
十五. 资源指标API以及自定义指标API
资源指标: Metrics-Server
资源指标: Metric-Server介绍
从k8s v1.8之后, 引入了Metric-API, 以前在使用heapster获取资源指标时, heapster有自己的获取路径, 没有通过apiServer, 所以之前资源指标的数据并不能通过apiServer直接获取, 用户和Kubernetes的其他组件必须通过master proxy的方式才能访问到. 后来k8s引入了资源指标API(Metrics API),有了Metrics Server组件,也采集到了该有的数据,也暴露了api,但因为api要统一,如何将请求到api-server的/apis/metrics请求转发给Metrics Server呢,解决方案就是:kube-aggregator, 于是资源指标的数据就从k8s的api中的直接获取,不必再通过其它途径。
- Metrics API 只可以查询当前的度量数据,并不保存历史数据
- Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 维护
- 必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 Kubelet Summary API 获取数据
Metrics-Server收集指标数据的方式是从各节点上kubelet提供的Summary API 收集数据,收集Node和Pod核心资源指标数据,主要是内存和cpu方面的使用情况,并将收集的信息存储在内存中,所以当通过kubectl top不能查看资源数据的历史情况,其它资源指标数据则通过prometheus采集了。
k8s中很多组件是依赖于资源指标API的功能 ,比如kubectl top 、hpa,如果没有一个资源指标API接口,这些组件是没法运行的;
新一代监控系统由核心指标流水线和监控指标流水线协同组成
- 核心指标流水线:由kubelet、metrics-server以及由API server提供的api组成;cpu累计利用率、内存实时利用率、pod的资源占用率及容器的磁盘占用率
- 监控流水线:用于从系统收集各种指标数据并提供给终端用户、存储系统以及HPA,他们包含核心指标以及许多非核心指标。非核心指标不能被k8s所解析
Metric-Server部署
下载yaml文件
for i in auth-delegator.yaml auth-reader.yaml metrics-apiservice.yaml metrics-server-deployment.yaml metrics-server-service.yaml resource-reader.yaml;do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/metrics-server/$i; done
因为有墙, 所以提前下载image镜像, 当然也可以手动修改yaml相关文件
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.5
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.5 k8s.gcr.io/metrics-server-amd64:v0.3.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/addon-resizer:1.8.5
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/addon-resizer:1.8.5 k8s.gcr.io/addon-resizer:1.8.5
修改文件, 不然报错
修改resource-reader.yaml
# 在resources下添加一行nodes/stats, 下列代码为部分代码
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:metrics-server
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- pods
- nodes/stats #添加此行
- nodes
- namespaces
修改metrics-server-deployment.yaml
默认会从kubelet的基于HTTP的10255端口获取指标数据,但出于安全通信目的,kubeadm在初始化集群时会关掉10255端口,导致无法正常获取数据
# 第一个container metrics-server的command只留下以下三行
containers:
- name: metrics-server
image: k8s.gcr.io/metrics-server-amd64:v0.3.5
command:
- /metrics-server
- --kubelet-insecure-tls # 不验证客户端证书
- --kubelet-preferred-address-types=InternalIP # 直接使用节点IP地址获取数据
# 第二个container metrics-server-nanny的command中内存和CPU修改为自己需要的具体的数值
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=20m
- --extra-cpu=0.5m
- --memory=200Mi #{{ base_metrics_server_memory }}
- --extra-memory=50Mi
- --threshold=5
- --deployment=metrics-server-v0.3.5
- --container=metrics-server
- --poll-period=300000
- --estimator=exponential
- --minClusterSize=10
创建Metric-Server
# 进入到yaml文件目录执行命令
kubectl apply -f ./
# 可以看到pod已经运行起来了
kubectl get pods -n kube-system |grep metrics-server
[root@master ~]# kubectl api-versions|grep metrics #已经可以看到metric的api了
