Redis相关知识
什么是 Redis?它主要用来什么的?
-
Redis是一个基于Key-Value存储结构的Nosql开源内存数据库。
-
它提供了5种常用的数据类型,String、Map、Set、ZSet、List。
-
它可以覆盖应用开发中大部分的业务场景,比如Top10问题、好友关注列表、热点话题等。
-
Redis是基于内存存储,并且在数据结构上做了大量的优化,所以IO性能比较好。在实际开发中,会把它作为应用与数据库之间的一个分布式缓存组件。
-
redis是非关系型数据库,不存在表之间的关联查询问题,所以它可以很好的提升应用程序的数据IO效率。
-
作为企业级开发来说,它又提供了主从复制+哨兵、以及集群方式实现高可用。在redis集群里面,通过hash槽的方式实现了数据分片,进一步提升了性能。
Redis 的基本数据结构类型
1.String(字符串)
-
String是Redis最基础的数据结构类型,它是二进制安全的,可以存储图片或者序列化的对象,值最大存储为512M。
-
应用场景
- 分布式锁(setnx)
- 计数器
- 限流
-
内部编码
- int —— 保存long型(长整型)的64位(8个字节)有符号整数,最多保存19位数字
- embstr —— 保存长度小于44字节的字符串
- raw —— 保存长度大于44字节的字符串
-
底层
- 使用SDS(simple dynamic string 简单动态字符串)封装。
-
为什么要重新设计一个SDS数据结构
- C语言获取字符长度需要从头开始遍历,时间复杂度为O(n)。SDS记录了当前字符串的长度,直接读取即可,时间复杂度为O(1)。
- 分配内存空间超过后,会导致数组下标越级或者内存分配溢出。SDS底层实现内存预分配和惰性空间释放,可有效解决内存溢出问题。
- 二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符。C语言在处理时可能读取数据不完全,SDS根据len长度来判断字符串结束,解决了二进制安全的问题。
空间预分配:字符串修改越频繁,内存空间分配就越频繁,就会消耗性能。而SDS修改和空间扩容,会额外分配未使用的空间,减少性能损耗。
惰性空间释放:SDS缩短时,不是回收多余的内存空间,而是free记录下多余的空间,后续有变更,直接使用free中记录的空间,减少分配。
2.Hash(哈希)
-
应用场景
- 缓存用户信息
-
底层
- Redis6中:Hash字段键的字段个数小于hash-max-ziplist-entries并且每个字段名和字段值的长度小于hash-max-ziplist-value时,底层使用ziplist存储,反之使用hashtable存储。Resdis7中使用listpack替代了zipList。
hash-max-ziplist-entries:使用压缩列表保存时哈希集合中的最大元素个数
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度
-
为什么设计使用ziplist压缩链表
- 普通的双向链表会有两个指针,在存储数据很小的时候,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失。zipList没有维护双向指针,而是存储上一个entry的长度和当前的长度,通过长度推算下一个元素在什么地方,牺牲读取的性能,获得高效的存储空间。
- 链表在内存中是不连续的,遍历比较慢。
- 压缩链表的头节点存储了链表的长度,获取链表的长度时间复杂度为O(1)。
-
为什么使用listpack替代zipList
- zipList有连锁更新问题,因为每个节点存储了上一个节点的长度。
- listpack通过每个节点记录自己的长度且放在节点的尾部。
3.list列表
-
双端链表的数据结构,最多可以存储2^32-1个元素
-
应用场景
- 栈、队列、有限集合、消息队列
-
底层
- 使用quickList数据结构存储,本质是zipList+linkedList
4.Set集合
-
使用场景
- 用户标签、生成随机数抽奖、社交需求
-
底层
- 使用intSet或hashTable存储。
- 集合元素都为longlong类型,且元素个数<=set-max-intset-entries(默认512)就是使用intset,反之使用hashTable。
5.ZSet有序集合
-
使用场景
- 排行榜,社交需求(如用户点赞)
-
底层
- 当元素个数超过zset-max-zipList-entries(默认128)或者添加元素长度超过zset-max-zipList-value(默认64)时,使用跳表skipList实现,否则使用zipList。
-
为什么要使用跳表
- 跳表是一种可以实现二分查找的有序链表。
- 链表无法进行二分查找,所以借鉴数据库索引的思想,提取出链表中的关键节点,现在节点上查找,再进入下层链表查找。
- 索引也需要占据一定空间,所以索引添加的越多,空间占用的越多。
Redis为什么这么快
- redis是基于内存存储实现
- 高效的数据结构
- SDS简单动态字符串
- 跳跃表
- reids作为K-V内存数据库,所有的键值都是用字典来存储,查询时间复杂度为O(1)
- 合理的数据编码
- 每种类型,可能对多种数据结构。什么时候使用什么样的数据结构,使用什么编码,是redis设计总结优化的结果。
- IO多路复用
- IO多路复用可以让单个线程高效的处理多个连接请求。
- 核心思想是让单个线程去监视多个连接,一旦某个连接就绪,就通知应用程序去获取这个就绪的连接进行读写操作。
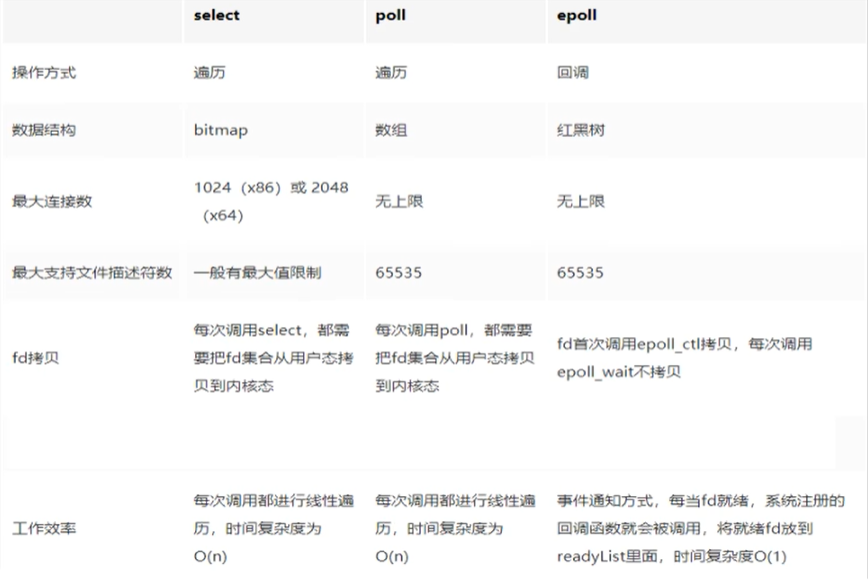
- IO多路复用的三种模型
- select —— 采用轮询和遍历的方式
- poll —— 也是轮询加遍历,只不过采用链表的方式来存储
- epoll —— 将轮询改为了回调,大大提高了CPU执行效率,不会随FD数量的增加而导致效率下降
IO可以理解为,在操作系统中,数据在内核态和用户态之间的读、写操作,大部分情况下是指网络IO;
多路大部分情况下是指多个TCP连接,也就是多个Socket 或者多个Channel;
复用是指复用一个或多个线程资源;
IO多路复用意思就是说,一个或多个线程处理多个 TCP 连接。尽可能地减少系统开销,无需创建和维护过多的进程/线程。
什么是缓存击穿、缓存穿透、缓存雪崩
什么是缓存:读请求来了,先查询缓存,缓存有值命中,则直接返回。缓存没命中,就去查询数据库,然后把数据库的值更新到缓存,再返回读取缓存。
1.缓存穿透
-
查询一个一定不存在的数据,由于缓存不命中时需要从数据库查询,查不到数据则不写入缓存,所以导致这个请求每次访问都要到数据库去查询。
-
产生情况
- 业务不合理设计
- 业务/运维/开发失误的操作,比如缓存和数据库的数据都被误删除了
- 恶意非法攻击,黑客故意捏造大量非法请求,攻击数据库
-
解决方案
- 对参数进行校验
- 空对象缓存或缺省值 —— 如果查询缓存和数据库都为空,则设置一个空值,防止下次查询依旧要查询数据库。
- 布隆过滤器
- 由一个初值为0的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素。
- 一个key进行N个hash算法获取N个值,在bit数组中将这N个值散列后设定为1,查的时候如果这N个值的位置都为1,则判断该key存在。
- 一个元素判断结果如果存在时,元素不一定存在。判断不存在时,则一定不存在。
- 可以增加元素,但是不能删除元素。因为一个bit数组的坑位可能属于多个key值
2.缓存雪崩
-
redis主机挂了或者redis有大量的key同时过期。
-
预防和解决
- redis的key设置永不过期或者过期时间错开
- redis集群实现高可用
