
Lecture 2 -- Batch & Momentum
1. Small Batch v.s. Large Batch
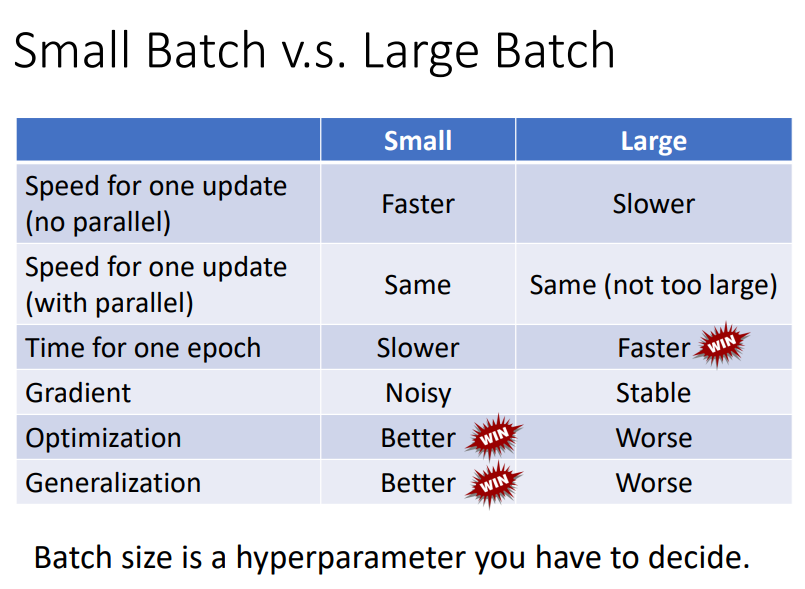
2. "Noisy" update is better for training!
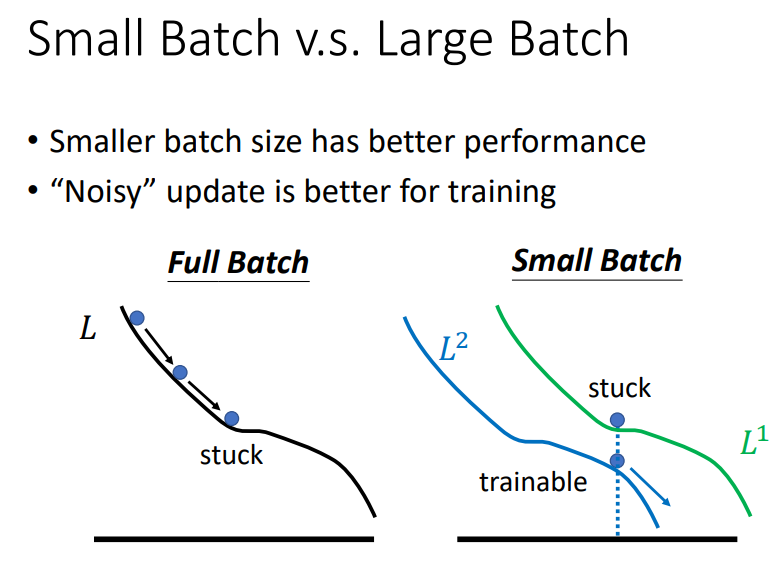
- 如果将所有的数据作为一个Batch丢进网络中,当梯度下降遇到critical point时,由于loss是恒定的,参数就会卡在critical point处;
- 当把数据分为一个一个的mini-batch丢进网络中时,当其中一个mini-batch更新参数时遇到critical point,由于下一次更新参数时换了一个mini-batch的数据,loss发生了变化,可能在这个mini-batch中,loss在这组参数下不是critical point,从而导致参数可以继续更新,loss可以继续下降
3. Small batch is better on testing data!

有人在不同数据集上做实验发现小的batch反而有更高的testing accuracy;
存在一个假说对此做出了解释:使用小的batch会使loss陷入flat minima,而大的batch会使loss陷入sharp minima;
训练和测试的loss不同,是因为数据分布不同,或者训练集和测试集是从一个分布中采样出来的,但是采样的数据不同;
假设testing loss只是在training loss的基础上向右发生了平移,那么可以看到,在flat minima处,训练和测试的损失gap很小,而在sharp minima处,训练和测试的损失gap很大!
需要注意的是,这只是其中的一个观点,也不是所有人都相信这个观点~
4.Momentum -- a method to escape local minima and saddle point

参数更新的方向不仅取决于梯度的反方向,还取决于前一步移动的方向!
从另一个角度也可以理解为:某一次参数的更新和之前所有的梯度相关!
即θn=θn-1-ηgn-1-ληgn-2-λ2ηgn-3-λ3ηgn-4-...-λn-1ηg0
有了Momentum,参数就可能越过local minima和saddle point,甚至会向着损失增大的方向移动,去找到下一个更好的local minima!
5. Concluding Remarks⭐

END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号