metrics.k8s.io/v1beta1
[root@master ~]# kubectl proxy --port=8080
[root@master ~]# curl http://localhost:8080/apis/metrics.k8s.io/v1beta1
[root@master ~]# curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/nodes
# kubectl可以使用了
[root@master ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 513m 25% 1348Mi 78%
node01 183m 18% 1143Mi 66%
自定义资源指标: Prometheus
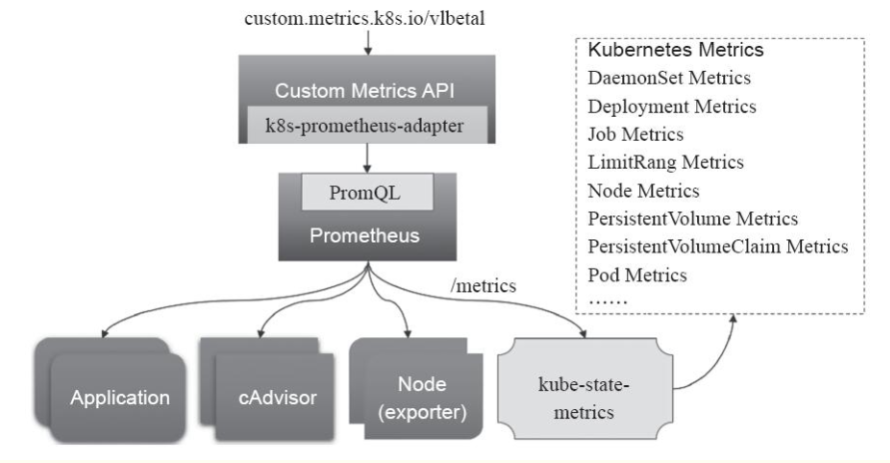
Prometheus可以采集其它各种指标,但是prometheus采集到的metrics并不能直接给k8s用,因为两者数据格式不兼容,因此还需要另外一个组件(kube-state-metrics),将prometheus的metrics数据格式转换成k8s API接口能识别的格式,转换以后,因为是自定义API,所以还需要用Kubernetes aggregator在主API服务器中注册,以便直接通过/apis/来访问。
k8s-prometheus-adapter 项目
Prometheus
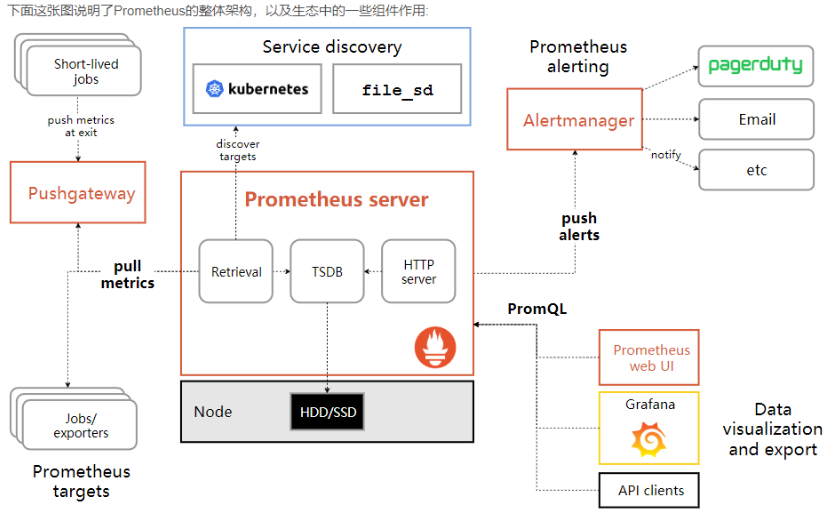
如上图,每个被监控的主机都可以通过专用的exporter程序提供输出监控数据的接口,并等待Prometheus服务器周期性的进行数据抓取。如果存在告警规则,则抓取到数据之后会根据规则进行计算,满足告警条件则会生成告警,并发送到Alertmanager完成告警的汇总和分发。当被监控的目标有主动推送数据的需求时,可以以Pushgateway组件进行接收并临时存储数据,然后等待Prometheus服务器完成数据的采集。
- 监控代理程序:如
node_exporter:收集主机的指标数据,如平均负载、CPU、内存、磁盘、网络等等多个维度的指标数据。 - kubelet(cAdvisor):收集容器指标数据,也是K8S的核心指标收集,每个容器的相关指标数据包括:CPU使用率、限额、文件系统读写限额、内存使用率和限额、网络报文发送、接收、丢弃速率等等。
- API Server:收集API Server的性能指标数据,包括控制队列的性能、请求速率和延迟时长等等
- etcd:收集etcd存储集群的相关指标数据
- kube-state-metrics:该组件可以派生出k8s相关的多个指标数据,主要是资源类型相关的计数器和元数据信息,包括制定类型的对象总数、资源限额、容器状态以及Pod资源标签系列等。
Prometheus把API Server作为服务发现系统发现和监控集群中的所有可被监控对象
这里需要特别说明的是, Pod 资源需要添加下列注解信息才能被 Prometheus 系统自动发现并抓取其内建的指标数据。
- prometheus.io/scrape: 是否采集指标数据,true/false
- prometheus.io/path: 抓取指标数据时使用 的URL 路径,常为 /metrics
- prometheus.io/port: 抓取指标数据时使用的套接字端口端口号
仅期望Prometheus为后端生成自定义指标时,仅部署Prometheus服务即可,甚至不需要持久功能
在k8s集群中部署Prometheus
github地址
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
需要部署的服务清单
node-exporter: prometheus的export,收集Node级别的监控数据prometheus: 监控服务端,从node-exporter拉数据并存储为时序数据。kube-state-metrics: 将prometheus中可以用PromQL查询到的指标数据转换成k8s对应的数据k8s-prometheus-adpater: 聚合进apiserver,即一种custom-metrics-apiserver实现开启Kubernetes aggregator功能(参考上文metric-server)
安装部署所有服务及插件
部署kube-state-metrics
# 下载相关yaml文件
for i in kube-state-metrics-deployment.yaml kube-state-metrics-rbac.yaml kube-state-metrics-service.yaml; do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/prometheus/$i; done
# 所有节点都要执行
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/addon-resizer:1.8.6
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/addon-resizer:1.8.6 k8s.gcr.io/addon-resizer:1.8.6
docker pull quay-mirror.qiniu.com/coreos/kube-state-metrics:v1.3.0
docker tag quay-mirror.qiniu.com/coreos/kube-state-metrics:v1.3.0 quay.io/coreos/kube-state-metrics:v1.3.0
# 查看提供的指标数据
curl 10.105.51.200:8080/metrics # 10.105.51.200 是Service的IP
部署Exporter及Node Exporter
监听 9100 端口
事实上,每个节点本身就能通过kubelet或cAdvisor提供节点指标数据,因此不需要安装node_exporter程序
for i in node-exporter-ds.yml node-exporter-service.yaml; do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/prometheus/$i; done
kubectl apply -f ./
curl 10.0.0.51:9100/metrics # 10.0.0.51是node01节点的IP
告警系统 Alertmanager
prometheus根据告警规则将告警信息发送给alertmanager,而后alertmanager对收到的告警信息进行处理,包括去重、分组并路由到告警接收端
alertmanager使用了持久存储卷,PVC , 这里只做测试, 所以把这部分修改了; 端口9093会有Web UI
for i in alertmanager-configmap.yaml alertmanager-deployment.yaml alertmanager-pvc.yaml alertmanager-service.yaml; do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/prometheus/$i; done
# 修改alertmanager-deployment.yaml的pvc设置
volumes:
- name: config-volume
configMap:
name: alertmanager-config
- name: storage-volume
emptyDir: {}
# persistentVolumeClaim:
# claimName: alertmanager
# 修改alertmanager-service.yaml
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9093
nodePort: 30093
selector:
k8s-app: alertmanager
type: "NodePort"
kubectl apply -f ./
kubectl get deployments -n kube-system
# 浏览器可以直接访问到Web UI
http://10.0.0.50:30093/#/alerts
部署prometheus服务
Prometheus提供Web UI,端口9090,需要存储卷,通过volumeClaimTemplates提供, 这里只做测试, 所以把这部分修改了, 所以采用了马哥的安装部署方式
# 官方安装yaml文件
for i in prometheus-configmap.yaml prometheus-rbac.yaml prometheus-service.yaml prometheus-statefulset.yaml; do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/prometheus/$i; done
# 马哥安装yaml文件
git clone https://github.com/iKubernetes/k8s-prom.git && cd k8s-prom #我只使用了这里边的prometheus文件, 并且把namespace统一修改成了kube-system
[root@master prometheus]# ls
prometheus-cfg.yaml prometheus-deploy.yaml prometheus-rbac.yaml prometheus-svc.yaml
kubectl apply -f ./
# 查看Web UI:
http://10.0.0.50:30090
自定义指标适配器 k8s-prometheus-adapter
PromQL接口无法直接作为自定义指标数据源,它不是聚合API服务器
需要使用 k8s-prometheus-adapter
# 配置ssl证书
cd /etc/kubernetes/pki/
(umask 077;openssl genrsa -out serving.key 2048)
openssl req -new -key serving.key -out serving.csr -subj "/CN=serving"
openssl x509 -req -in serving.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out serving.crt -days 3650
k8s-prometheus-adapter默认部署在custom-metrics名称空间,在该名称空间创建secret对象
证书和私钥键名为 serving.crt 和 serving.key
cd /etc/kubernetes/pki/
kubectl create namespace custom-metrics
kubectl create secret generic cm-adapter-serving-certs -n custom-metrics --from-file=serving.crt=./serving.crt --from-file=serving.key=./serving.key
git clone https://github.com/DirectXMan12/k8s-prometheus-adapter
cd k8s-prometheus-adapter/deploy/manifests/
# 编辑:custom-metrics-apiserver-deployment.yaml 第28行. 因为我的promethus部署在了kube-system名称空间中
--prometheus-url=http://prometheus.prom.svc:9090/ -> --prometheus-url=http://prometheus.kube-system.svc:9090/
# 查看API
kubectl api-versions | grep custom
# 列出指标名称
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq '.resources[].name'
# 查看pod内存占用率
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/*/memory_usage_bytes" | jq
HPA 自动弹性缩放
自动弹性伸缩工具 Auto Scaling:
- HPA,Horizontal Pod Autoscaler,两个版本,HPA仅支持CPU指标;HPAv2支持资源指标API和自定义指标API
- CA,Cluster Autoscaler,集群规模自动弹性伸缩,能自动增减节点数量,用于云环境
- VPA,Vertical Pod Autoscaler,Pod应用垂直伸缩工具,调整Pod对象的CPU和内存资源需求量完成扩展或收缩
- AR,Addon Resizer,简化版本的Pod应用垂直伸缩工具,基于集群中节点数量调整附加组件的资源需求量
Horizontal Pod Autoscaling可以根据CPU利用率(内存为不可压缩资源)自动伸缩一个Replication Controller、Deployment 或者Replica Set中的Pod数量;
HPA自身是一个控制循环,周期由 controller-manager的 --horizontal-pod-autoscaler-sync-period选项定义,默认为30s
对于未定义资源需求量的Pod对象,HPA控制器无法定义容器CPU利用率,且不会为该指标采取任何操作
对于每个Pod的自定义指标,HPA仅能处理原始值而非利用率
默认缩容延迟时长为5min,扩容延迟时长为3min,目的是防止出现抖动
目前HPA只支持两个版本,其中v1版本只支持核心指标的定义;
[root@master ~]# kubectl api-versions |grep autoscaling
autoscaling/v1 # 仅支持CPU一种资源指标的扩容
autoscaling/v2beta1 # 支持更多自定义资源指标的扩容
autoscaling/v2beta2 # 支持更多自定义资源指标的扩容
实验一: HPA
用命令行的方式创建一个带有资源限制的pod
kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=1 --requests='cpu=50m,memory=100Mi' --limits='cpu=50m,memory=100Mi' --labels='app=myapp' --expose --port=80
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-cf57cd7b-2r6q2 1/1 Running 0 2m3s
下面我们让myapp 这个pod能自动水平扩展
用kubectl autoscale,其实就是创建HPA控制器的
kubectl autoscale deployment myapp --min=1 --max=8 --cpu-percent=60
# --min:表示最小扩展pod的个数
# --max:表示最多扩展pod的个数
# --cpu-percent:cpu利用率
[root@master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp Deployment/myapp 0%/60% 1 8 1 4m14s
kubectl patch svc myapp -p '{"spec":{"type": "NodePort"}}'
kubectl get svc |grep myapp
# [root@master ~]# kubectl get svc |grep myapp
# myapp NodePort 10.99.246.253 <none> 80:31835/TCP 11m
#压测命令
ab -c 100 -n 500000000 http://10.0.0.51:30304/index.html
[root@master manifests]# kubectl describe hpa |grep -A 3 "resource cpu"
resource cpu on pods (as a percentage of request): 81% (40m) / 60%
Min replicas: 1
Max replicas: 8
Deployment pods: 3 current / 3 desired
[root@master manifests]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-cf57cd7b-2lqdx 1/1 Running 0 14m
myapp-cf57cd7b-bwm4h 1/1 Running 0 3m19s
myapp-cf57cd7b-fc5ns 1/1 Running 0 91s
# 压测结束五分钟后, 资源恢复到初始值
[root@master manifests]# kubectl describe hpa |grep -A 3 "resource cpu"
resource cpu on pods (as a percentage of request): 0% (0) / 60%
Min replicas: 1
Max replicas: 8
Deployment pods: 1 current / 1 desired
[root@master manifests]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-cf57cd7b-2lqdx 1/1 Running 0 22m
实验二: HPA v2
HPA(v2)支持从metrics-server中请求核心指标;从k8s-prometheus-adapter一类自定义API中获取自定义指标数据, 多个指标计算时,结果中数值较大的胜出

规则一
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp
spec:
scaleTargetRef: # 要缩放的目标资源
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50
- type: Resource
resource:
name: memory
targetAverageValue: 50Mi
metrics,计算所需Pod副本数量的指标列表,每个指标单独计算,取所有计算结果的最大值作为最终副本数量
- external: 引用非附属于任何对象的全局指标,可以是集群之外的组件的指标数据,如消息队列长度
