Neo4j基础
Neo4j基础
1.Windows环境下Neo4j下载安装
1.1Java安装

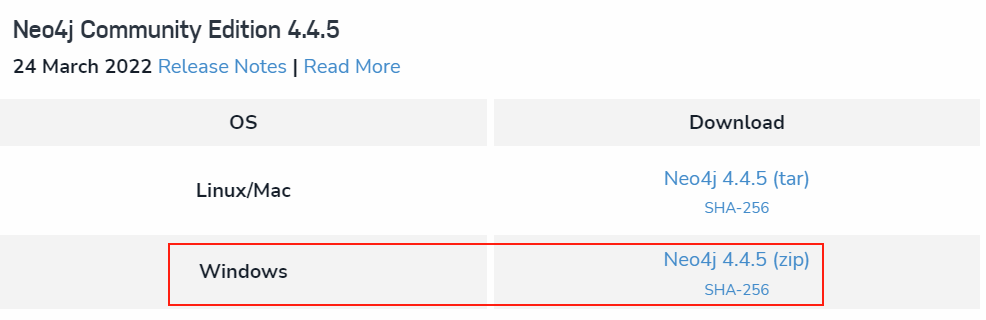
1.2Neo4j下载
1.3启动服务
cd D:\Neo4j\bin
#输入neo4j console启动服务
neo4j console
默认用户名和密码都是neo4j
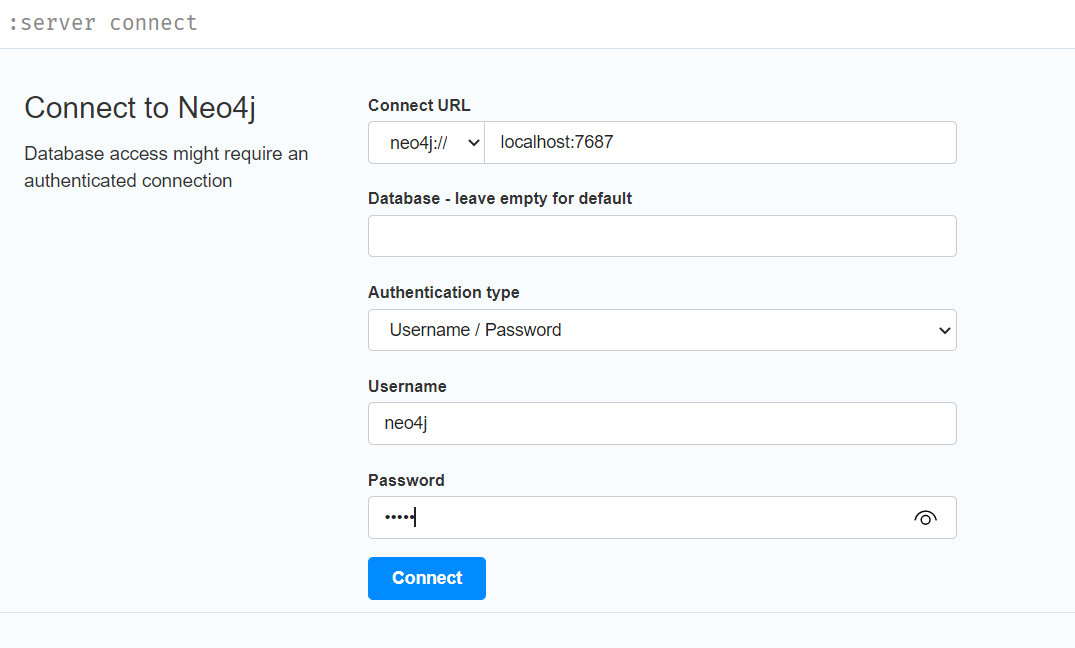
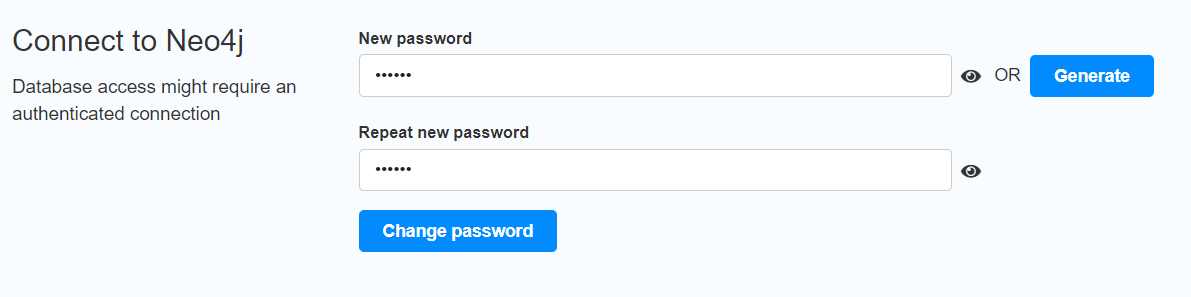
注:修改密码:123456
2.图数据库基础知识
图数据库以图这种数据结构为基础,可以保存任意种类的数据。
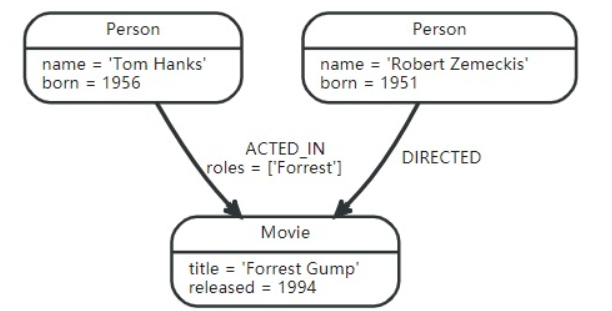
1.节点(Nodes)
表示图数据库的实体(entities),代表图数据库中的数据记录。上图中的圆角矩形即代表图数据库中的一个节点。
2.关系(Relationships)
描述节点之间的关系,关系总是有方向并且有一个类型的,一个节点也可以和自己有关系。上图中的箭头便代表关系,ACTED_IN和DIRECTED表示关系的类型。
3.属性(Properties)
用来保存数据,表示方法为name/value对,属性值可以有多种数据类型,比如数字、字符串和布尔值。节点和关系都可以有自己的属性,比如name='Tom Hanks'是一个节点的属性,roles=['Forrest']是一个关系的属性。
4.标签(Labels)
用来关联一系列相关的节点,表示一组相关节点的域,没有属性。比如表示人的节点可以使用标签:Person,表示关系的类型为出演也使用标签:ACTED_IN。在执行图数据库操作时可以在限定的标签域上进行。
5.模式(Schema)
Neo4j中的模式指的是索引(indexes)和约束(constraints)。不过Neo4j中的模式是可选的,即创建索引和约束不是必须的。索引可以提高性能,约束可以确保数据遵守领域规则。
6.Neo4j Browser
Neo4j Browser是一个命令驱动的客户机,适合运行即时的图查询语句。下载Neo4j Desktop之后,启动工程后,在浏览器输入http://localhost:7474/browser/ 便可以使用。在Neo4j Browser中:
- 开发人员只需要注重使用Cypher编写和运行图查询语句
- 任何查询结果可以导出为
表格 - 查询结果可以使用包含节点和关系的可视化图形展示
- Cypher语句编辑框在浏览器上部,起始符为$。若想多行输入,以< shift+enter > 换行,使用
< ctrl+enter >运行查询。
Neo4j Browser中也有指导教程,在编辑框输入:play start便可以开始探索Neo4j Browser了。
3.基础语法
3.1Values and types值和类型
Property types 属性类型
Integer, Float, String, Boolean, Point, Date, Time, LocalTime, DateTime, LocalDateTime, and Duration.
整数、浮点数、字符串、布尔值、点、日期、时间、 LocalTime、 DateTime、 LocalDateTime 和 Duration。
Structural types 结构类型
Node, Relationship, and Path.
节点、关系和路径。
Composite types 复合类型
List and Map.
清单及地图。
3.2Naming rules and recommendations命名规则和建议
Here are the recommended naming conventions:
以下是建议的命名约定:
| Node labels节点标签 | Camel-case, beginning with an upper-case character驼峰式大小写,以大写字母开头 | :VehicleOwner rather than :vehicle_owner etc.车主,而不是: 车主。 |
|---|---|---|
| Relationship types关系类型 | Upper-case, using underscore to separate words大写,使用下划线分隔单词 | :OWNS_VEHICLE rather than :ownsVehicle etc.拥有车辆而不是: 拥有车辆等。 |
3.3Expressions表达式
3.3.1Expressions in general 一般用语
如果 Cypher 中的大多数表达式的任何一个内部表达式都是 null,那么它们的计算结果都是 null。值得注意的例外是运算符 isnull 和 isnotnull。
-
A decimal (integer or float) literal:
13,-40000,3.14十进制(整数或浮点数)文字量: 13,-40000,3.14
-
A decimal (integer or float) literal in scientific notation:
6.022E23.一个十进制(整数或浮点数)字面科学记数法: 6.022 E23。
-
A hexadecimal integer literal (starting with
0x):0x13af,0xFC3A9,-0x66eff.十六进制整数文字(以0x 开始) : 0x13af,0xFC3A9,-0 x66eff。
-
An octal integer literal (starting with
0oor0):0o1372,02127,-0o5671.一个八进制整数文字(以0o 或0开头) : 0o1372,02127,-0o5671。
-
A string literal:
'Hello',"World".字符串: “ Hello”,“ World”。
-
A boolean literal:
true,false.一个布尔值: true,false。
-
A variable:
n,x,rel,myFancyVariable,A name with weird stuff in it[]!.变量: n,x,rel,myFancyVariable,‘ a name with weird stuff in it [] !’。
-
A property:
n.prop,x.prop,rel.thisProperty,myFancyVariable.``(weird property name).属性: n.prop,x.prop,rel.thisProperty,myFancyVariable. ‘(奇怪的属性名)’。
-
A dynamic property:
n["prop"],rel[n.city + n.zip],map[coll[0]].动态属性: n [“ prop”] ,rel [ ; city + n.zip ] ,map [ coll [0]]。
-
A parameter:
$param,$0.参数: $param,$0。
-
A list of expressions:
['a', 'b'],[1, 2, 3],['a', 2, n.property, $param],[].表达式列表: [‘ a’,‘ b’] ,[1,2,3] ,[‘ a’,2,n.property,$param ] ,[]。
-
A function call:
length(p),nodes(p).函数调用: length (p) ,nodes (p)。
-
An aggregate function:
avg(x.prop),count(*).聚合函数: avg (x.prop) ,count (*)。
-
A path-pattern:
(a)-[r]->(b),(a)-[r]-(b),(a)--(b),(a)-->()<--(b).路径模式: (a)-[ r ]-> (b) ,(a)-[ r ]-(b) ,(a)--(b) ,(a)--> () <--(b)。
-
An operator application:
1 + 2,3 < 4.操作符应用程序: 1 + 2,3 < 4。
-
A predicate expression is an expression that returns true or false:
a.prop = 'Hello',length(p) > 10,a.name IS NOT NULL.谓词表达式是返回 true 或 false 的表达式: a.prop = ‘ Hello’,length (p) > 10,a.name IS NOT NULL。
-
An existential subquery is an expression that returns true or false:
EXISTS { MATCH (n)-[r]→(p) WHERE p.name = 'Sven' }.存在子查询是返回 true 或 false 的表达式: EXISTS { MATCH (n)-[ r ]→(p) WHERE p.name = ‘ Sven’}。
-
A regular expression:
a.name =~ 'Tim.*'.正则表达式: a.name = ~ ‘ Tim. *’。
-
A case-sensitive string matching expression:
a.surname STARTS WITH 'Sven',a.surname ENDS WITH 'son'ora.surname CONTAINS 'son'.区分大小写的字符串匹配表达式: a.surname 以‘ Sven’开头,a.surname 以‘ son’结尾或 a.surname CONTAINS‘ son’。
-
A
CASEexpression.CASE 表达式。
3.3.2Note on string literals 关于字符串文本的注释
String literals can contain the following escape sequences:
字符串文字可以包含以下转义序列:
| Escape sequence 转义序列 | Character 性格 |
|---|---|
\t |
Tab表 |
\b |
Backspace |
\n |
Newline |
\r |
Carriage return回车 |
\f |
Form feed表单提要 |
\' |
Single quote单引号 |
\" |
Double quote双引号 |
\\ |
Backslash反斜杠 |
\uxxxx |
Unicode UTF-16 code point (4 hex digits must follow the \u)Unicode utf-16编码点(4个十六进制数字必须跟在 u 后面) |
\UxxxxxxxxUxxxxxx |
Unicode UTF-32 code point (8 hex digits must follow the \U)Unicode utf-32编码点(8个十六进制数字必须跟在 u 后面) |
3.3.3CASE expressions 表达
通用条件表达式可以使用 CASE 结构来表示。Cypher 中存在两种 CASE 变体: 一种是简单形式,允许表达式与多个值进行比较; 另一种是通用形式,允许多个条件语句进行表达。
如果希望在随后的子句或语句中使用结果,则 CASE 只能用作 RETURN 或 WITH 的一部分。
1.SimpleCASE form: comparing an expression against multiple values : 将表达式与多个值进行比较
计算表达式,并按照 WHEN 子句的顺序进行比较,直到找到匹配。如果没有找到匹配项,则返回 ELSE 子句中的表达式。但是,如果没有 ELSE 大小写且没有找到匹配项,则返回 null。
CASE test
WHEN value THEN result
[WHEN ...]