- 多缓存结合预防雪崩 —— ehcache本地缓存 + redis缓存
- 服务降级
- 使用云数据库redis
3.缓存击穿
-
大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上。
-
解决方案
- 差异失效时间 —— 对于频繁访问的热点key,不设置过期时间
- 互斥更新 —— 双检加锁策略
- AB双缓存架构 —— 开启两块缓存,主A从B,先更新B再更新A
双检枷锁策略:
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如有直接返回结,如没有再去查mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == nul1) {
//2 大厂用,对于高OPS的优化,进来就先加锁,保证一个请求作,让外面的redis 等待一下,避免击穿mysql
synchronized (UserService.class) {
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysgl数据
user = userMapper.selectByPrimaryKey(id);
//mysql有数据默认
if (user == nu11) {
return null;
} else {
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setifAbsent(key,user, timeout: 7L,TimeUnit,DAYS);
}
}
}
}
return user;
什么是热Key问题,如何解决热Key问题
Redis中,我们频繁频率高的key,就是热key。如果某一热key的请求到达服务器主机时,由于请求量特别大,可能会导致主机资源不足,甚至宕机,从而影响正常的服务。
-
产生原因
- 用户消费的数量远大于生产的数量,如秒杀、热点新闻等读多写少的场景。
- 请求分片集中,超过单redis服务器的性能,如固定名称key,Hash落入同一台服务器中,瞬间访问量极大,超过机器瓶颈。
-
如何解决
- Redis集群扩容,增加分片副本,均衡读取流量
- 将热key分散到不同的服务器中
- 使用本地缓存,减少redis的读请求
Redis过期策略和内存淘汰策略
过期策略
-
定时删除 —— 键值只要过期了就会立即删除,会产生大量的性能消耗
-
惰性删除 —— 键值过期了,不立即删除。而是等下次访问的时候,如果过期,再删除
-
定期删除
- 每间隔一段时间,执行一次删除过期键操作
- 定期抽样,判断是否有过期的key
- 是一种折中的方案,仍会有漏网之鱼(过期的key一直未删除)
内存淘汰策略
-
noeviction:默认策略,不会删除任何key,所有能引起内存增加的命令都会报错。
-
allkeys-lru:优先删除最近最不经常使用的key。
-
volatile-lru:对所有设置了过期时间的key使用LRU算法进行删除。
-
allkeys-random:对所有key随机删除。
-
volatile-random:对所有设置了过期时间的key进行随机删除。
-
volatile-ttl:删除马上要过期的key。
-
allkeys-lfu:优先删除最不经常使用的key。
-
volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除。
在redis正常运行中,会有过期策略以维护redis的使用效率。当内存仍然占满后,有内存淘汰策略进行兜底,以维持redis的正常使用。
说说 Redis 的常用应用场景
-
缓存
-
排行榜
- 使用zset数据结构
-
计数器应用
-
共享Session
-
分布式锁
-
社交网络
-
消息队列
-
位操作
Redis 持久化有哪几种方式,怎么选?
