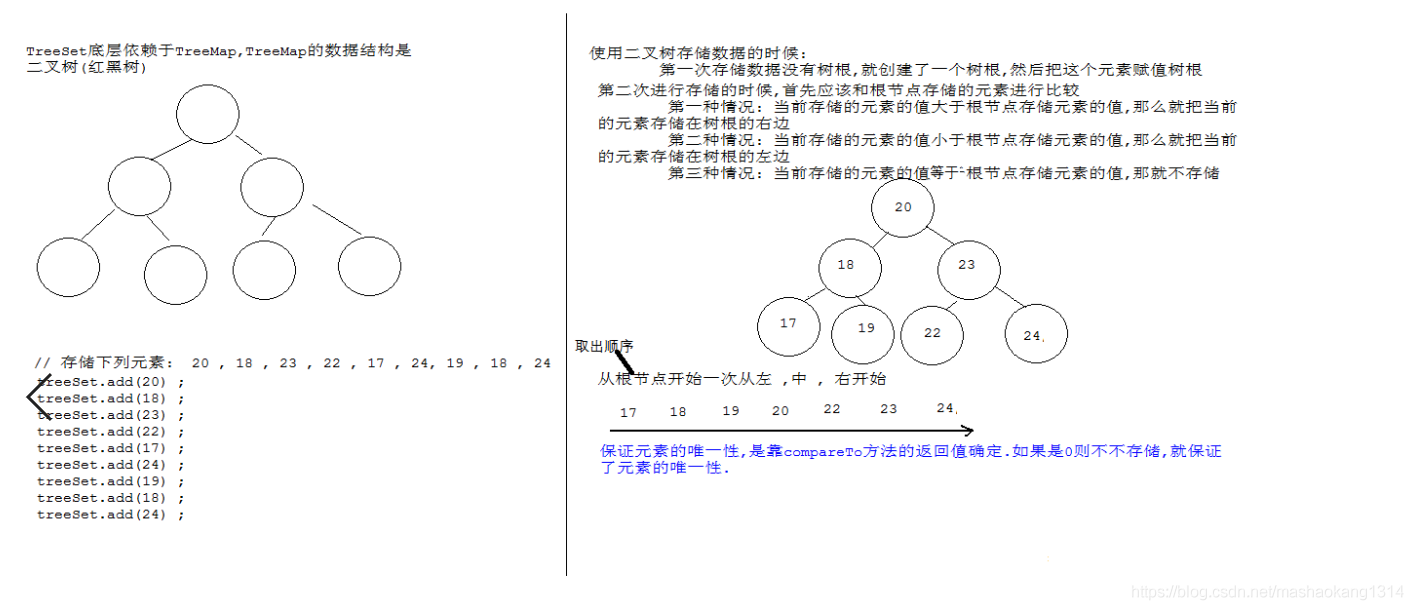
TreeSet
基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator进行排序,具体取决于使用的构造方法。
TreeSet可以确保集合元素处于排序状态。
内部存储机制
TreeSet内部实现的是红黑树,默认整形排序为从小到大。
与HashSet集合相比,TreeSet还提供了几个额外方法:
- Comparator comparator():如果TreeSet采用了定制顺序,则该方法返回定制排序所使用的Comparator,如果TreeSet采用自然排序,则返回null;
- Object first():返回集合中的第一个元素;
- Object last():返回集合中的最后一个元素;
- Object lower(Object e):返回指定元素之前的元素。
- Object higher(Object e):返回指定元素之后的元素。
- SortedSet subSet(Object fromElement,Object toElement):返回此Set的子集合,含头不含尾;
- SortedSet headSet(Object toElement):返回此Set的子集,由小于toElement的元素组成;
- SortedSet tailSet(Object fromElement):返回此Set的子集,由大于fromElement的元素组成;
1 TreeSet<Integer> nums = new TreeSet<>(); 2 //向集合中添加元素 3 nums.add(5); 4 nums.add(2); 5 nums.add(15); 6 nums.add(-4); 7 //输出集合,可以看到元素已经处于排序状态 8 System.out.println(nums);//[-4, 2, 5, 15] 9 10 System.out.println("集合中的第一个元素:"+nums.first());//集合中的第一个元素:-4 11 System.out.println("集合中的最后一个元素:"+nums.last());//集合中的最后一个元素:15 12 System.out.println("集合小于4的子集,不包含4:"+nums.headSet(4));//集合小于4的子集,不包含4:[-4, 2] 13 System.out.println("集合大于5的子集:"+nums.tailSet(2));//集合大于5的子集:[2, 5, 15] 14 System.out.println("集合中大于等于-3,小于4的子集:"+nums.subSet(-3,4));//集合中大于等于-3,小于4的子集:[2] 15 }
从上面的运行结果可以看出输出的集合已经按从小到大排好了,但是问题来了,只能从小到大排序吗?如果是字符对象应按该怎样的顺序排序?如果是一个学生对象又按怎样的顺序排序呢?遵循怎样的排序规则呢?
针对这个问题,TreeSet支持两种排序方法:自然排序和定制排序,在默认情况下,采用的是自然排序。
自然排序
TreeSet会调用集合元素的compareTo(Objec obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这就是自然排序。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类必须实现该方法,实现接口的类就可以比较大小了。当调用一个一个对象调用该方法与另一个对象进行比较时,obj1.compareTo(obj2)如果返回0表示两个对象相等;如果返回正整数则表明obj1大于obj2,如果是负整数则相反。
案例:
实现存储学生类的集合,排序方式,按年龄大小,如果年龄相等,则按name字符串长度,如果长度相等则比较字符。如果name和age都相等则视为同一对象。
5 public class Student implements Comparable<Student> { 6 private String name; 7 private int age; 8 9 public Student(String name, int age) { 10 this.name = name; 11 this.age = age; 12 } 13 14 public String getName() { 15 return name; 16 } 17 18 public void setName(String name) { 19 this.name = name; 20 } 21 22 public int getAge() { 23 return age; 24 } 25 26 public void setAge(int age) { 27 this.age = age; 28 } 29 30 @Override 31 public String toString() { 32 return "Student{" + 33 "name='" + name + '\'' + 34 ", age=" + age + 35 '}'; 36 } 37 38 @Override 39 public int compareTo(Student o) { 40 //比较age 41 int num=this.age-o.age; 42 //如果age相等则比较name长度 43 int num1=num==0?this.name.length()-o.name.length():num; 44 //如果前两者都相等则比较name字符串 45 int num2=num1==0?this.name.compareTo(o.name):num1; 46 return num2; 47 } 48 }
1 public class TreeSetDemo4 { 2 public static void main(String[] args) { 3 TreeSet<Student> tree = new TreeSet<>(); 4 5 //向集合中添加元素 6 tree.add(new Student("孙悟空",16)); 7 tree.add(new Student("孙悟空",17)); 8 tree.add(new Student("孙悟空",16)); 9 tree.add(new Student("唐僧",16)); 10 tree.add(new Student("沙悟净",23)); 11 tree.add(new Student("唐僧",30)); 12 13 //遍历 14 System.out.println(tree); 15 /*[Student{name='唐僧', age=16}, 16 Student{name='孙悟空', age=16}, 17 Student{name='孙悟空', age=17}, 18 Student{name='沙悟净', age=23}, 19 Student{name='唐僧', age=30}] 20 */ 21 22 } 23 }
当把一个对象添加进集合时,集合调用该对象的CompareTo(Object obj)方法与容器中的其他对象比较大小,然后根据红黑树结构中找到它的存储位置。如果两个对象相等则新对象无法加入到集合中。
注意问题
- 大部分类在实现CompareTo(Object o)方法时,都需要将被比较对象obj强制类型转换成相同类型,因为只有相同的两个实例才会比较大小。
- 加入集合的类都必须实现Comparable接口,否则会引发ClassCastException异常。
- 向TreeSet集合中添加元素时,只有第一个元素无须实现Comparable接口,后面添加的所有元素都必须实现Comparable接口。当然这也不是一种好做法,当试图从TreeSet中取出元素时,依然会引发ClassCastException异常。
- 不要修改已经存入集合的实例变量,这将导致它与其他对象的大小顺序发生改变,但TreeSet集合不会再次调整它们的顺序,这点和HashSet一样。
- 如果希望TreeSet能正常工作,TreeSet只能添加同一种类型的对象
- 对于TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj)方法比较是否返回0,如果是0则认为对象相等,否则认为不相等。
定制排序
TreeSet的自然排序是根据集合元素的大小,TreeSet将它们以升序排列。如果需要实现定制排序,例如降序排序,则可通过Comparator接口的帮助。该接口里包含一个int compare(T o1,T o2)方法,用于比较o1和o2的大小。由于Comparator是一个函数式接口,因此还可以使用Lambda表达式来代替Comparator子类对象。
1 //如果需要更改排序方式,则更改Comparator对象的返回值; 2 3 TreeSet<Integer> nums = new TreeSet<>(new Comparator<Integer>() { 4 @Override 5 public int compare(Integer o1, Integer o2) { 6 return -(o1-o2); 7 } 8 }); 9 //向集合中添加元素 10 nums.add(5); 11 nums.add(2); 12 nums.add(15); 13 nums.add(-4); 14 //输出集合,可以看到元素已经处于排序状态 15 System.out.println(nums);//[15, 5, 2, -4]
//使用Lambda表达式来代替Comparator子类对象。
TreeSet<Integer> nums = new TreeSet<>(new Comparator<Integer>() { 2 @Override 3 public int compare(Integer o1, Integer o2) { 4 return o1-o2; 5 } 6 }); 7 //向集合中添加元素 8 nums.add(5); 9 nums.add(2); 10 nums.add(15); 11 nums.add(-4); 12 //输出集合,可以看到元素已经处于排序状态 13 System.out.println(nums);//[-4, 2, 5, 15]
1 //使用Lambda表达式来实现: 2 3 TreeSet<Integer> nums = new TreeSet<>((a,b)->-(a-b)); 4 //向集合中添加元素 5 nums.add(5); 6 nums.add(2); 7 nums.add(15); 8 nums.add(-4); 9 //输出集合,可以看到元素已经处于排序状态 10 System.out.println(nums);//[15, 5, 2, -4]
遍历
迭代遍历:
1 Set<String> set = new HashSet<String>(); 2 Iterator<String> it = set.iterator(); 3 while (it.hasNext()) { 4 String str = it.next(); 5 System.out.println(str); 6 }
for(foreach)循环遍历:
1 for (String str : set) { 2 System.out.println(str); 3 }
Queue:
Queue用于模拟队列这种数据结构,队列通常是指"先进先出"的容器。队列不允许随机访问队列中的元素
Queue接口里定义了如下几种方法:
- void add(Object e):将指定元素加入此队列的尾部;
- Object element():获取队列头部的元素,但是不删除该元素;
- boolean offer(Object e):将指定元素加入此队列的尾部。当使用有容量限制的队列时,此方法通常比add方法更好;
- Object peek():获取头部元素,但不删除,如果队列为空,则返回null;
- Object poll():获取队列头部元素并删除。如果队列为空,则返回null;
- Object remove():删除头部元素。
Queue接口有一个PriorityQueue实现类,除此之外Queue还有一个Deque接口,Deque代表一个"双端队列",可以同时从两端来添加或删除元素。
PriorityQueue实现类:
PriorityQueue保存队列元素的顺序并不是按加入顺序,而是按队列元素的大小进行重新排序。因此当调用peek或poll方法时,并不是取出元素的最先进入的,而是取出最小元素。
1 PriorityQueue pq = new PriorityQueue(); 2 3 //添加元素 4 pq.offer(6); 5 pq.offer(23); 6 pq.offer(-4); 7 pq.offer(18); 8 9 //输出队列 10 System.out.println(pq);//[-4, 18, 6, 23] 11 12 //访问队列第一个元素 13 System.out.println(pq.poll());//-4
PriorityQueue不允许插入null元素,他还需要对队列元素进行排序,PriorityQueue的元素有两种排序方法:
自然排序:采用自然排序的PriorityQueue集合中的元素必须实现Comparable接口,而且应该是同一个类的多个实例,否则会引发异常。
定制排序:创建PriorityQueue对烈士,传入一个Comparator对象。
Deque接口:
Deque接口是Queue接口的子接口,它代表一个双端队列,Deque接口里定义了一些双端队列的方法,这些方法允许从两端来操作队列元素:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | void addfirst(Object o):将指定元素插入该双端队列的开头;void addLast(Object o):将置顶元素插入双端队列末尾。Iterator descendingIterator():返回该双端队列对应的迭代器,该迭代器将以逆向顺序来迭代队列中的元素。Object getFirst():获取但不删除双端队列的第一个元素;Object getLast():获取但不删除双端队列的最后一个元素;boolean offerFirst(Object e):将指定元素加入双端队列的头部;boolean offerLast(Object e):将指定元素加入双端队列的尾部;Object peekFirst():获取头部元素,但不删除,如果队列为空,则返回null;Object peekLast():获取尾部元素,但不删除,如果队列为空,则返回null;Object pollFirst():获取队列头部元素并删除。如果队列为空,则返回null;Object pollLast():获取队列尾部元素并删除。如果队列为空,则返回null;Object pop():pop取出双端队列所表示的栈的栈顶元素。Object removeFirst():删除头部元素。Object removeFirstOccurrence(Object o):删除该双端队列的第一次出现的元素o;Object removeLast():删除尾部元素。Object removeLastOccurrence(Object o):删除该双端队列的最后一次出现的元素o; |
Deque提供了一个典型的实现类:ArrayDeque,它是一个基于数组实现的双端队列。
创建Deque时同样可指定一个numElements参数来指定Object[]数组的长度,如果不指定,默认长度为16
LinkedList类是List接口的实现类,这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,可以当做双端队列来使用。
ArrayDeque实现类:
ArrayDeque既可以当做“栈”来使用,也可以当做“队列”来使用;
Map(键值对、键唯一、值不唯一)
Map集合中存储的是键值对,键(key)很像下标,在List中下标是整数。在Map中键(key)可以使任意类型的对象,Map中的元素是两个对象,一个对象作为键,一个对象作为值,键不能重复,值可以重复。根据键得到值,对map集合遍历时先得到键的set集合,对set集合进行遍历,得到相应的值。
- Map与Collection在集合框架中属并列存在
- Map存储的是键值对
- Map存储元素使用put方法,Collection使用add方法
- Map集合没有直接取出元素的方法,而是先转成Set集合,在通过迭代获取元素
- Map集合中键要保证唯一性
- 也就是Collection是单列集合, Map 是双列集合。
-
123456789101112131415
Map学习体系:---| Map 接口 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。---| HashMap 采用哈希表实现,所以无序---| TreeMap 可以对健进行排序---|Hashtable:底层是哈希表数据结构,线程是同步的,不可以存入null键,null值。效率较低,被HashMap 替代。---|HashMap:底层是哈希表数据结构,线程是不同步的,可以存入null键,null值。要保证键的唯一性,需要覆盖hashCode方法,和equals方法。---| LinkedHashMap:该子类基于哈希表又融入了链表。可以Map集合进行增删提高效率。---|TreeMap:底层是二叉树数据结构。可以对map集合中的键进行排序。需要使用Comparable或者Comparator 进行比较排序。return0,来判断键的唯一性。<br>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | //常见方法:<br>1、添加: 1、V put(K key, V value) (可以相同的key值,但是添加的value值会覆盖前面的,返回值是前一个,如果没有就返回null) 2、putAll(Map<? extends K,? extends V> m) 从指定映射中将所有映射关系复制到此映射中(可选操作)。2、删除 1、remove() 删除关联对象,指定key对象 2、clear() 清空集合对象3、获取 1:value get(key); 可以用于判断键是否存在的情况。当指定的键不存在的时候,返回的是null。 3、判断: 1、boolean isEmpty() 长度为0返回true否则false 2、boolean containsKey(Object key) 判断集合中是否包含指定的key3、boolean containsValue(Object value) 判断集合中是否包含指定的value4、长度:Int size() |
Map集合的扩容方式
- 初始容量16,负载因子0.75,扩容增量1倍
- Map集合底层是一个数组
- 数组的初始容量是16
- 当长度到数组负载因子0.75长度的时候(16*0.75=12也就是说在12这个长度的时候)
- 进行一次扩容,扩容后容量是原容量的两倍
- 当我们已经知道需要的容量大小的时候
- 就可以指定初始容量跟负载因子的大小
HashMap
数组方式存储key/value,线程非安全,允许null作为key和value,key不可以重复,value允许重复,不保证元素迭代顺序是按照插入时的顺序,key的hash值是先计算key的hashcode值,然后再进行计算,每次容量扩容会重新计算所以key的hash值,会消耗资源,要求key必须重写equals和hashcode方法
默认初始容量16,加载因子0.75,扩容为旧容量乘2,查找元素快,如果key一样则比较value,如果value不一样,则按照链表结构存储value,就是一个key后面有多个value;
方法
1、添加:
V put(K key, V value) (可以相同的key值,但是添加的value值会覆盖前面的,返回值是前一个,如果没有就返回null)
putAll(Map<? extends K,? extends V> m) 从指定映射中将所有映射关系复制到此映射中(可选操作)。
2、删除
remove() 删除关联对象,指定key对象
clear() 清空集合对象
3、获取
value get(key) 可以用于判断键是否存在的情况。当指定的键不存在的时候,返回的是null。
4、判断:
boolean isEmpty() 长度为0返回true否则false
boolean containsKey(Object key) 判断集合中是否包含指定的key
boolean containsValue(Object value) 判断集合中是否包含指定的value
4、长度:
Int size()
map的主要的方法就这几个
Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
TreeMap
基于红黑二叉树的NavigableMap的实现,线程非安全,不允许null,key不可以重复,value允许重复,存入TreeMap的元素应当实现Comparable接口或者实现Comparator接口,会按照排序后的顺序迭代元素,两个相比较的key不得抛出classCastException。主要用于存入元素的时候对元素进行自动排序,迭代输出的时候就按排序顺序输出
