mysql索引
一、索引
1.1. 索引的数据结构
1.1.1. 索引的优缺点
索引是帮助mysql高效获取数据的数据结构。
- 优点
- 降低数据库的IO成本,提升数据检索的效率。
- 创建唯一索引,可以保证数据的唯一性。
- 可以加速表和表的连接,对于有依赖关系的字表和父表联合查询时,可以提升查询效率。
- 减少查询中分组和排序时间。
- 缺点
- 创建索引和维护索引要耗费时间,随着数据量的增加,所耗费的时间也会增加。
- 索引需要占磁盘空间。
- 降低更新表的速度。
索引可以提高查询的速度,但是会影响插入记录的速度。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
1.1.2. 索引的设计
1.2 索引的分类
1.2.1 聚簇索引和非聚簇索引
- 聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式(所有的用户记录都存储在了叶子节点),也就是
所谓的索引即数据,数据即索引。
术语:“聚簇”表示数据行和相邻的键值聚簇的存储在一起。
优点:
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚族索引更快
- 聚簇索引对于主键的 排序查找 和 范围查找 速度非常快
- 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以 节省了大量的io操作。
缺点:
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式I 否则将会出现页分裂,严重影响性能。因此,对于innoDB表,我们一般都会定义一个自增的ID列为主键
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于innoDB表,我们一般定义主键为不可更新
- 二级索引访问需要两次索引查找 ,第一次找到主键值,第二次根据主键值找到行数据
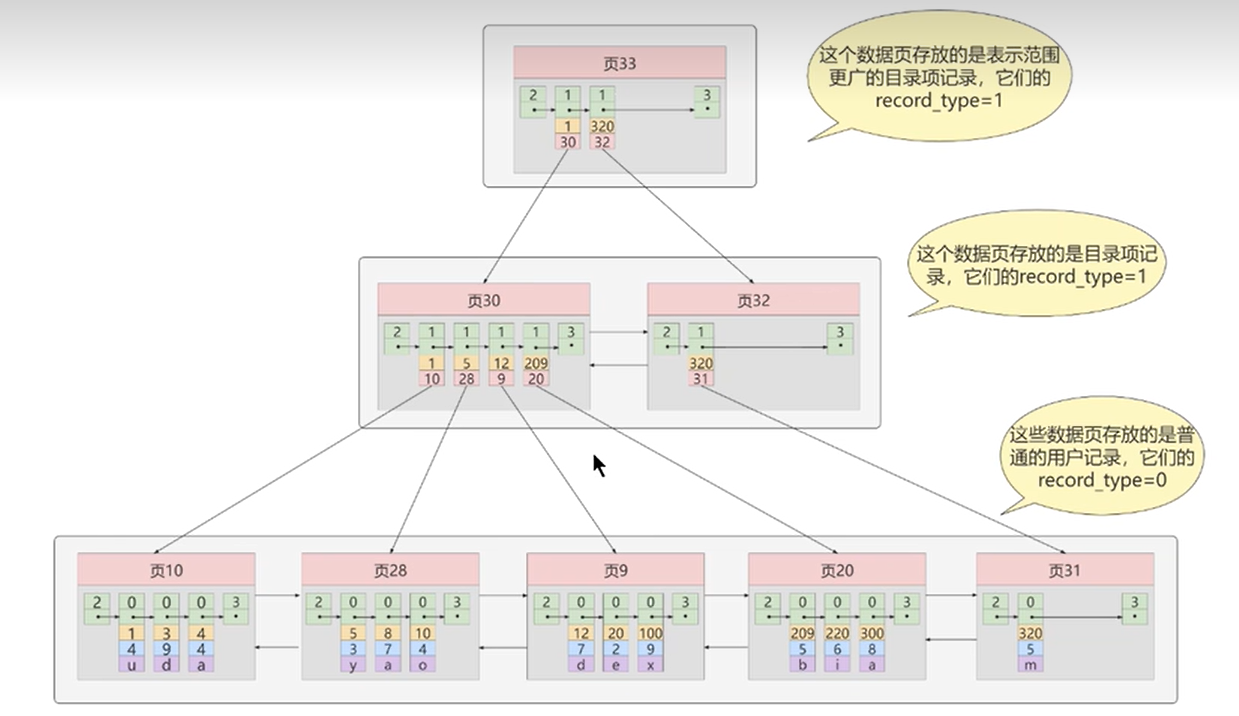
1.2.2 B+树的注意事项
- 根页面的位置万年不动
- 每当为某个表创建一个B+树索引(聚族索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个根节点 页面。最开始表中没有数据的时候,每个B+树索引对应的 根节点 中既没有用户记录,也没有目录项记录,
- 随后向表中插入用户记录时,先把用户记录存储到这个 根节点 中
- 当根节点中的可用 空间用完时 继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a 中,然后对这个新页进行 页分裂 的操作,得到另一个新页,比如 页b 。这时新插入的记录根据键值 (也就是聚簇索引中的主键值,二级索引中对应的索列的值)的大小就会被分配到页a 或者 页b 中,而 根节点 便升级为存储目录项记录的页。
- 内节点中目录项记录的唯一性
- 二级索引的目录项记录中也保存了主键值
- 一个页面最少存储两条记录
1.2.3 MyISAM与InnoDB对比
MylSAM的索引方式都是“非聚族”的,与lnnoDB包含1个聚族索引是不同的。小结两种引擎中索引的区别:
①在nnoDB存储引擎中,我们只需要根据主键值对 聚索引进行一次查找就能找到对应的记录,而在 MyISAM 中却需要进行一次 回表 操作,意味着MyISAM中建立的索引相当于全部都是 二级索引。
②lnnoDB的数据文件本身就是索引文件,而MylSAM索引文件和数据文件是 分离的,索引文件仅保存数据记录的地址。
③nnoDB的非聚簇索引data域存储相应记录 主键的值,而MylSAM索引记录的是地址。换句话说,innoDB的所有非聚簇索引都引用主键作为data域。
④MylSAM的回表操作是十分 快迷 的,因为是拿着地址偏移量直接到文件中取数据的,反观innoDB是通过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问。
⑤InnoDB要求表必须有主键 (MyISAM可以设有)。如果没有显式指定,则MySQL系统会自动选择一个可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。
1.3 一级目录3
1.3.1 二级目录5
内容5


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?