
Lecture 2 -- 理想与现实 (从宝可梦和数码宝贝的分类浅谈机器学习原理)
1. Case Study

观察上图,可以看到,数码宝贝的线条较为复杂,而宝可梦的线条较为简单,画风偏儿童~
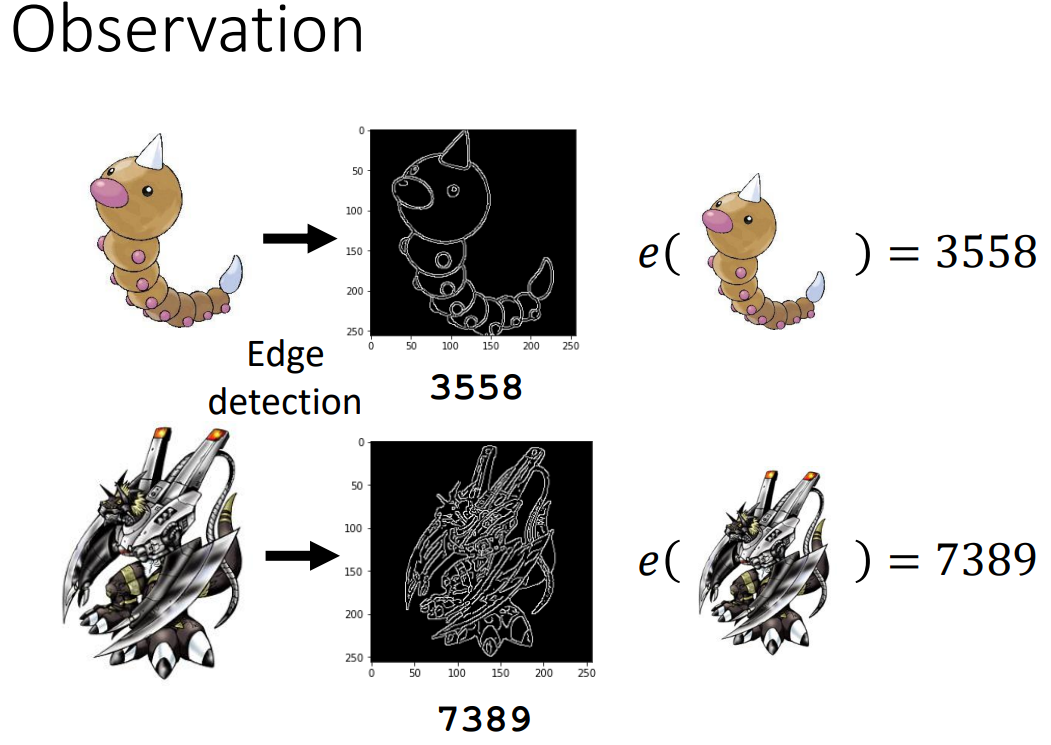
我们可以对不同的图像做edge detection,用图像中白色像素点的个数对宝可梦和数码宝贝进行分类
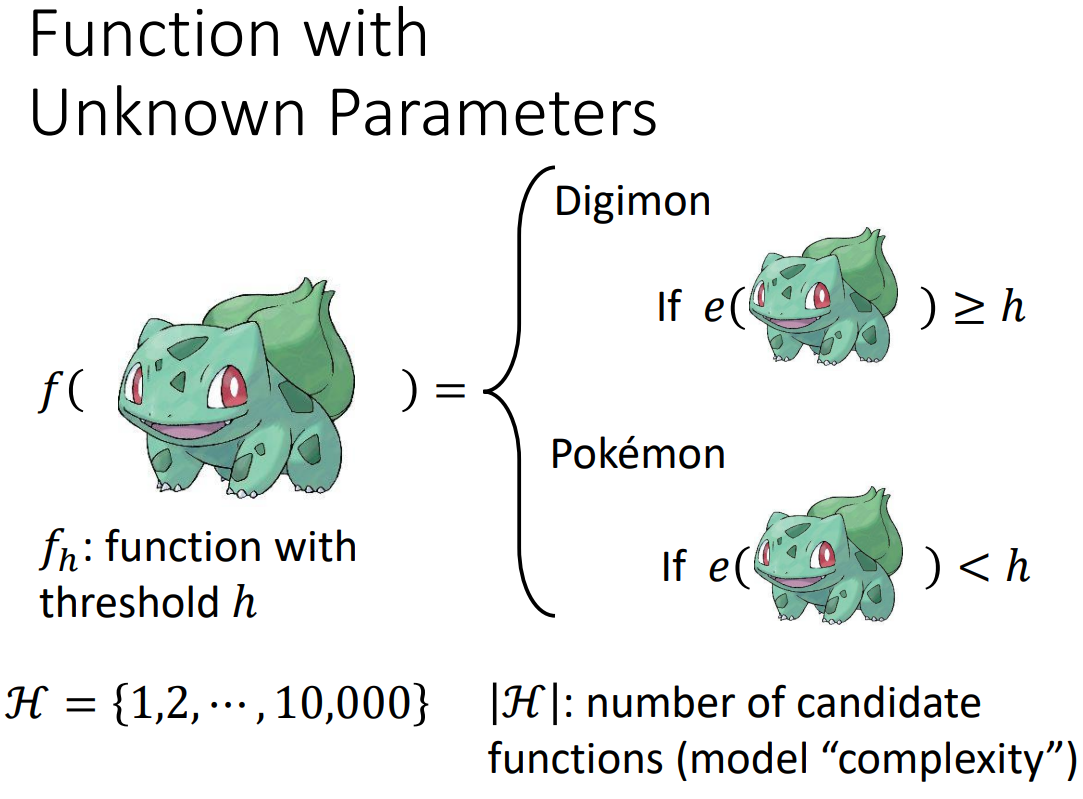
我们可以定义一个简单的模型进行分类,其中h是阈值,如果一张图像经过edge detection后,其白色像素点的数量小于h,那么我们可以判定其为宝可梦,反之为数码宝贝
这里的h为模型的参数,我们将其取值设定为有限值{1,2,3,...,10000},也就是说,我们的function set中可以选择的function是有限的
2. 理想?现实?

假设我们可以搜集到宇宙中所有的数码宝贝和宝可梦,将它们构成数据集Dall,在Dall数据集上能够使得loss最小的h称为hall,hall应用于Dall上的loss即为理想;
而现实中,我们不可能找到这样的Dall,我们往往是从Dall中采样出Dtrain,进而找到能在Dtrain上loss最低的htrain,我们期望在有限的数据集上找到的参数htrain,其应用于Dall上的loss(现实)也能够很小,也就是说,我们期望理想和现实越接近越好!
什么样的训练数据能让理想和现实很接近呢?

⭐任意的h,将它应用于Dtrain的loss和将它应用于Dall的loss的差值≤δ/2(一个很小的数),我们就认为这样的Dtrain是好的Dtrain,能够让理想和现实接近的Dtrain!
具体的推导过程如下:

我们已经知道了一个好的训练数据集应该满足的条件,那么我们采样出坏的数据集的概率有多大呢?

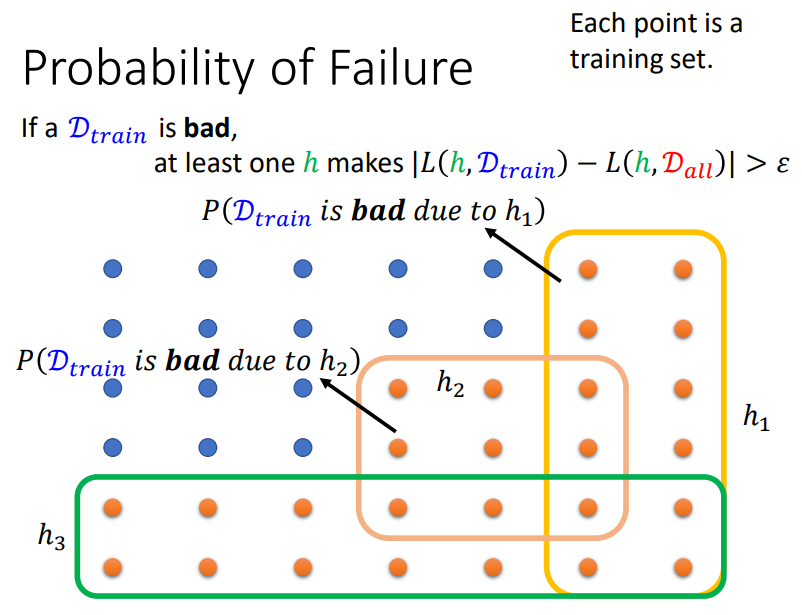
如果一个训练数据集是坏的,那么至少存在一个h,使得|L(h,Dtrain)-L(h,Dall)|>ε

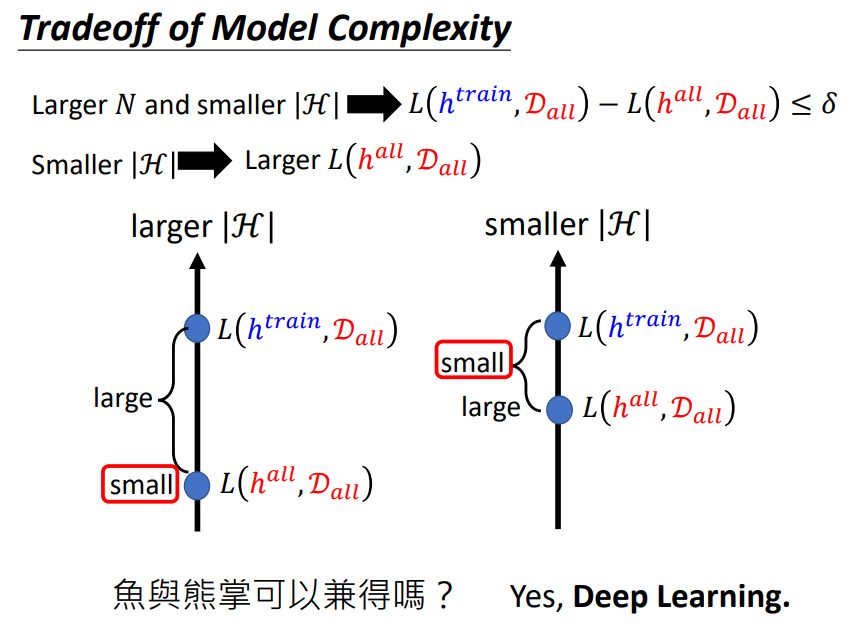
根据上图的推导过程,我们想要理想与现实更接近,我们就需要更多的训练数据集或者更小的function set,这似乎是一个矛盾,因为较小的function set或许会使理想崩坏,即使得L(hall,Dall)很大,这时候即使现实与理想很接近,那也无济于事!

我们如何能让理想不会崩坏(使模型拥有足够的复杂程度[VC-dimension]),并且现实和理想又能很接近?鱼和熊掌可以兼得吗? → Yes,deep learning!
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号