[ELSE default]
END
| Name 姓名 | Description 描述 |
|---|---|
test测试 |
A valid expression.有效的表达式。 |
value价值 |
An expression whose result will be compared to test.其结果将与测试结果相比较的表达式。 |
result结果 |
This is the expression returned as output if value matches test.如果值与 test 匹配,这是作为输出返回的表达式。 |
default默认 |
If no match is found, default is returned.如果没有找到匹配项,则返回默认值。 |
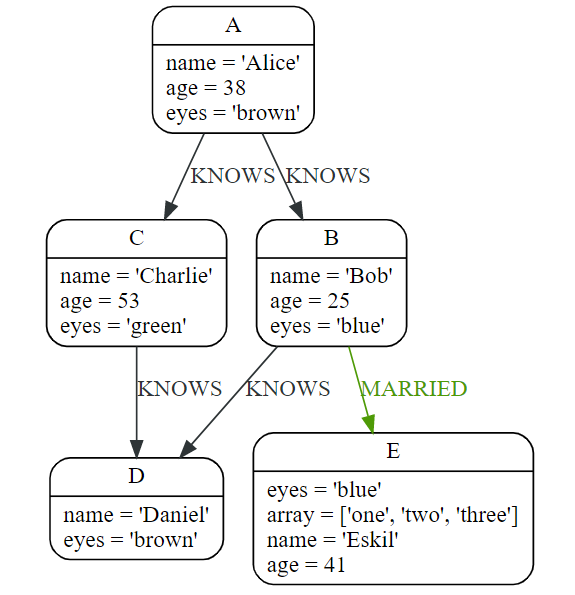
CREATE (p:Person{name:'Peanut',age:23}),(h:Person{name:'Hello',age:77}),(b:Book{title:'My holiday',money:45}),(p)-[:HAS_BORROW{way:'online'}]->(b) RETURN p,h,b
MATCH (n)
RETURN
CASE n.name
WHEN 'Peanut' THEN 'No.1'
WHEN 'Hello' THEN 'World'
ELSE '-'
END AS result

2.Generic CASE form: allowing for multiple conditionals to be expressed 允许表达多个条件
在找到真值并使用结果值之前,按顺序对谓词进行计算。如果没有找到匹配项,则返回 ELSE 子句中的表达式。但是,如果没有 ELSE 大小写且没有找到匹配项,则返回 null。
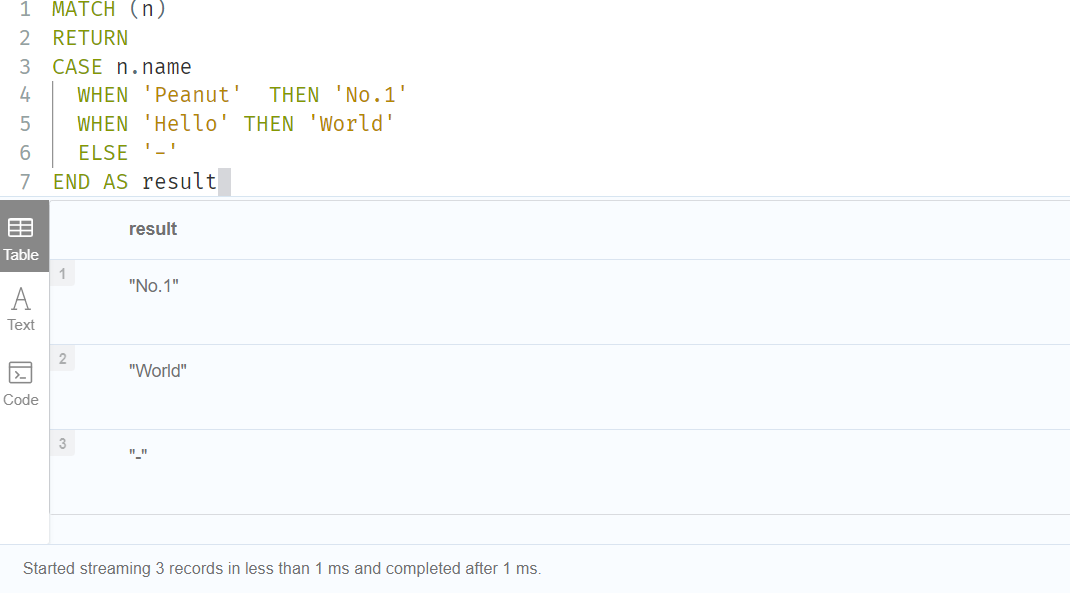
MATCH (n)
RETURN
CASE
WHEN n.name IS NOT NULL THEN '好人'
WHEN n.title IS NOT NULL THEN '好书'
ELSE '-'
END AS result
3.Distinguishing between when to use the simple and genericCASE forms 区分何时使用简单和通用形式
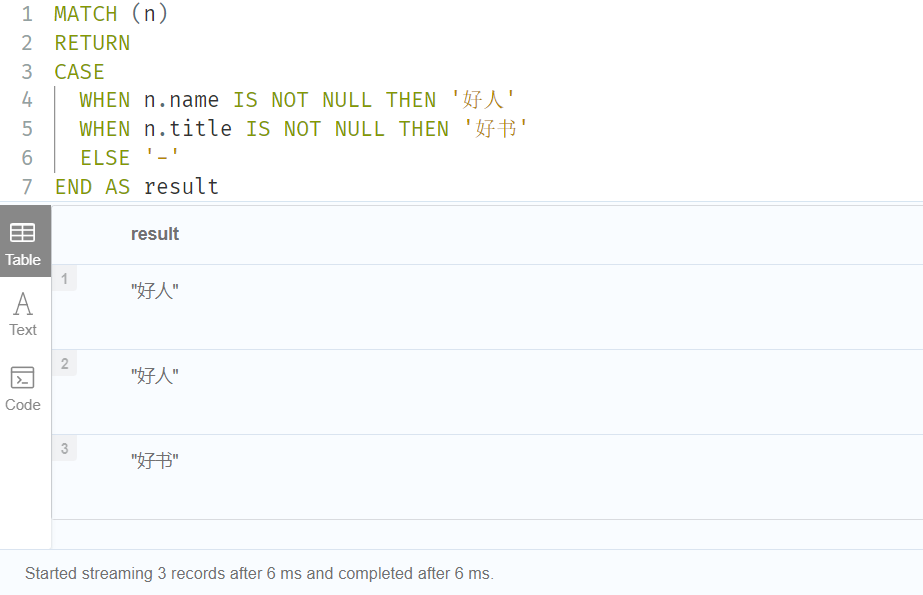
由于这两种形式的语法非常相似,有时一开始就不清楚使用哪种形式。我们通过下面的查询来说明这个场景,在这个查询中,如果 n.age 为 null,那么我们期望 age _ 10 _ years _ ago 是-1:
CREATE (:Person{name:'Peanut'})
MATCH (n)
RETURN n.name,
CASE n.age
WHEN n.age IS NULL THEN -1
ELSE n.age - 10
END AS age_10_years_ago
但是,由于此查询是使用简单的 CASE 格式编写的,因此对于名为 Daniel 的节点,age _ 10 _ years _ ago 为 -1,所以它为 null。这是因为对 n. age 和 n. age IS NULL 进行了比较。由于 n. age IS NULL 是一个布尔值,n. age 是一个整数值,因此 n. age IS NULL THEN-1分支从未被使用。这将导致 ELSE n.age-10分支被取代,返回 null。
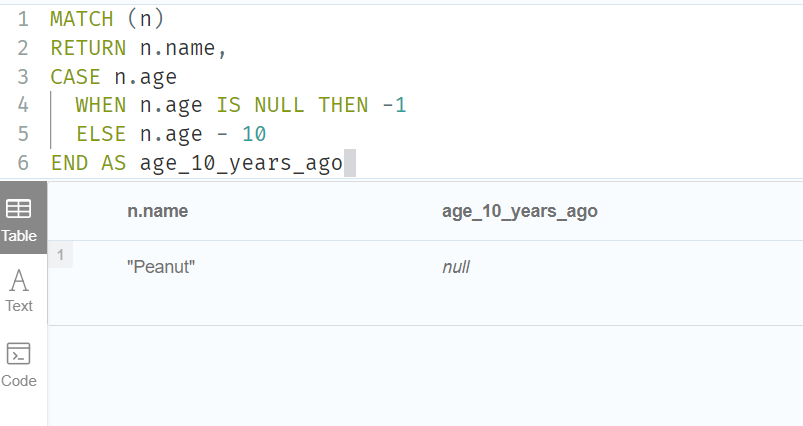
修正后的查询,如预期的那样,是通过以下通用 CASE 表格给出的:
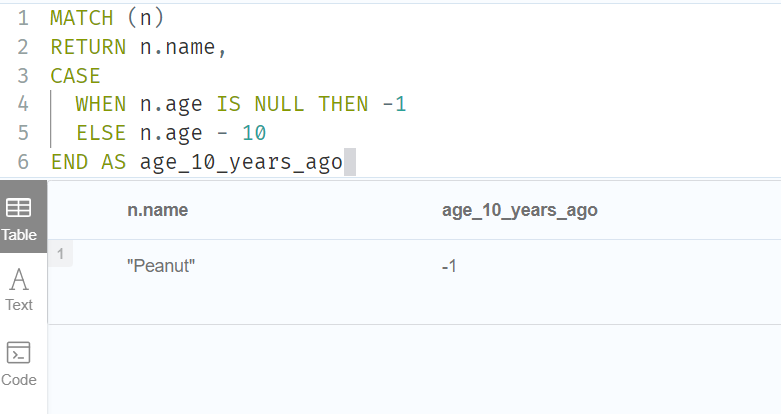
MATCH (n)
RETURN n.name,
CASE
WHEN n.age IS NULL THEN -1
ELSE n.age - 10
END AS age_10_years_ago
4.Using the result of CASE in the succeeding clause or statement 在后面的子句或陈述句中使用CASE的结果
CREATE (p:Person{name:'Peanut',age:23,nickname:'-'}),(h:Person{name:'Hello',age:77,nickname:'-'}),(b:Book{title:'My holiday',money:45}),(p)-[:HAS_BORROW{way:'online'}]->(b)
MATCH (n)
WITH n,
CASE n.name
WHEN 'Peanut' THEN '花生'
WHEN 'Hello' THEN '你好'
ELSE -1
END AS nickname
SET n.nickname = nickname
RETURN n.name,n.nickname

3.4Variables变量
When you reference parts of a pattern or a query, you do so by naming them. The names you give the different parts are called variables.
当引用模式或查询的某些部分时,可以通过给它们命名来实现。你给不同部分起的名字叫做变量。
MATCH (n)-->(b)
RETURN b
The variables are n and b.
变量是 n 和 b。
3.5Reserved keywords保留关键字
保留关键字是在 Cypher 中具有特殊意义的单词。保留关键字的列表按照它们所来自的类别进行分组。除此之外,还有一些关键字是为将来使用而保留的。
The reserved keywords are not permitted to be used as identifiers in the following contexts:
在下列上下文中,不允许使用保留关键字作为标识符:
-
Variables
变量
-
Function names
函数名
-
Parameters
参数
更多保留字参考:https://neo4j.com/docs/cypher-manual/current/syntax/reserved/
3.6Operators参数
Operators at a glance
| Aggregation operators | DISTINCT |
|---|---|
| Property operators | . for static property access, [] for dynamic property access, = for replacing all properties, += for mutating specific properties. 对于静态属性访问,[]对于动态属性访问,= 用于替换所有属性,+ = 用于修改特定属性 |
| Mathematical operators | +, -, *, /, %, ^ |
| Comparison operators | =, <>, <, >, <=, >=, IS NULL, IS NOT NULL |
| String-specific comparison operators | STARTS WITH, ENDS WITH, CONTAINS |
| Boolean operators | AND, OR, XOR, NOT |
| String operators | + for concatenation, =~ for regex matching |
| Temporal operators | + and - for operations between durations and temporal instants/durations, * and / for operations between durations and numbers |
| Map operators | . for static value access by key, [] for dynamic value access by key |
| List operators | + for concatenation, IN to check existence of an element in a list, [] for accessing element(s) dynamically |
3.6.1Aggregation operators 聚合操作符
The aggregation operators comprise:
聚合操作符包括:
-
remove duplicates values:
DISTINCT删除重复值: DISTINCT
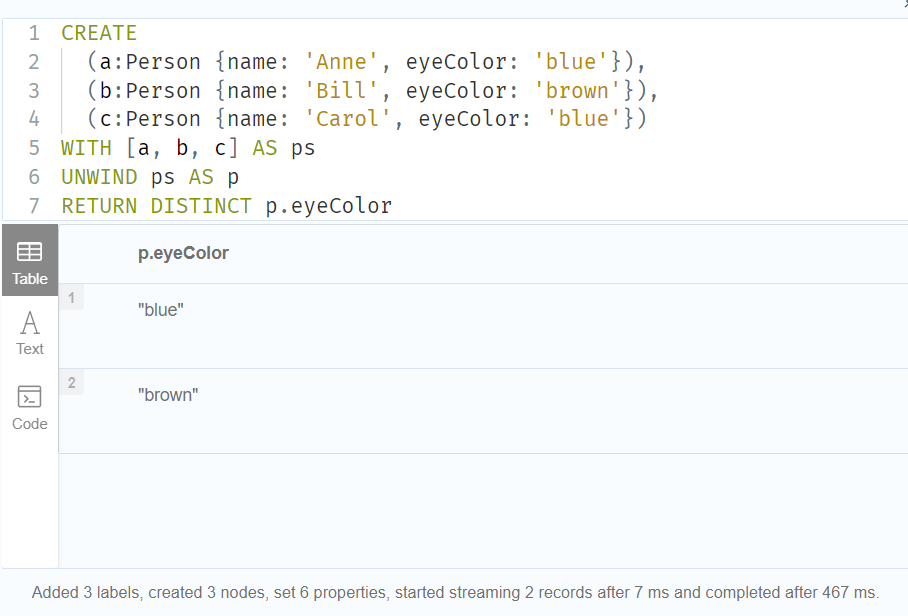
Retrieve the unique eye colors from Person nodes.
从 Person 节点检索独特的眼睛颜色。
CREATE
(a:Person {name: 'Anne', eyeColor: 'blue'}),
(b:Person {name: 'Bill', eyeColor: 'brown'}),
(c:Person {name: 'Carol', eyeColor: 'blue'})
WITH [a, b, c] AS ps
UNWIND ps AS p
RETURN DISTINCT p.eyeColor
3.6.2Property operators
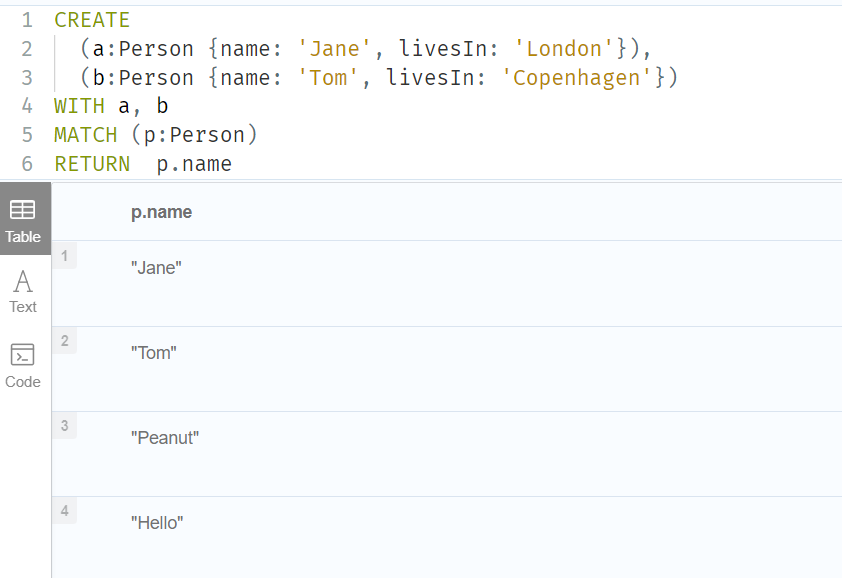
1.Statically accessing a property of a node or relationship using the .` operator
CREATE
(a:Person {name: 'Jane', livesIn: 'London'}),
(b:Person {name: 'Tom', livesIn: 'Copenhagen'})
WITH a, b
MATCH (p:Person)