遍历
第一种:KeySet()
将Map中所有的键存入到set集合中。因为set具备迭代器。所有可以迭代方式取出所有的键,再根据get方法。获取每一个键对应的值。 keySet():迭代后只能通过get()取key 。
取到的结果会乱序,是因为取得数据行主键的时候,使用了HashMap.keySet()方法,而这个方法返回的Set结果,里面的数据是乱序排放的。
1 Map map = new HashMap(); 2 map.put("key1","lisi1"); 3 map.put("key2","lisi2"); 4 map.put("key3","lisi3"); 5 map.put("key4","lisi4"); 6 //先获取map集合的所有键的set集合,keyset() 7 Iterator it = map.keySet().iterator(); 8 //获取迭代器 9 while(it.hasNext()){ 10 Object key = it.next(); 11 System.out.println(map.get(key)); 12 }
第二种: values() 获取所有的值.
Collection values()不能获取到key对象
1 Collection<String> vs = map.values(); 2 Iterator<String> it = vs.iterator(); 3 while (it.hasNext()) { 4 String value = it.next(); 5 System.out.println(" value=" + value); 6 }
第三种:entrySet()
Set<Map.Entry<K,V>> entrySet() //返回此映射中包含的映射关系的 Set 视图。(一个关系就是一个键-值对),就是把(key-value)作为一个整体一对一对地存放到Set集合当中的。Map.Entry表示映射关系。entrySet():迭代后可以e.getKey(),e.getValue()两种方法来取key和value。返回的是Entry接口。
典型用法如下:
1 // 返回的Map.Entry对象的Set集合 Map.Entry包含了key和value对象 2 Set<Map.Entry<Integer, String>> es = map.entrySet(); 3 4 Iterator<Map.Entry<Integer, String>> it = es.iterator(); 5 6 while (it.hasNext()) { 7 8 // 返回的是封装了key和value对象的Map.Entry对象 9 Map.Entry<Integer, String> en = it.next(); 10 11 // 获取Map.Entry对象中封装的key和value对象 12 Integer key = en.getKey(); 13 String value = en.getValue(); 14 15 System.out.println("key=" + key + " value=" + value); 16 }
推荐使用第三种方式,即entrySet()方法,效率较高。
对于keySet其实是遍历了2次,一次是转为iterator,一次就是从HashMap中取出key所对于的value。而entryset只是遍历了第一次,它把key和value都放到了entry中,所以快了。两种遍历的遍历时间相差还是很明显的。
总结:
Vector和ArrayList
1,vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
2,如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度的50%。如果在集合中使用数据量比较大的数据,用vector有一定的优势。
3,如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,如果频繁的访问数据,这个时候使用vector和arraylist都可以。而如果移动一个指定位置会导致后面的元素都发生移动,这个时候就应该考虑到使用linklist,因为它移动一个指定位置的数据时其它元素不移动。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要涉及到数组元素移动等内存操作,所以索引数据快,插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。
arraylist和linkedlist
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
HashMap与TreeMap
1、 HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
2、在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
两个map中的元素一样,但顺序不一样,导致hashCode()不一样。
同样做测试:
在HashMap中,同样的值的map,顺序不同,equals时,false;
而在treeMap中,同样的值的map,顺序不同,equals时,true,说明,treeMap在equals()时是整理了顺序了的。
HashTable与HashMap
1、同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的。
2、HashMap允许存在一个为null的key,多个为null的value 。
3、hashtable的key和value都不允许为null。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!