

Shell——数组
目录
1、数组的定义方法
数组名=(元素1 元素2 元素3 ……元素n)
- 使用括号包含数组中的元素,每个元素都有各自索引(从0开始)元素可以是字符串或者数字
方法一:
数组名=(value0 value1 value2 ……)

方法二:
数组名=([0]=value [1]=value [2]=value ……)

方法三:
列表名="value0 value1 value2 ……"
数组名=($列表名)

方法四:
数组名[0]="value"
数组名[1]="value"
数组名[2]="value"
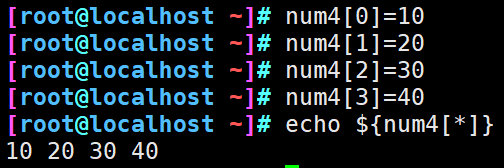
2、数组包括的数据类型
- 数值类型
- 字符类型
使用" "或' '定义
3、获取数组长度


4、获取数据列表

5、读取某索引赋值
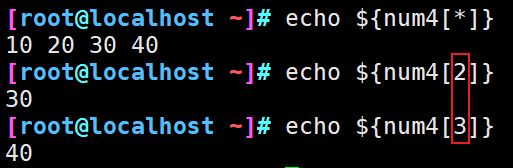
6、数组遍历

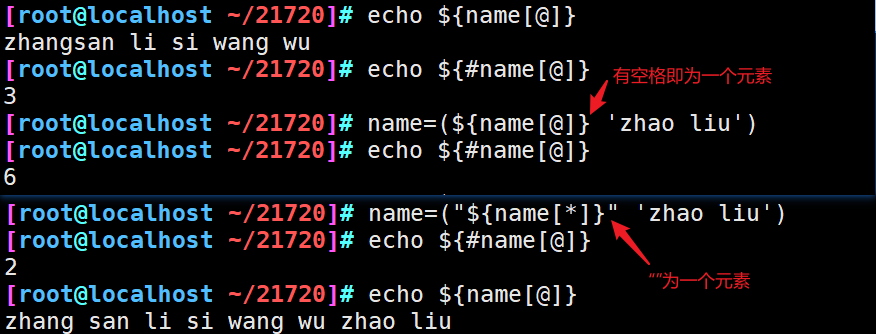
7、数组切片
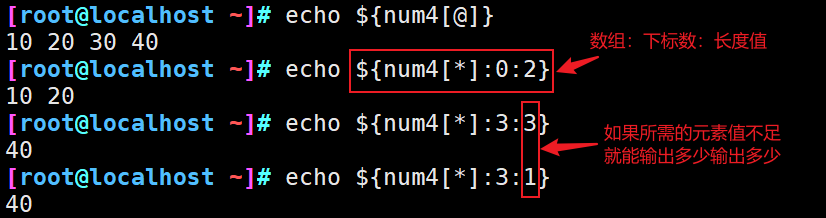
8、数组替换
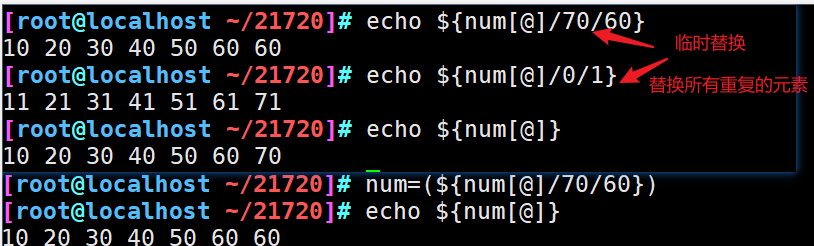

9、数组删除
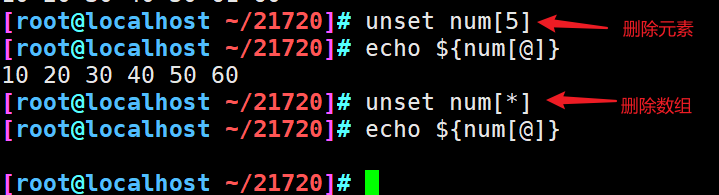
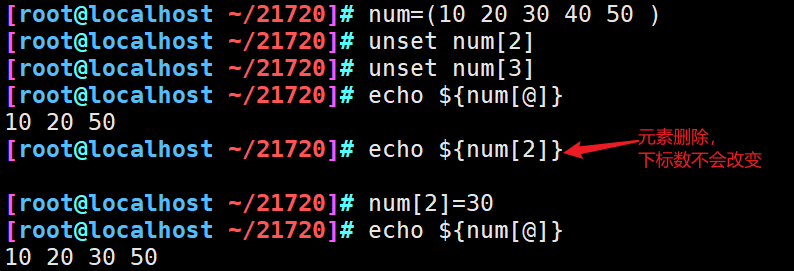
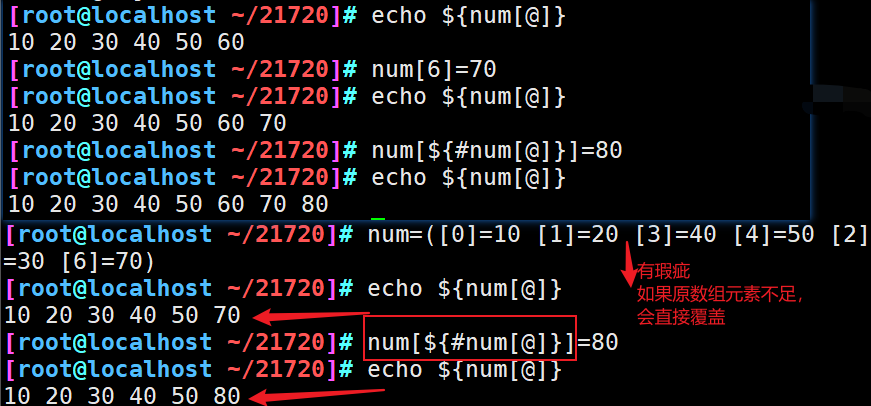
10、数组追加元素
方法一:按照索引进行逐个添加
array_name[index]=value
方法二:按照最大索引值进行向后添加
array_name[${#array_name[@]}]=value
方法三:使用原数组的元素进行重新赋值
array_name=("${#array_name[@]}" value1 value2 ... valueN)
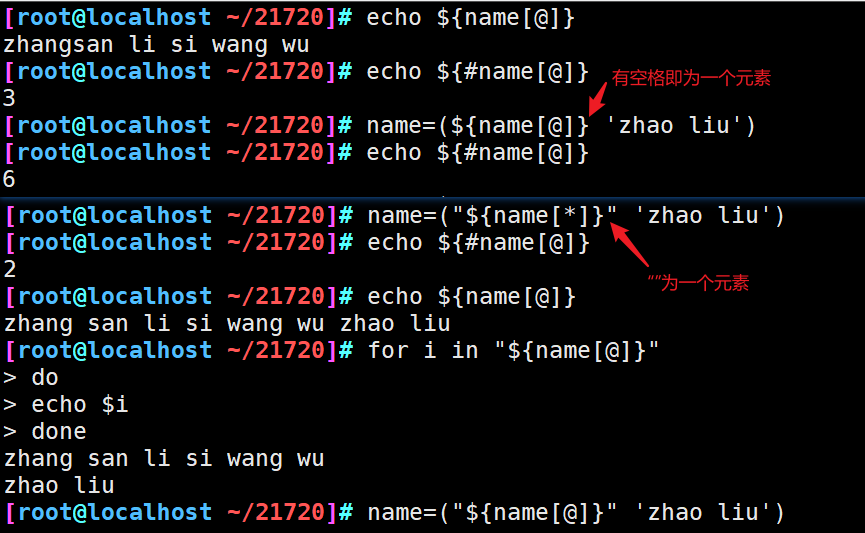
注:
双引号不能省略,否则数组中存在包含空格的元素时会按空格将元素拆分成多个
不能将“@”替换为“*”,如果替换为“*”,不加双引号时与“@”的表现一致,加双引号时,会将数组array_name中的所有元素作为一个元素添加到数组中
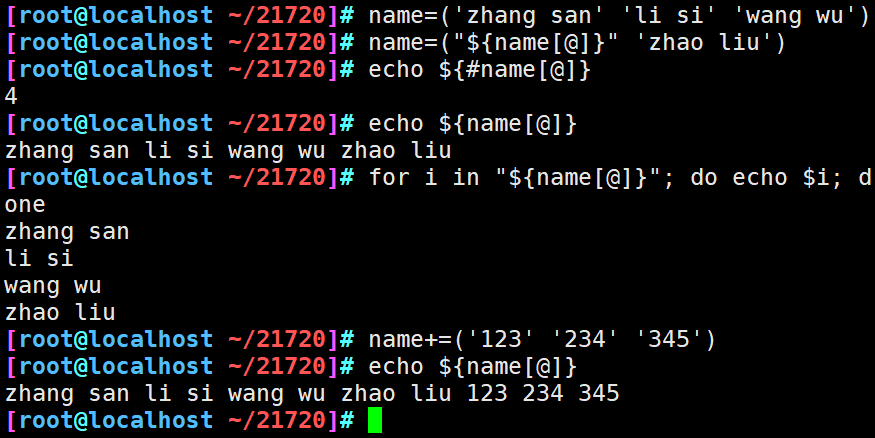
方法四:
array_name+=(value1 value2 ... valueN)
注:待添加元素必须用“()”包围起来,并且多个元素用空格分隔
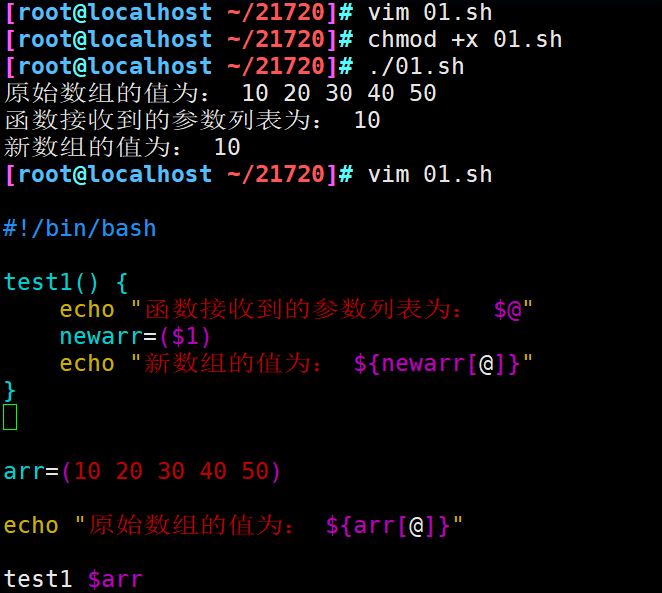
向函数传数组参数
如果将数组变量作为函数参数,函数只会取数组变量的第一个值
#!/bin/bash test1() { echo "函数接收到的参数列表为: $@" newarr=($1) echo "新数组的值为: ${newarr[@]}" } arr=(10 20 30 40 50) echo "原始数组的值为: ${arr[@]}" test1 $arr
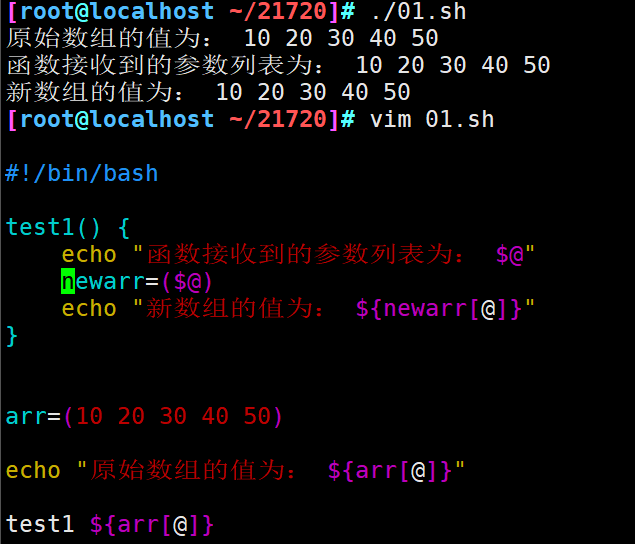
解决方法:将newarr=($1)改成newarr=($@),test1 $arr改为test1 ${arr[@]}
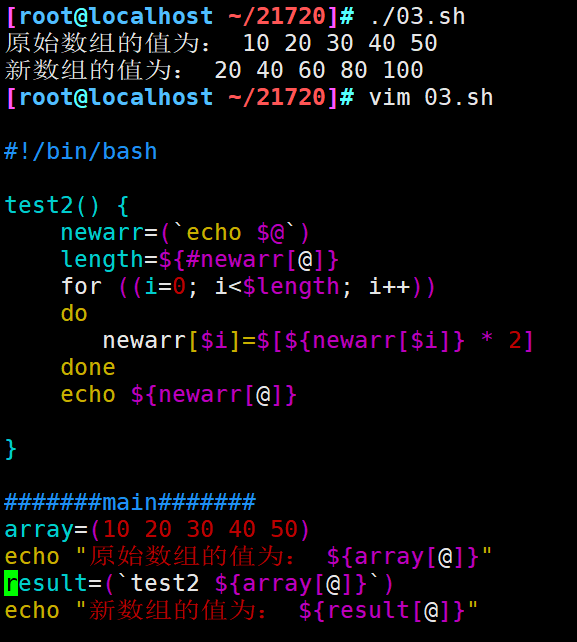
#!/bin/bash test1() { echo "函数接收到的参数列表为: $@" newarr=($@) echo "新数组的值为: ${newarr[@]}" } arr=(10 20 30 40 50) echo "原始数组的值为: ${arr[@]}" test1 ${arr[@]}
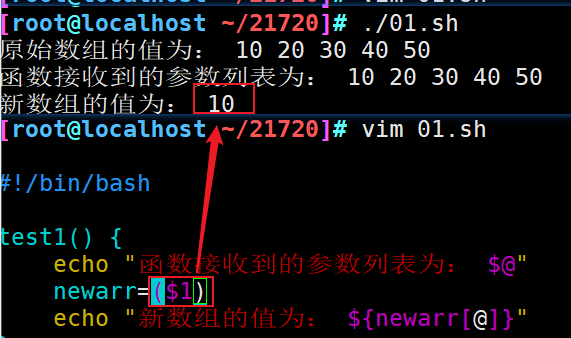
将原数组的元素*2再输出
#!/bin/bash test2() { newarr=(`echo $@`) length=${#newarr[@]} for ((i=0; i<$length; i++)) do newarr[$i]=$[${newarr[$i]} * 2] done echo ${newarr[@]} } #######main####### array=(10 20 30 40 50) echo "原始数组的值为: ${array[@]}" result=(`test2 ${array[@]}`) echo "新数组的值为: ${result[@]}"
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
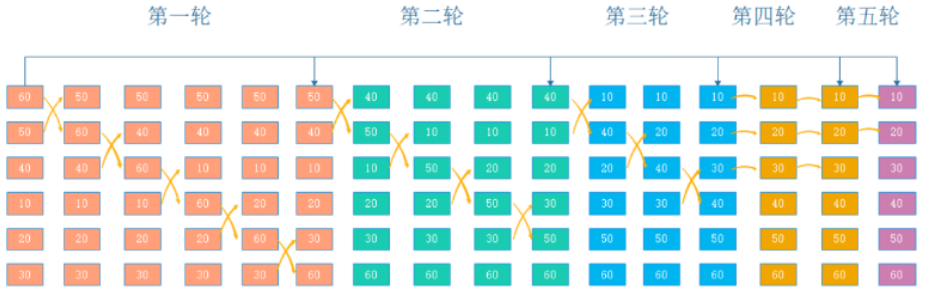
基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
算法思路:
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。

#!/bin/bash arr=(20 60 40 30 50 10) echo "原始数组的顺序为: ${arr[@]}" ### 获取数组长度 length=${#arr[@]} ### 外层循环,定义比较的轮数,轮数为数组长度-1,从1开始 for ((a=1; a<$length; a++)) do ### 确定比较相邻两个元素的位置,较大的往后放,并且每次每轮比较 的最后一个元素下标要递减 ### 这里使用变量b代表左边比较元素的下标范围 for ((b=0; b<$length-a; b++)) do ### 定义左边比较的元素的值 left=${arr[$b]} ### 定义右边比较的元素的值 c=$[$b + 1] right=${arr[$c]} ### 如果左边的元素比右边的元素的值大就互换元素的位置 if [ $left -gt $right ];then ### 把左边元素的值保存到临时变量tmp中 tmp=$left ### 把右边元素的值赋给左边的元素 arr[$b]=$right ### 再把保存在临时变量中的值赋给右边的元素 arr[$c]=$tmp fi done done echo "排序后的数组的顺序为: ${arr[@]}"
与冒泡排序相比,直接选择排序的交换次数更少,所以速度会快些
基本思想:
将指定排序位置与其他数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式。

#!/bin/bash arr=(20 50 40 30 60 10) echo "原始数组的顺序为: ${arr[*]}" length=${#arr[*]} for ((a=1; a<$length; a++)) do ### 先假设下标为0的元素值最大 index=0 ### 通过比较获取拥有最大值的下标(索引) for ((b=1; b<=$length-a; b++)) do right=${arr[$b]} left=${arr[$index]} if [ $right -gt $left ];then index=$b fi done ### 把最大元素的值跟当前轮次最后一个元素的值进行交换 last=$[$length - $a] tmp=${arr[$last]} arr[$last]=${arr[$index]} arr[$index]=$tmp done echo "排序后的数组的顺序为: ${arr[*]}"
以相反的顺序把原有数组的内容重新排序
基本思想:
把数组最后一个元素与第一个元素替换,倒数第二个元素与第二个元素替换,以此类推,直到把所有数组元素反转替换

#!/bin/bash arr=(1 2 3 4 5 6 7) echo "原始数组顺序为: ${arr[@]}" length=${#arr[*]} for ((a=0; a<$length/2; a++)) do tmp=${arr[$a]} arr[$a]=${arr[$length-1-$a]} arr[$length-1-$a]=$tmp done echo "反转排序后的数组顺序为: ${arr[@]}"