RETURN p.name
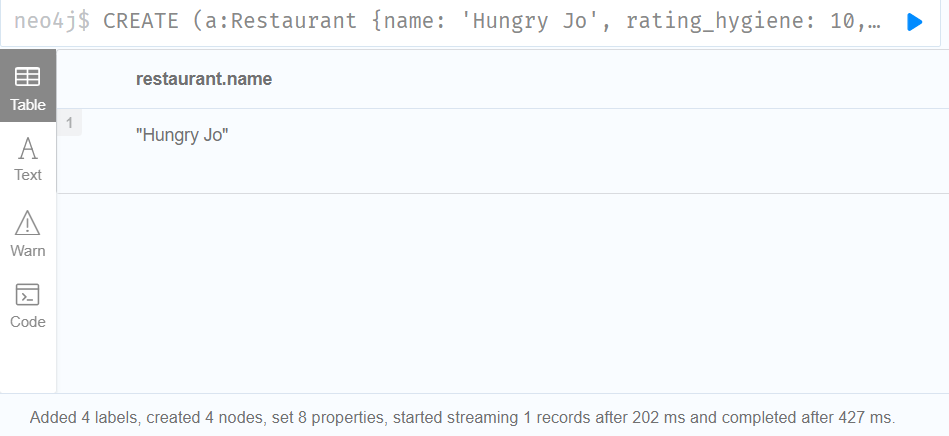
2.Filtering on a dynamically-computed property key using the[]operator
CREATE
(a:Restaurant {name: 'Hungry Jo', rating_hygiene: 10, rating_food: 7}),
(b:Restaurant {name: 'Buttercup Tea Rooms', rating_hygiene: 5, rating_food: 6}),
(c1:Category {name: 'hygiene'}),
(c2:Category {name: 'food'})
WITH a, b, c1, c2
MATCH (restaurant:Restaurant), (category:Category)
WHERE restaurant["rating_" + category.name] > 6
RETURN DISTINCT restaurant.name
3.Replacing all properties of a node or relationship using the = operator
CREATE (a:Person {name: 'Jane', age: 20})
WITH a
MATCH (p:Person {name: 'Jane'})
SET p = {name: 'Ellen', livesIn: 'London'}
RETURN p.name, p.age, p.livesIn
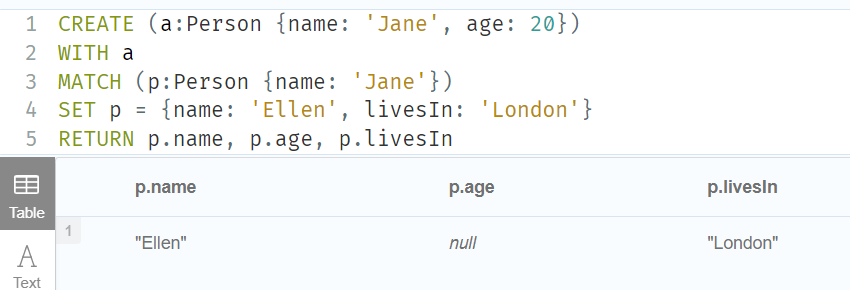
该节点上的所有现有属性都被映射中提供的属性所替换; 即 name 属性从 Jane 更新为 Ellen,age 属性被删除,并添加 livesIn 属性。
4.Mutating specific properties of a node or relationship using the 使+= operator
CREATE (a:Person {name: 'Jane', age: 20})
WITH a
MATCH (p:Person {name: 'Jane'})
SET p += {name: 'Ellen', livesIn: 'London'}
RETURN p.name, p.age, p.livesIn
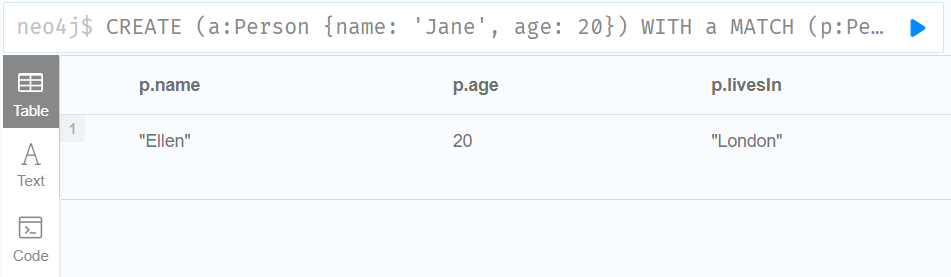
节点上的属性按照映射中提供的属性进行更新: name 属性从 Jane 更新为 Ellen,age 属性保持不变,并添加 livesIn 属性。
3.6.3Mathematical operators
-
addition:
+加法: +
-
subtraction or unary minus:
-减法或一元减法:-
-
multiplication:
*乘: *
-
division:
/分部:/
-
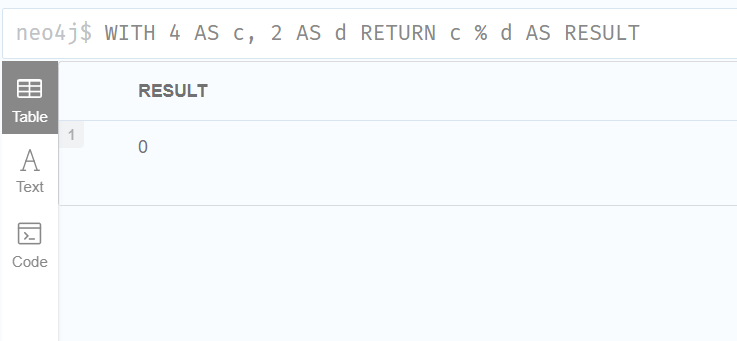
modulo division:
%模除法:%
-
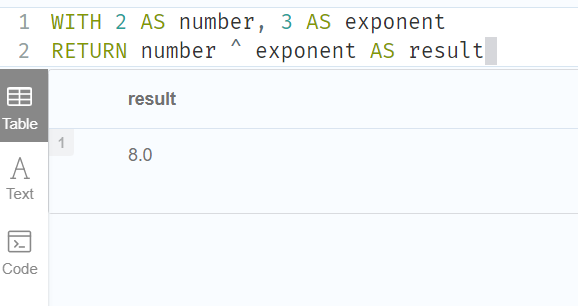
exponentiation:
^求幂: ^
//求幂运算符^
WITH 2 AS number, 3 AS exponent
RETURN number ^ exponent AS result
//使用一元减号运算符-
WITH -3 AS a, 4 AS b
RETURN b - a AS result
WITH 4 AS c, 2 AS d
RETURN c % d AS RESULT
3.6.4Comparison operators
The comparison operators comprise:
比较运算符包括:
-
equality:
=平等: =
-
inequality:
<>不平等:
-
less than:
<少于: <
-
greater than:
>大于: >
-
less than or equal to:
<=小于或等于: < =
-
greater than or equal to:
>=大于或等于: > =
-
IS NULL无效
-
IS NOT NULL不是 NULL
1.String-specific comparison operators comprise
-
STARTS WITH: perform case-sensitive prefix searching on stringsSTARTS WITH: 对字符串执行区分大小写的前缀搜索
-
ENDS WITH: perform case-sensitive suffix searching on strings对字符串执行区分大小写的后缀搜索
-
CONTAINS: perform case-sensitive inclusion searching in stringsCONTAINS: 在字符串中执行区分大小写的包含搜索
2.Comparing two numbers
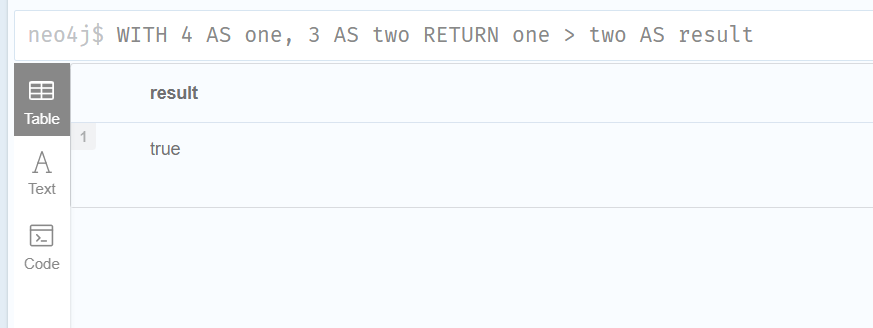
WITH 4 AS one, 3 AS two
RETURN one > two AS result
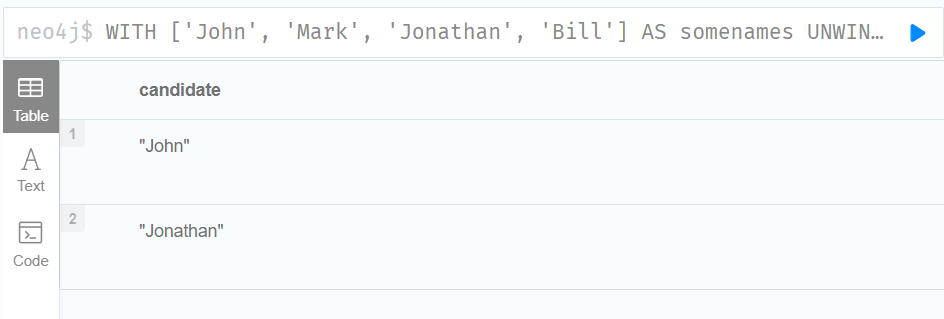
3.Using STARTS WITH to filter names
WITH ['John', 'Mark', 'Jonathan', 'Bill'] AS somenames
UNWIND somenames AS names
WITH names AS candidate
WHERE candidate STARTS WITH 'Jo'
RETURN candidate
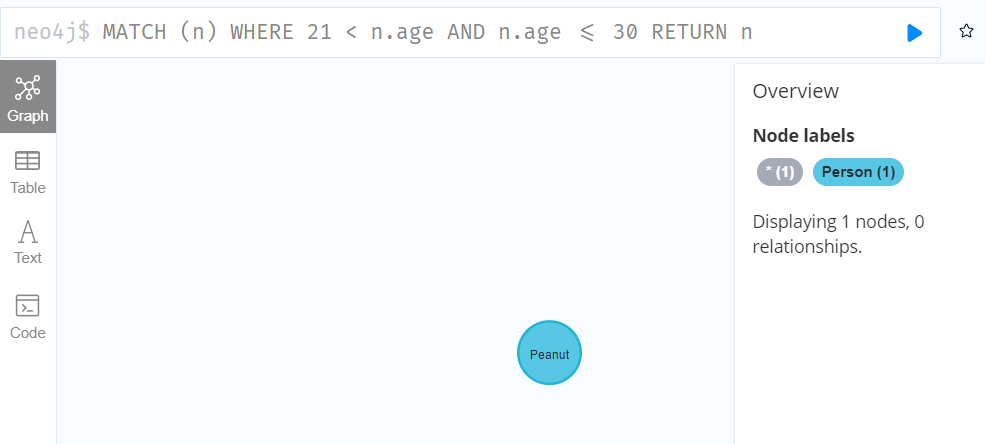
3.6.5Chaining comparison operations
Comparisons can be chained arbitrarily, e.g., x < y <= z is equivalent to x < y AND y <= z.
MATCH (n) WHERE 21 < n.age AND n.age <= 30 RETURN n
a < b = c <= d <> e
//等价于
a < b AND b = c AND c <= d AND d <> e
3.6.6Boolean operators
The boolean operators — also known as logical operators — comprise:
布尔运算符(又称逻辑运算符)包括:
-
conjunction:
AND连词: AND
-
disjunction:
OR,分离: 或,
-
exclusive disjunction:
XOR逻辑异或: XOR
-
negation:
NOT否定: 否定
Here is the truth table for AND, OR, XOR and NOT.
| a | b | a AND b |
a OR b |
a XOR b |
NOT a |
|---|---|---|---|---|---|
false |
false |
false |
false |
false |
true |
false |
null |
false |
null |
null |
true |
false |
true |
false |
true |
true |
true |
true |
false |
false |
true |
true |
false |
true |
null |
null |
true |
null |
false |
true |
true |
true |
true |
false |
false |
null |
false |
false |
null |
null |
null |
null |
null |
null |
null |
null |
null |
null |
true |
null |
true |
null |
null |
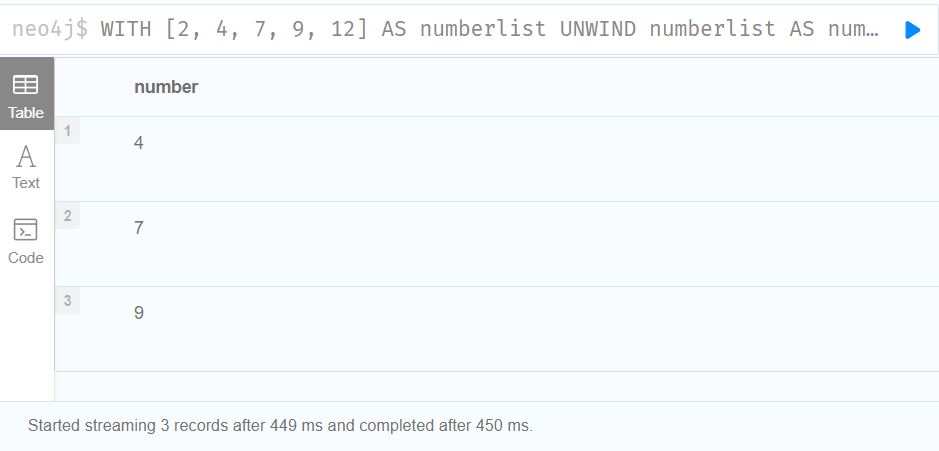
1.Using boolean operators to filter numbers
WITH [2, 4, 7, 9, 12] AS numberlist
UNWIND numberlist AS number
WITH number
WHERE number = 4 OR (number > 6 AND number < 10)
RETURN number
3.6.7String operators
The string operators comprise:
字符串操作符包括:
-
concatenating strings:
+连接字符串: +
-
matching a regular expression:
=~匹配正则表达式: = ~
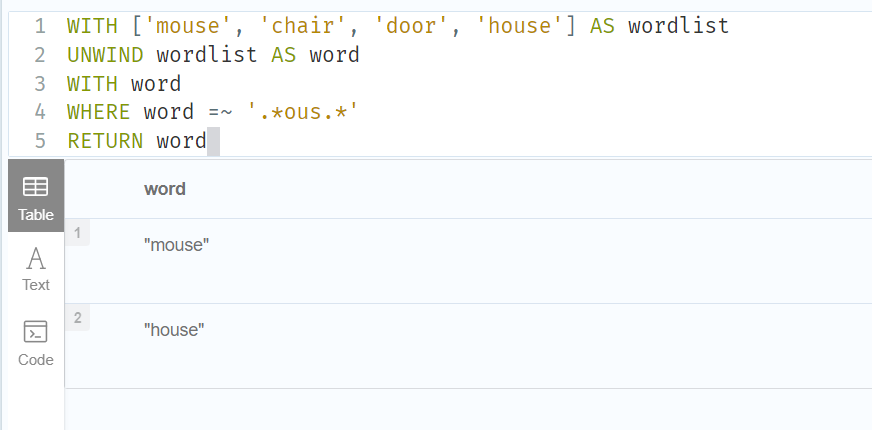
1.Using a regular expression with =~ to filter words
WITH ['mouse', 'chair', 'door', 'house'] AS wordlist
UNWIND wordlist AS word
WITH word
WHERE word =~ '.*ous.*'
RETURN word
. 表示匹配除换行符 \n 之外的任何单字符,*表示零次或多次。
.*在一起就表示任意字符出现零次或多次。
a.*?b匹配最短的,以a开始,以b结束的字符串。且开始和结束中间可以没有字符,因为*表示零到多个
a.+?b匹配最短的,以a开始,以b结束的字符串,但a和b中间至少要有一个字符。且开始和结束中间必须有字符,因为+表示1到多个。
3.6.8Temporal operators时态操作符
-
adding a Duration to either a temporal instant or another Duration:
+将持续时间添加到时间瞬间或另一个持续时间: +
-
