

python学习笔记
获取mac地址
1 2 3 4 5 6 | import uuiddef get_mac_address(): node = uuid.getnode() mac = uuid.UUID(int = node).hex[-12:] return mac |
axios对应的fastapi服务端中间件CORSMiddleware
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # -*- coding: UTF-8 -*-from fastapi import FastAPIfrom starlette.middleware.cors import CORSMiddlewarefrom fastapi.responses import JSONResponseapp = FastAPI()app.add_middleware( # 添加中间件 CORSMiddleware, # CORS中间件类 allow_origins=["*"], # 允许起源 allow_credentials=True, # 允许凭据 allow_methods=["*"], # 允许方法 allow_headers=["*"], # 允许头部)@app.get("/{a}")async def regist(a): print('前端数据是:', a) # print(type(a)) return a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | 1、使用 f-string拼接字符串def manual_str_formatting(name, subscribers): # better if subscribers > 100000: print(f"Wow {name}! you have {subscribers} subscribers!") else: print(f"Lol {name} that's not many subs")2、使用上下文管理器def finally_instead_of_context_manager(host, port): # close even if exception with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.connect((host, port)) s.sendall(b'Hello, world')def manually_calling_close_on_a_file(filename): with open(filename) as f: f.write("hello!\n") # close automatic, even if exception3、适当使用推导式odd_squares = {i: i * i for i in range(10)}c = []for i in range(n): for j in range(n): ij_entry = sum(a[n * i + k] * b[n * k + j] for k in range(n)) c.append(ij_entry)4、检查类型def checking_type_equality(): Point = namedtuple('Point', ['x', 'y']) p = Point(1, 2) # probably meant to check if is instance of tuple if isinstance(p, tuple): print("it's a tuple") else: print("it's not a tuple")5、判断是否单例def equality_for_singletons(x): # better if x is None: pass if x is True: pass6、for 循环def range_len_pattern(): a = [1, 2, 3] # instead for v in a: ...def not_using_dict_items(): d = {"a": 1, "b": 2, "c": 3} for key, val in d.items(): ...7、解包元组mytuple = 1, 2x, y = mytuple8、统计耗时def timing_with_time(): # more accurate start = time.perf_counter() time.sleep(1) end = time.perf_counter() print(end - start)9、记录日志使用loggingdef print_vs_logging(): # versus # in main level = logging.DEBUG fmt = '[%(levelname)s] %(asctime)s - %(message)s' logging.basicConfig(level=level, format=fmt) # wherever logging.debug("debug info") logging.info("just some info") logging.error("uh oh :(")10、尝试使用 numpydef not_using_numpy_pandas(): x = list(range(100)) y = list(range(100)) s = [a + b for a, b in zip(x, y)]import numpy as npdef not_using_numpy_pandas(): # 性能更快 x = np.arange(100) y = np.arange(100) s = x + y11、喜欢 import *from itertools import *count()from mypackage.nearby_module import awesome_functiondef main(): awesome_function() |
列表中的所有元素组合成字符串
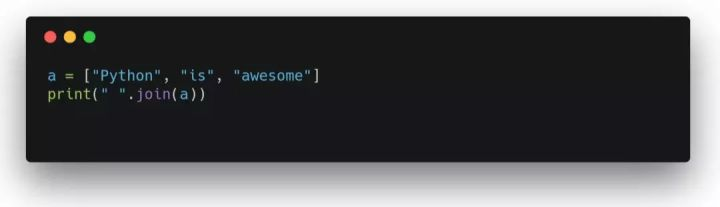
交换变量在c++中,肯定需要一个空变量。但是Python不需要,只需一行,大家看清楚了
>>>a,b=b,a
list comprehension列表推导 就是一个更简短、简洁的创建一个list的方法。
>>> some_list = [1, 2, 3, 4, 5]
>>> another_list = [ x + 1 for x in some_list ]
>>> another_list
[2, 3, 4, 5, 6]
>>> some_list = [1, 2, 3, 4, 5]
>>> another_list = [ x + 1 for x in some_list ]
>>> another_list
[2, 3, 4, 5, 6]
Set Comprehensions集合推导
>>> some_list = [1, 2, 3, 4, 5, 2, 5, 1, 4, 8]
>>> even_set = { x for x in some_list if x % 2 == 0 }
>>> even_set
set([8, 2, 4])
>>> some_list = [1, 2, 3, 4, 5, 2, 5, 1, 4, 8]
>>> even_set = { x for x in some_list if x % 2 == 0 }
>>> even_set
set([8, 2, 4])
Dict Comprehensions字典推导
>>> d = { x: x % 2 == 0 for x in range(1, 11) }
>>> d
{1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False, 10: True}
>>> d = { x: x % 2 == 0 for x in range(1, 11) }
>>> d
{1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False, 10: True}
计数时使用Counter计数对象。
这听起来显而易见,但经常被人忘记。对于大多数程序员来说,数一个东西是一项很常见的任务,而且在大多数情况下并不是很有挑战性的事情——这里有几种方法能更简单的完成这种任务。
Python的collections类库里有个内置的dict类的子类,是专门来干这种事情的:
>>> from collections import Counter
>>> c = Counter( hello world )
>>> c
Counter({ l : 3, o : 2, : 1, e : 1, d : 1, h : 1, r : 1, w : 1})
>>> c.most_common(2)
[( l , 3), ( o , 2)]
这听起来显而易见,但经常被人忘记。对于大多数程序员来说,数一个东西是一项很常见的任务,而且在大多数情况下并不是很有挑战性的事情——这里有几种方法能更简单的完成这种任务。
Python的collections类库里有个内置的dict类的子类,是专门来干这种事情的:
>>> from collections import Counter
>>> c = Counter( hello world )
>>> c
Counter({ l : 3, o : 2, : 1, e : 1, d : 1, h : 1, r : 1, w : 1})
>>> c.most_common(2)
[( l , 3), ( o , 2)]
作者:郑子明
链接:https://zhuanlan.zhihu.com/p/442822146
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://zhuanlan.zhihu.com/p/442822146
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
04 漂亮的打印出JSON
JSON是一种非常好的数据序列化的形式,被如今的各种API和web service大量的使用。使用python内置的json处理,可以使JSON串具有一定的可读性,但当遇到大型数据时,它表现成一个很长的、连续的一行时,人的肉眼就很难观看了。
为了能让JSON数据表现的更友好,我们可以使用indent参数来输出漂亮的JSON。当在控制台交互式编程或做日志时,这尤其有用:
>>> import json
>>> print(json.dumps(data)) # No indention
{"status": "OK", "count": 2, "results": [{"age": 27, "name": "Oz", "lactose_intolerant": true}, {"age": 29, "name": "Joe", "lactose_intolerant": false}]}
>>> print(json.dumps(data, indent=2)) # With indention
同样,使用内置的pprint模块,也可以让其它任何东西打印输出的更漂亮。
JSON是一种非常好的数据序列化的形式,被如今的各种API和web service大量的使用。使用python内置的json处理,可以使JSON串具有一定的可读性,但当遇到大型数据时,它表现成一个很长的、连续的一行时,人的肉眼就很难观看了。
为了能让JSON数据表现的更友好,我们可以使用indent参数来输出漂亮的JSON。当在控制台交互式编程或做日志时,这尤其有用:
>>> import json
>>> print(json.dumps(data)) # No indention
{"status": "OK", "count": 2, "results": [{"age": 27, "name": "Oz", "lactose_intolerant": true}, {"age": 29, "name": "Joe", "lactose_intolerant": false}]}
>>> print(json.dumps(data, indent=2)) # With indention
同样,使用内置的pprint模块,也可以让其它任何东西打印输出的更漂亮。
07 连接
下面的最后一种方式在绑定两个不同类型的对象时显得很cool。
nfc = ["Packers", "49ers"]
afc = ["Ravens", "Patriots"]
print nfc + afc
>>> [ Packers , 49ers , Ravens , Patriots ]
print str(1) + " world"
>>> 1 world
print `1` + " world"
>>> 1 world
print 1, "world"
>>> 1 world
print nfc, 1
>>> [ Packers , 49ers ] 1
下面的最后一种方式在绑定两个不同类型的对象时显得很cool。
nfc = ["Packers", "49ers"]
afc = ["Ravens", "Patriots"]
print nfc + afc
>>> [ Packers , 49ers , Ravens , Patriots ]
print str(1) + " world"
>>> 1 world
print `1` + " world"
>>> 1 world
print 1, "world"
>>> 1 world
print nfc, 1
>>> [ Packers , 49ers ] 1
08 数值比较
这是我见过诸多语言中很少有的如此棒的简便法
x = 2
if 3 > x > 1:
print x
>>> 2
if 1 < x > 0:
print x
>>> 2
09 拉链迭代两个列表
nfc = ["Packers", "49ers"]
afc = ["Ravens", "Patriots"]
for teama, teamb in zip(nfc, afc):
print teama + " vs. " + teamb
>>> Packers vs. Ravens
>>> 49ers vs. Patriots
nfc = ["Packers", "49ers"]
afc = ["Ravens", "Patriots"]
for teama, teamb in zip(nfc, afc):
print teama + " vs. " + teamb
>>> Packers vs. Ravens
>>> 49ers vs. Patriots
10 带索引的列表迭代
teams = ["Packers", "49ers", "Ravens", "Patriots"]
for index, team in enumerate(teams):
print index, team
>>> 0 Packers
>>> 1 49ers
>>> 2 Ravens
>>> 3 Patriots
teams = ["Packers", "49ers", "Ravens", "Patriots"]
for index, team in enumerate(teams):
print index, team
>>> 0 Packers
>>> 1 49ers
>>> 2 Ravens
>>> 3 Patriots
11 列表推导式
已知一个列表,我们可以刷选出偶数列表方法:
numbers = [1,2,3,4,5,6]
even = [number for number in numbers if number%2 == 0]
已知一个列表,我们可以刷选出偶数列表方法:
numbers = [1,2,3,4,5,6]
even = [number for number in numbers if number%2 == 0]
12 字典推导
和列表推导类似,字典可以做同样的工作:
teams = ["Packers", "49ers", "Ravens", "Patriots"]
print {key: value for value, key in enumerate(teams)}
>>> { 49ers : 1, Ravens : 2, Patriots : 3, Packers : 0}
和列表推导类似,字典可以做同样的工作:
teams = ["Packers", "49ers", "Ravens", "Patriots"]
print {key: value for value, key in enumerate(teams)}
>>> { 49ers : 1, Ravens : 2, Patriots : 3, Packers : 0}
13 初始化列表的值
items = [0]*3
print items
>>> [0,0,0]
teams = ["Packers", "49ers", "Ravens", "Patriots"]
print ", ".join(teams)
>>> Packers, 49ers, Ravens, Patriots
15 从字典中获取元素
我承认try/except代码并不雅致,不过这里有一种简单方法,尝试在字典中找key,如果没有找到对应的alue将用第二个参数设为其变量值。
data = { user : 1, name : Max , three : 4}
is_admin = data.get( admin , False)
我承认try/except代码并不雅致,不过这里有一种简单方法,尝试在字典中找key,如果没有找到对应的alue将用第二个参数设为其变量值。
data = { user : 1, name : Max , three : 4}
is_admin = data.get( admin , False)
17 迭代工具
和collections库一样,还有一个库叫itertools,对某些问题真能高效地解决。其中一个用例是查找所有组合,他能告诉你在一个组中元素的所有不能的组合方式
from itertools import combinations
teams = ["Packers", "49ers", "Ravens", "Patriots"]
for game in combinations(teams, 2):
print game
>>> ( Packers , 49ers )
>>> ( Packers , Ravens )
>>> ( Packers , Patriots )
>>> ( 49ers , Ravens )
>>> ( 49ers , Patriots )
>>> ( Ravens , Patriots )
和collections库一样,还有一个库叫itertools,对某些问题真能高效地解决。其中一个用例是查找所有组合,他能告诉你在一个组中元素的所有不能的组合方式
from itertools import combinations
teams = ["Packers", "49ers", "Ravens", "Patriots"]
for game in combinations(teams, 2):
print game
>>> ( Packers , 49ers )
>>> ( Packers , Ravens )
>>> ( Packers , Patriots )
>>> ( 49ers , Ravens )
>>> ( 49ers , Patriots )
>>> ( Ravens , Patriots )


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix