

python 学习摘要 小知识点
python3字符串base64编解码
首先,Base64生成的编码都是ascii字符。
其次,python3中字符都为unicode编码,而b64encode函数的参数为byte类型,所以必须先转码。

import base64
s = "你好" bs = base64.b64encode(s.encode("utf-8")) # 将字符为unicode编码转换为utf-8编码 print(bs) # 得到的编码结果前带有 b>>> b'5L2g5aW9' bbs = str(base64.b64decode(bs), "utf-8") print(bbs) # 解码>>> 你好 bs = str(base64.b64encode(s.encode("utf-8")), "utf-8") print(bs) # 去掉编码结果前的 b>>> 5L2g5aW9 bbs = str(base64.b64decode(bs), "utf-8") print(bbs) # 解码>>> 你好
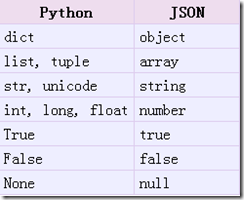
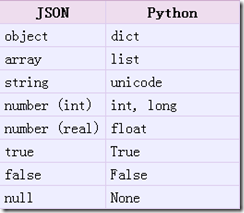
python中的json对象字符串转化
https://www.cnblogs.com/minsons/articles/8042101.html(有详细说明,转换表对比和注意事项等)
>>> import json # 导入json库 >>> json_str=json.dumps(data) # 字典转换为字符串 >>> type(json_str) <class 'str'> >>> d=json.loads(json_str) # 字符串转换为字典 >>> type(d) <class 'dict'>
计算运行时间
import timeit def sum_sqr_1(): li = list(range(10000)) print(timeit.timeit(stmt = sum_sqr_1, number = 1000))
列表表达式[List Comprehension]
顾名思义,这个表达式作用是以一个快捷的方法对列表进行操作或运算,返回新的列表。其使用方式为[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]。
#打印出100以内所有十位数比个位数大1位的数字 num = [ n1*10+n2 for n1 in range(0, 10) for n2 in range(0, 10) if n1 == n2+1 ] print(num)
匿名函数lambda函数
Lambda函数又称匿名函数,也有人称为lambda表达式。顾名思义,匿名函数就是没有名字的函数。函数没有名字也行?当然可以啦。有些函数如果只是临时一用,而且它的业务逻辑也很简单时,就没必要非给它取个名字不可。
lambda匿名函数的格式是 lambda 参数: 表达式。冒号前是参数,可以有多个,用逗号隔开,冒号右边的为表达式。其实lambda返回值是一个函数的地址,也就是函数对象。
flist = [lambda x:x*x for x in range(1, 3)] #函数列表 print(flist) print(flist[0]) print(flist[0](9))
zip函数
zip()函数来可以把2个或多个列表合并,并创建一个元组对的列表。元组对的数量以合并列表的最短长度为准。python 3中zip方法合并列表后生成的是zip对象,使用list方法可以将其变成列表,使用dict方法可以将其变成字典。
map函数
map函数是个非常有用的方法,其语法是 map(function, iterable, ...)。map方法可以接收函数作为参数,并将其映射于列表的多个元素。
#map函数的经典考题。我们有两个字符串A和B,现在要统计字符串A中有多少个字符也在字符串B中可以找到。 strA = "aAAAbBCCjjjj" strB = "aAsahajjsssjj" print(sum(map(strA.count, strB)))
reduce函数
reduce() 函数会对参数序列中元素进行累积。该方法第一个参数必需是函数,而且传入的函数必需要有2个参数,否则出现错误。该方法将一个数据集合(列表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
#reduce函数很适合连续计算(比如列表求和或连乘计算阶乘),经典代码如下。 from functools import reduce reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) reduce(lambda x, y: x*y, range(1, 5))
filter函数
Python的 filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该方法与map和reduce类似,第一个参数都是函数,作用于可以迭代的对象比如列表和元组,但不同的是filter方法传入的函数是判断性函数, 只有符合条件的列表元素才会加入新的列表。Python 2中返回列表,python 3中返回filter对象,使用list方法可以转化为列表。
#下面这段代码利用filter方法删除字符串列表里的空白字符串。只有满足s and s.strip() = True的字符串才会加入新的列表。 def not_empty(s): return s and s.strip() list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
enumerate() 函数
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,常见用于for循环。一般只有需要同时用到索引index和value值的时候才用enumerate方法。注意直接使用enumerate方法生成是个enumerate对象,可以遍历的。
name = ["John", "Lucy", "Mary"] name1 = enumerate(name) print(dict(name1))
defaultdict
defaultdict工作起来完全像一个普通的Python字典,但它有额外的奖励。当您试图访问一个不存在的键,它不会引发错误,而是使用不存在的键创建新的key,其对应的默认值是根据创建defaultdict对象时作为参数传递的数据类型自动设置的。请看下面的代码作为示例。
from collections import defaultdict names_dict = defaultdict(int) names_dict["Bob"] = 1 names_dict["Katie"] = 2 sara_number = names_dict["Sara"] #通用的dict方法会出错,这个不会 print(names_dict)
deque
deque队列是在计算机科学里最基本的数据结构,遵循先入先出(FIFO)的原理。简单来说,这意味着添加到队列中的第一个对象也必须是要删除的第一个对象。我们只能在队列的前面插入内容,而只能从队列的后面删除内容,而队列中间没有任何动作。
collections模块提供的deque对象是能实现队列数据结构的优化版本。该功能的主要特色是能够保持队列的大小,即如果将队列的最大长度设置为10,则将deque根据FIFO原理添加和删除元素以保持最大长度始终为10。这是到目前为止,Python中队列的最佳实现。
from collections import deque my_queue = deque(maxlen=10) for i in range(10): my_queue.append(i+1) print(my_queue) for i in range(10, 15): my_queue.append(i+1) print(my_queue) #结果 deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], maxlen=10) deque([6, 7, 8, 9, 10, 11, 12, 13, 14, 15], maxlen=10)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix