Prometheus在Linux主机的安装
目录
第二步:在192.168.248.11 上安装Prometheus
第四步:在192.168.248.11 上安装Grafana
第五步:在Prometheus服务器上安装alermanager
准备一台Prometheus服务器 192.168.248.11
一台被监控服务器 192.168.248.12
安装Prometheus服务
tar -xzf go1.8.3.linux-amd64.tar.gz -C /usr/local
vim /etc/profile
#在文件最下面添加go环境
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export PATH=$PATH:/usr/local/go/bin

#保存退出后,让配置文件生效:
source /etc/profile
#验证是否成功
go version

#去官网下载对应的系统的版本,官方地址:https://prometheus.io/download/
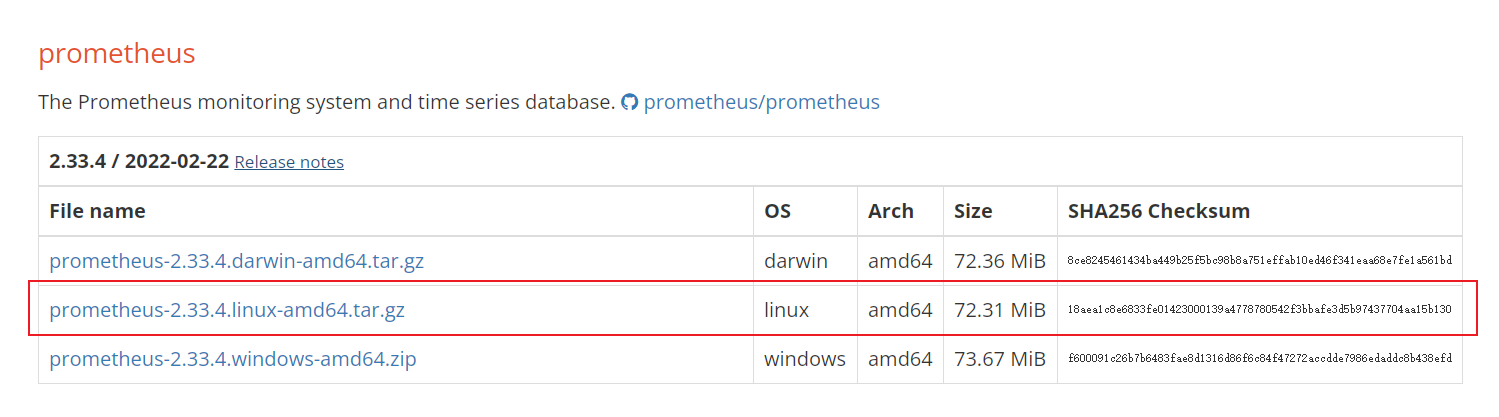
#传入服务器,解压到/usr/local
tar -vxf prometheus-2.33.4.linux-amd64.tar.gz -C /usr/local
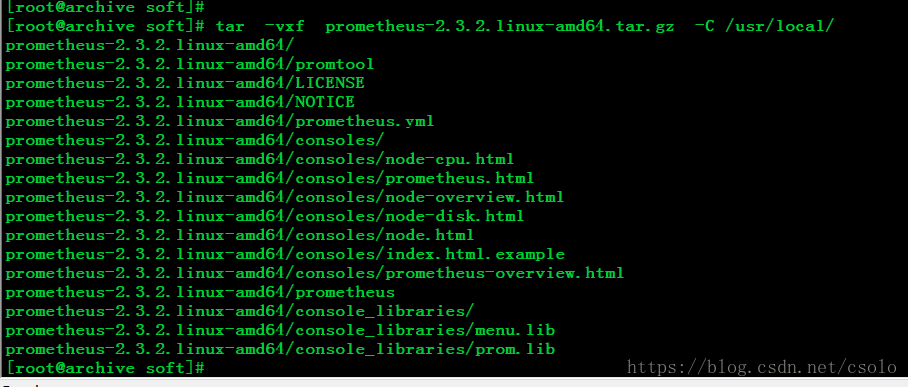
#为了以后方便进入目录,可以做个软连接
ln -sv /usr/local/prometheus-2.33.4.linux-amd64.tar.gz -C /usr/local/Prometheus
#配置监控的配置文件:prometheus.yml
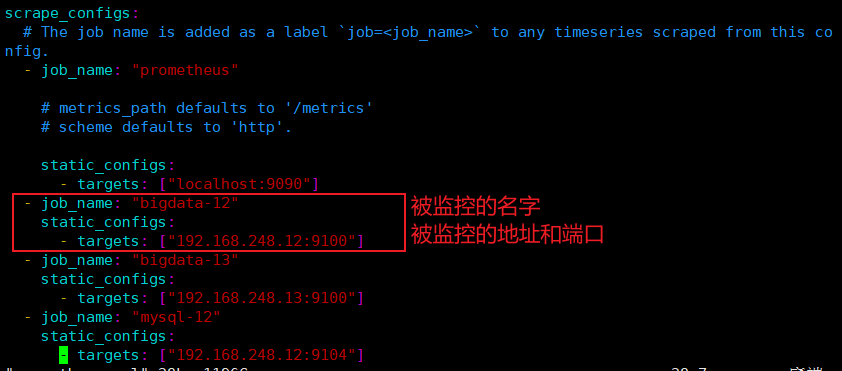
#运行该文件
cd /usr/local/Prometheus
./prometheus
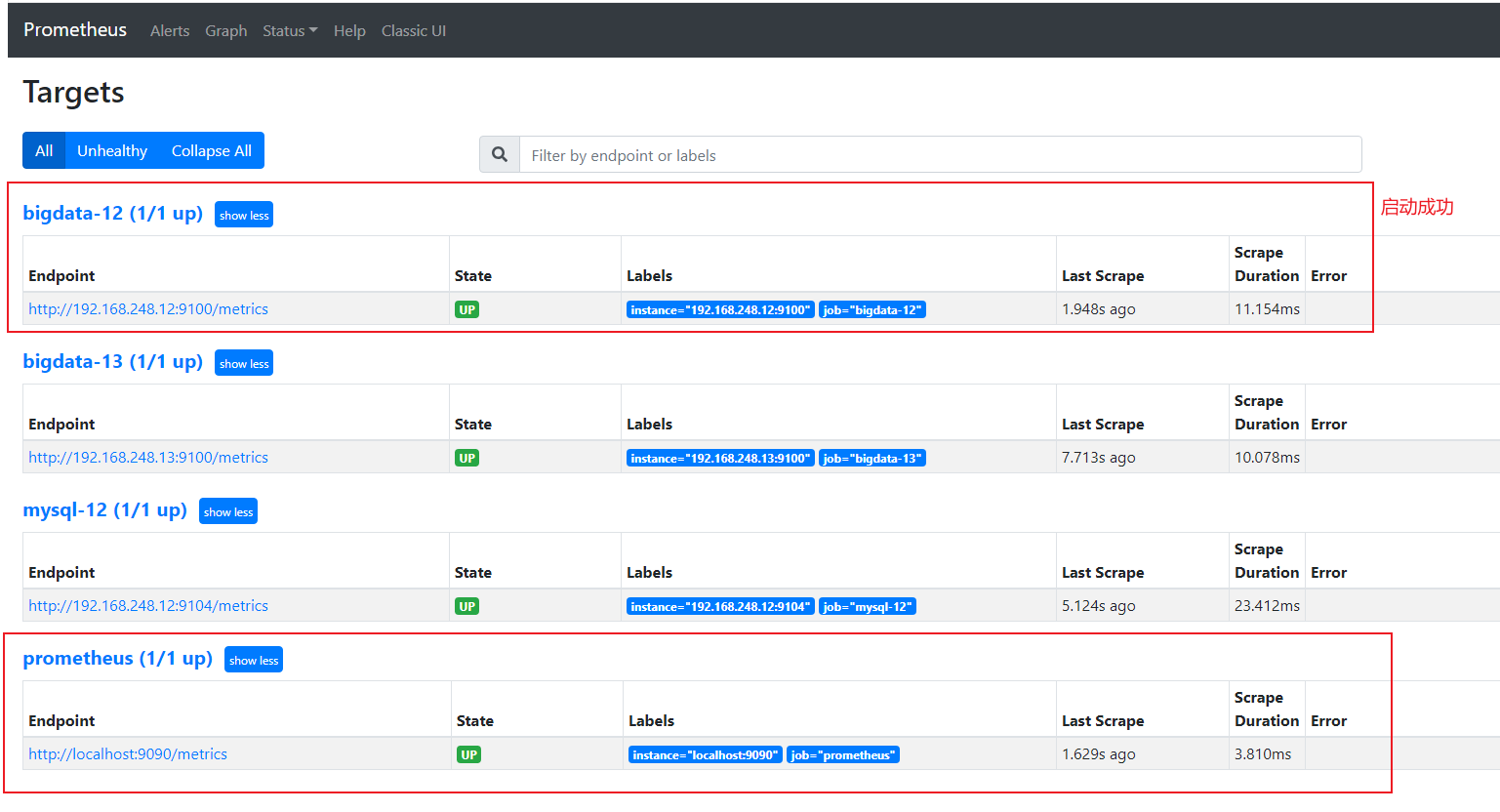
#通过url 192.168.248.11:9090,点击targets跳转到监控目标
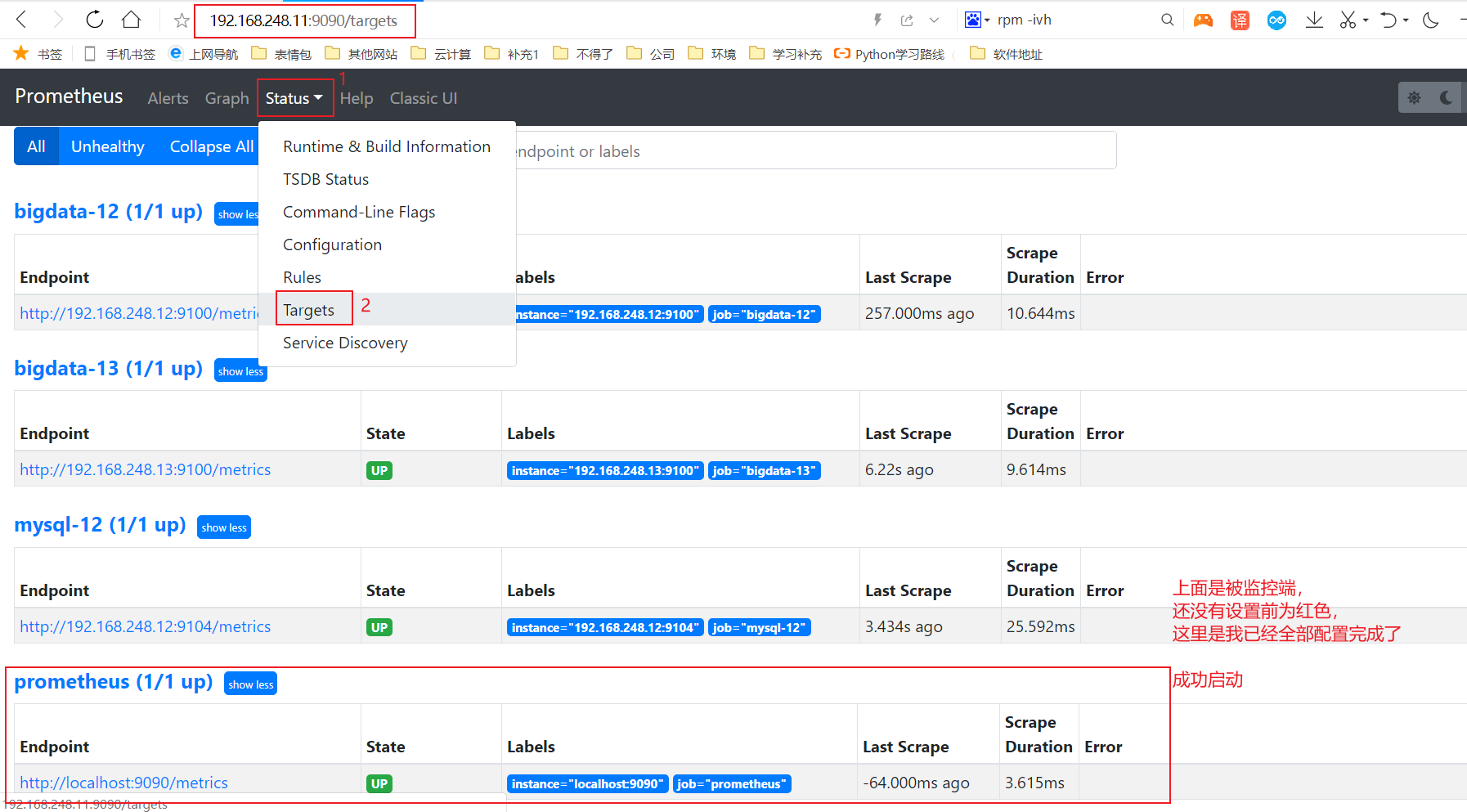
#主机数据展示
#在web主页面可以通过关键字查询监控项
#补充:可以将Prometheus服务放入系统服务里,使用systemctl启动
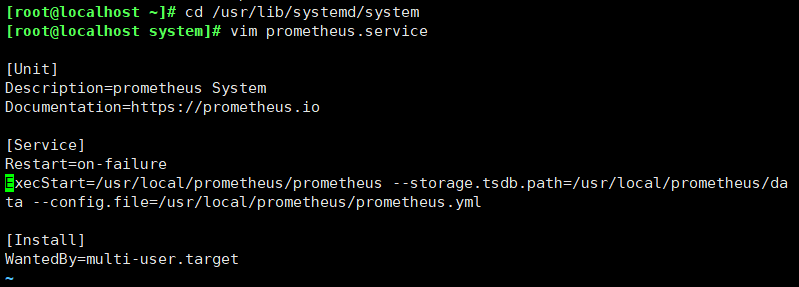
cd /usr/lib/systemd/system
vim prometheus.service
[Unit] Description=prometheus System Documentation=https://prometheus.io [Service] Restart=on-failure ExecStart=/usr/local/prometheus/prometheus --storage.tsdb.path=/usr/local/prometheus/data --config.file=/usr/local/prometheus/prometheus.yml [Install] WantedBy=multi-user.target
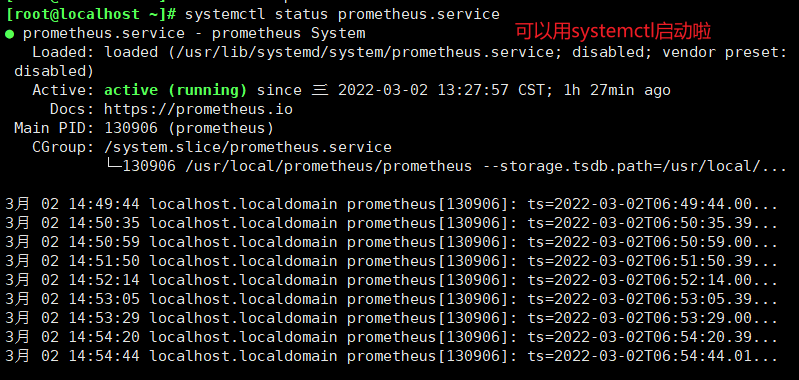
#在远程linux主机(被监控端安装node_exporter组件)
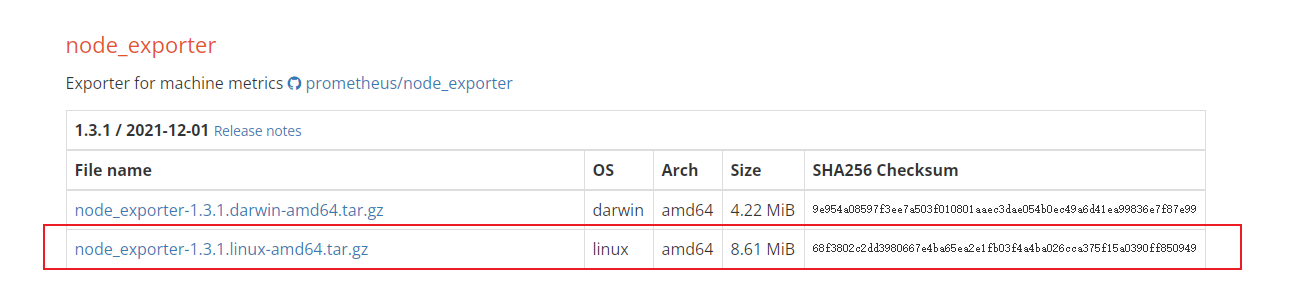
tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/node_exporter-0.16.0.linux-amd64/ /usr/local/node_exporter
#包里只有一个启动命令node_exporter,可以直接使用此命令启动
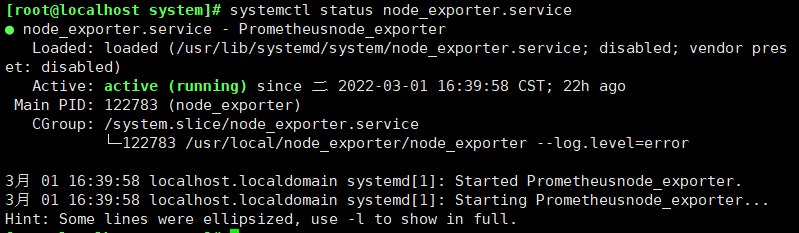
nohup /usr/local/node_exporter/node_exporter &

#再开一个终端,确认9100的端口

#Tip:nohup命令:如果把启动node_exporter的终端给关闭,那么进程也会随之关闭。nohup命令会帮我们解决这个问题
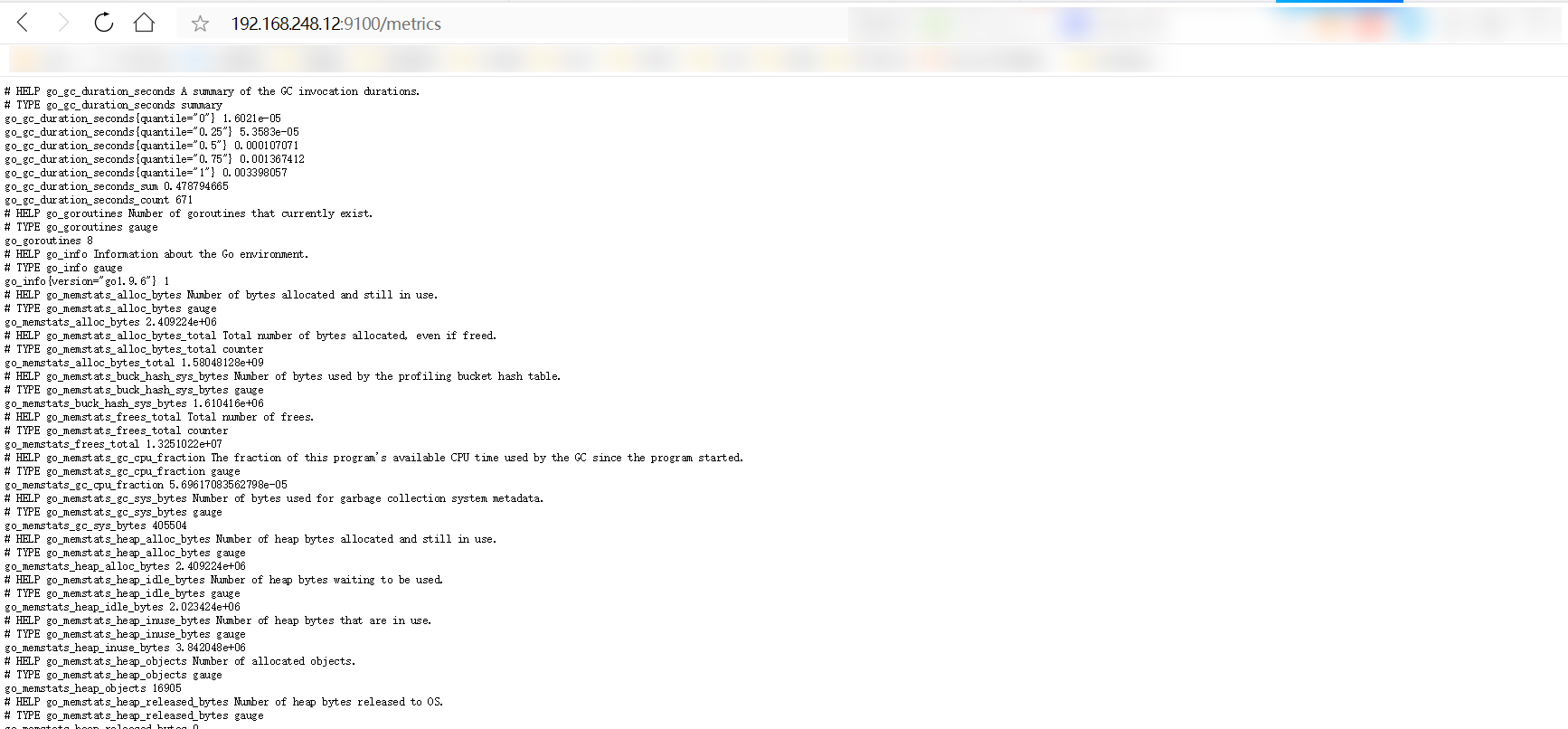
#通过访问192.168.248.12:9100/metrics可以查看node_exporter在被监控端收集的监控信息
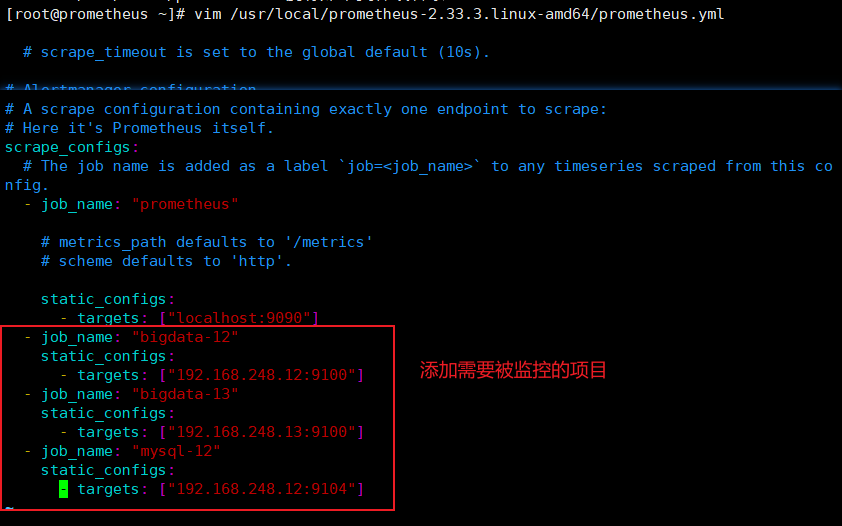