RDB
-
以指定的时间间隔执行数据集的时间点快照
-
什么情况会触发RDB快照
- 配置文件中默认的快照配置,每隔多少秒有多少条数据新增,则自动触发RDB快照
- 手动save/bgsave命令,save命令是同步快照,bgsave是异步快照
- flushall/flushdb
- shutdown且没有设置开启AOF持久化
- 主从复制时,主节点自动触发
-
优点
- 适合大规模的数据恢复
- 按照业务定时备份
- 对数据完整性和一致性要求不高
- RDB文件在内存中的加载速度比AOF要高
-
缺点
- 会丢失数据
- 内存数据的全量同步,如果数据量太大会导致IO严重影响性能
- RDB依赖于主程序的fork,在更大的数据集中,这会导致服务请求的瞬间延迟。fork的时候,内存中数据被克隆了一份,大致两倍的膨胀性,需要考虑。
AOF
-
redis把数据变更的命令追加到aof缓冲区的末尾,再根据制定的写回策略,把缓冲区的内容写回到磁盘中。当aof文件的大小达到某个阈值的时候,就会把这个文件里面相同的指令进行压缩。
-
写回策略
- 同步回写,每个写命令执行完后立刻同步地将日志写回磁盘
- (默认)每秒写回,每个写命令执行完,只是先把日志写到AOF的内存缓冲区,每隔1秒把缓冲区中的内容写入磁盘
- 操作系统控制的写回,每个写命令执行完,只先把日志写回到AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
-
重写机制
- 自动触发:默认当aof文件大小是上次重写后大小的一倍且文件大于64M时触发
-
优点
- 更好的保护数据不丢失,默认每一秒写回一次,所以最多丢失一秒的数据。
- 性能高
- 可做紧急恢复,因为AOF是指令追加的方式,所以命令会一直保存在磁盘中
-
缺点
- 相同数据集的数据而言,aof文件要远大于rdb文件,恢复速度慢
- aof运行效率要慢于rdb
混合持久化
-
redis重启的时候,优先加载aof文件来恢复原始的数据
-
rdb做全量持久化,aof做增量持久化
-
先使用RDB做快照存储,再使用aof持久化记录所有写操作,当重写策略满足或手动触发重写的时候,将最新的数据存储为新的RDB记录。这样,重启的时候,就会从RDB和AOF两部分恢复数据,既保证数据完整性,又提高了恢复数据的性能。
怎么实现Redis的高可用?
主从复制
-
主机以写为主,从机以读为主
-
工作流程
- slave启动,同步初请
- slave启动成功连接到master后,会发送一个sync命令
- 首次连接,全量复制
- master节点收到sync命令后会开始在后台保存快照,同时收集所有接受到的用于修改数据集命令缓存起来,master执行完RDB持久化后,master将rdb快照文件和所有缓存的命令发送到所有slave,以完成一次完全同步。
- slave服务接受到数据库文件数据后,将其存入磁盘并加载到内存中,完成复制初始化。
- 心跳持续,保持通信
- master发出PING包的周期,默认每10秒一次
- 进入平稳,增量复制
- master继续将新的所有收集到的修改命令自动依次传给slave,完成同步。
- 从机下线,重连续传
- master会检查backlog里面的offset,master和slave都会保存一个复制的offset还有一个masterId,offset是保存在backlog中的。master只会把已经复制的offset后面的数据复制给slave。
- slave启动,同步初请
-
缺点
-
从master复制到slave上时,有一定的延时,当系统繁忙时,延迟问题会更严重
-
master挂了,默认不会在slave中自动重选一个master,每次都需人工干预
-
哨兵
-
吹哨人巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转换为新主库,继续对外服务。
-
如何重新选择主库
- 新主登基
- 在剩余健康的节点中选择
- 首先在redis.conf文件中,看谁的slave-priority或者replica-priority最高。再看复制偏移量位置offset谁最大。如果都一样,最后在取Run ID最小的从节点。
- 群臣俯首
- 执行slaveof no one命令让选出来的从节点成为新的主节点,并通过slaveof命令让其它节点成为其从节点。
- 旧主拜服
- 将之前已经下线的老master设置为新选出的新master的从节点。
- 新主登基
-
由哪个哨兵执行主从切换呢
- 一个哨兵标记主库为主观下线后,它会征求其他哨兵意见,确认主库是否确认进入主观下线状态。向其他哨兵发送
is-master-down-by-addr命令,其他哨兵回复Y或N,如果这个哨兵获得足够多的赞成票数,主库会被标记为客观下线。 - 标记主库客观下线的哨兵,再次发送命令,希望由它来执行主从复制(被成为Leader选举)。
- Leader需要满足两个条件:
- 需要拿到
num(sentinels)/2+1赞成票 - 拿到的票数需大于哨兵配置文件中设置的
quorum值
- 需要拿到
- 一个哨兵标记主库为主观下线后,它会征求其他哨兵意见,确认主库是否确认进入主观下线状态。向其他哨兵发送
集群
-
由于数据量过大,单个master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分。
-
槽位slot
- 集群的密钥空间分为16384个槽,有效设置了16384个主节点的集群大小上限(建议最大节点为1000个节点)
- 集群中每个主节点处理16384个哈希槽的一个子集。
- 每个key根据CRC16算法校验取模来决定放在哪个槽。
-
分片
- 使用redis集群时我们会将存储的数据分散到多台redis机器上,集群中的每个redis实例都被认为时整个数据的一个分片。
- 优势
- 方便扩缩容和数据分派查找
-
slot槽位映射
-
哈希取余
- hash(key) % N个机器台数
- 根据求得key的hash值,在根据redis集群的数量取余,来决定数据映射到哪一个节点上。
- 优点:简单粗暴,直接有效,只需要预估好数据规划好节点,就能保证一段时间的数据支撑。
- 缺点:不管是扩容还是缩容,映射关系需要重新计算,导致根据公式获取的服务器变得不可控。
-
一致性hash算法
- 为了解决分布式缓存数据变动和映射问题。
- 三大步骤:
- 算法构建一致性hash环。hash算法产生的hash值构成一个全量集,成为一个hash空间[0,232],这是一个线性空间,但在算法中,我们通过适当的逻辑控制将它首尾相连,使它在逻辑上形成了一个环形空间。key仍然按照取模的方式(对232取模),但是始终会落在圆环的一个点上。
- redis服务器IP节点映射。将集群中各个IP节点映射到环上的某一个位置(通过求各个节点IP的hash值)。
- key落到服务器的落键规则。求key的hash值,缺点此数据在环上的位置,然后从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值存储在该节点上。
- 优点
- 容错性:一个节点宕机了,不会影响其他的节点,受影响的数据仅仅是此服务器到其环形空间中前一台服务器(逆时针)。
- 扩展性:新增一台节点,只需将节点加入到环上,不会导致hash取余全部数据重新洗牌。
- 缺点:数据倾斜问题,节点分布不均匀会导致数据倾斜,导致大量数据集中缓存在一台服务器上。
-
哈希槽分区
- 实质是一个数组,数组[0,2^14-1]形成hash slot空间。
- 解决均匀分配的问题,在数据和节点之间又加入了一层,相当于redis节点上放的是槽,槽里面放的是数据。
- 为什么redis集群的最大槽数是16384个
- 每秒钟,redis需要发送一定数量的ping消息作为心跳包,如果槽位是65536,发送心跳信息的消息头达8k,发送心跳包过于庞大,浪费带宽。
- redis集群主节点数量基本不可能超过1000个,节点过多会导致网络拥堵。对于1000以内的redis集群,16384个槽位够用了。
- 槽位越小,节点少的情况下,压缩比高,容易传输。Redis主节点的配置信息中,它所负责的哈希槽是通过bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,如果bitmap的填充率
slots/N个节点很高的话,bitmap的压缩率就很低。如果节点很少,哈希槽数量很多的话,bitmap的压缩率就很低。
-
-
Redis集群不保证强一致性,可能会丢掉一些被系统收到的写入请求命令。
-
在一台服务器上新增key,可能会报错,因为该key所在的槽位是路由到其他服务器上的,不是在当前节点上,所以新增会报错。防止路由失效,在启动的时候加上-c。
-
故障转移
- redis集群通过ping/pong消息,实现故障发现。
- 当一个节点认为另一个节点不可用,即节点A向节点B发送ping消息,B节点未向A节点回复pong消息,A节点会将B节点标记为主观下线。
- A节点通过消息把节点B状态发到其他节点,节点C接受到消息并解析出消息体,如果发现B节点是pfail状态时,会触发客观下线流程。
- 维护故障列表,尝试客观下线,计算有效下线报告数量,如果超过半数的节点认为节点B下线,则将节点B标记为客观下线。
- 故障发现后,如果下线节点是主节点,需要在它的从节点中选一个替换它。
-
故障恢复
- 资格检查:检查从节点最后与主节点断线时间,判断是否有资格替换故障的主节点。
- 准备选举时间:当从节点符合故障转移资格后,更新触发故障选举时间,只有到达该时间后才能执行后续流程。
- 发起选举:更新配置纪元,广播选举消息
- 选举投票:只有主节点才有票,从节点收集到足够选票(大于一半),才能触发替换主节点操作
- 替换主节点
使用过 Redis 分布式锁嘛?有哪些注意点呢?
