
Lecture 2 -- Adaptive Learning Rate
1. Training stuck ≠ Small Gradient
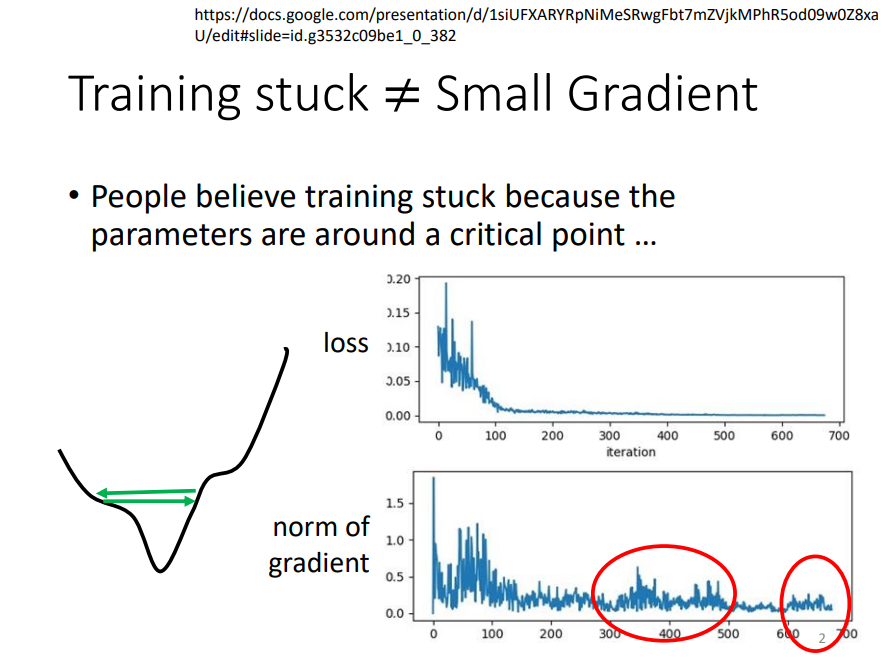
如果我们在训练过程中遇到了training stuck,不一定是遇到了critical point,也可能是走到了critical point附近,并在山谷两端左右徘徊!
把此时的梯度计算出来,可以发现,梯度并不为0,可以证明此时loss并不处于critical point处!
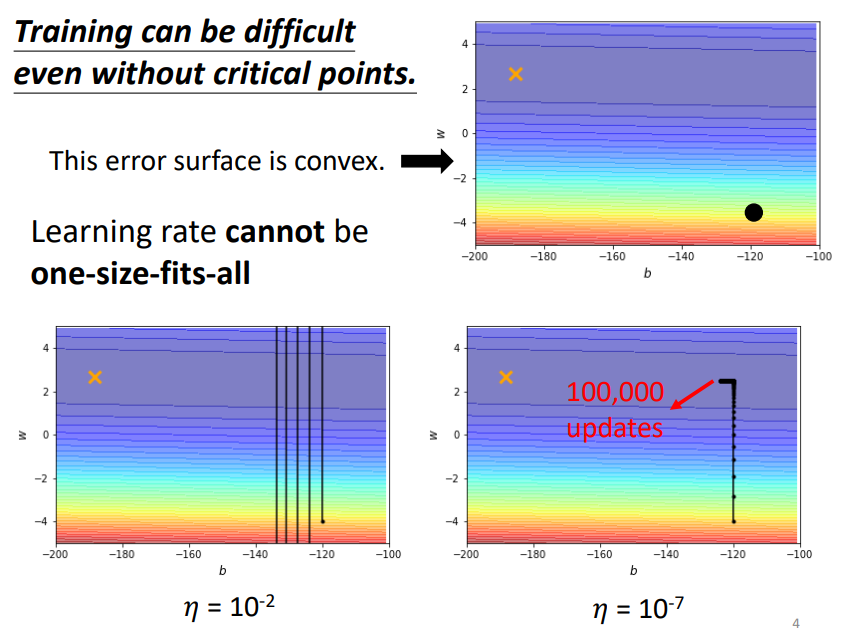
即使是没有任何critical point的损失函数,当我们把learning rate设置为定值时,训练过程也会变得非常困难!
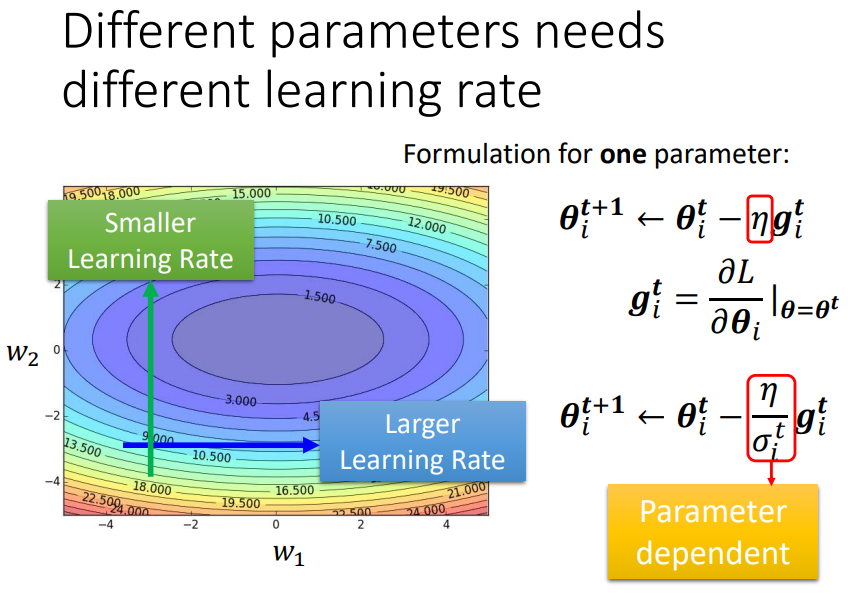
不同的参数需要不同的learning rate,
在损失陡峭的地方,我们应该减小步伐(刹车),即减小学习率,
在损失平坦的地方,我们应该增大步伐(加速),即增大学习率。
我们应该如何动态的控制学习率???
2. AdaGrad & RMSProp & Adam

第一种方式:AdaGrad,如上图。
每一次更新参数时,学习率都会除以一个数σ,σ是前面所有更新过程所计算梯度的均方根;
当遇到平坦地带时,更新几次参数所计算的梯度都比较小,就会导致σ小,η/σ增大,步伐增大;
当遇到陡峭地带时,更新几次参数所计算的梯度都比较大,就会导致σ大,η/σ减小,步伐减小。
可以想象一下,这种更新学习率的方式存在一定的问题,如果在一个较长的平坦地带更新非常多次的参数,这些梯度的均方根非常小,从而导致学习率爆炸式增长,loss出现“喷”到某一处,接着再计算这一处的梯度,调整学习率,继续更新参数。
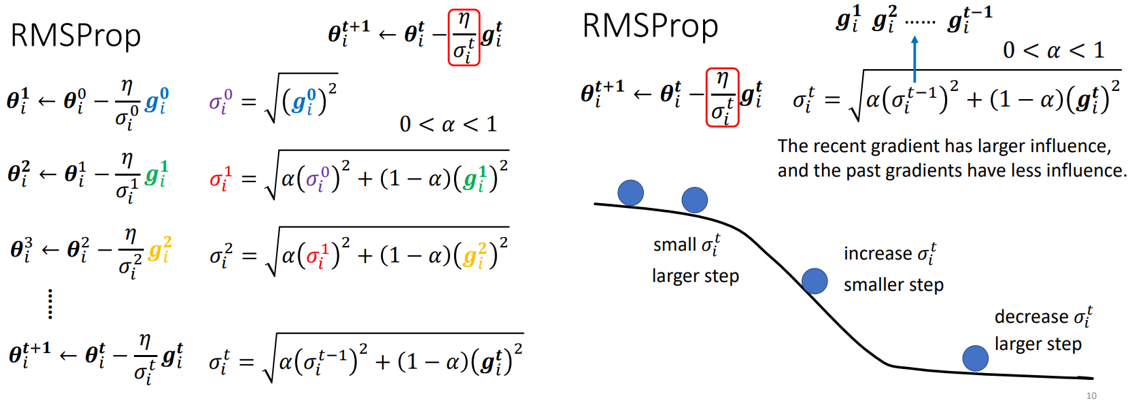
第二种方式:RMSProp,如上图。
与AdaGrad不同的是,其σ的计算会在当前的梯度和之前的所有梯度之间做一个权衡,如果α设置的比较小,则σ的大小更多的取决于当前的梯度!

现如今,使用最多的优化算法是Adam,其可以看作是RMSProp和Momentum的结合,这两个方法都考虑了当前的梯度和之前的所有梯度,
不同的是,Momentum不仅考虑了所有梯度的大小,同时考虑了方向,而RMSProp仅考虑了所有梯度的大小,进而调整学习率(从σ的计算公式可以看出)
3. Learning Rate Scheduling
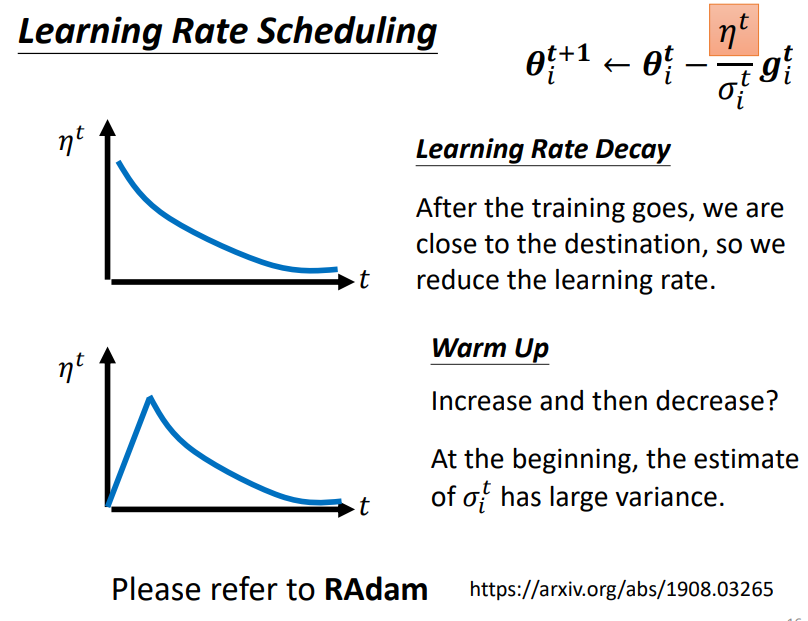
此外,学习率也可以随时间动态变化,常见的做法有learning rate decay和warm up;
learning rate decay是指随着训练的进行,学习率不断变小;
warm up是指随着训练的进行,学习率先变大后变小,在大语言模型BERT和Transformer中,warm up这种方法也都有用到!
4. Summary of Optimization

调整Optimization,无非就是调整learning rate scheduling,momentum,以及调整σ的计算方式(AdaGrad,RMSProp等)
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号