#在192.168.248.11这台服务器的配置文件里添加被监控及其的配置段
#重启服务,先关闭上次打开的进程
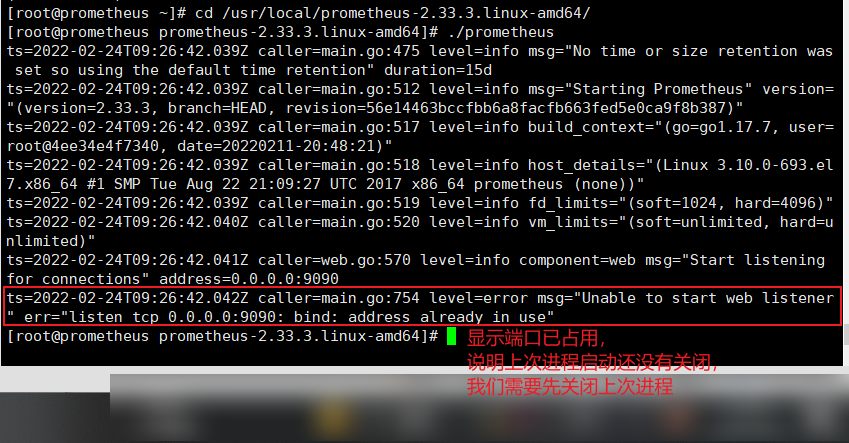
#在192.168.248.11这台服务器 lsof -i:9090
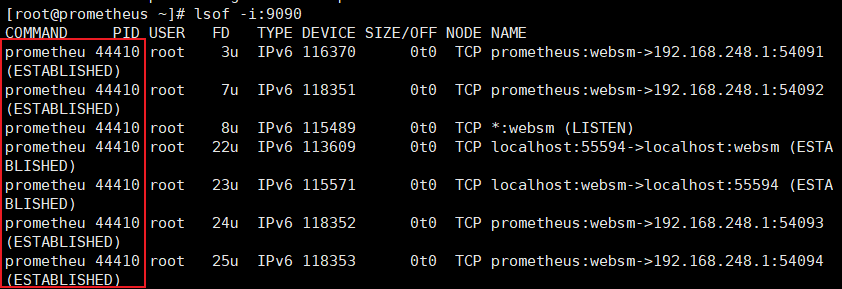
kill -9 44410
cd /usr/local/Prometheus
./prometheus
#贴士:可以将node exporter加入系统启动
cd /usr/lib/systemd/system
vim node_exporter.service
[Unit] Description=Prometheusnode_exporter [Service] User=nobody ExecStart=/usr/local/node_exporter/node_exporter --log.level=error ExecStop=/usr/bin/killallnode_exporter [Install] WantedBy=default.target
rpm -ivh grafana-5.3.4-1.x86_64.rpm
## sudo yum install grafana-enterprise-7.2.0-1.x86_64.rpm
systemctl start grafana-server
systemctl enable grafana-server
#检查端口 lsof -i:3000
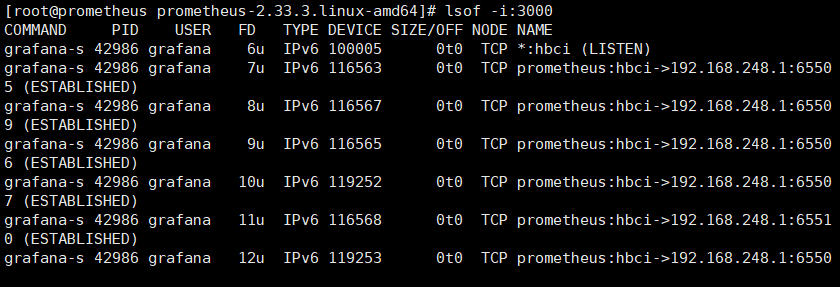
#浏览器访问192.168.248.11:3000

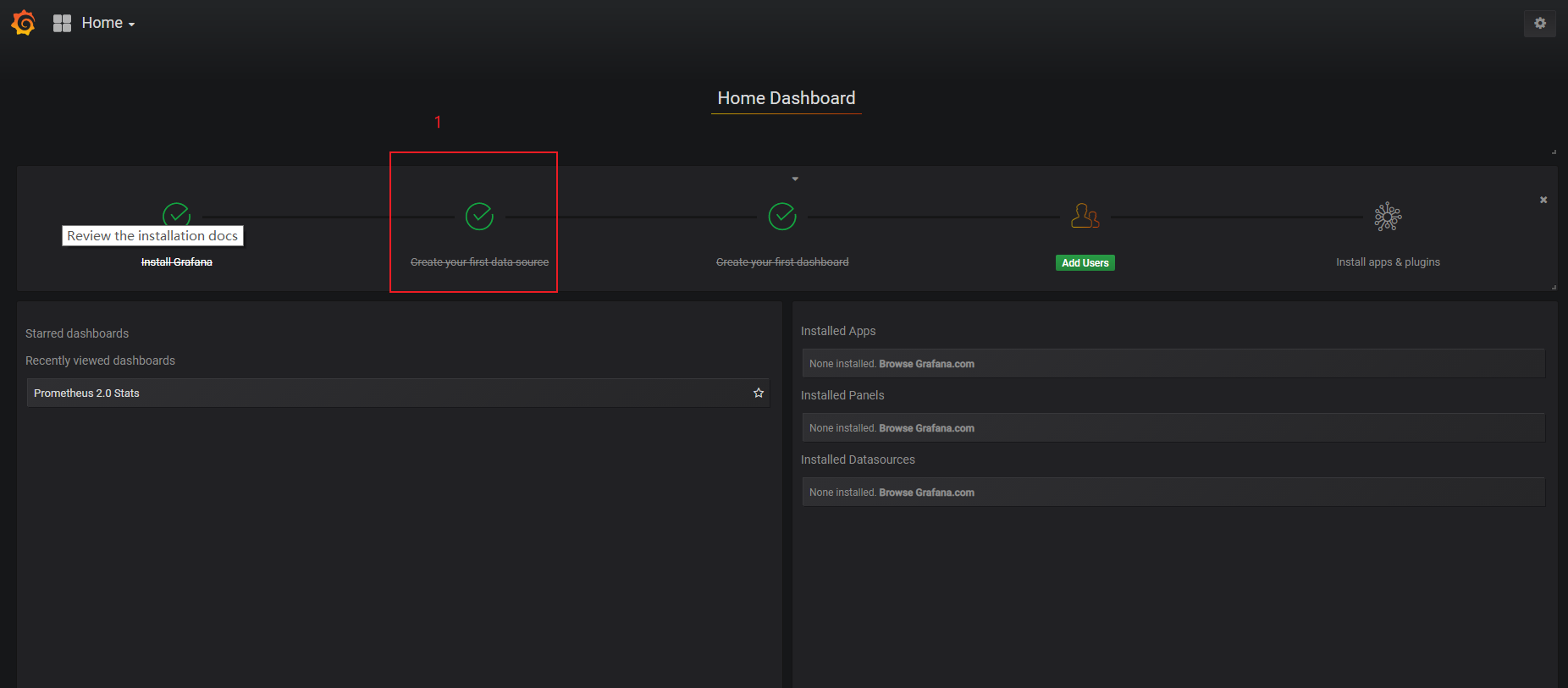
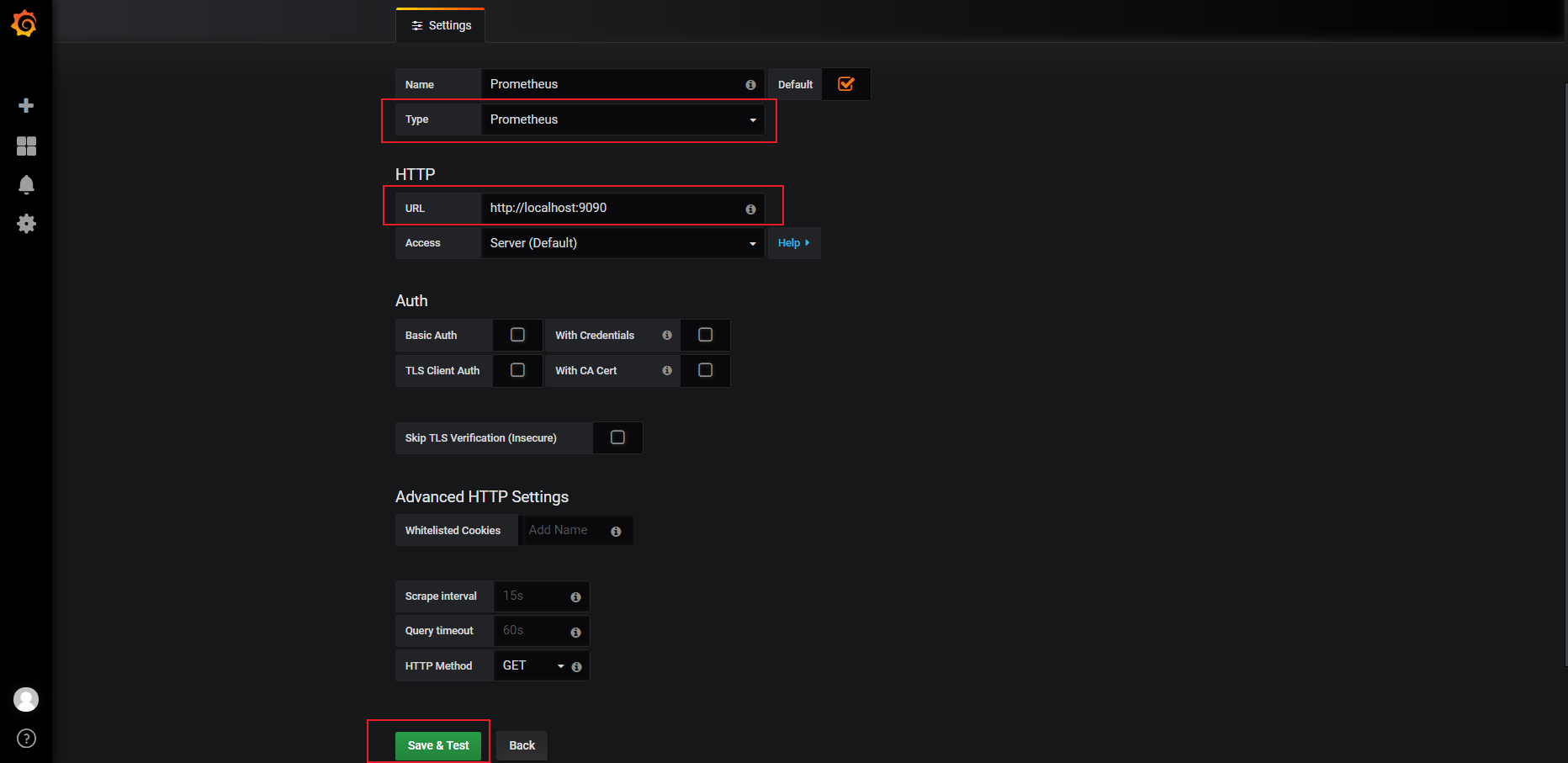
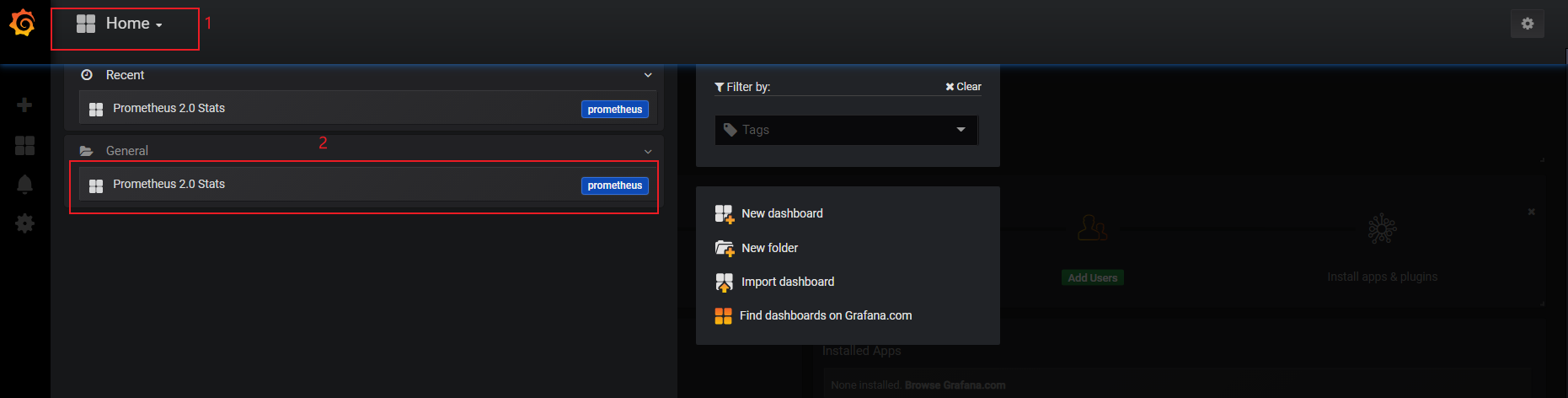
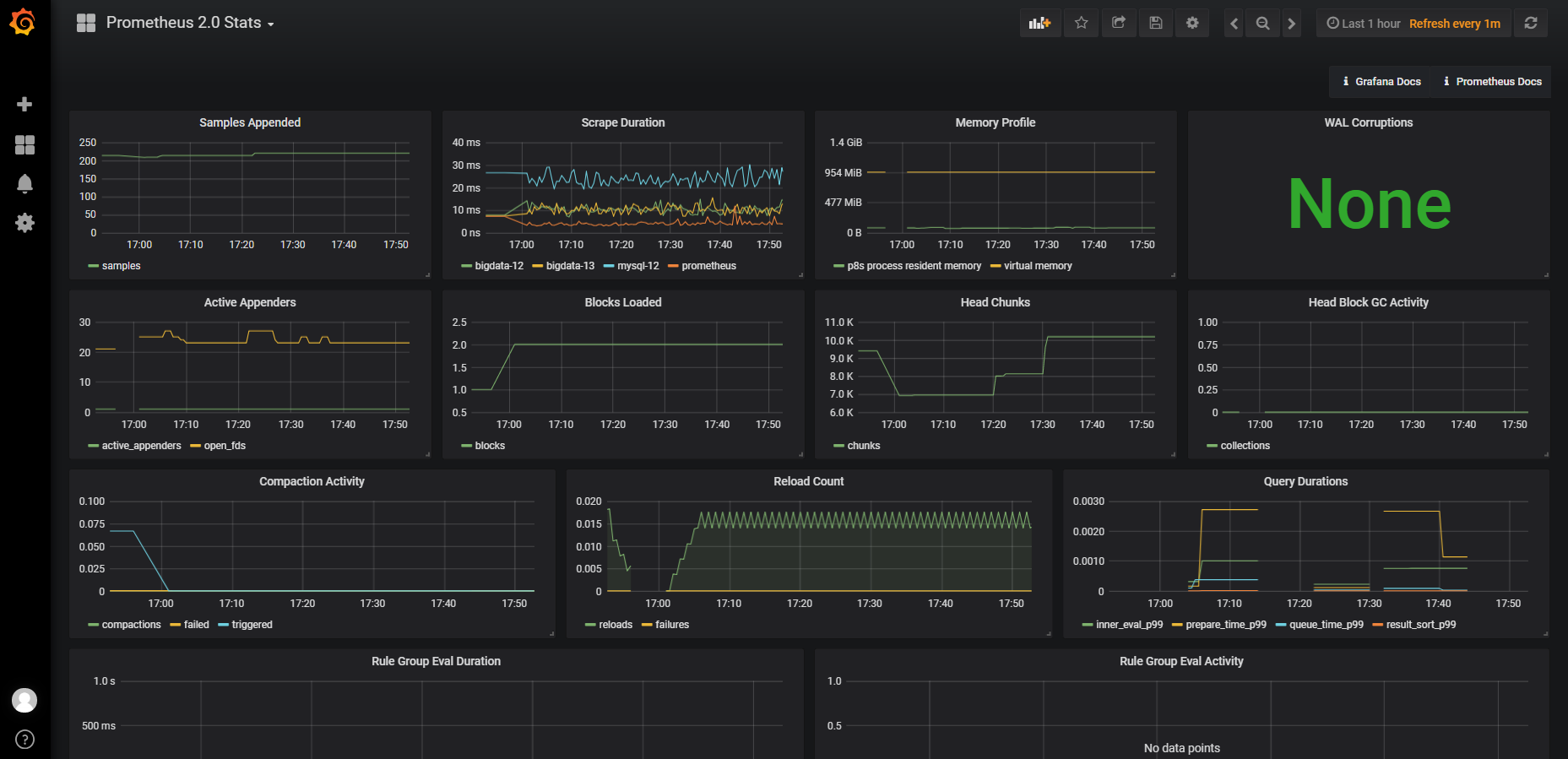
#配置dashboard
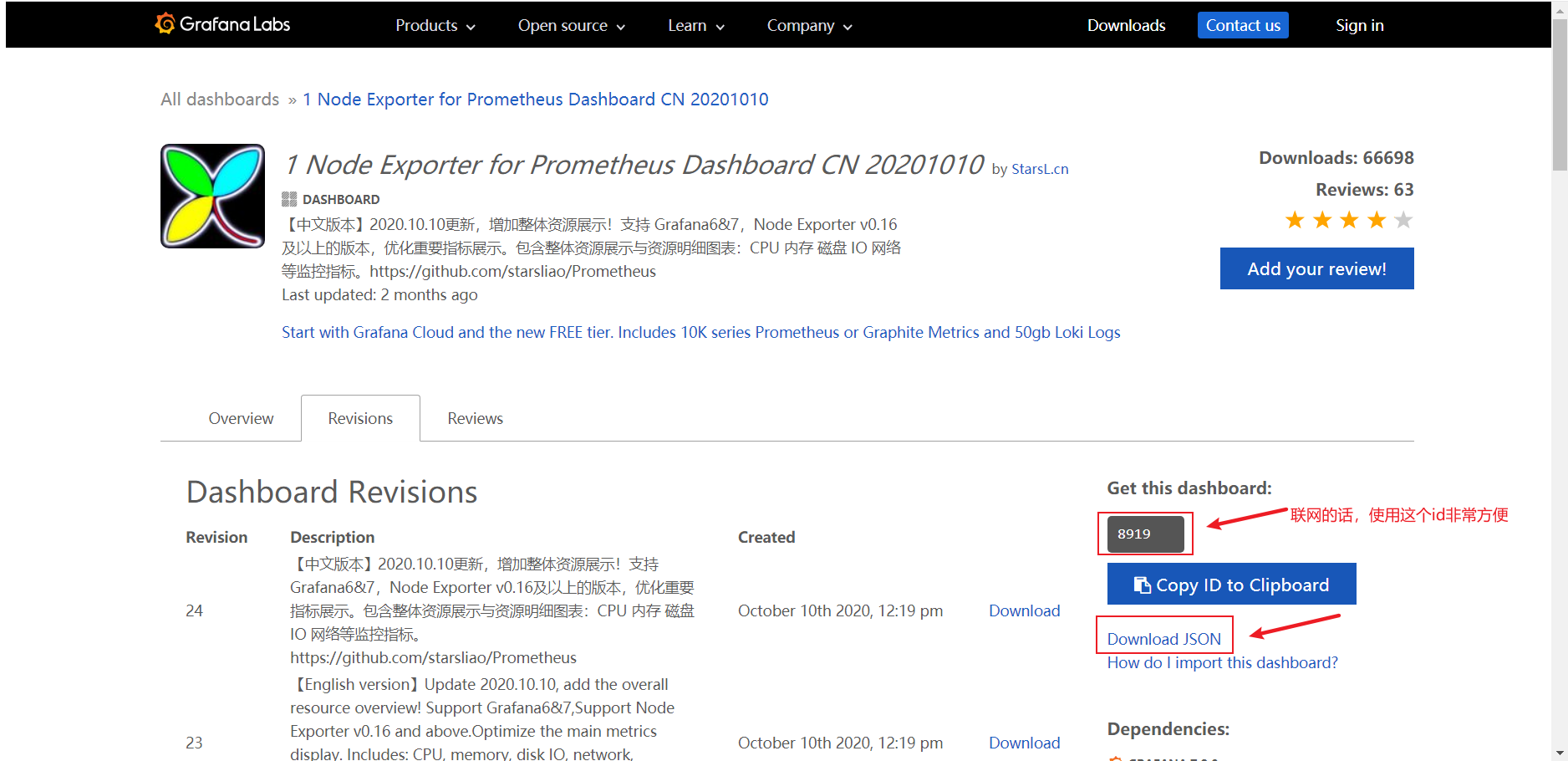
#登录grafana的dashboard平台,查询所需的json文件,地址:https://grafana.com/grafana/dashboards
#去官网寻找对应的表盘,这里选择node exporter监控看板
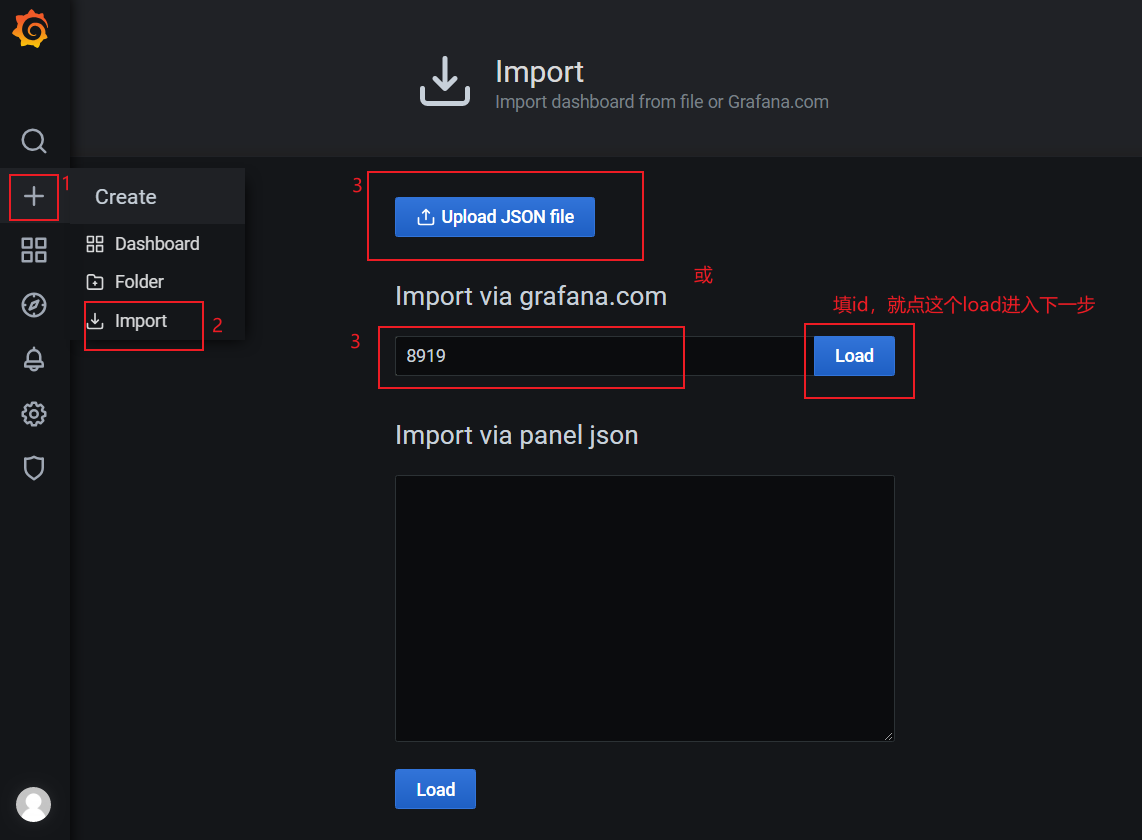
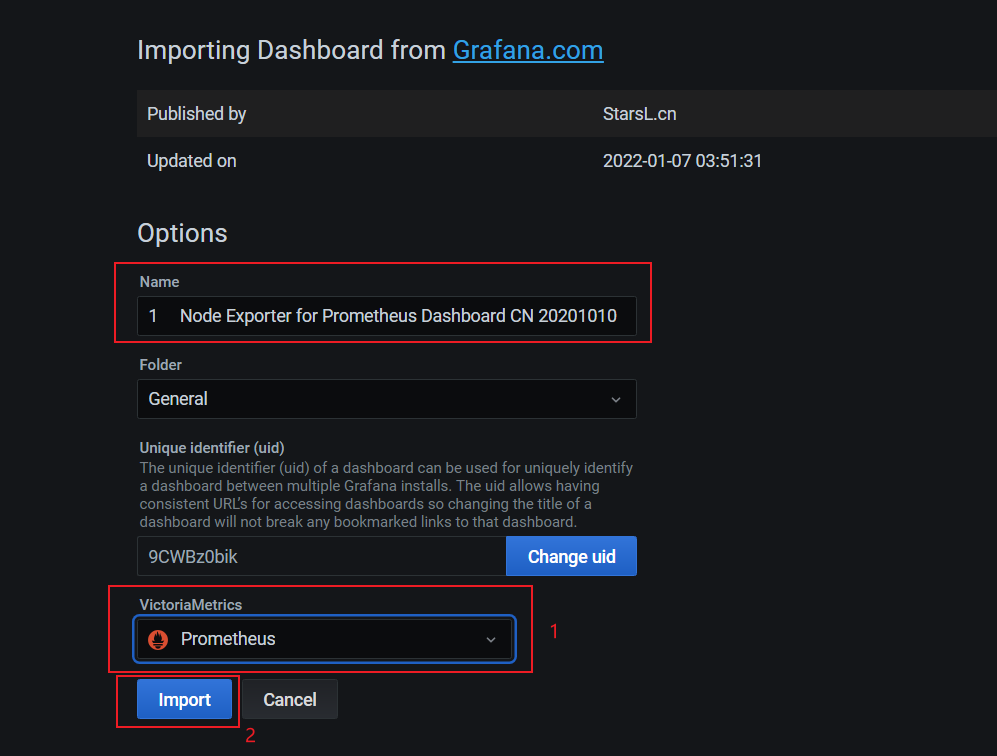
#在grafana中导入表盘
#访问https://grafana.com/grafana/dashboards/8919/revisions 下载最小的json,或copy对应id
#grafana的dashboard安装成功界面展示
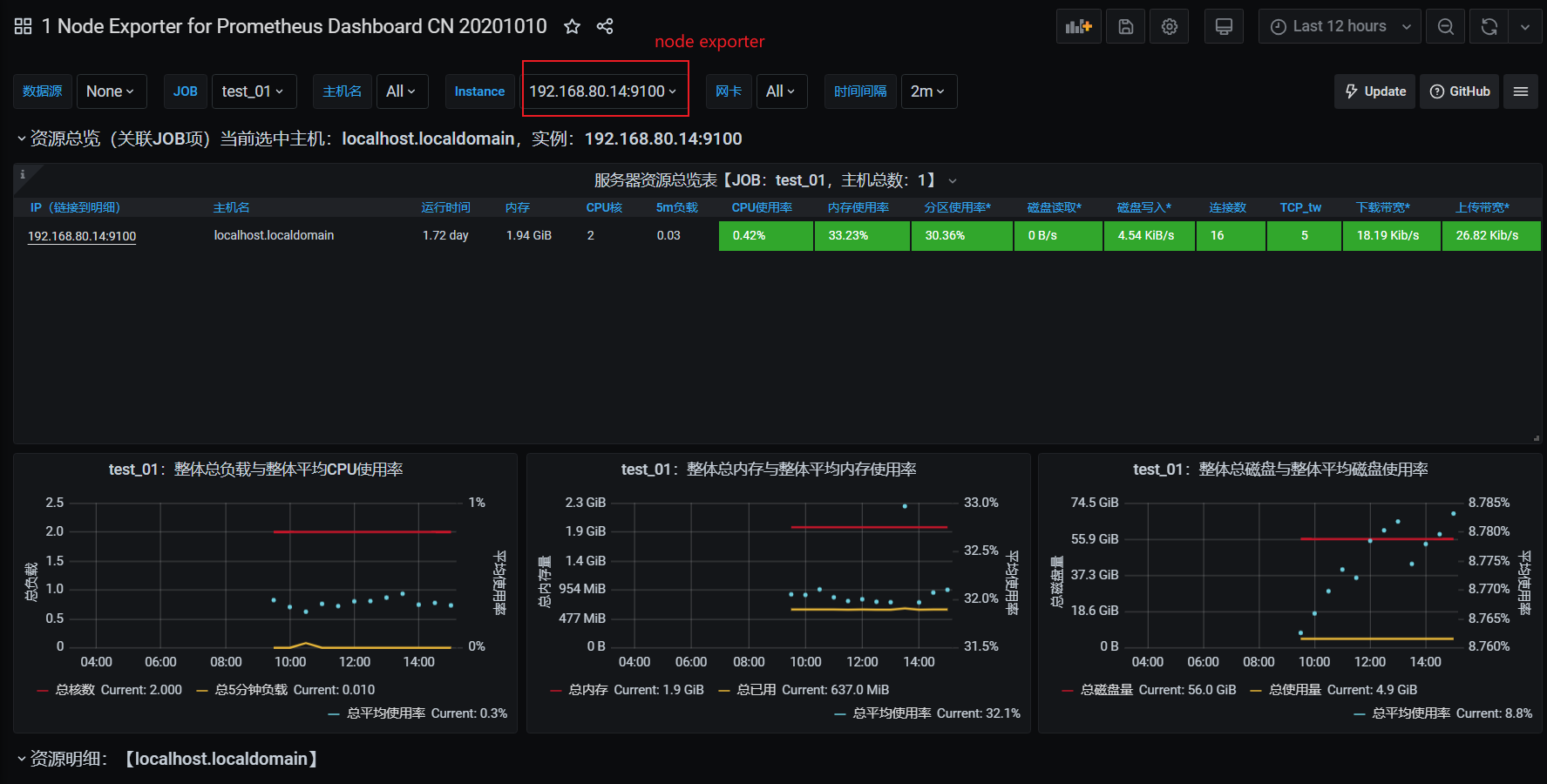
==================Prometheus+Grafana安装完成============================
#在192.168.248.12 上安装mysql并加入Prometheus的监控
#下载
#解压:
tar xf mysqld_exporter-0.11.0.linux-amd64.tar.gz -C /usr/local/
#创建一个mysql配置文件,写上连接的用户名和密码(这个用户需要被授予远程访问的权限)
vim /usr/local/mysqld_exporter-0.11.0.linux-amd64/.my.cnf
[client]
user=abc
password=123456
#启动mysql的监控
nohup /usr/local/mysqld_exporter-0.11.0.linux-amd64/mysqld_exporter --config.my.cnf=/usr/local/mysqld_exporter-0.11.0.linux-amd64/.my.cnf &
#将mysql的监控配置到192.168.248.11上
cd /usr/local/Prometheus
vim /prometheus.yml
#文件末尾添加如下内容,注意缩进
- job_name:'agent_mysql'
static_configs:
- targets:['192.168.246.12:9104']
#杀死原进程,再启动新进程
lsof -i:9090
cd /usr/local/Prometheus
./prometheus
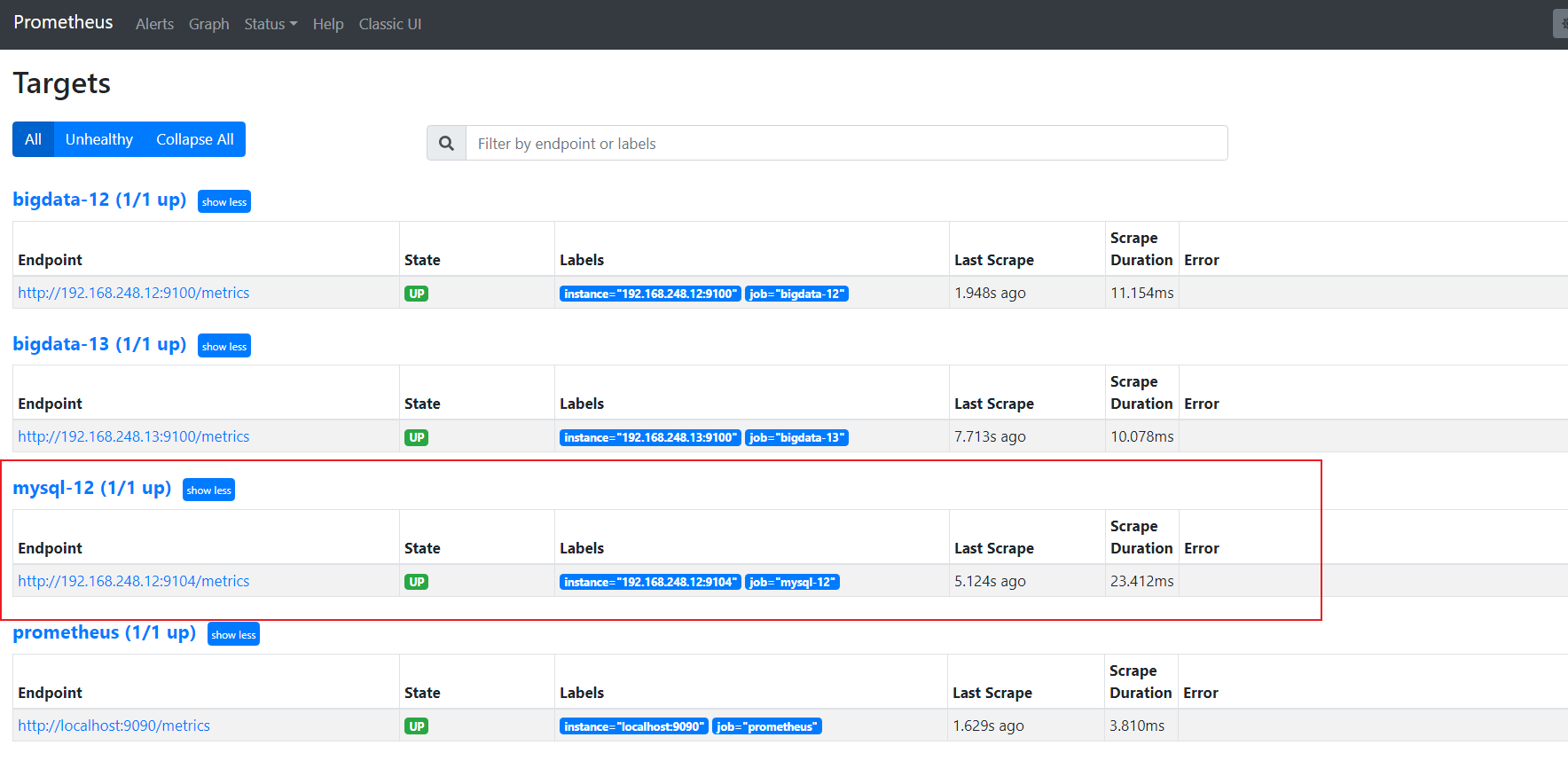
=======================mysql添加到Prometheus完成=========================
上面的Prometheus服务安排在192.168.80.11上,下面的统一安排在192.168.80.14上
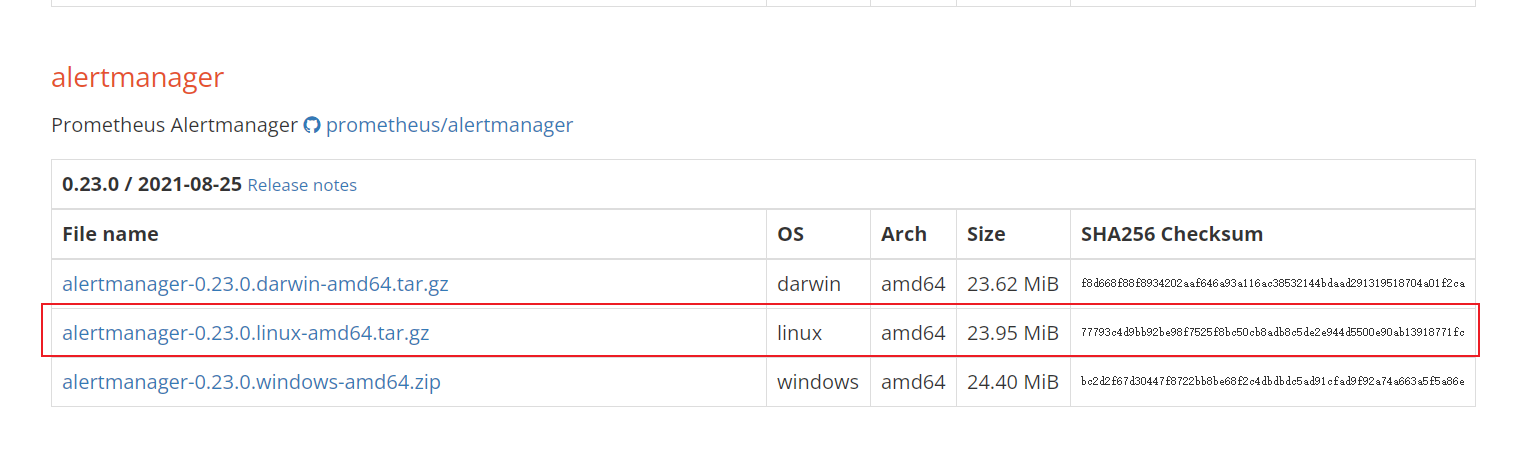
#或者
tar -zxvf alertmanager-0.21.0.linux-amd64.tar.gz
mv alertmanager-0.21.0.linux-amd64 /usr/local/alertmanager
#我这里用的是0.23.0的版本
#修改配置文件
cd /usr/local/alertmanager
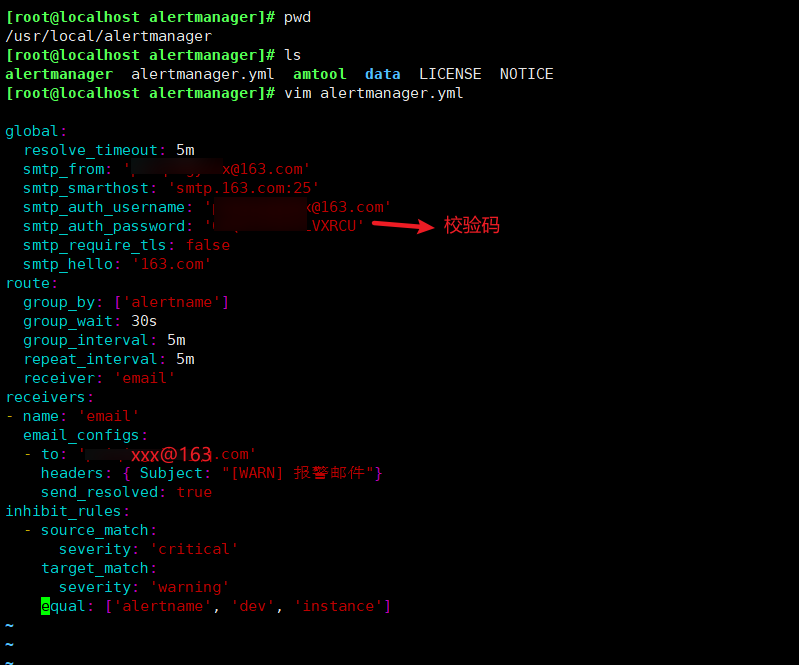
vim alertmanager.yml
global: resolve_timeout: 5m smtp_from: '17****818@qq.com' #邮箱地址 smtp_smarthost: 'smtp.qq.com:465' #邮箱smtp服务器代理 smtp_auth_username: '17*****718@qq.com' # 邮箱名称 smtp_auth_password: '*****' #授权码 smtp_require_tls: false smtp_hello: 'qq.com' route: group_by: ['alertname'] #报警分组依据 group_wait: 5s #最初即第一次等待多久时间发送一组警报的通知 group_interval: 5s # 在发送新警报前的等待时间 repeat_interval: 30m # 发送重复警报的周期 对于email配置中,此项不可以设置过低,>否则将会由于邮件发送太多频繁,被smtp服务器拒绝 receiver: 'email' # 发送警报的接收者的名称,以下receivers name的名称 receivers: - name: 'email' email_configs: # 邮箱配置 - to: '17*****8@qq.com' # 接收警报的email配置 headers: { Subject: "[WARN] 报警邮件"} # 接收邮件的标题 send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
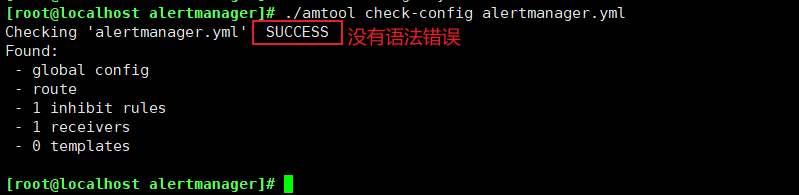
#检测yml文件是否有语法错误
./amtool check-config alertmanager.yml
#启动alertmanager
cd /usr/local/alertmanager
./alertmanager
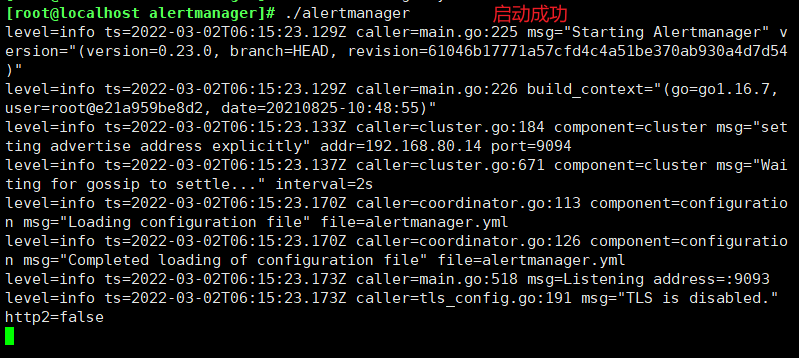
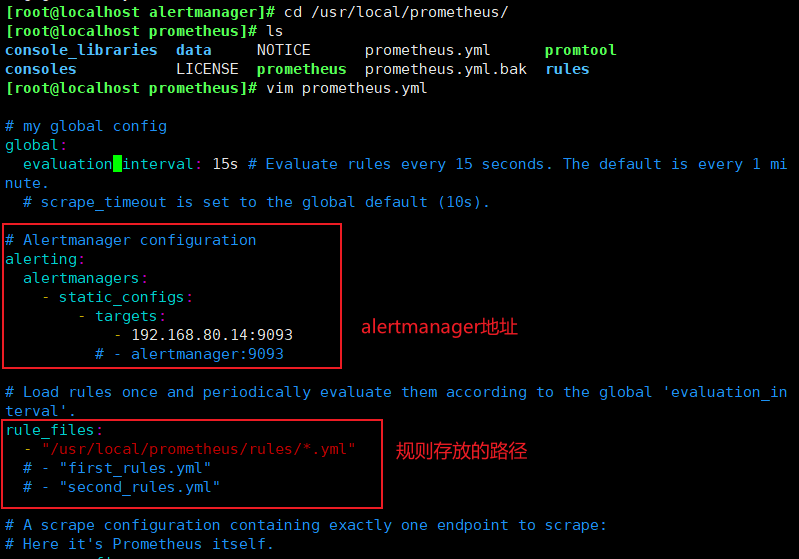
#修改Prometheus配置文件
cd /usr/local/prometheus/
vim prometheus.yml
cd /usr/local/prometheus vim prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: ['localhost:9093'] #alermanager地址 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "/usr/local/prometheus/rules/*.yml" #规则存放路径 # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
#创建rules规则目录
cd /usr/local/prometheus
mkdir rules
cd rules
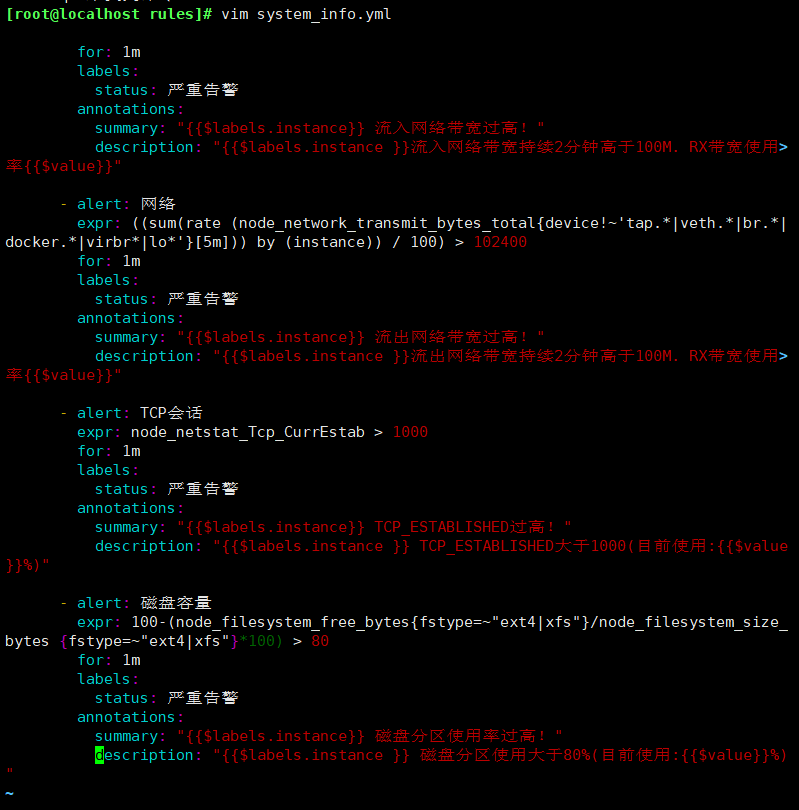
#添加报警规则
vim system_info.yml
groups: - name: 主机状态-监控告警 rules: - alert: 主机状态 expr: up == 0 for: 5m labels: status: 非常严重 annotations: summary: "{{$labels.instance}}:服务器宕机" description: "{{$labels.instance}}:服务器延时超过5分钟" - alert: CPU使用情况 expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 80 for: 1m labels: status: 一般告警 annotations: summary: "{{$labels.instance}} CPU使用率过高!" description: "{{$labels.instance }} CPU使用大于80%(目前使用:{{$value}}%)" - alert: 内存使用 expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80 for: 1m labels: status: 严重告警 annotations: summary: "{{$labels.instance}} 内存使用率过高!" description: "{{$labels.instance }} 内存使用大于80%(目前使用:{{$value}}%)" - alert: IO性能 expr: (avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) > 80 for: 1m labels: status: 严重告警 annotations: summary: "{{$labels.instance}} 流入磁盘IO使用率过高!" description: "{{$labels.instance }} 流入磁盘IO大于80%(目前使用:{{$value}})" - alert: 网络 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 1m labels: status: 严重告警 annotations: summary: "{{$labels.instance}} 流入网络带宽过高!" description: "{{$labels.instance }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}" - alert: 网络 expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 1m labels: status: 严重告警 annotations: summary: "{{$labels.instance}} 流出网络带宽过高!" description: "{{$labels.instance }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话 expr: node_netstat_Tcp_CurrEstab > 1000 for: 1m labels: status: 严重告警 annotations: summary: "{{$labels.instance}} TCP_ESTABLISHED过高!" description: "{{$labels.instance }} TCP_ESTABLISHED大于1000(目前使用:{{$value}}%)" - alert: 磁盘容量 expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80 for: 1m labels: status: 严重告警 annotations: summary: "{{$labels.instance}} 磁盘分区使用率过高!" description: "{{$labels.instance }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
#重启Prometheus服务
systemctl restart prometheus
#进浏览器查看警报
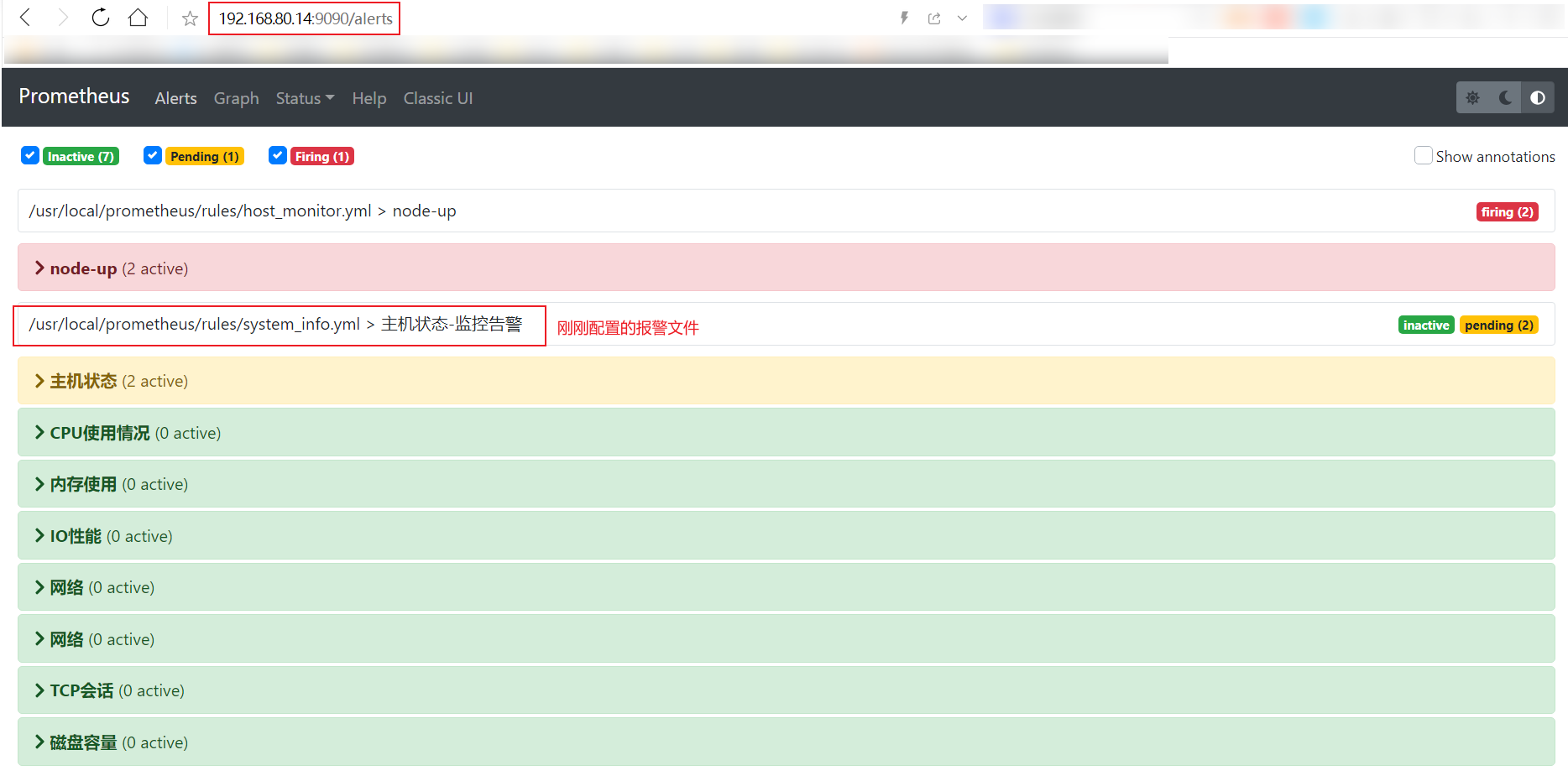
#邮箱展示(由于我这里邮箱名字给错了,所有显示发送失败
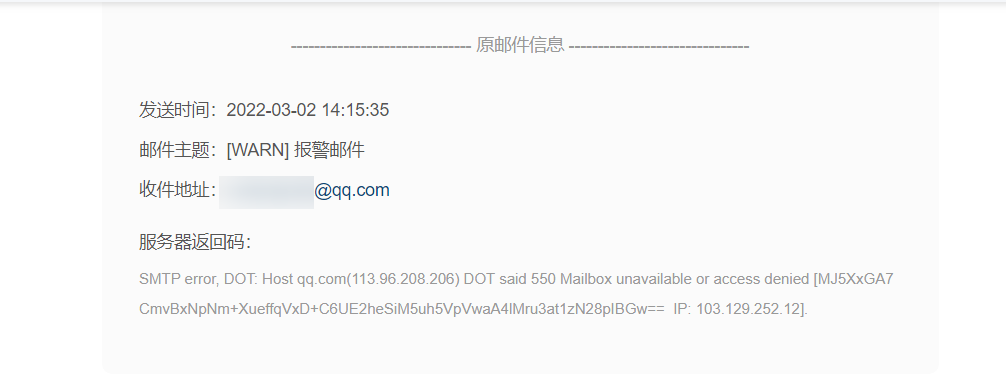
=================================alertmanager报警配置完成============================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号