Lecture 3 -- More about Validation Set
⭐I used a validation set, but my model still overfitted?

通常,我们会选择在验证集上损失最小的模型应用于测试集上!
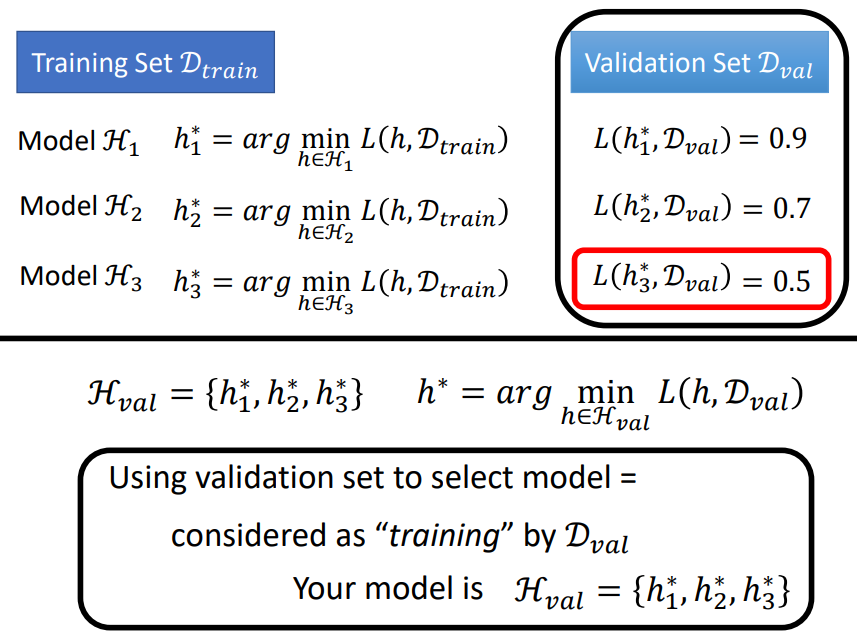
实际上,使用验证集选择模型的过程也可以视为在验证集上“训练”的过程,只是可供我们选择的模型没有训练集那么多!

正如之前所说,我们采样出坏的训练集的概率和function set的大小和训练集样本量有关;
在验证集上同理,但是由于在验证集上可供我们选择的模型的数量非常少,并且验证集的样本量也不大,
因此我们在验证集上找出的参数应用于"所有数据集上"的损失(现实)会和理想的最小损失比较接近!
但是,如果我们尝试了太多的模型架构,比如模型的每一层的神经元和模型的层数都进行非常大范围的网格搜索等,
就会导致模型在验证集上过拟合,从而在真实的数据集上泛化性能下降!
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号