
PySpark
1. PySpark前言介绍


2. 基础准备

⭐构建PySpark执行环境入口对象:
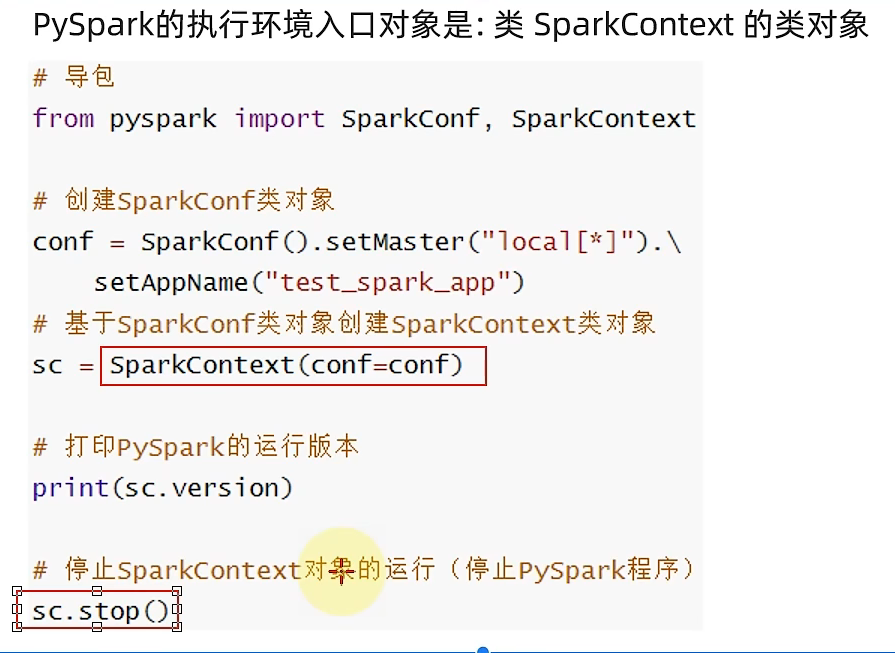
⭐后续的代码都通过对象sc进行编写!
3. 数据输入

A. Python数据容器转RDD对象:

B. 读取文件转RDD对象:


RDD和列表,元组等类似,用于存储数据,是Spark用于数据计算的载体!数据输入可以理解为获得RDD对象!
4. 数据计算
A. map算子

B. flatMap算子

C. reduceByKey算子

KV型RDD:二元元组,元组里面只有两个元素!
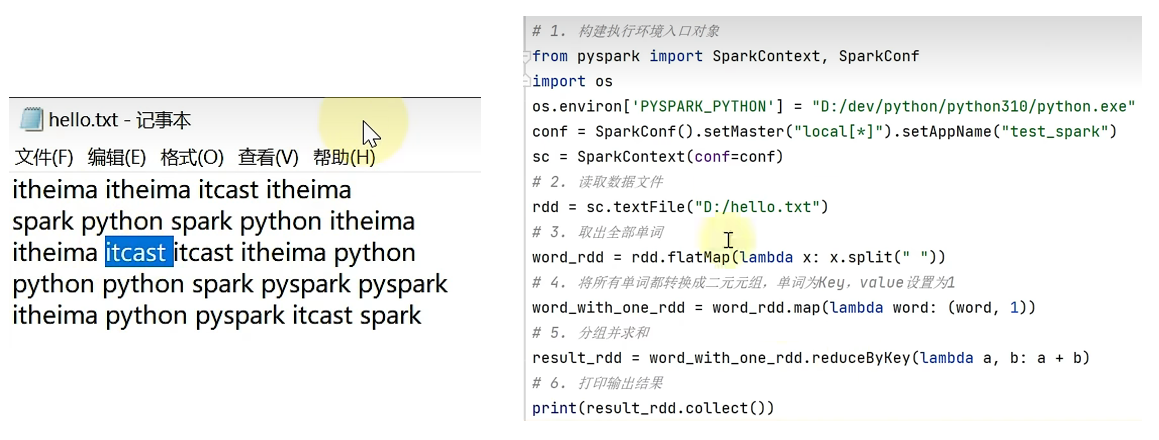
⭐一个单词统计的小案例:
D. filter算子

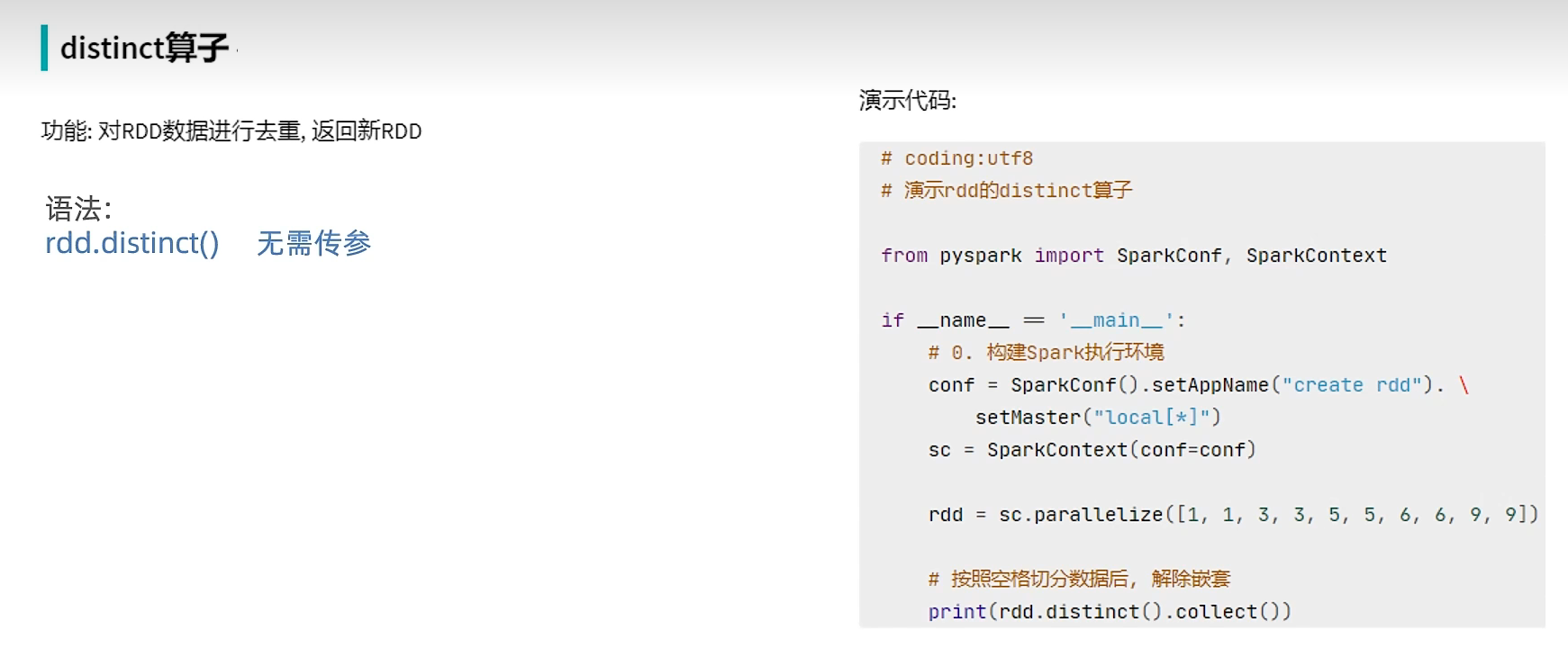
E. distinct算子
F. sortBy算子

5. 数据输出
A. 输出为Python对象
(1) collect算子

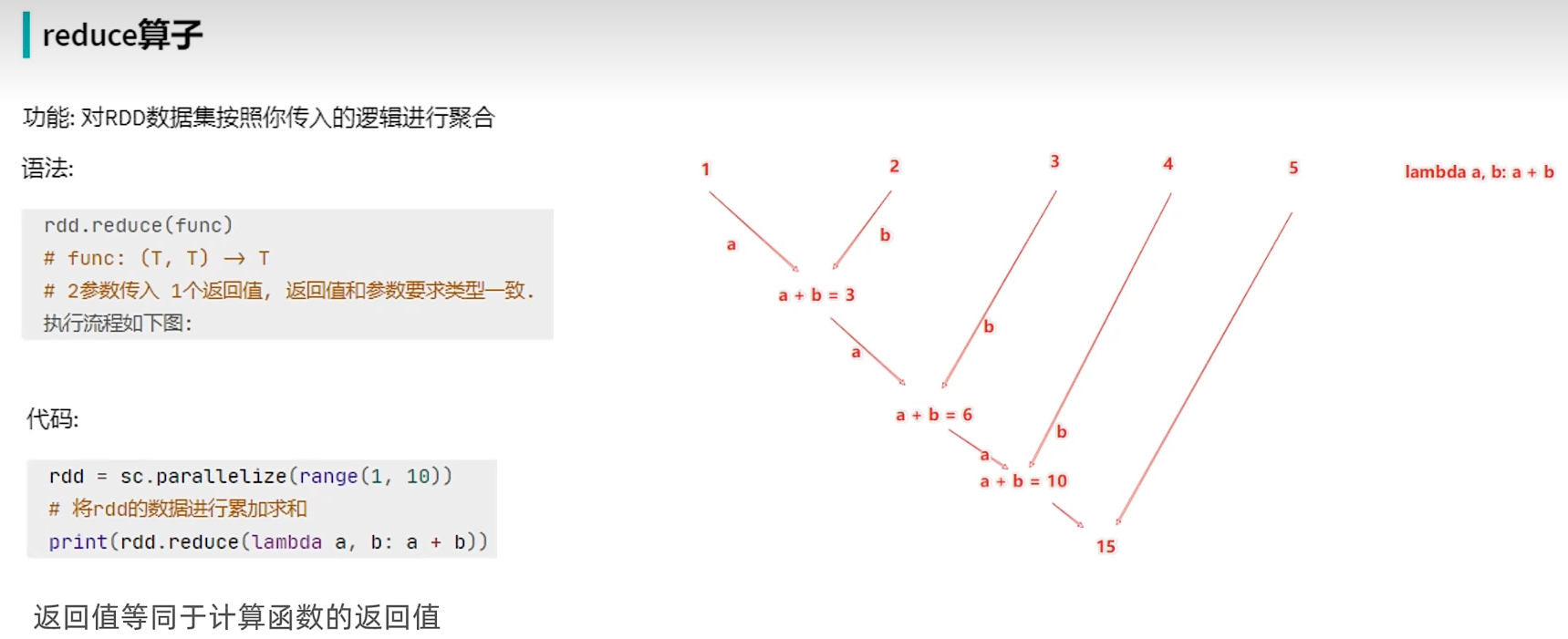
(2) reduce算子
(3) take算子

(4) count算子

B. 输出到文件中
(1) saveAsTextFile算子

注意:需要配置Hadoop相关依赖!
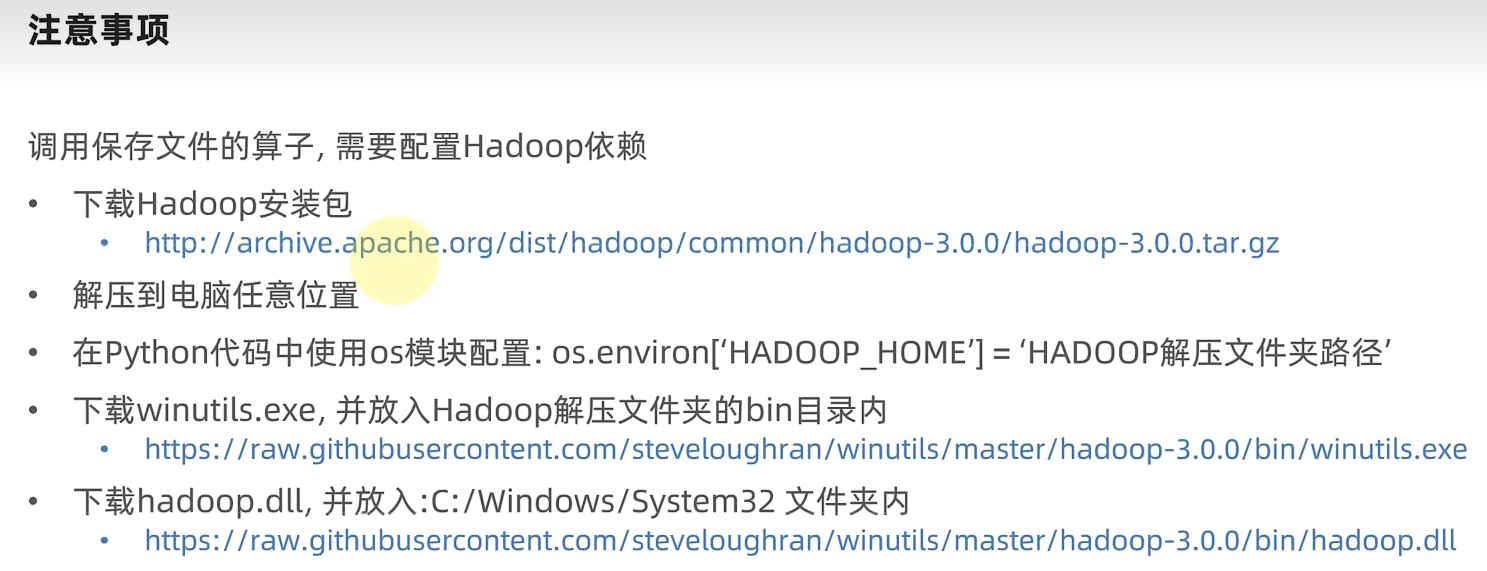
有几个分区就写到几个文件中!
(2) 修改RDD分区为1个



 浙公网安备 33010602011771号
浙公网安备 33010602011771号