- object: 引用描述集群中某单一对象的特定指标,如Ingress对象上的hits-per-second等
- pods: 引用当前被弹性伸缩的Pod对象的特定指标
- resource: 引用资源指标,即当前被弹性伸缩的Pod对象中容器的requests和limits中定义的指标
- type: 指标源的类型,可为Objects、Pods、Resource
规则二
ikubernetes/metrics-app 运行时会通过 /metrics路径输出 http_requests_total 和 http_requests_per_second 两个指标
注释 prometheus.io/scrape:"true" 使Pod对象能够被 Promethues采集相关指标
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: metrics-app
name: metrics-app
spec:
replicas: 2
selector:
matchLabels:
app: metrics-app
template:
metadata:
labels:
app: metrics-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics"
spec:
containers:
- image: ikubernetes/metrics-app
name: metrics-app
ports:
- name: web
containerPort: 80
resources:
requests:
cpu: 200m
memory: 256Mi
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: metrics-app
labels:
app: metrics-app
spec:
ports:
- name: web
port: 80
targetPort: 80
selector:
app: metrics-app
curl 10.98.175.207/metrics # IP为上一个文件创建的service IP
创建HPA
Prometheus通过服务发现机制发现新创建的Pod对象,根据注释提供的配置信息识别指标并纳入采集对象,而后由k8s-prometheus-adapter将这些指标注册到自定义API中,提供给HPA(v2)控制器和调度器等作为调度评估参数使用
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: metrics-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: metrics-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: http_requests_per_second
targetAverageValue: 800m # 800m 即0.8个/秒
# 压测命令
while true; do curl 10.98.175.207/metrics &>/dev/null; sleep 0.1; done # IP为service IP
压测结果
[root@master ~]# kubectl describe hpa metrics-app-hpa |grep -A 4 Metrics
Metrics: ( current / target )
"http_requests_per_second" on pods: 4350m / 800m
Min replicas: 2
Max replicas: 10
Deployment pods: 10 current / 10 desired
添加自定义指标 http_requests_per_second
编辑k8s-prometheus-adapter/deploy/manifests/custom-metrics-config-map.yaml添加规则:
rules:
- seriesQuery: 'http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'
自定义规则参考文档:
将prometheus指标升级为k8s自定义指标,需要定义规则
- https://github.com/DirectXMan12/k8s-prometheus-adapter/blob/master/docs/config-walkthrough.md
- https://github.com/DirectXMan12/k8s-prometheus-adapter/blob/master/docs/walkthrough.md
将 http_requests_total 命令为 http_requests_per_second 自定义指标
让配置生效:
需要先应用 custom-metrics-config-map.yaml 然后手动删除 custom-metrics 空间下 custom-metrics-apiserver-xxxx Pod
注意:修改config-map后,不删除Pod,不会生效
测试:
kubectl get pods -w
curl 10.104.226.230/metrics
kubectl run client -it --image=cirros --rm -- /bin/sh
while true; do curl http://metrics-app; let i++; sleep 0.$RANDOM; done # 模拟压力
测试需要达到数分钟后才能看到自动扩容,原因是:默认缩容延迟时长为5min,扩容延迟时长为3min
参考链接
https://www.cnblogs.com/fawaikuangtu123/p/11296510.html
https://www.qingtingip.com/h_252011.html
https://www.servicemesher.com/blog/prometheus-operator-manual/
https://www.cnblogs.com/centos-python/articles/10921991.html
https://pdf.us/tag/docker

 浙公网安备 33010602011771号
浙公网安备 33010602011771号