redis大数据统计
一、大数据统计
1.1. 亿级系统中常见的四种统计
1.1.1 聚合统计
- 统计多个集合元素的聚合结果,就是前面讲解过的交差并等集合统计
- 交并差集和聚合函数的应用
1.2. 排序统计
问:抖音短视频最新评论留言的场景,请你设计一个展现列表。
答:在面对需要展示最新列表、排行榜等场景时如果数据更新频繁或者需要分页显示,建议使用ZSet
1.3. 二值统计
- 集合元素的取值就只有0和1两种在钉钉上班签到打卡的场景中,我们只用记录有签到(1)或没签到(0)
- 见bitmap
1.4. 基数统计
- 指统计一个集合中不重复的元素个数
- 见hyperloglog
1.2. hyperloglog
1.2.1 什么是UV
- Unique Visitor,独立访客,一般理解为客户端IP
- 需要去重考虑
- 一个用户一天无论浏览了页面多少次,UV都是1
1.2.2 什么是PV
- Page View,页面浏览量
- 不用去重
- 一个用户一天浏览了页面多少次,PV就是多少
1.2.3 什么是DAU
- Daily Active User
- 日活跃用户量 —— 登录或者使用了某个产品的用户数(去重复登录的用户)
- 常用于反映网站、迈联网应用或者网络游戏的运营情况
1.2.4 什么是MAU
- Monthly Active User
- 月活跃用户量
1.2.5 统计需求
- 很多计数类场景,比如每日注册 IP每日访问 IP 数、页面实时访问数 PV、访问用户数 UV等。
- 因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
- 统计单日一个页面的访问量(PV),单次访问就算一次。
- 统计单日一个页面的用户访问量(UV),即按照用户为维度计算,单个用户一天内多次访问也只算一次。
- 多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
1.2.6 HyperLogLog结构
去重复统计功能的基数估计算法
用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
- Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
- 在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数内存就越多的集合形成鲜明对比。这和计算基数时,元素越多耗费
- 但是,因为 HyperLoaLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各元素。
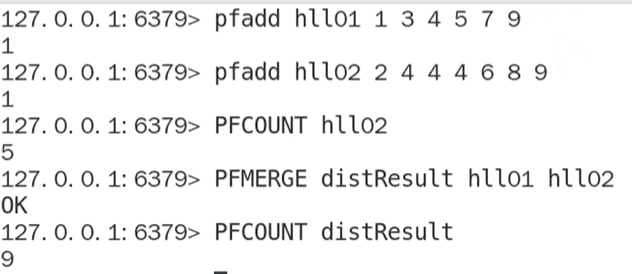
1.2.7 HyperLogLog基本命令
| 命令 | 作用 |
|---|---|
| pfadd key element ... | 将所有元素添加到key中 |
| pfcount key | 统计key的估算值(不精确) |
| pgmerge new_key key1 key2 .. | 合并key至新key |
示例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号