-
单机版加锁
lock()、unlock(),不满足高并发分布式锁的性能要求,会出现超卖。 -
自研一把分布式锁要实现java.util.concurrent.locks.Lock接口规范
-
迭代
-
使用redis做分布式锁,用
setnx命令,为当前线程加锁setnx lock uuid,其他线程只能自选等待当前线程释放锁del lock。 -
如果当前线程加完锁,未解锁时服务器宕机了,导致未解锁,则后面线程永远拿不到锁。所以需要设置过期时间
setnx lock expire uuid。 -
因为锁设置了过期时间,如果过期时间内,业务仍未执行完(即没删除锁,但锁自动过期了),等到其他线程获得锁后,当前线程执行删除锁操作,把别人的锁删除了,导致数据混乱。所以需要设置只能删除自己的锁。在删除锁的时候需要先查询当前锁是否是自己的锁,即
get lock是否等于自己生成的uuid。 -
因为判断当前锁是否是自己持有的锁和删除操作不是原子操作,所以需要使用lua脚本。
-
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else " +
return 0
end
- 以上可以解决大部分分布式锁问题,但缺少可重入性,即在一个线程获取到锁后,在执行业务代码时又加了一道锁,因为是同一个线程,所以应该满足可重入性,当前线程应该可以在未释放锁的情况下拿到第二把锁。此时需要使用hset。
使用过 Redisson 嘛?说说它的原理
- 分布式锁可能存在锁,业务没执行完的问题。可以在获取锁成功之后,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间进行延长,防止锁过期提前释放。
什么是Redlock算法
-
线程1获取到锁成功,将键值对写入redis的master节点,在redis将该键值对同步到slave节点之前,master发生了故障;redis触发了故障转移,其中一个slave升级为新的master,此时新上位的master不包含线程1写入的键值对,因此当线程2尝试获取锁也能够成功拿到锁,此时相当于有两个线程获取到了锁,可能会导致各种预期之外的情况发生,例如脏数据。
-
Redlock算法
-
用来实现多个实例的分布式锁。
-
设计理念
- 获取当前时间,以毫秒为单位
- 依次尝试从5个实例,使用相同的key和随机值(例如uuid)获取锁。当向redis请求获取锁时,客户端应该设置一个超时时间(如果你的锁自动失效时间为10s,则超时时间应该在5-50ms之间),这个超时时间应该小于锁的失效时间。这样可以防止客户端在试图与一个宕机的Redis节点对话时长时间处于阻塞状态。如果一个实例不可用,客户端应该是尽快尝试去另外一个Redis实例请求获取锁。
- 客户端通过当前时间减去步骤1记录的时间来计算获取锁使用的时间。当且仅当从大多数(N/2+1)的Redis节点都取到锁,并且获取锁使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,其真正有效时间等于初始有效时间减去获取锁所使用的时间(步骤c计算的结果)
- 如果由于某些原因未能获取锁
无法在至少N/2+1个Redis实例获取锁、或获取锁的时间超过了有效时间,客户端应该在所有Redis实例上进行解锁
-
Mysql与Redis如何保证双写一致性
延时双删
-
客户端发送一个写请求,先删除缓存
-
再更新数据库
-
休眠一会(这个时间要大于读业务逻辑耗时+几百毫秒,即为了确保写请求可以删除读请求可能带来的脏数据),再次删除缓存
删除缓存重试机制
-
因为延时双删可能会存在第二步删除缓存失败,导致数据不一致问题。所以该机制是保证二次删除缓存成功。
-
流程
- 写请求更新数据库
- 缓存因为某些原因,删除失败
- 把删除失败的key放在消息队列中
- 消费消息队列的消息,获取要删除的key
- 重试删除缓存操作
读取binlog异步删除缓存
-
删除缓存重试机制会造成好多业务代码入侵,使用binlog异步删除优化。
-
流程
- 更新数据库数据
- 数据库会将操作信息写入binlog日志当中
- 订阅程序提取出所需要的数据以及key
- 另起一段非业务代码,获取该信息
- 尝试删除缓存操作,发现删除失败
- 将这些信息发送至消息队列
- 重新从消息队列中获取该数据,重试操作
Redis存在线程安全问题吗?为什么?
-
Redis Server是一个线程安全的K-V数据库,不存在线程安全问题。
-
在Redis6.0中,增加了多线程,但是增加的多线程只是用来处理网络IO事件,对于指令的执行过程,仍然是由主线程来处理,所以不会存在多个线程通知执行操作指令的情况。
-
因为CPU不是Redis的瓶颈点,如果采用多线程,则必须考虑线程安全问题,需要加锁,这种方式带来的性能影响反而更大,所以没必要使用多线程来执行指令。
-
Redis中的指令执行是原子的,如果有多个Redis客户端同时执行多个指令时,就无法保证原子性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix