
GAN
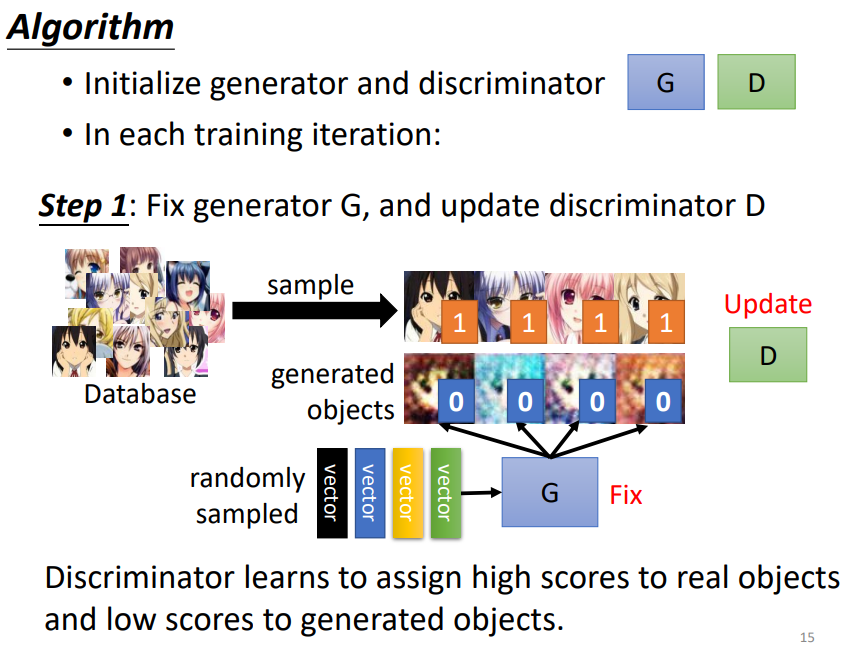
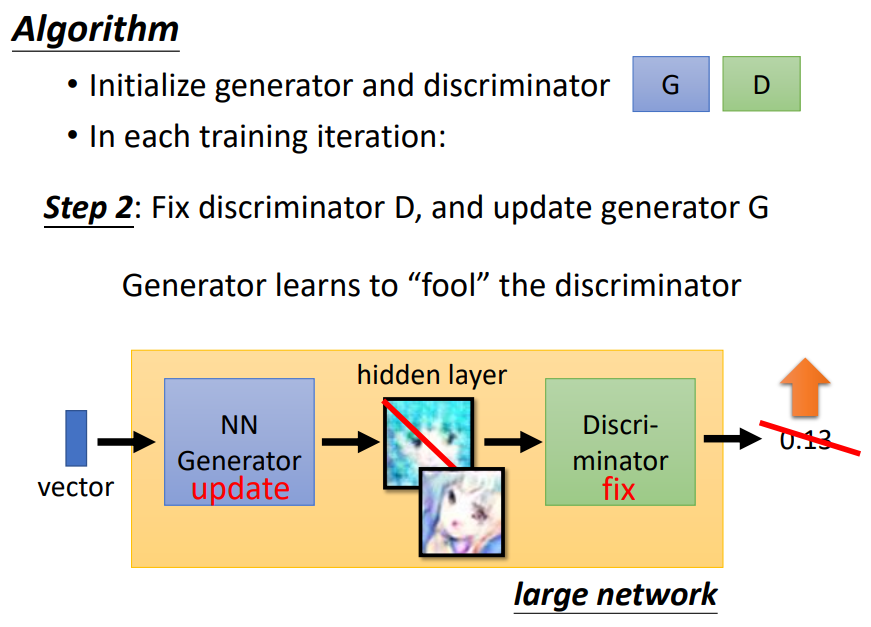
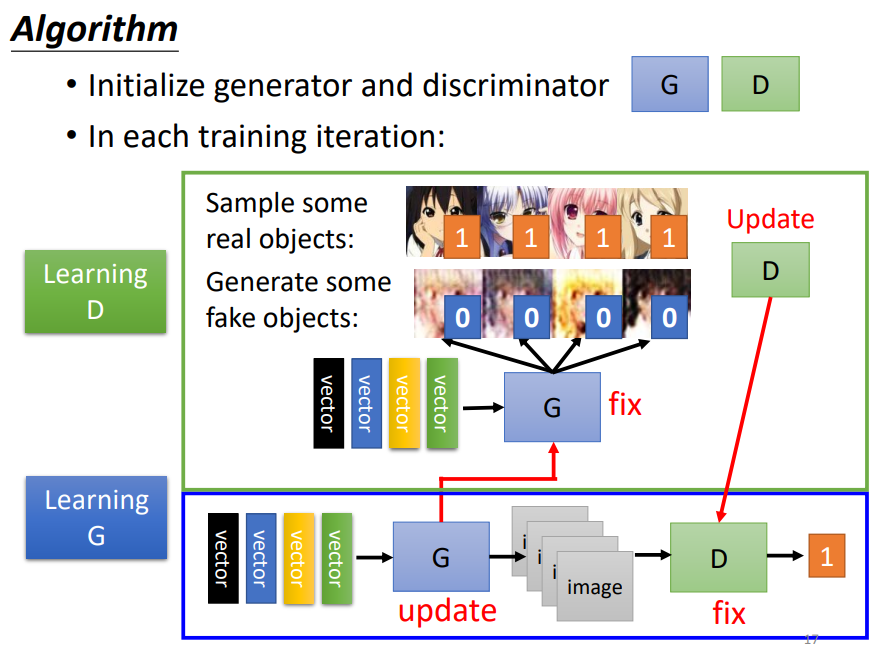
1. Algorithm
2. Theory behind GAN
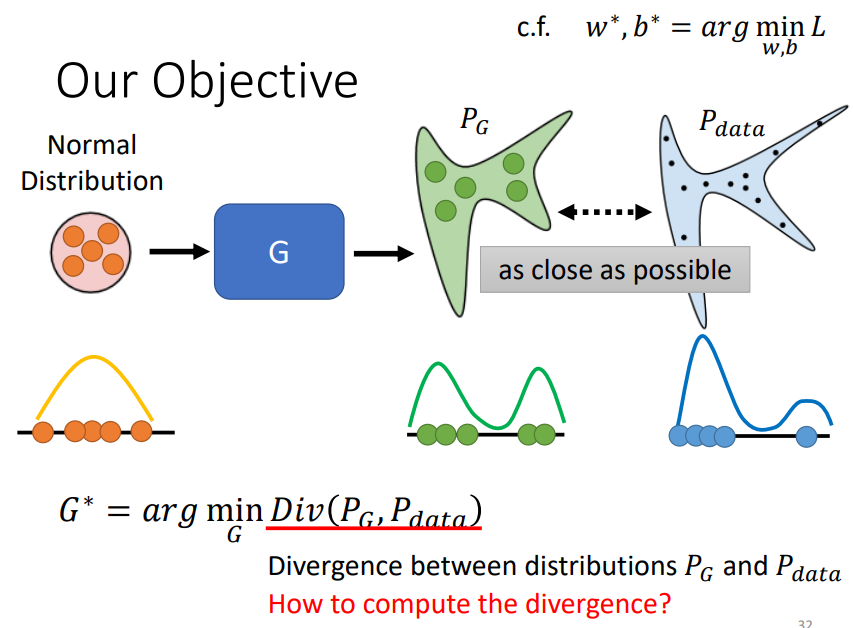
我们的目标是让生成器生成的数据的分布PG和实际的数据分布Pdata越接近越好,而衡量两个分布之间是否接近可以通过Divergence Function;
Divergence Function的值越小,说明两个分布之间越接近;
但是,如何计算Divergence是关键的问题,因为我们不可能知道PG和Pdata长什么样;
实际上,我们可以通过解另外一个问题,相当于近似计算了Divergence:

我们可以分别从PG和Pdata中采样足够多的数据,去训练一个Discriminator,
定义一个目标函数Objetive Function(这直接决定了我们的Divergence的计算方式),去找到能使得Objective Fuction最大的Discriminator,
而训练好的Discriminator的Objective Function的值,就与我们的Divergence的值密切相关!

如上图,如果我们的Objective Function定义为V(G, D),则训练后Objective Function的值与JS Divergence的值(衡量两种分布相似程度的一种计算方式)密切相关!
如何直观的理解这两种问题之间是相关的呢?
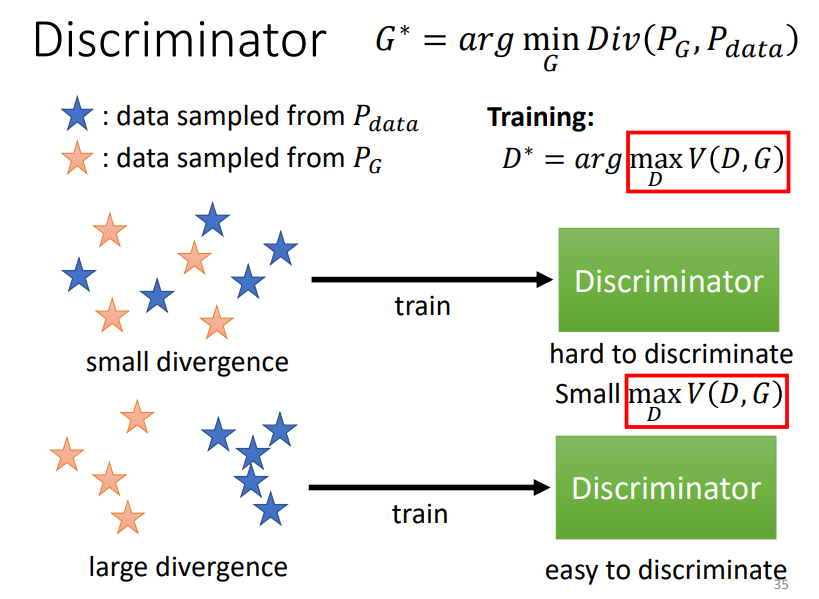
如上图,如果我们的两个分布非常接近,也就是有非常小的Divergence(中文翻译:分歧),那么Discriminator很难对Generator生成的图片和真实的图片进行区分,也就是说训练后的Objective Function的值会很小;
相反,如果我们的两个分布相差很远,也就是有非常大的Divergence,那么Discriminator很容易对Generator生成的图片和真实的图片进行区分,也就是说训练后的Objective Function的值会很大。
因此,GAN实际上在做的事情如下图所示,这也与其Algorithm相对应:

存在许多Divergence Function可供我们使用,我们只需要调整Objective Function的表达式即可:

3. Tips for GAN

通常情况下,真实的数据分布和Generator生成的数据分布在高维空间是很难有重叠的,因为这两个分布很可能只是低维的流型嵌入到了高维的空间中;
另一方面,即使两个分布有重叠,如果我们在两个分布中采样的数据不足够多,Discriminator也可能认为两个分布之间是没有重叠的。

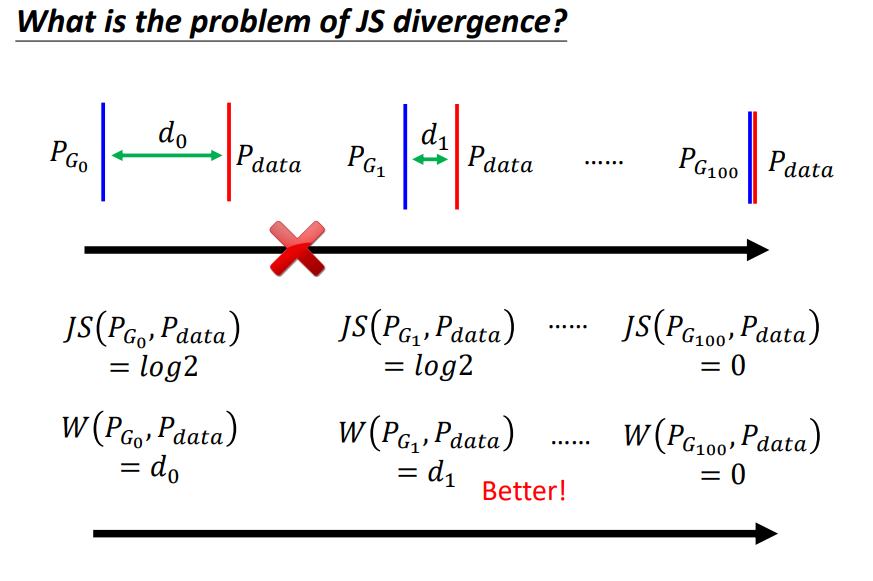
JS Divergence存在的最大的问题:
不管Generator生成的数据的分布和真实的数据分布之间有多接近,只要它们之间是没有重叠的,那么计算出来的JS Divergence的值都是log2!
也就是说,或许我们的Generator在训练的过程中在逐渐变好,其生成的数据的分布在逐渐逼近真实的数据分布,但是由于两者没有重叠,因此从Discriminator的Objective Function中我们无法看出Generator是不是在变好!我们要在训练的过程中不断观察Generator生成的数据,这使得GAN的训练变得非常吃力!
我们可以用Wasserstein distance去解决这个问题(使用Wasserstein distance去衡量Divergence的网络称为WGAN):
我们之前有提到,我们无法直接计算Divergence,而是需要采样数据,并通过trian一个Discriminator去找到使得Objective Function最大的值,那么Objective Function应该如何定义呢?如下图!

有一个重要的条件,就是需要使Discriminator的Function足够smooth!
以下是一些做法:

4. GAN for Sequence Generation
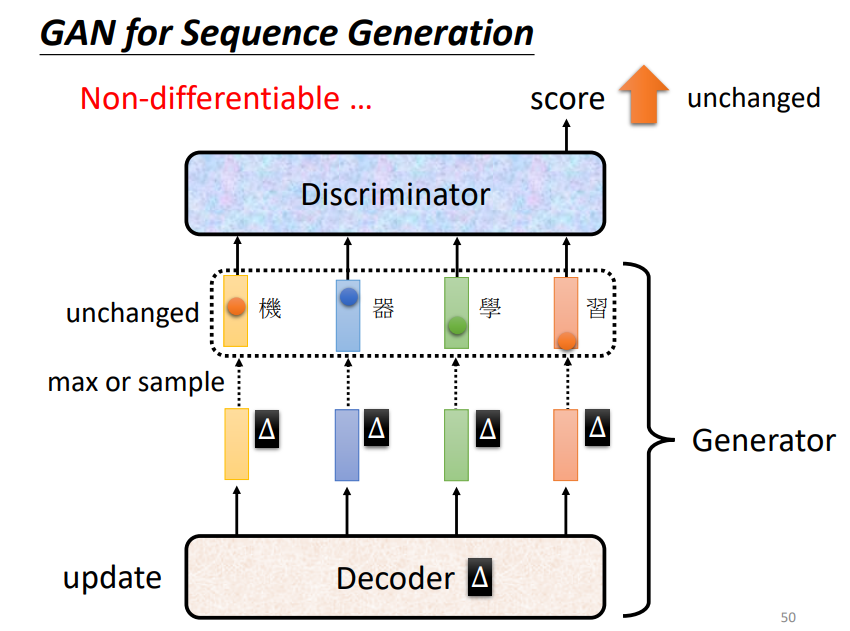
GAN用在序列生成上是比较困难的,因为Generator的参数发生微小的变化时,Discriminator的输入并不会发生太大的变化,进而导致Discriminator的输出分数不会发生改变,Gradient Descent无法进行下去!
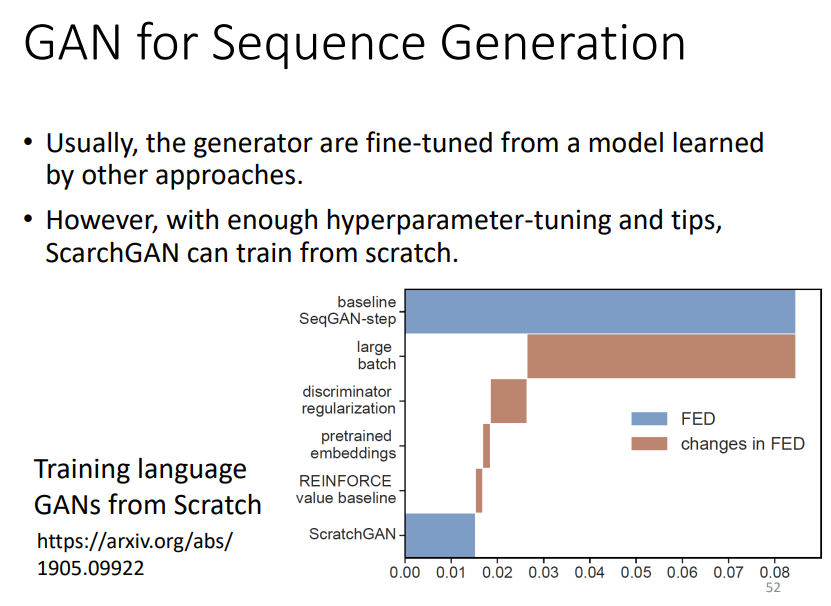
通常情况下,生成器会使用预训练的模型进行微调,也有其他方法如ScarchGAN可以从头Train!
有没有办法让GAN进行Supervised Learning,实行端到端的学习?
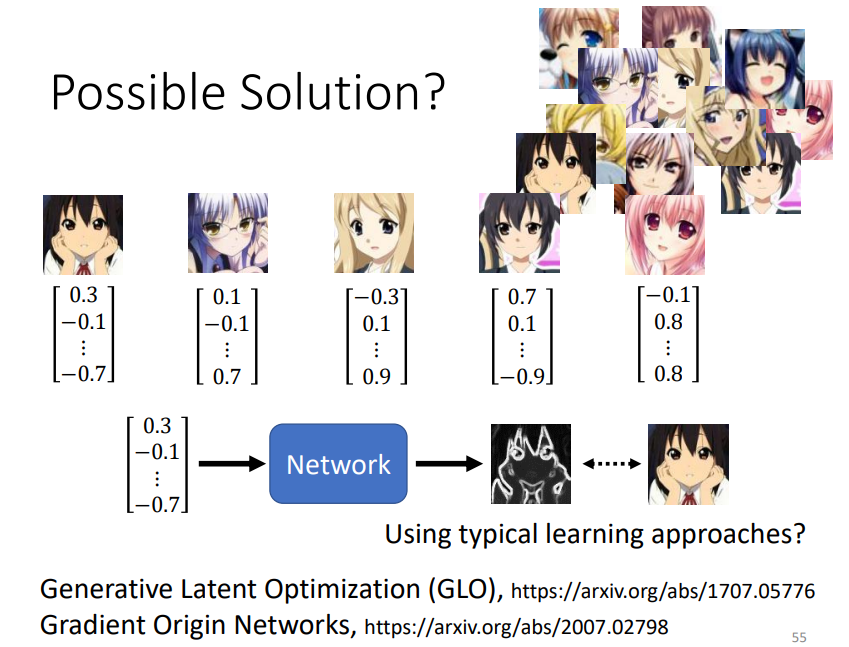
有!给训练资料中的每一张图片匹配一个Vector,这个Vector从一个分布中采样而来,关键是如何将图片和Vector进行配对,以上是一些文章的做法!
5. Evaluation of Generation
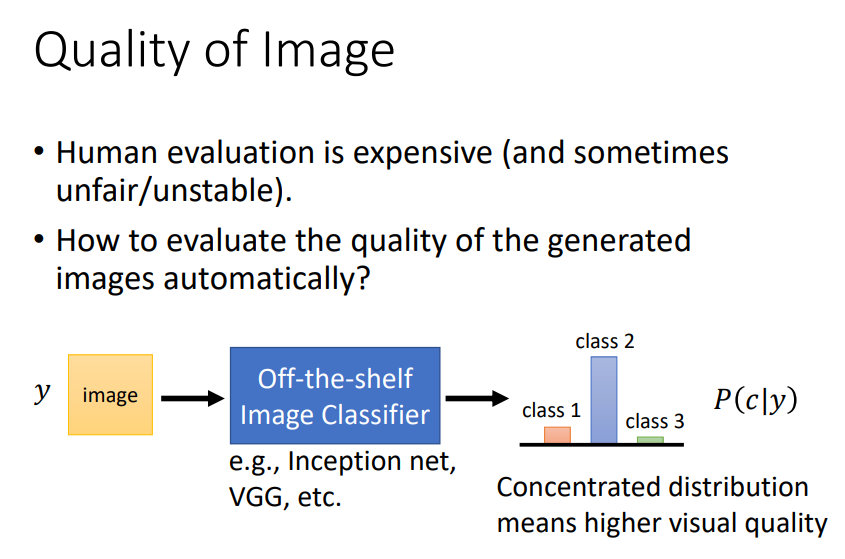
Q1:如何评估一个生成器生成图片的好坏?
(1)人工判断:主观性强,不稳定。
(2)自动判断:将生成的图片输入到一个图像分类器中,如Inception net,VGG等,输出的分布越集中越好(如上图)!


此外,生成器可能会遇到生成图片多样性的问题,如始终生成和真实数据集中某一张图像类似的图像(Mode Collapse),或者生成的图像始终是同一批类似的图像(Mode Dropping)。
Q2:如何衡量生成器生成图像的多样性的好坏?

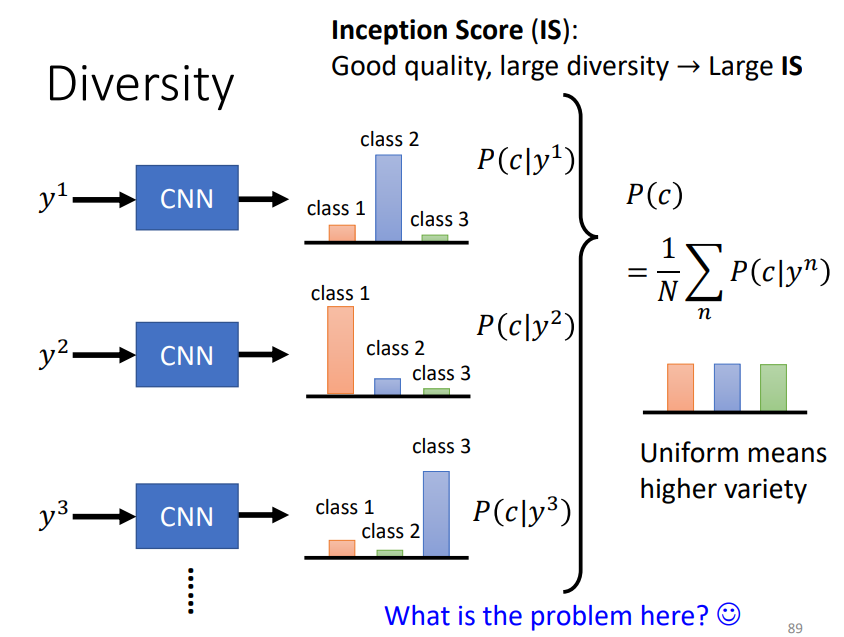
把生成器生成的一堆图片丢到Image Classifier中,如果这一堆图片的平均分布比较平坦,说明生成器生成图片的多样性是足够的。
需要注意的是,上面提到评估一张图片质量的好坏也是丢到Image Classifier中,但这里评估的范围是不同的:
评估一张图片质量的好坏只看这一张图片经过Classifier后的分布是否集中,
而评估图片的Diversity是看一堆图片经过Classifier后的平均分布是否平坦!

另一种计算方法:把生成的图片和真实的图片分别丢到Inception网络中,取softmax前的向量;
假设这两堆向量都服从高斯分布,计算两个高斯分布之间的Frechet distance即可(具体计算方式在上图中的论文链接)。

即使我们解决了生成图片的质量和多样性的问题,Generator的评估仍然面临许多问题,例如上图,我们不希望Generator只是copy真实数据集中的图片或者只是对真实数据集中的图片做了简单的翻转等......
更多关于GAN的评估方法如下:

6. Conditional Generation
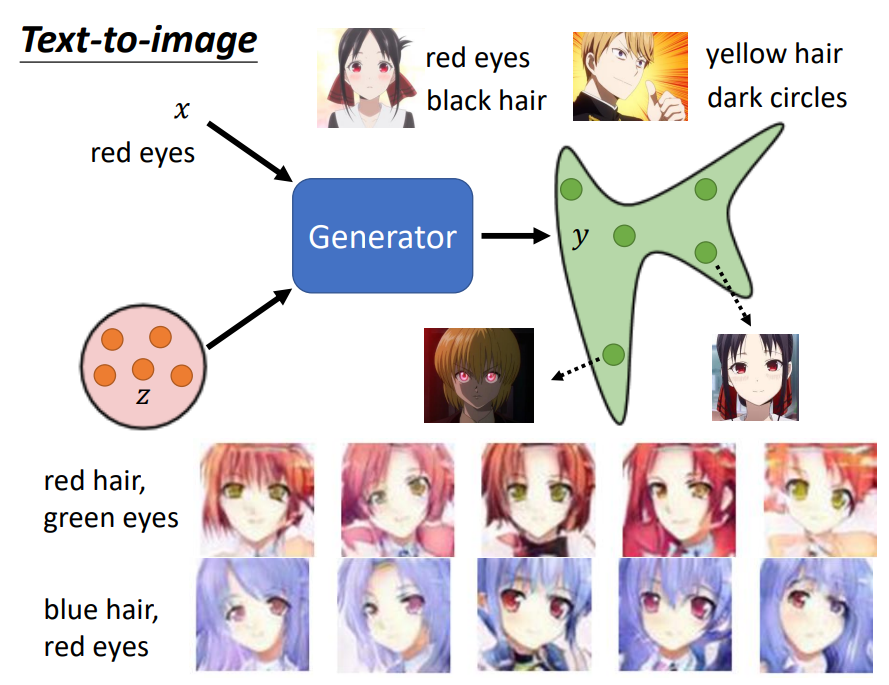
Conditional Generation是指Generation的输入不仅仅是一个随机向量z,还包含了描述信息(条件)x
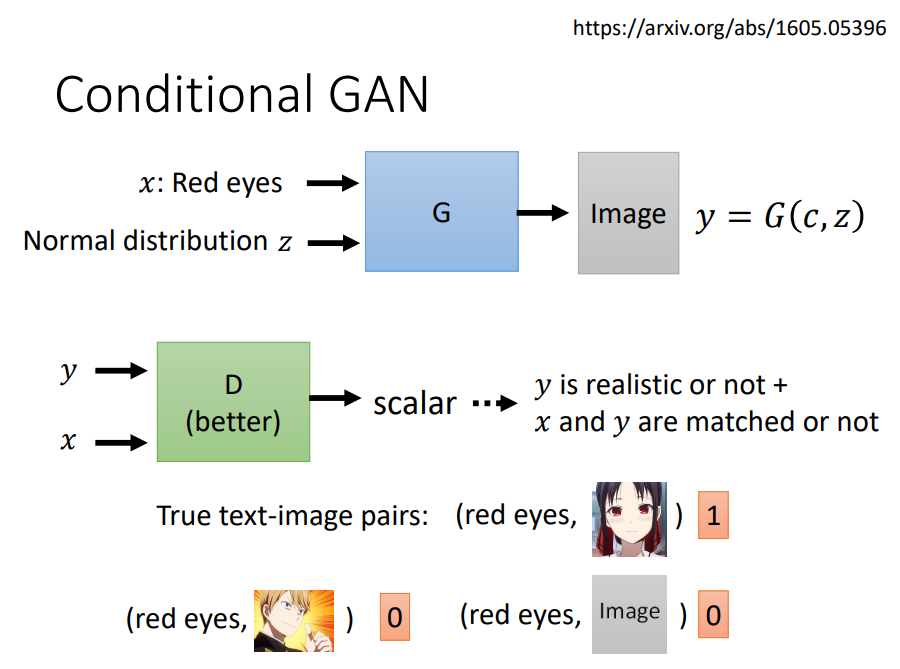
Conditional GAN的Discriminator的输入不仅仅是Generator生成的图片或者真实的图片,同时还要输入描述信息x,
此时我们的训练资料为text-image pairs,要注意的是,我们要对真实的资料做一定的随机配对,即将描述信息和图片随机配对制造一些负样本。

Conditional GAN除了可以做Text-to-Image,还可以做Image translation(pix2pix)、Sound2image。
7. Learning from Unpaired Data (Cycle GAN)
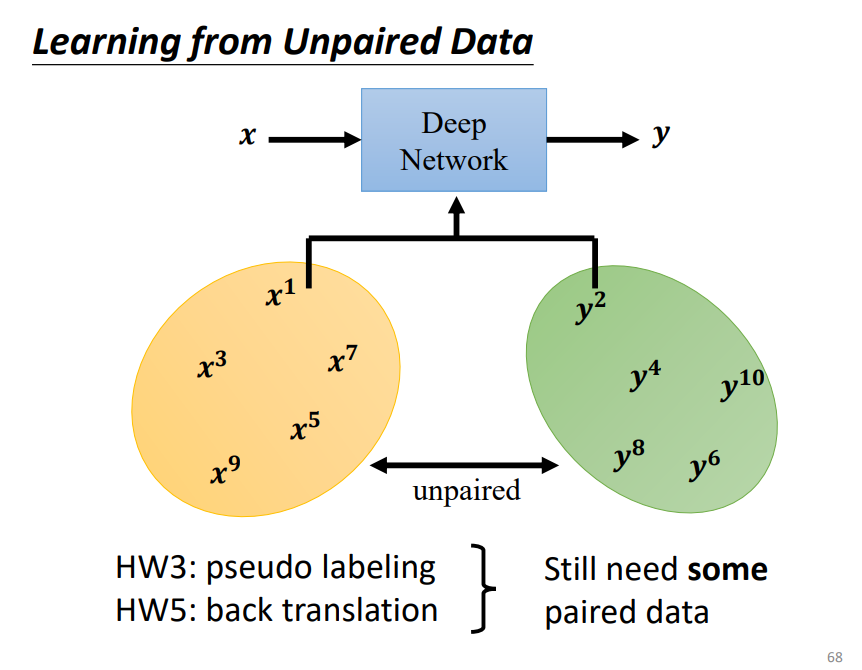
GAN还可以用在Unsupervised Learning上面,可以处理一堆x和一堆y,但是它们之间没有配对的情况。
例如:图像风格转换(真人 -- 动漫),翻译(中文 -- 英文),语言风格转换(正面 -- 负面)等。
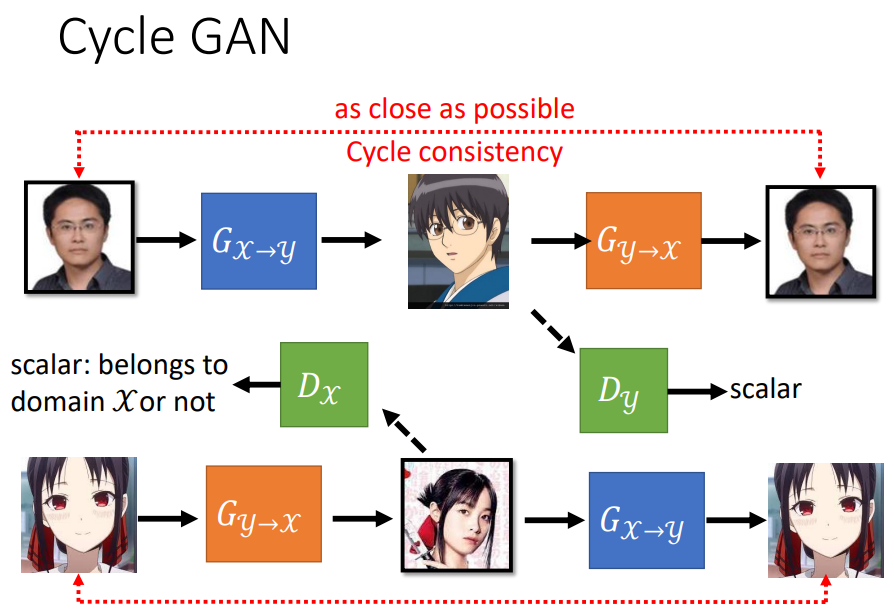
一个韩国团队做的关于真人转动漫的AI模型:

END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号