subtracting a Duration from either a temporal instant or another Duration:
-从时间瞬间或另一时间瞬间减去持续时间:-
-
multiplying a Duration with a number:
*将 Duration 乘以一个数字: *
-
dividing a Duration by a number:
/将持续时间除以一个数字:/
The following table shows — for each combination of operation and operand type — the type of the value returned from the application of each temporal operator:
下表显示了每个操作和操作数类型的组合,每个时态运算符应用程序返回的值的类型:
| Operator | Left-hand operand | Right-hand operand | Type of result |
|---|---|---|---|
+ |
Temporal instant | Duration | The type of the temporal instant |
+ |
Duration | Temporal instant | The type of the temporal instant |
- |
Temporal instant | Duration | The type of the temporal instant |
+ |
Duration | Duration | Duration |
- |
Duration | Duration | Duration |
* |
Duration | Number | Duration |
* |
Number | Duration | Duration |
/ |
Duration | Number | Duration |
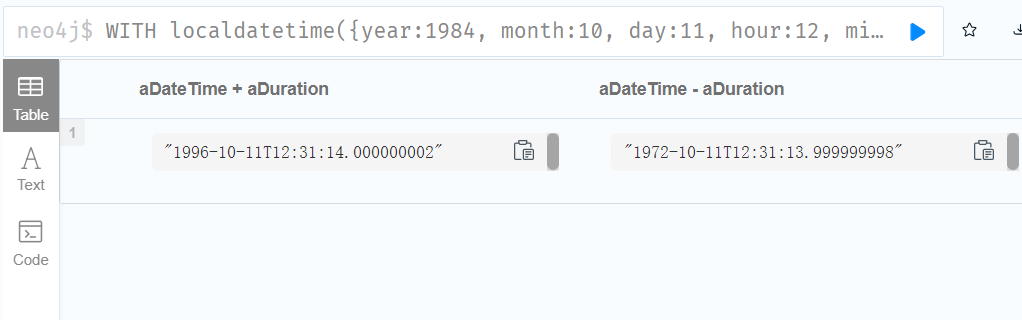
1.Adding and subtracting a Duration to or from a temporal instant
WITH
localdatetime({year:1984, month:10, day:11, hour:12, minute:31, second:14}) AS aDateTime,
duration({years: 12, nanoseconds: 2}) AS aDuration
RETURN aDateTime + aDuration, aDateTime - aDuration
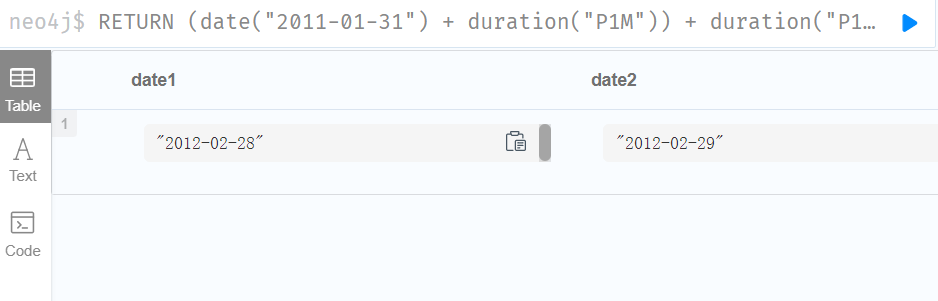
Adding two durations to a temporal instant is not an associative operation. This is because non-existing dates are truncated to the nearest existing date:
将两个持续时间添加到时间瞬间不是关联操作。这是因为不存在的日期被截断到最近的现有日期:
//P1M表示一个月
RETURN
(date("2011-01-31") + duration("P1M")) + duration("P12M") AS date1,
date("2011-01-31") + (duration("P1M") + duration("P12M")) AS date2
3.6.9Map operators
The map operators comprise:
地图操作员包括:
-
statically access the value of a map by key using the dot operator:
.使用点操作符: 静态地通过键访问 map 的值。
-
dynamically access the value of a map by key using the subscript operator:
[]使用下标操作符[]通过键动态地访问映射的值
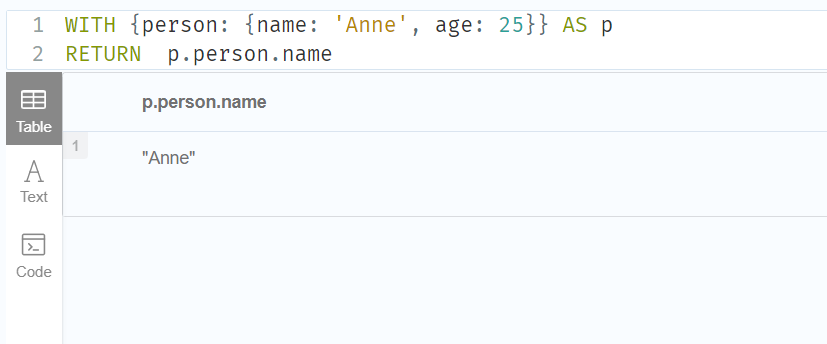
1.Statically accessing the value of a nested map by key using the . operator
WITH {person: {name: 'Anne', age: 25}} AS p
RETURN p.person.name
2.Dynamically accessing the value of a map by key using the [] operator and a parameter
A parameter may be used to specify the key of the value to access:
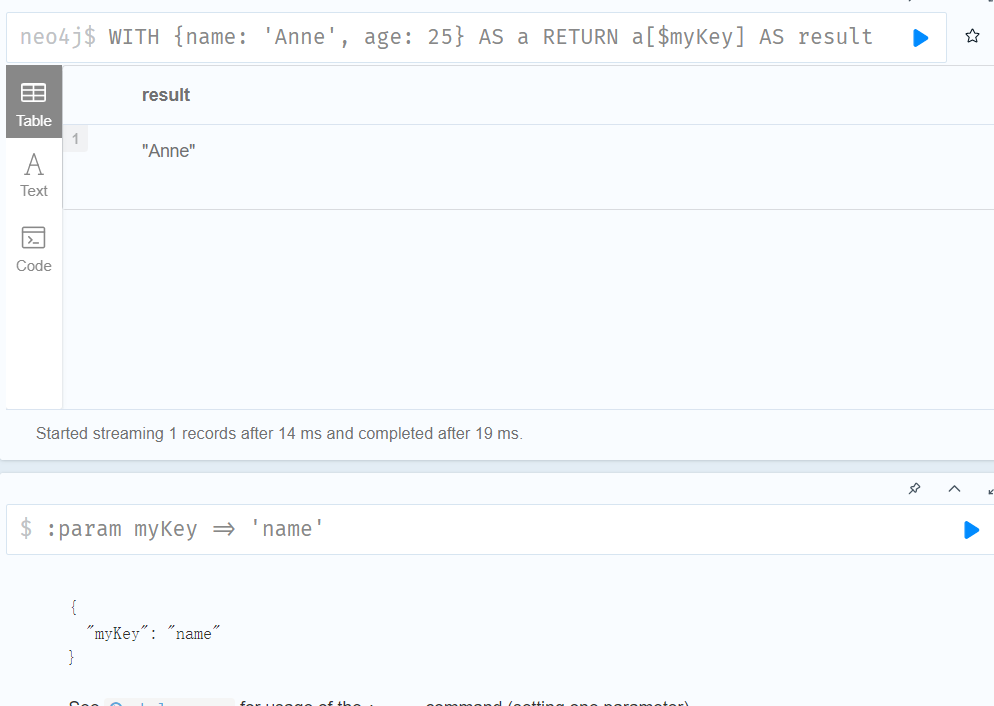
可以使用参数指定要访问的值的键:
//设置参数myKey等于name
:param myKey => 'name'
WITH {name: 'Anne', age: 25} AS a
RETURN a[$myKey] AS result
3.6.10List operators
The list operators comprise:
列表操作符包括:
-
concatenating lists
l1andl2:[l1] + [l2]连接列表 l1和 l2: [ l1] + [ l2]
-
checking if an element
eexists in a listl:e IN [l]检查列表 l: e IN [ l ]中是否存在元素 e
-
dynamically accessing an element(s) in a list using the subscript operator:
[]使用下标操作符[]动态访问列表中的元素
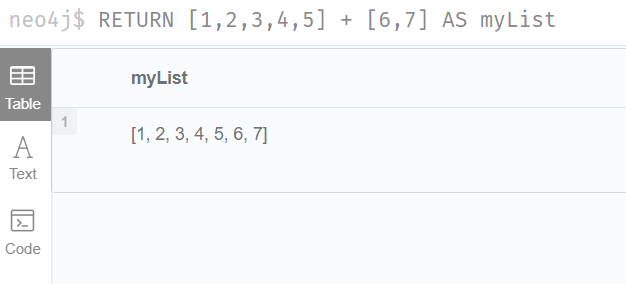
1.Concatenating two lists using +
RETURN [1,2,3,4,5] + [6,7] AS myList
WITH [2, 3, 4, 5] AS numberlist
UNWIND numberlist AS number
WITH number
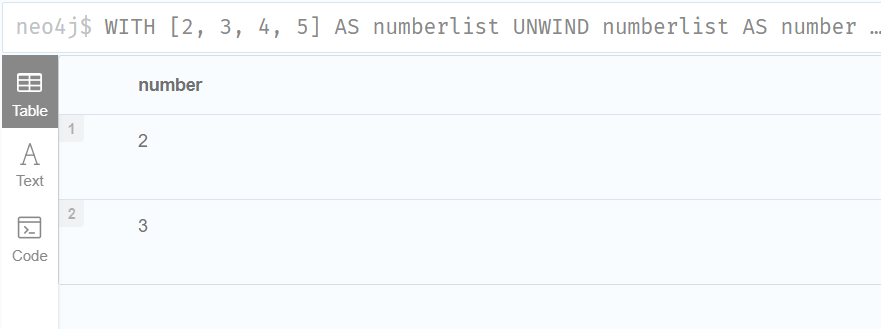
WHERE number IN [2, 3, 8]
RETURN number
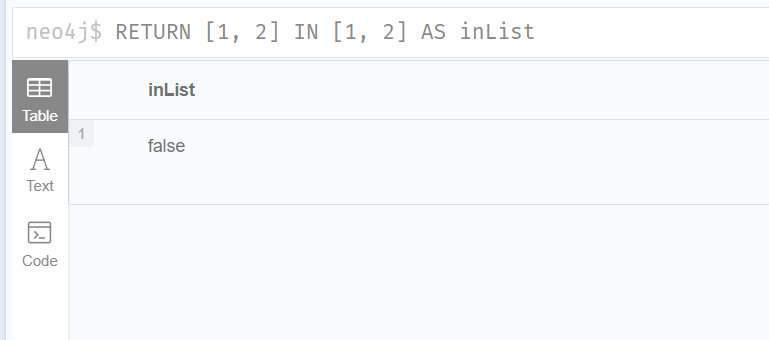
2.Using IN to check if a number is in a list
下面的查询检查 list [2,1]是否是 list [1,[2,1] ,3]的元素:
RETURN [2, 1] IN [1, [2, 1], 3] AS inList

RETURN [1, 2] IN [1, 2] AS inList
//IN 的计算结果为 false,因为右操作数不包含与左操作数类型相同的元素ー即列表。
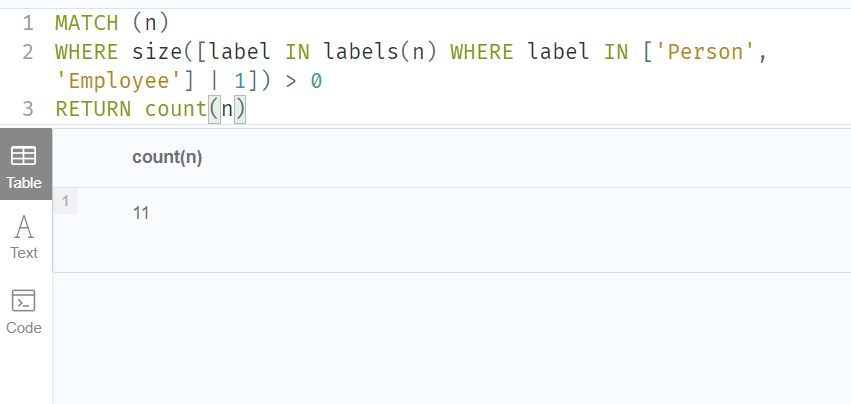
下面的查询可用于确定一个列表(例如,从 labels ()函数获得)是否包含至少一个也出现在另一个列表中的元素:
MATCH (n)
WHERE size([label IN labels(n) WHERE label IN ['Person', 'Employee'] | 1]) > 0
RETURN count(n)
As long as labels(n) returns either Person or Employee (or both), the query will return a value greater than zero.
只要 labels (n)返回 Person 或 Employee (或者两者都返回) ,查询将返回大于零的值。
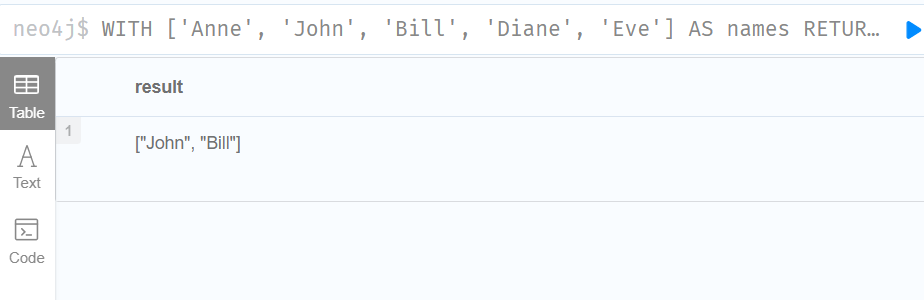
3.Accessing elements in a list using the [] operator
WITH ['Anne', 'John', 'Bill', 'Diane', 'Eve'] AS names
RETURN names[1..3] AS result
The square brackets will extract the elements from the start index 1, and up to (but excluding) the end index 3.
方括号将从开始索引1提取元素,并提取到(但不包括)结束索引3。
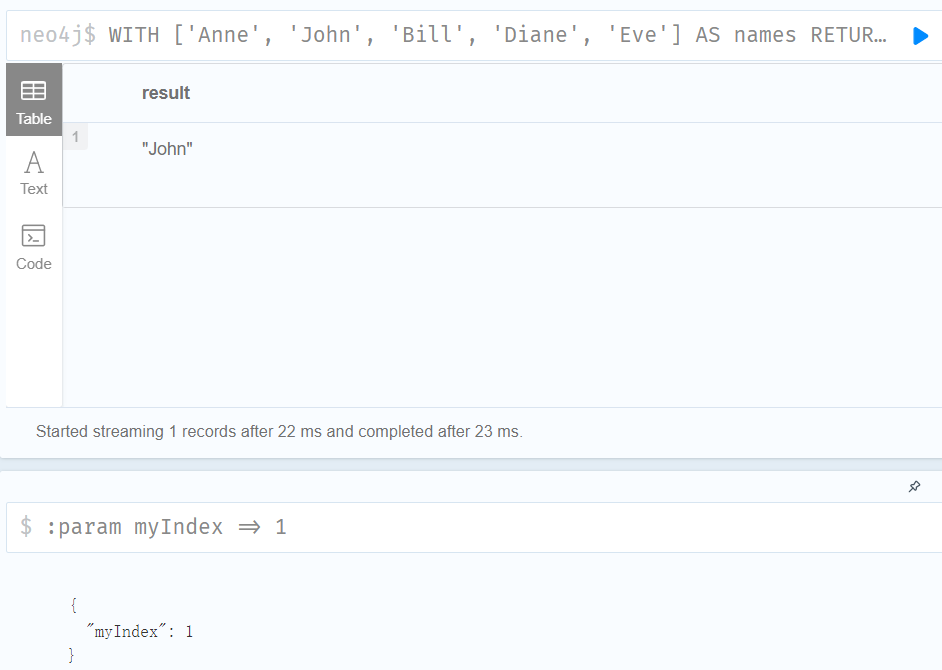
4.Dynamically accessing an element in a list using the [] operator and a parameter
:param myIndex => 1
WITH ['Anne', 'John', 'Bill', 'Diane', 'Eve'] AS names
RETURN names[$myIndex] AS result
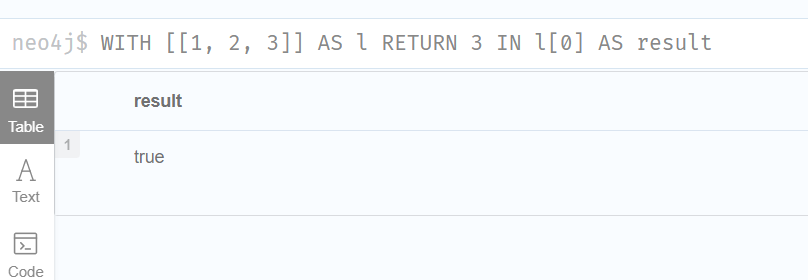
5.Using IN with [] on a nested list
IN can be used in conjunction with [] to test whether an element exists in a nested list:
IN 可以与[]结合使用来测试一个元素是否存在于嵌套列表中:
WITH [[1, 2, 3]] AS l
RETURN 3 IN l[0] AS result
3.7Comments注释
A comment begin with double slash (//) and continue to the end of the line. Comments do not execute, they are for humans to read.
注释以双斜杠(//)开头,一直到行尾。注释不会执行,它们是供人阅读的。
MATCH (n) RETURN n //This is an end of line comment
3.8Patterns模式
3.8.1Introduction
模式和模式匹配是 Cypher 的核心,因此使用 Cypher 高效需要对模式有很好的理解。
使用模式,您可以描述您正在寻找的数据的形状。例如,在 MATCH 子句中,您使用模式描述形状,Cypher 将指出如何为您获取该数据。
该模式使用一种非常类似于在白板上绘制属性图数据形状的表单来描述数据: 通常作为圆(表示节点) ,在它们之间用箭头表示关系。
模式出现在 Cypher 中的多个地方: 在 MATCH、 CREATE 和 MERGE 子句以及模式表达式中。
3.8.2Patterns for nodes节点模式
Neo4j中使用
()代表一个节点
() // 一个匿名无特征地节点
(matrix) // 拥有变量名matrix的节点,其他地方可以通过变量名使用
(:Movie) // 声明节点标签为Movie,限制了匹配的模式
(matrix:Movie) // 既赋变量名又声明标签的节点
// {}表示节点属性,用来存储信息或限制模式
(matrix:Movie{title:"the matrix"})
(matrix:Movie{title:"the matrix",released:1997})
3.8.3关系语法(Relationship Syntax)
Neo4j中使用一对虚线
--表示无向关系,有向关系在尾部会有箭头,比如<--和-->。中括号表达式[...]用来为关系添加详细信息,比如变量名、类型和属性。
-->
-[role]-> //定义关系的变量名为role,其他地方可以使用
-[:ACTED_IN]-> // 定义关系的类型为ACTED_IN
-[role:ACTED_IN]-> // 同时定义关系的变量名和类型
-[role:ACTED_IN {roles:["Neo"]}]-> // 定义关系的属性
3.8.4指定属性
// 以下是一个模式的实例
(keanu:Person {name:"Keanu Reeves"})
-[role:ACTED_IN {roles:["Neo"]}]->
(matrix:Movie {title:"The Matrix"})
// 表示指定姓名的人在指定电影中担当指定角色的模式
3.8.5Variable-length pattern matching
与使用模式中的许多节点和关系描述的序列来描述长路径不同,许多关系(和中间节点)可以通过在模式的关系描述中指定一个长度来描述。
//这是一个最小长度为3,最大长度为5。它描述了一个由4个节点和3个关系、5个节点和4个关系或6个节点和5个关系组成的图,所有这些节点和关系在一个单一的路径中连接在一起。
(a)-[*3..5]->(b)
CREATE (a:Person{name:'Anders'}),(b:Person{name:'Becky'}),(c:Person{name:'Cesar'}),(d:Person{name:'Dilshad'}),(f:Person{name:'Filipa'}),(g:Person{name:'George'}),(a)-[:KNOWS]->(b),(a)-[:KNOWS]->(c),(a)-[:KNOWS]->(d),(d)-[:KNOWS]->(f),(c)-[:KNOWS]->(g),(b)-[:KNOWS]->(g) RETURN a,b,c,d,f,g
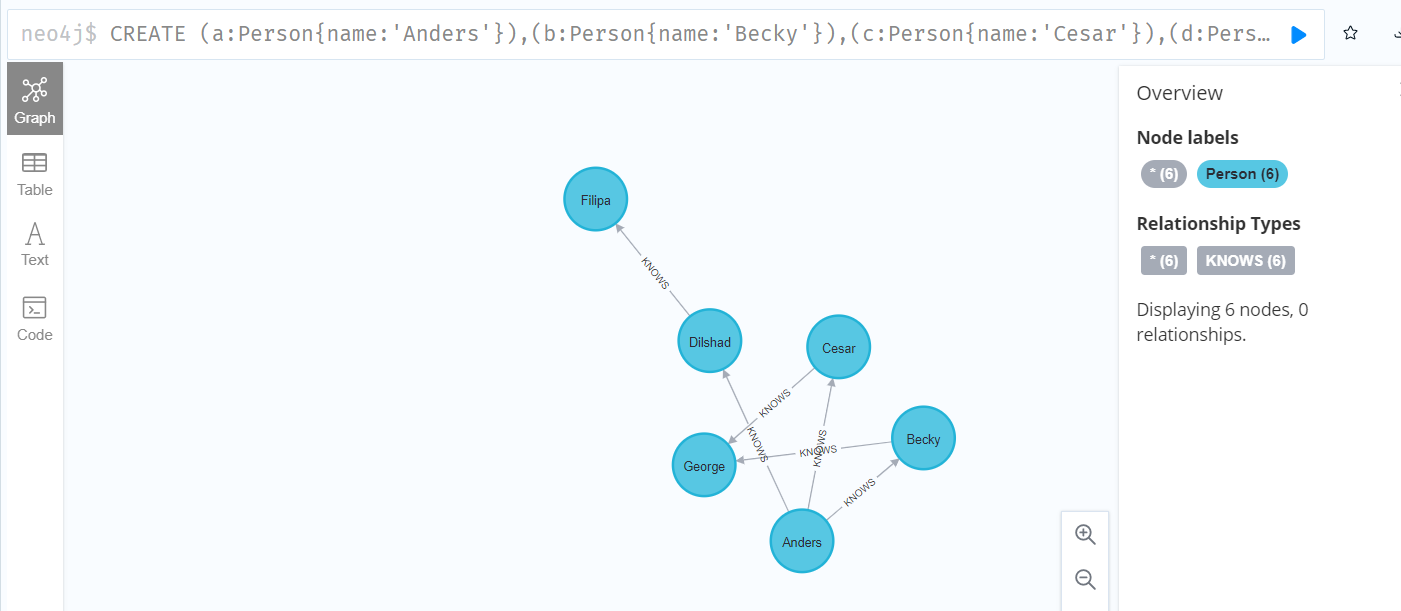
MATCH (me)-[:KNOWS*1..2]-(remote_friend)
WHERE me.name = 'Filipa'
RETURN remote_friend.name
3.9Temporal (Date/Time) values时态(日期/时间)值
The following table lists the temporal value types and supported components:
| Type | Date support | Time support | Time zone support |
|---|---|---|---|
Date |
💛 | ||
Time |
💛 | 💛 | |
LocalTime |
💛 | ||
DateTime |
💛 | 💛 | 💛 |
LocalDateTime |
💛 | 💛 | |
Duration |
- |
- |
- |
3.9.1Temporal instants
Specifying dates
| Component | Format | Description |
|---|---|---|
| Year | YYYY |
Specified with at least four digits (special rules apply in certain cases). |
| Month | MM |
Specified with a double digit number from 01 to 12. |
| Week | ww |
Always prefixed with W and specified with a double digit number from 01 to 53. |
| Quarter | q |
Always prefixed with Q and specified with a single digit number from 1 to 4. |
| Day of the month | DD |
Specified with a double digit number from 01 to 31. |
| Day of the week | D |
Specified with a single digit number from 1 to 7. |
| Day of the quarter | DD |
Specified with a double digit number from 01 to 92. |
| Ordinal day of the year | DDD |
Specified with a triple digit number from 001 to 366. |
YYYY-MM-DD |
Calendar date: Year-Month-Day |
2015-07-21 |
2015-07-21 |
|---|---|---|---|
YYYYMMDD |
Calendar date: Year-Month-Day |
20150721 |
2015-07-21 |
YYYY-MM |
Calendar date: Year-Month |
2015-07 |
2015-07-01 |
YYYYMM |
Calendar date: Year-Month |
201507 |
2015-07-01 |
YYYY-Www-D |
Week date: Year-Week-Day |
2015-W30-2 |
2015-07-21 |
YYYYWwwD |
Week date: Year-Week-Day |
2015W302 |
2015-07-21 |
YYYY-Www |
Week date: Year-Week |
2015-W30 |
2015-07-20 |
YYYYWww |
Week date: Year-Week |
2015W30 |
2015-07-20 |
YYYY-Qq-DD |
Quarter date: Year-Quarter-Day |
2015-Q2-60 |
2015-05-30 |
YYYYQqDD |
Quarter date: Year-Quarter-Day |
2015Q260 |
2015-05-30 |
YYYY-Qq |
Quarter date: Year-Quarter |
2015-Q2 |
2015-04-01 |
YYYYQq |
Quarter date: Year-Quarter |
2015Q2 |
2015-04-01 |
YYYY-DDD |
Ordinal date: Year-Day |
2015-202 |
2015-07-21 |
YYYYDDD |
Ordinal date: Year-Day |
2015202 |
2015-07-21 |
YYYY |
Year | 2015 |
2015-01-01 |
Specifying times
| Component | Format | Description |
|---|---|---|
Hour |
HH |
Specified with a double digit number from 00 to 23. |
Minute |
MM |
Specified with a double digit number from 00 to 59. |
Second |
SS |
Specified with a double digit number from 00 to 59. |
fraction |
sssssssss |
Specified with a number from 0 to 999999999. It is not required to specify trailing zeros. fraction is an optional, sub-second component of Second. This can be separated from Second using either a full stop (.) or a comma (,). The fraction is in addition to the two digits of Second. |
| Format | Description | Example | Interpretation of example |
|---|---|---|---|
HH:MM:SS.sssssssss |
Hour:Minute:Second.fraction |
21:40:32.142 |
21:40:32.142 |
HHMMSS.sssssssss |
Hour:Minute:Second.fraction |
214032.142 |
21:40:32.142 |
HH:MM:SS |
Hour:Minute:Second |
21:40:32 |
21:40:32.000 |
HHMMSS |
Hour:Minute:Second |
214032 |
21:40:32.000 |
HH:MM |
Hour:Minute |
21:40 |
21:40:00.000 |
HHMM |
Hour:Minute |
2140 |
21:40:00.000 |
HH |
Hour |
21 |
21:00:00.000 |
Specifying time zones
协调世界时,又称世界统一时间、世界标准时间、国际协调时间。由于英文(CUT)和法文(TUC)的缩写不同,作为妥协,简称UTC。
| Format | Description | Example | Supported for DateTime |
Supported for Time |
Z |
UTC | Z |
👍 | 👍 |
±HH:MM |
Hour:Minute |
+09:30 |
👍 | 👍 |
±HH:MM[ZoneName] |
Hour:Minute[ZoneName] |
+08:45[Australia/Eucla] |
👍 | |
±HHMM |
Hour:Minute |
+0100 |
👍 | 👍 |
±HHMM[ZoneName] |
Hour:Minute[ZoneName] |
+0200[Africa/Johannesburg] |
👍 | |
±HH |
Hour |
-08 |
👍 | 👍 |
±HH[ZoneName] |
Hour[ZoneName] |
+08[Asia/Singapore] |
👍 | |
[ZoneName] |
[ZoneName] |
[America/Regina] |
👍 |
//使用日历日期格式解析 DateTime:
RETURN datetime('2015-06-24T12:50:35.556+0100') AS theDateTime
//使用序号日期格式解析 LocalDateTime:
RETURN localdatetime('2015185T19:32:24') AS theLocalDateTime
//使用星期日期格式解析日期:
RETURN date('+2015-W13-4') AS theDate
//解析 LocalTime:
RETURN localtime('12:50:35.556') AS theLocalTime

Accessing components of temporal instants
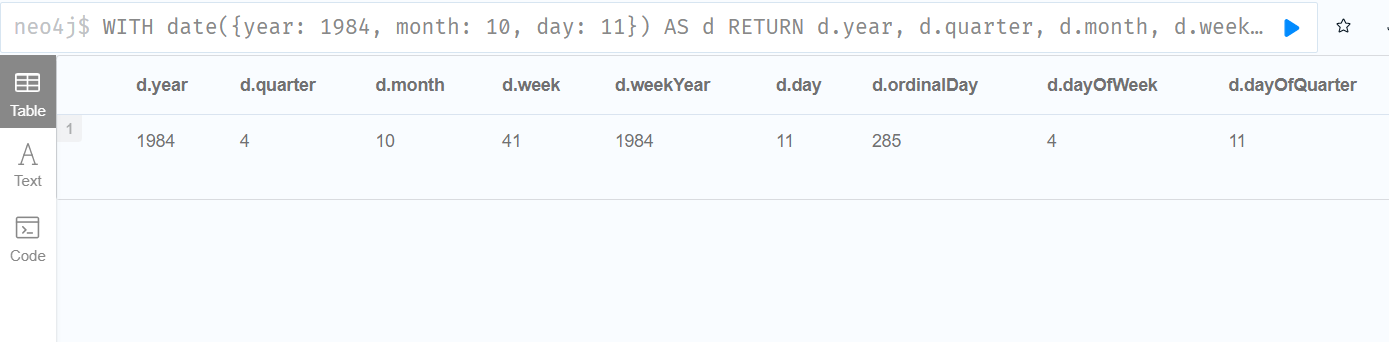
WITH date({year: 1984, month: 10, day: 11}) AS d
RETURN d.year, d.quarter, d.month, d.week, d.weekYear, d.day, d.ordinalDay, d.dayOfWeek, d.dayOfQuarter
WITH datetime({
year: 1984, month: 11, day: 11,
hour: 12, minute: 31, second: 14, nanosecond: 645876123,
timezone: 'Europe/Stockholm'
}) AS d
RETURN d.year, d.quarter, d.month, d.week, d.weekYear, d.day, d.ordinalDay, d.dayOfWeek, d.dayOfQuarter

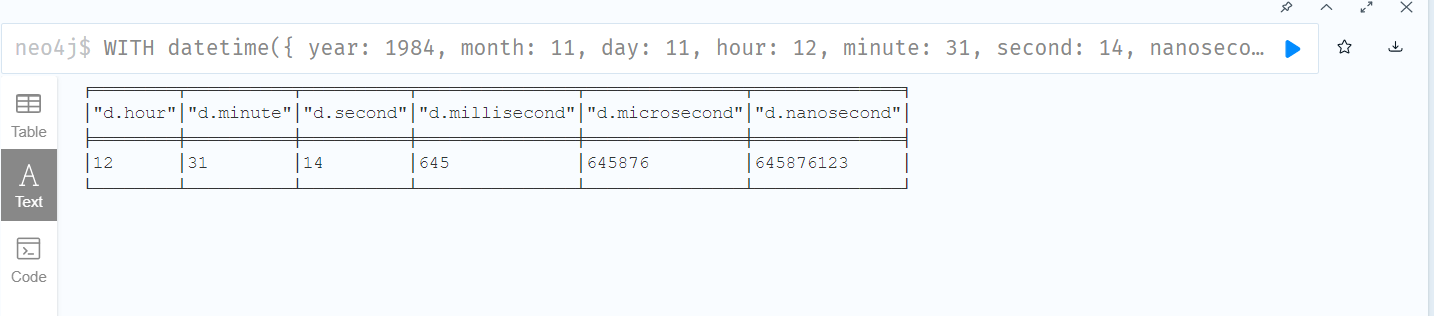
WITH datetime({
year: 1984, month: 11, day: 11,
hour: 12, minute: 31, second: 14, nanosecond: 645876123,
timezone: 'Europe/Stockholm'
}) AS d
RETURN d.hour, d.minute, d.second, d.millisecond, d.microsecond, d.nanosecond
3.9.2Durations
1.Specifying durations
持续时间的规范以 p 作为前缀,时间部分必须始终以 t 开头
Date-and-time-based form: P<date>T<time>.
日期及时间表格: p < 日期 > t < 时间 > 。
The following table lists the component identifiers for the unit-based form:
| Component identifier | Description | Comments |
|---|---|---|
Y |
Years | |
M |
Months | Must be specified before T. |
W |
Weeks | |
D |
Days | |
H |
Hours | |
M |
Minutes | Must be specified after T. |
S |
Seconds |
//返回持续时间为45秒的值:
RETURN duration('PT0.75M') AS theDuration
2. Accessing components of durations
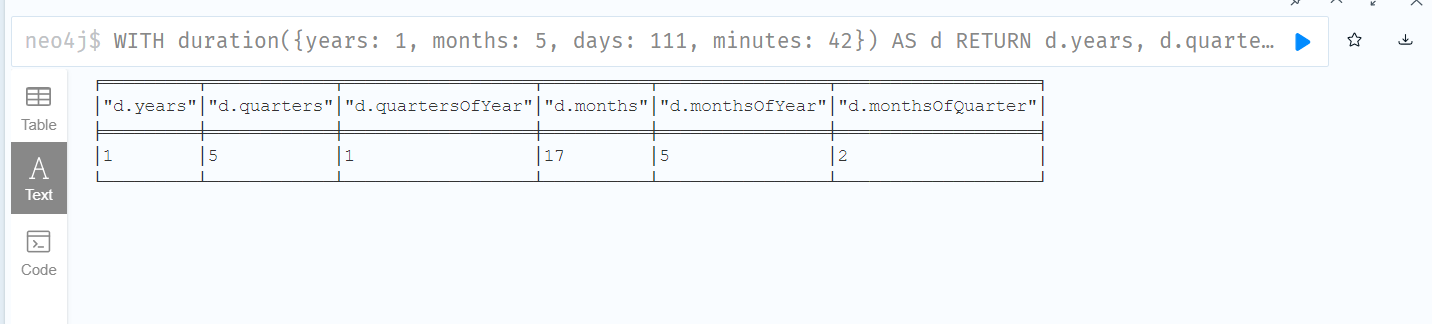
WITH duration({years: 1, months: 5, days: 111, minutes: 42}) AS d
RETURN d.years, d.quarters, d.quartersOfYear, d.months, d.monthsOfYear, d.monthsOfQuarter
3.9.3Examples
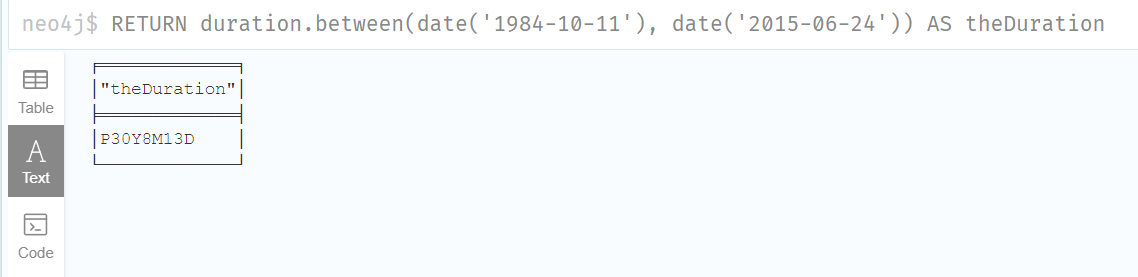
1.Compute the Duration between two temporal instants:
计算两个时间瞬间之间的持续时间:
RETURN duration.between(date('1984-10-11'), date('2015-06-24')) AS theDuration
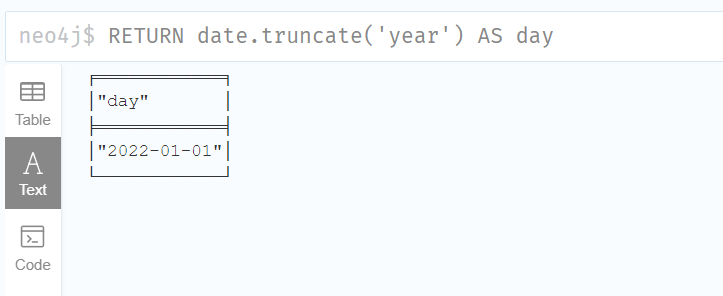
2.Get the first Date of the current year:
获取当年的第一个日期:
RETURN date.truncate('year') AS day
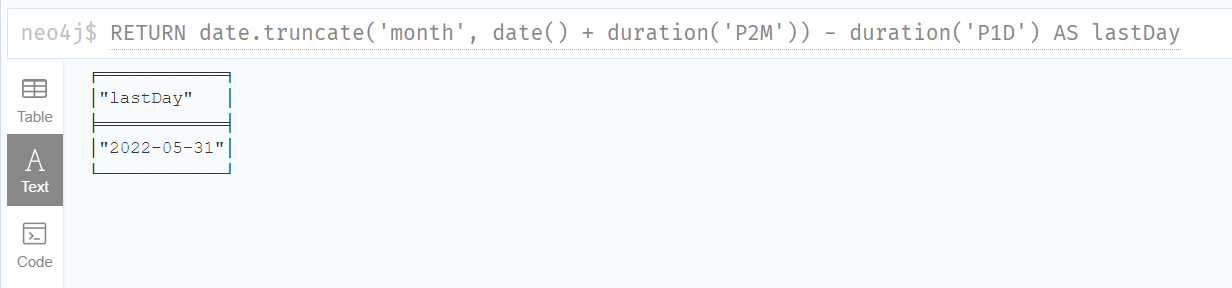
3.Get the Date of the last day of the next month:
得到下个月最后一天的日期:
RETURN date.truncate('month', date() + duration('P2M')) - duration('P1D') AS lastDay
3.10Spatial values空间价值
3.10.1Introduction
Neo4j 只支持一种类型的空间几何体,Point 具有以下特点:
每个点可以有2或3个维度。这意味着它包含2或3个64位浮点值,这些浮点值一起被称为坐标。
每个点还将与一个特定的坐标参考系统(CRS)相关联,该系统决定坐标中的值的含义。
3.10.2Coordinate Reference Systems 坐标参考系统
支持四种坐标参考系统,每种都属于两种类型之一: 地球上的地理坐标建模点,或欧几里德空间中的笛卡尔坐标建模点:
-
Geographic coordinate reference systems
经纬度参考系统
-
WGS-84: longitude, latitude (x, y)
WGS-84: 经度,纬度(x,y)
-
WGS-84-3D: longitude, latitude, height (x, y, z)
WGS-84-3D: 经度,纬度,高度(x,y,z)
-
-
Cartesian coordinate reference systems
笛卡尔坐标参考系
-
Cartesian: x, y
笛卡儿坐标: x,y
-
Cartesian 3D: x, y, z
3 d 坐标: x,y,z
-
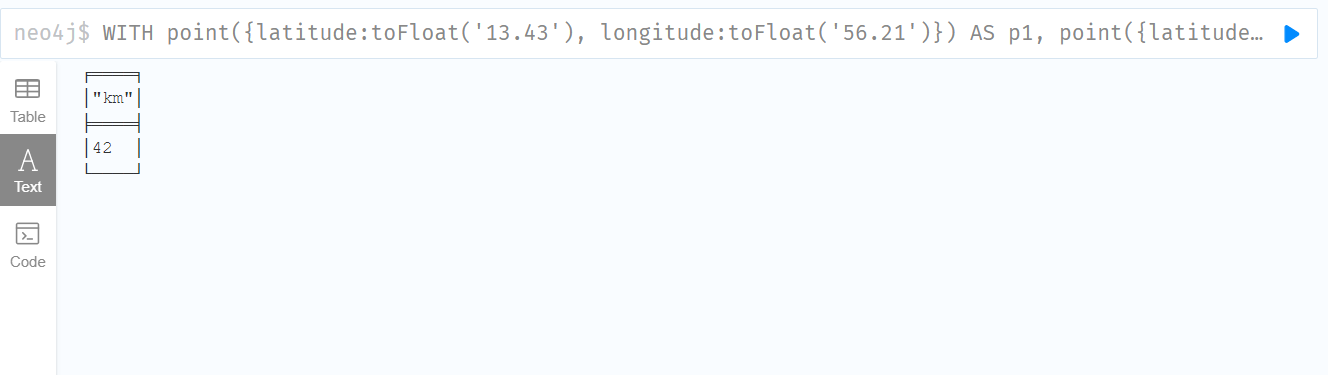
WITH
point({latitude:toFloat('13.43'), longitude:toFloat('56.21')}) AS p1,
point({latitude:toFloat('13.10'), longitude:toFloat('56.41')}) AS p2
RETURN toInteger(point.distance(p1, p2)/1000) AS km
WITH
point({x: 3, y: 0}) AS p2d,
point({x: 0, y: 4, z: 1}) AS p3d
RETURN
point.distance(p2d, p3d) AS bad,
point.distance(p2d, point({x: p3d.x, y: p3d.y})) AS good

3.10.3Spatial instants空间实例
RETURN
point({x: 3, y: 0}) AS cartesian_2d,
point({x: 0, y: 4, z: 1}) AS cartesian_3d,
point({latitude: 12, longitude: 56}) AS geo_2d,
point({latitude: 12, longitude: 56, height: 1000}) AS geo_3d

Accessing components of points
WITH point({latitude: 3, longitude: 4, height: 4321}) AS p
RETURN
p.latitude AS latitude,
p.longitude AS longitude,
p.height AS height,
p.x AS x,
p.y AS y,
p.z AS z,
p.crs AS crs,
p.srid AS srid

3.11List
3.11.1 Lists in general
cy//[0,1,2,3,4,5,6,7,8,9]
RETURN [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] AS list
//3
RETURN range(0, 10)[3]
//[0,1,2]
RETURN range(0, 10)[0..3]
//[5,6,7,8,9,10]
RETURN range(0, 10)[5..15]
//3
RETURN size(range(0, 10)[0..3])
3.11.2List comprehension
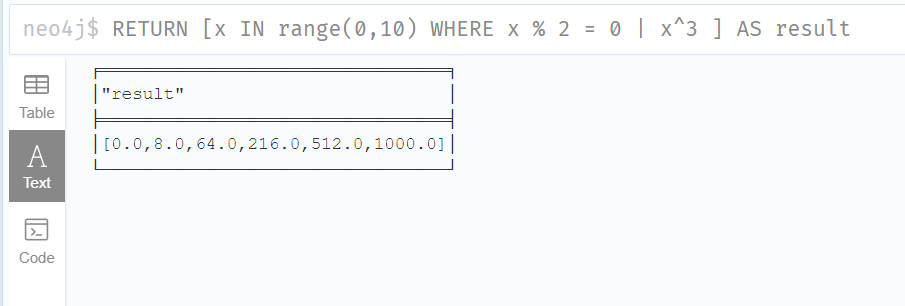
列表内涵是一种在 Cypher 可用于基于现有列表创建列表的语法构造。它采用了数学抽象化(数学)(集合理解)的形式,而不是使用地图和过滤函数。
RETURN [x IN range(0,10) WHERE x % 2 = 0 | x^3 ] AS result
3.11.3Pattern comprehension

MATCH (a:Person {name: 'Keanu Reeves'})
WITH [(a)-->(b:Movie) | b.released] AS years
UNWIND years AS year
WITH year ORDER BY year
RETURN COLLECT(year) AS sorted_years
//[1995,1997,1999,2000,2003,2003,2003,2021]
3.12Maps映射
Cypher supports a concept called "map projections". It allows for easily constructing map projections from nodes, relationships and other map values.
塞弗支持一个叫做“地图投影”的概念。它允许从节点、关系和其他地图值轻松地构建地图投影。
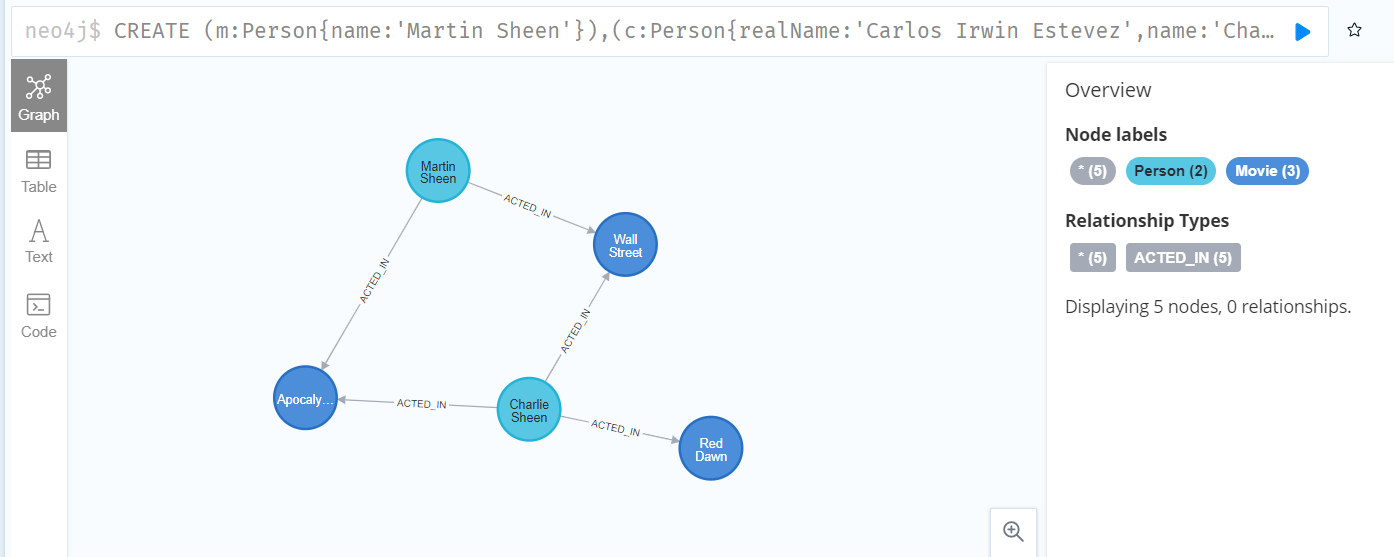
CREATE (m:Person{name:'Martin Sheen'}),(c:Person{realName:'Carlos Irwin Estevez',name:'Charlie Sheen'}),(w:Movie{year:1987,title:'Wall Street'}),(a:Movie{year:1979,title:'Apocalypse Now'}),(r:Movie{year:1984,title:'Red Dawn'}),(m)-[:ACTED_IN]->(w),(m)-[:ACTED_IN]->(a),(c)-[:ACTED_IN]->(w),(c)-[:ACTED_IN]->(a),(c)-[:ACTED_IN]->(r) RETURN m,c,w,a,r
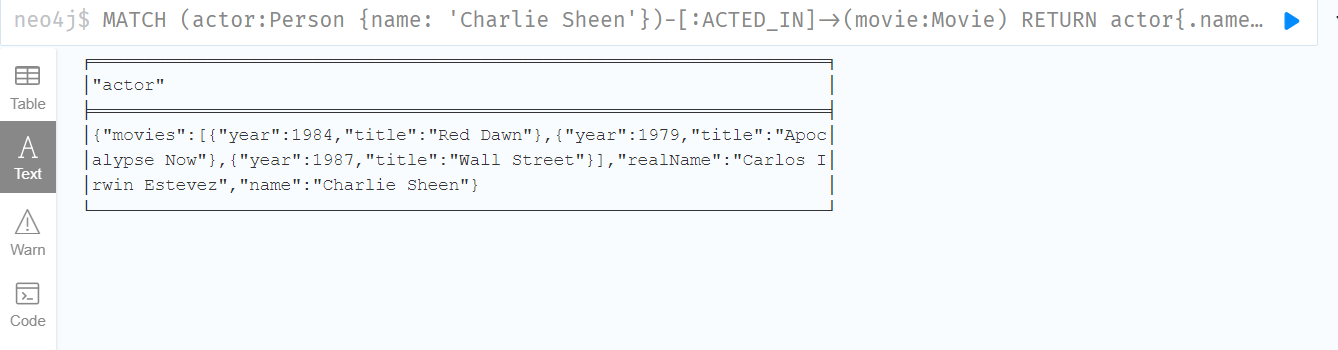
MATCH (actor:Person {name: 'Charlie Sheen'})-[:ACTED_IN]->(movie:Movie)
RETURN actor{.name, .realName, movies: collect(movie{.title, .year})}
3.13Working with null
Here is the truth table for AND, OR, XOR and NOT.
| a | b | a AND b |
a OR b |
a XOR b |
NOT a |
|---|---|---|---|---|---|
false |
false |
false |
false |
false |
true |
false |
null |
false |
null |
null |
true |
false |
true |
false |
true |
true |
true |
true |
false |
false |
true |
true |
false |
true |
null |
null |
true |
null |
false |
true |
true |
true |
true |
false |
false |
null |
false |
false |
null |
null |
null |
null |
null |
null |
null |
null |
null |
null |
true |
null |
true |
null |
null |
3.13.1The IN operator and null
| Expression | Result |
|---|---|
| 2 IN [1, 2, 3] | true |
2 IN [1, null, 3] |
null |
2 IN [1, 2, null] |
true |
| 2 IN [1] | false |
| 2 IN [] | false |
null IN [1, 2, 3] |
null |
null IN [1, null, 3] |
null |
null IN [] |
false |
3.13.2The [] operator and null
Accessing a list or a map with null will result in null:
| Expression | Result |
|---|---|
[1, 2, 3][null] |
null |
[1, 2, 3, 4][null..2] |
null |
[1, 2, 3][1..null] |
null |
{age: 25}[null] |
null |
4.Clauses
4.1Reading clauses
These comprise clauses that read data from the database.
这些子句包含从数据库中读取数据的子句。
| Clause 条款 | Description 描述 |
|---|---|
MATCH匹配 |
Specify the patterns to search for in the database.指定要在数据库中搜索的模式。 |
OPTIONAL MATCH可选配对 |
Specify the patterns to search for in the database while using nulls for missing parts of the pattern.指定要在数据库中搜索的模式,同时对模式的缺失部分使用空值。 |
4.1.1MATCH
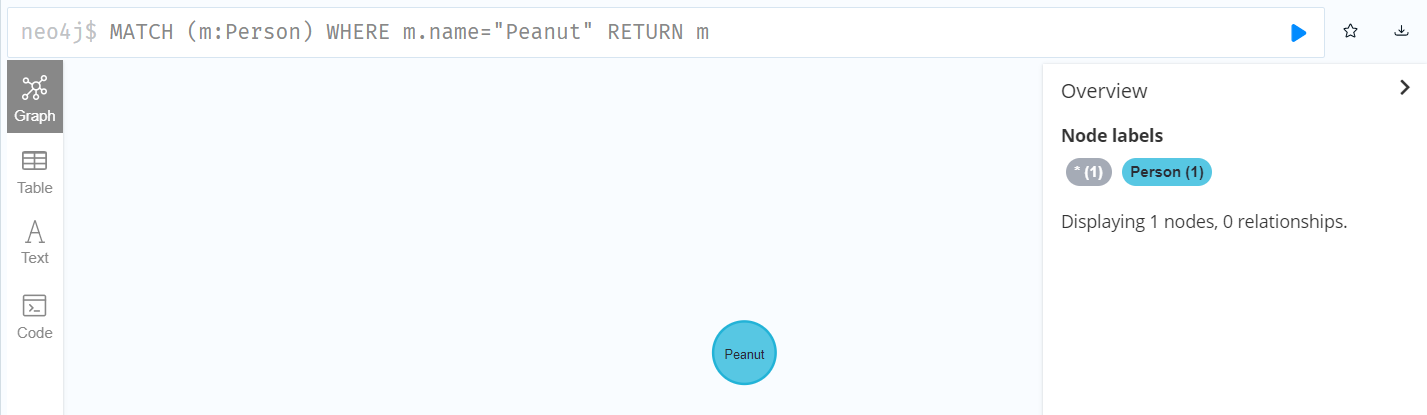
MATCH (m:Person) WHERE m.name="Peanut" RETURN m
// MATCH从句用来指定节点和关系的模式
// (m:Person)表示标签为Person的节点,并将这类节点的变量命名为m
// WHERE从句用来约束结果
// m.name="Peanut"比较了name属性值与"Peanut"的相等关系
// RETURN从句用于返回特定的结果
// 比如上句的含义为返回所有属于Person的节点中name属性值为"Peanut"的所有节点
MATCH (n:Person)-[:HAS_BORROWED]->(read) WHERE n.name="Neo4j" RETURN n,read
// MATCH从句描述了从已知节点到待寻找节点的模式
// -[:HAS_BORROWED]->匹配了可以是任意方向的关系HAS_BORROWED
// 上句的含义是查找neo4j借过的书籍(假设存在HAS_BORROWED关系即为看过)

4.2Projecting clauses
These comprise clauses that define which expressions to return in the result set. The returned expressions may all be aliased using AS.
这些子句定义在结果集中返回哪些表达式。返回的表达式都可以使用 AS 进行别名。
| Clause 条款 | Description 描述 |
|---|---|
RETURN ... [AS]返回... [ AS ] |
Defines what to include in the query result set.定义要在查询结果集中包含的内容。 |
WITH ... [AS]用... [ AS ] |
Allows query parts to be chained together, piping the results from one to be used as starting points or criteria in the next.允许将查询部分链接在一起,将结果从一个部分管道化,以用作下一个部分的起始点或条件。 |
UNWIND ... [AS]放松... ... [ AS ] |
Expands a list into a sequence of rows.将列表展开为一系列行。 |
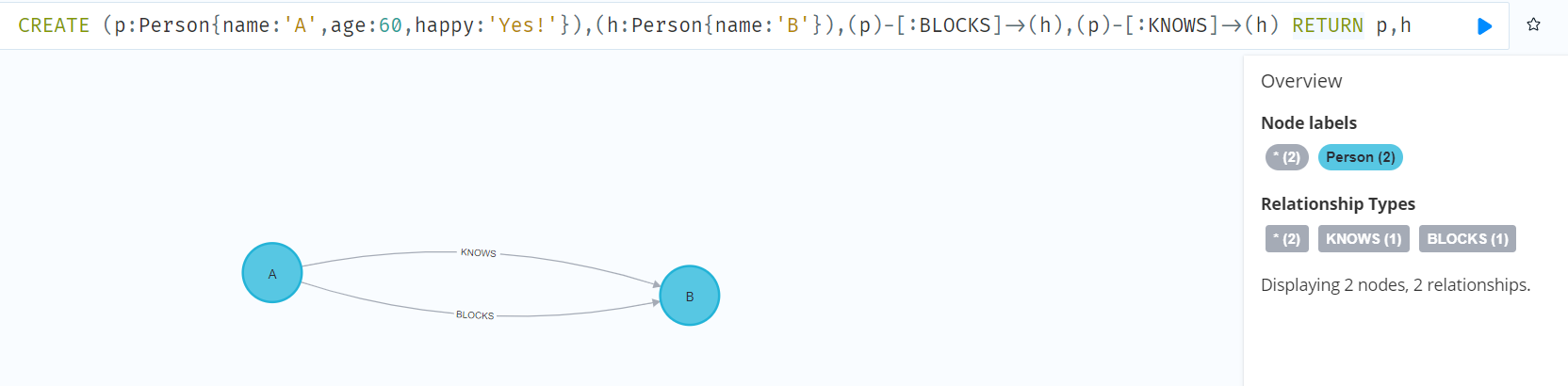
CREATE (p:Person{name:'A',age:60,happy:'Yes!'}),(h:Person{name:'B'}),(p)-[:BLOCKS]->(h),(p)-[:KNOWS]->(h) RETURN p,h
4.2.1RETURN
//Return nodes
MATCH (n{name:'B'}) RETURN n
//Return relationships
MATCH (n{name:'A'})-[r:KNOWS]->(c)
RETURN r
//Return property
MATCH (n{name:'A'}) RETURN n.name
//Return all elements
MATCH p=(a{name:'A'})-[r]->(b)
RETURN *
//Column alias 列别名
MATCH (a{name:'A'})
RETURN a.age AS SomethingTotallyDifferent
// Optional properties 可选属性
MATCH (n)
RETURN n.age
// Unique results 独特的结果
MATCH (a{name:'A'})-->(b)
RETURN DISTINCT b
4.2.2WITH
//MATCH (n) DETACH DELETE n
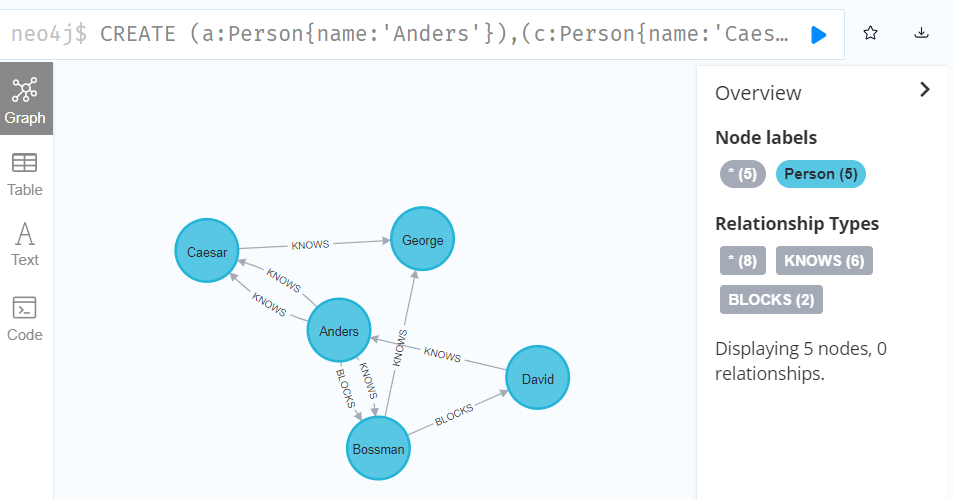
CREATE (a:Person{name:'Anders'}),(c:Person{name:'Caesar'}),(b:Person{name:'Bossman'}),(g:Person{name:'George'}),(d:Person{name:'David'}),(a)-[:BLOCKS]->(b),(a)-[:KNOWS]->(b),(a)-[:KNOWS]->(c),(c)-[:KNOWS]->(g),(a)-[:KNOWS]->(c),(b)-[:KNOWS]->(g),(d)-[:KNOWS]->(a),(b)-[:BLOCKS]->(d) RETURN a,b,c,d,g
//Introducing variables for expressions 为表达式引入变量
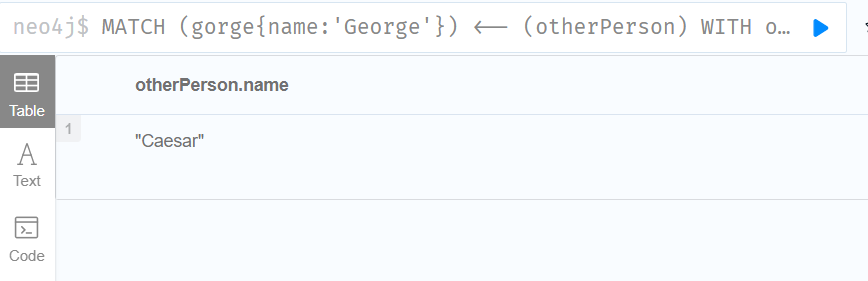
//这个查询返回与名字以 c 开头的“ George”连接的人的名字,而不考虑大小写。
MATCH (gorge{name:'George'}) <-- (otherPerson)
WITH otherPerson, toUpper(otherPerson.name) AS upperCaseName WHERE upperCaseName STARTS WITH 'C'
RETURN otherPerson.name
//Using the wildcard to carry over variables使用通配符传递变量
MATCH (person)-[r]->(otherPerson)
WITH *, type(r) AS connectionType
RETURN person.name, otherPerson.name,connectionType

//Filter on aggregate function results对聚合函数结果进行过滤
//查询将返回至少有一个外出关系的与“ David”连接的人的姓名。
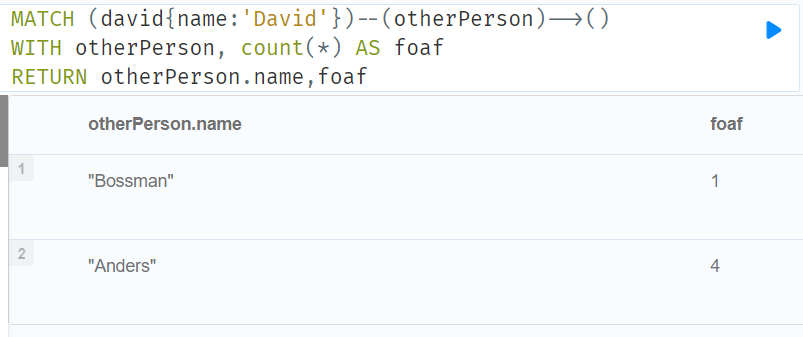
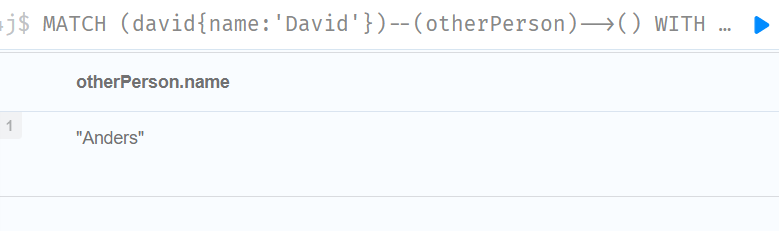
MATCH (david{name:'David'})--(otherPerson)-->()
WITH otherPerson, count(*) AS foaf
WHERE foaf > 1
RETURN otherPerson.name
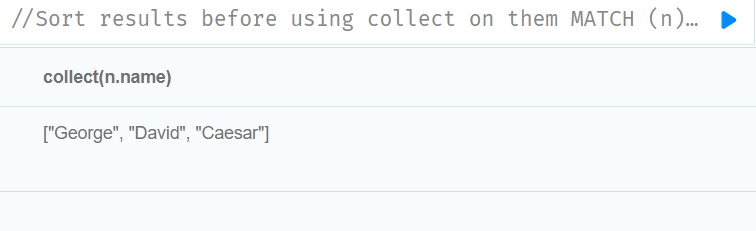
//Sort results before using collect on them
MATCH (n)
WITH n
ORDER BY n.name DESC
LIMIT 3
RETURN collect(n.name)
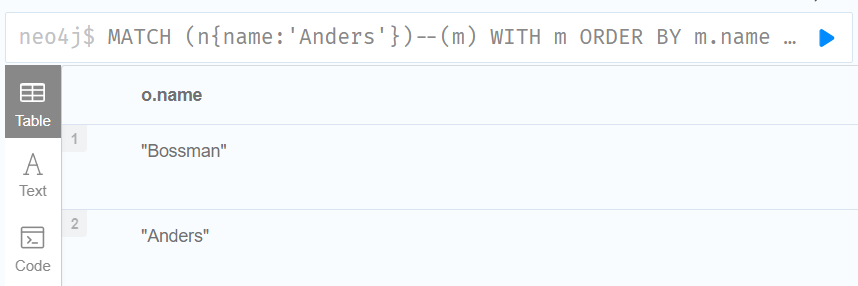
//Limit branching of a path search 限制路径搜索的分支
//从“ Anders”开始,找到所有匹配的节点,按名称降序排列,得到最高结果,然后找到所有连接到最高结果的节点,并返回它们的名称。
MATCH (n{name:'Anders'})--(m)
WITH m
ORDER BY m.name DESC
LIMIT 1
MATCH (m) -- (o)
RETURN o.name
4.2.3UNWIND
//Unwinding a list
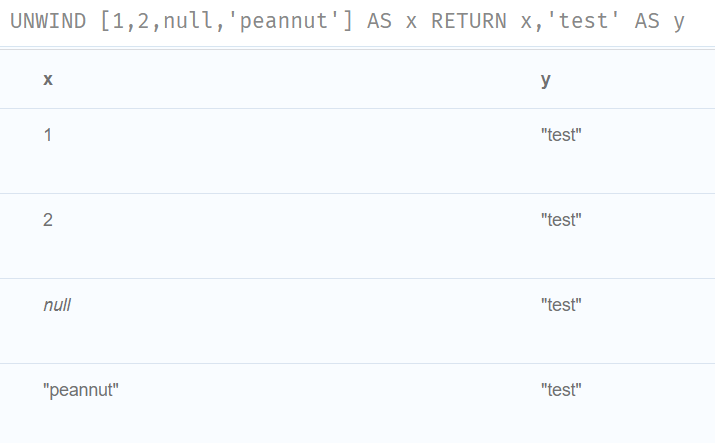
UNWIND [1,2,null,'peannut'] AS x
RETURN x,'test' AS y
//Creating a distinct list
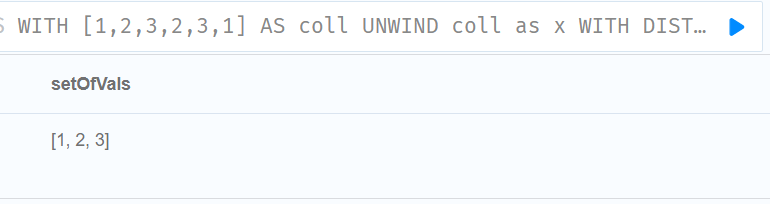
WITH [1,2,3,2,3,1] AS coll
UNWIND coll as x
WITH DISTINCT x
RETURN collect(x) AS setOfVals
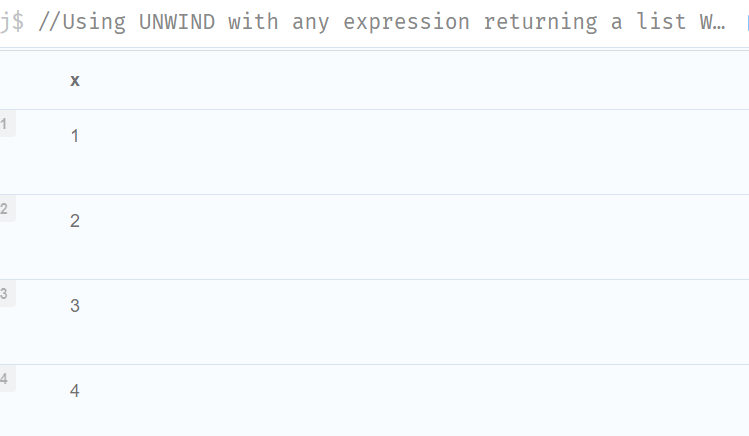
//Using UNWIND with any expression returning a list
WITH
[1,2] AS a,
[3,4] AS b
UNWIND (a+b) AS x
RETURN x
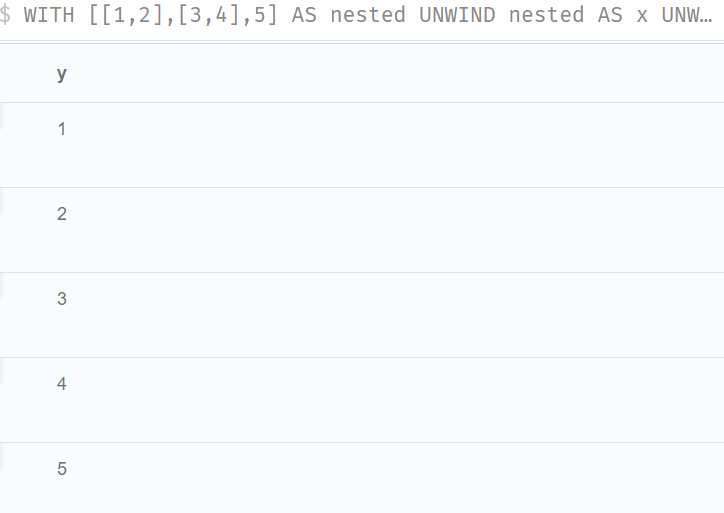
//Using UNWIND with a list of lists
WITH [[1,2],[3,4],5] AS nested
UNWIND nested AS x
UNWIND x as y
return y
//UsingUNWIND with an empty list
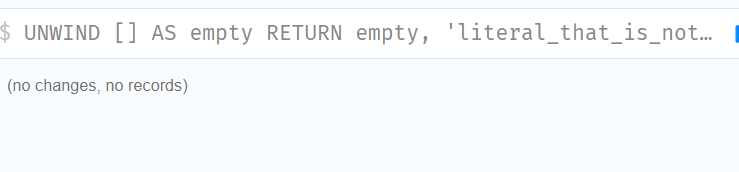
//UNWIND []将行数减少为零,从而导致查询停止执行,不返回任何结果
UNWIND [] AS empty
RETURN empty, 'literal_that_is_not_returned'
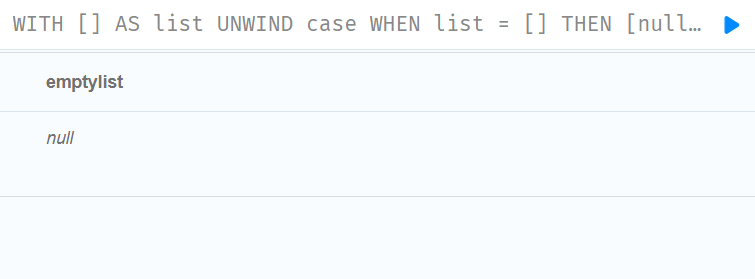
//为了避免无意中在空列表上使用 UNWIND,CASE 可以用 null 替换空列表
WITH [] AS list
UNWIND
case
WHEN list = [] THEN [null]
ELSE list
END AS emptylist
RETURN emptylist
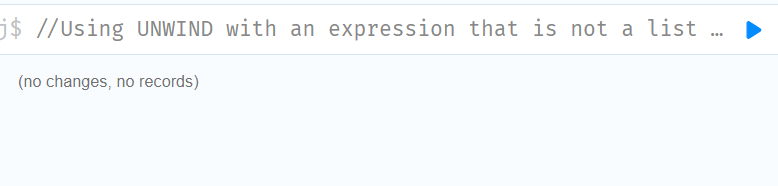
//Using UNWIND with an expression that is not a list
UNWIND null AS x
RETURN x, 'some_literal'
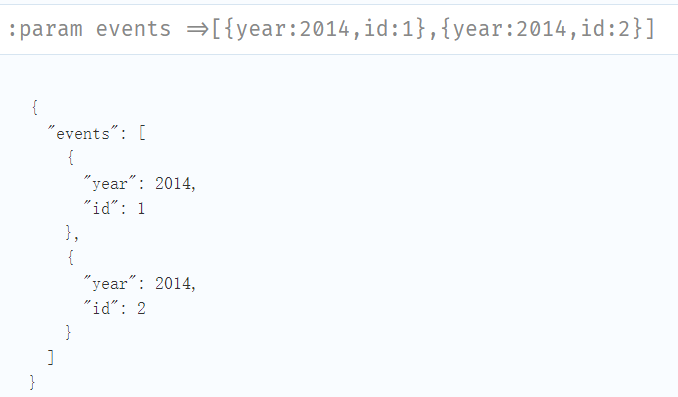
//Creating nodes from a list parameter
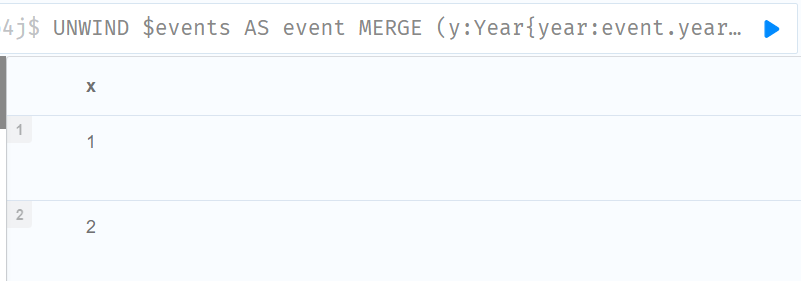
:param events =>[{year:2014,id:1},{year:2014,id:2}]
//原始列表的每个值都被解包,并通过 MERGE 传递以查找或创建节点和关系。
UNWIND $events AS event
MERGE (y:Year{year:event.year})
MERGE (y)<-[:IN]-(e:Event{id:event.id})
RETURN e.id AS x ORDER BY x
4.3Reading sub-clauses
These comprise sub-clauses that must operate as part of reading clauses.
这些条款包括必须作为阅读条款的一部分运作的子条款。
| Sub-clause 附属条款 | Description 描述 |
|---|---|
WHERE地点 |
Adds constraints to the patterns in a MATCH or OPTIONAL MATCH clause or filters the results of a WITH clause.在 MATCH 或 OPTIONAL MATCH 子句中向模式添加约束,或筛选 WITH 子句的结果。 |
WHERE EXISTS { ... }存在的地方 |
An existential sub-query used to filter the results of a MATCH, OPTIONAL MATCH or WITH clause.用于筛选 MATCH、 OPTIONAL MATCH 或 WITH 子句的结果的存在子查询。 |
| `ORDER BY [ASC[ENDING] | DESC[ENDING]]`订单由[ ASC [结束] | DESC [结束] |
SKIP跳过 |
Defines from which row to start including the rows in the output.定义从哪一行开始,包括输出中的行。 |
LIMIT极限 |
Constrains the number of rows in the output.限制输出中的行数。 |
4.3.1WHERE
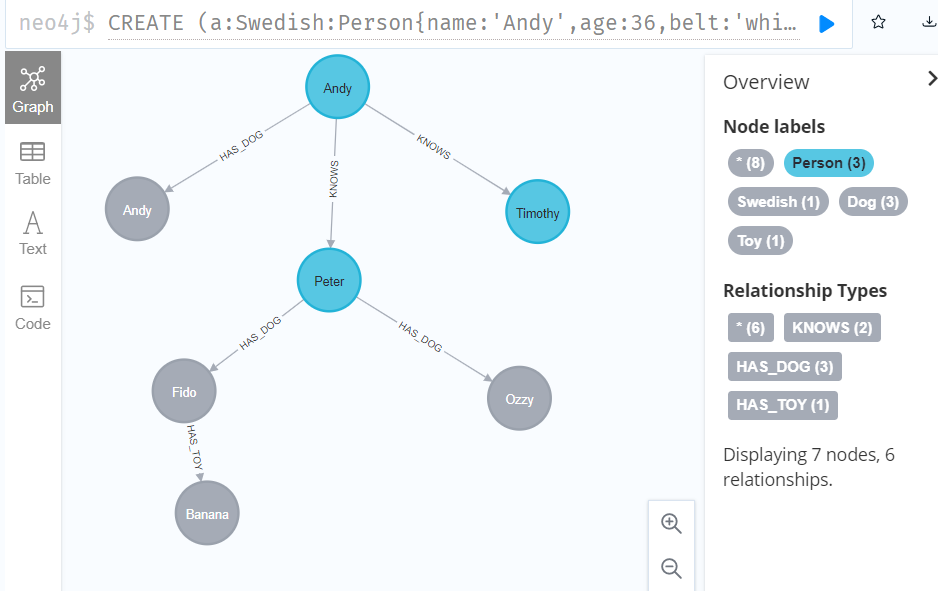
CREATE (a:Swedish:Person{name:'Andy',age:36,belt:'white'}),(an:Dog{name:'Andy'}),(p:Person{name:'Peter',email:'peter_n@example.com',age:35}),(t:Person{age:25,address:'Sweden/Malmo',name:'Timothy'}),(f:Dog{name:'Fido'}),(o:Dog{name:'Ozzy'}),(b:Toy{name:'Banana'}),(a)-[:HAS_DOG{since:2016}]->(an),(p)-[:HAS_DOG{since:2010}]->(f),(p)-[:HAS_DOG{since:2018}]->(o),(a)-[:KNOWS{since:1999}]->(p),(a)-[:KNOWS{since:2012}]->(t),(f)-[:HAS_TOY]->(b) RETURN a,an,p,t,f,o,b
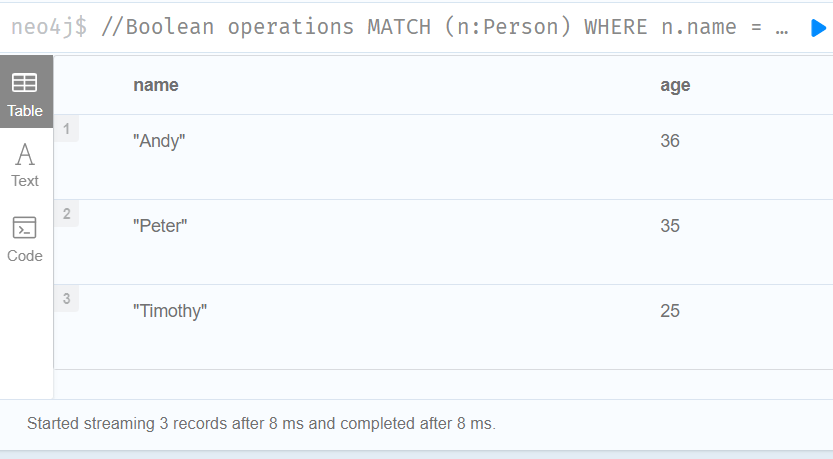
//Boolean operations
MATCH (n:Person)
WHERE n.name = 'Peter' XOR (n.age < 30 AND n.name = 'Timothy') OR NOT (n.name = 'Timothy' OR n.name = 'Peter')
RETURN
n.name AS name,
n.age AS age
ORDER BY name
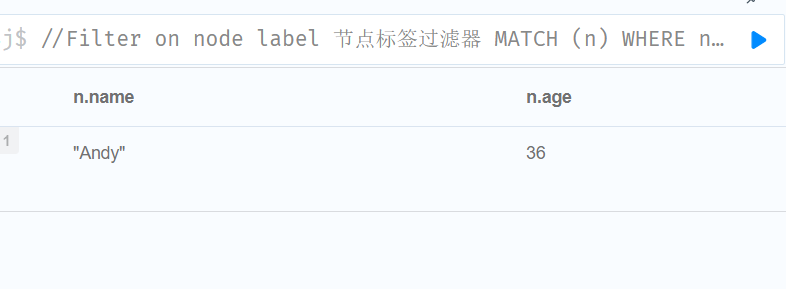
//Filter on node label 节点标签过滤器
MATCH (n)
WHERE n:Swedish
RETURN n.name, n.age
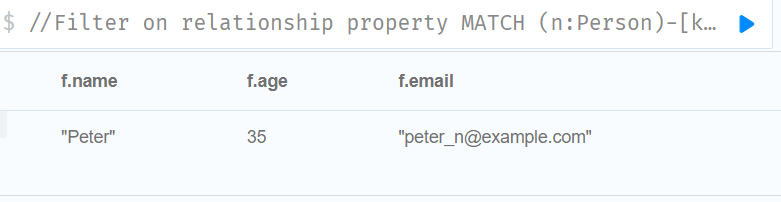
//Filter on relationship property
MATCH (n:Person)-[k:KNOWS]->(f)
WHERE k.since < 2000
RETURN f.name, f.age, f.email
//Filter on dynamically-computed node property
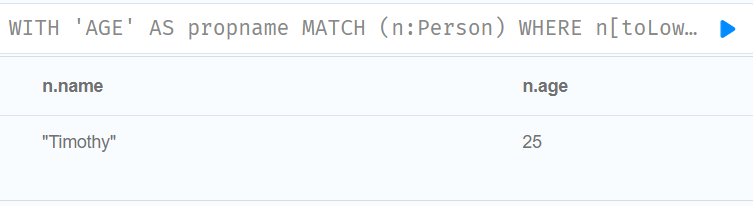
//基于动态计算节点属性的过滤器
WITH 'AGE' AS propname
MATCH (n:Person)
WHERE n[toLower(propname)] < 30
RETURN n.name, n.age
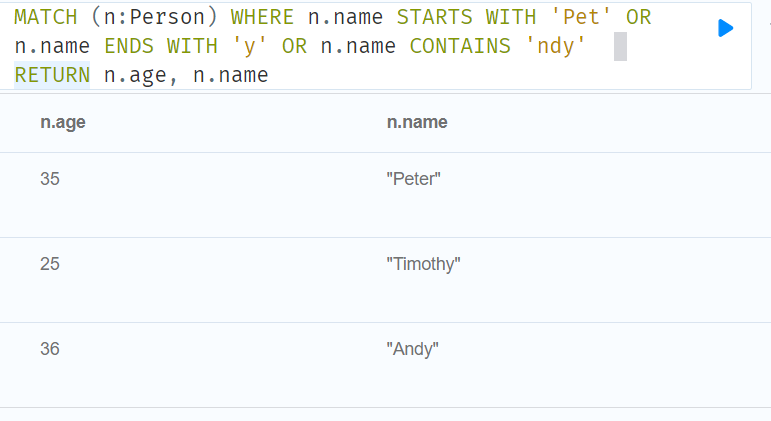
MATCH (n:Person) WHERE n.name STARTS WITH 'Pet' OR n.name ENDS WITH 'y' OR n.name CONTAINS 'ndy' RETURN n.age, n.name
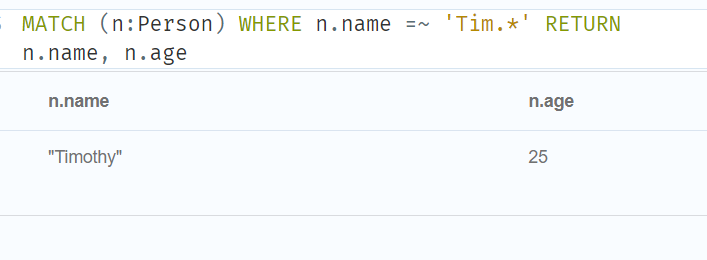
//可以使用 = ~ ‘ regexp’匹配正则表达式,如下所示:
MATCH (n:Person) WHERE n.name =~ 'Tim.*' RETURN n.name, n.age
//Escaping in regular expressions 正则表达式中的转义
MATCH (n:Person) WHERE n.email =~ '.*\\.com' RETURN n.name, n.age, n.email
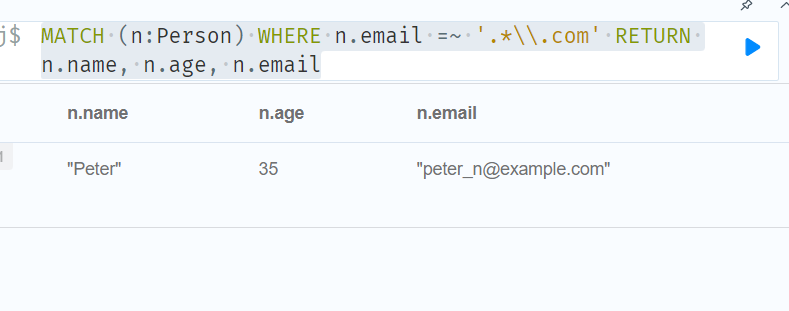
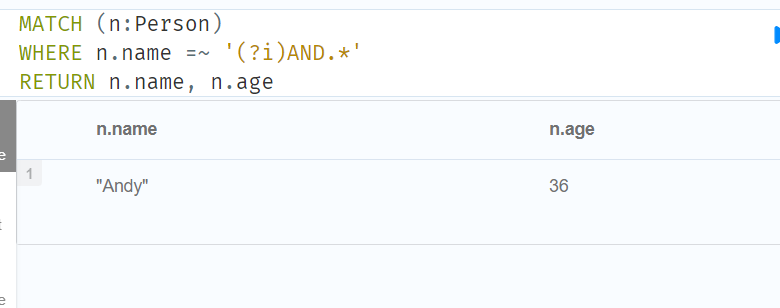
//Case-insensitive regular expressions不区分大小写的正则表达式
MATCH (n:Person)
WHERE n.name =~ '(?i)AND.*'
RETURN n.name, n.age
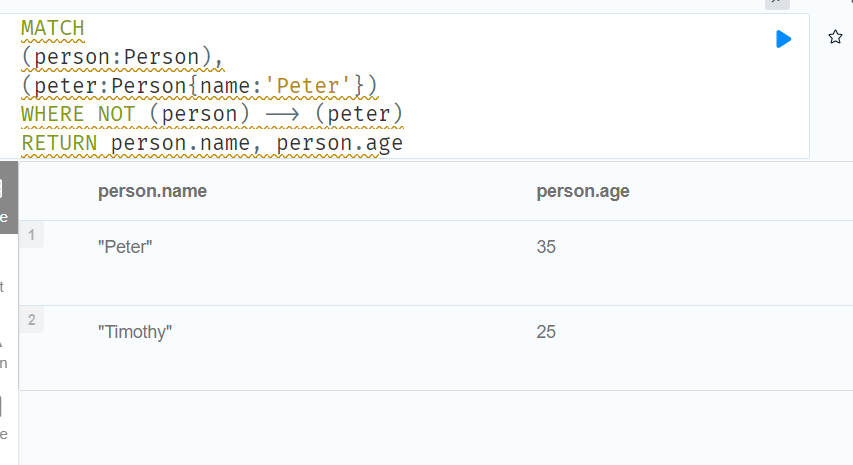
//WHERE 子句完全是关于消除匹配路径的。MATCH (a)-[ * ]-> (b)与 WHERE (a)-[ * ]-> (b)非常不同。第一种方法将为 a 和 b 之间的每条路径生成一条路径,而后者将消除 a 和 b 之间没有定向关系链的任何匹配路径。
MATCH
(person:Person),
(peter:Person{name:'Peter'})
WHERE NOT (person) --> (peter)
RETURN person.name, person.age
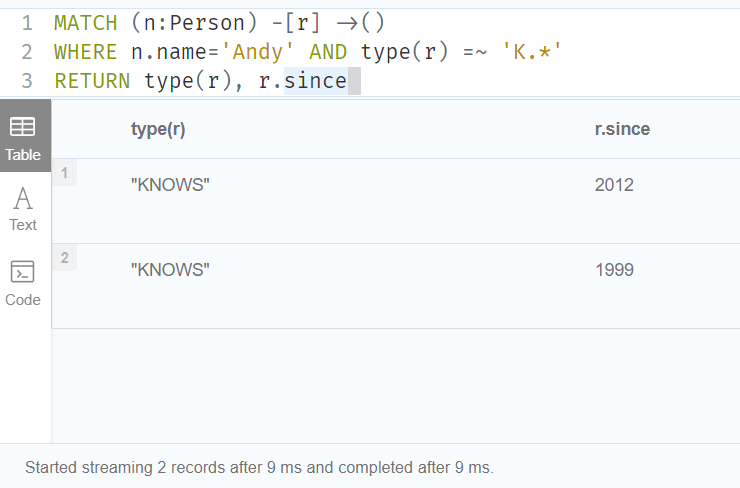
//Filter on relationship type 过滤关系类型
MATCH (n:Person) -[r] ->()
WHERE n.name='Andy' AND type(r) =~ 'K.*'
RETURN type(r), r.since
//Using existential subqueries in WHERE
//由外部范围引入的变量可以在内部 MATCH 子句中使用:
MATCH (person:Person)
WHERE EXISTS{
MATCH (person)-[:HAS_DOG]->(:Dog)
}
RETURN person.name AS name
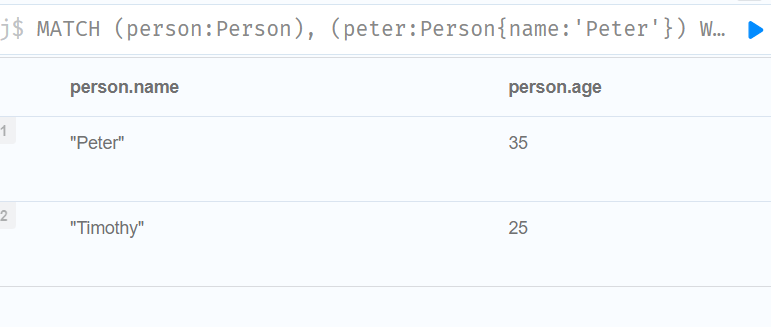
//Nesting existential subqueries 嵌套存在子查询
MATCH (person:Person)
WHERE EXISTS{
MATCH (person)-[:HAS_DOG]->(dog:Dog)
WHERE EXISTS{
MATCH (dog)-[:HAS_TOY]->(toy:Toy)
WHERE toy.name = 'Banana'
}
}
RETURN person.name AS name
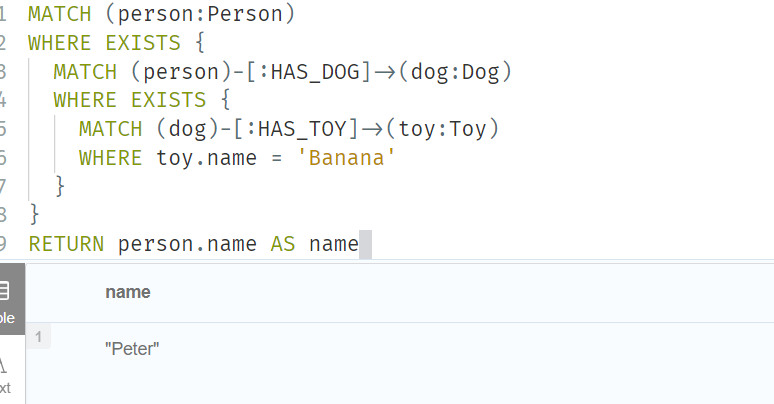
// IN operator
MATCH (a:Person)
WHERE a.name IN ['Peter','Timothy']
RETURN a.name, a.age
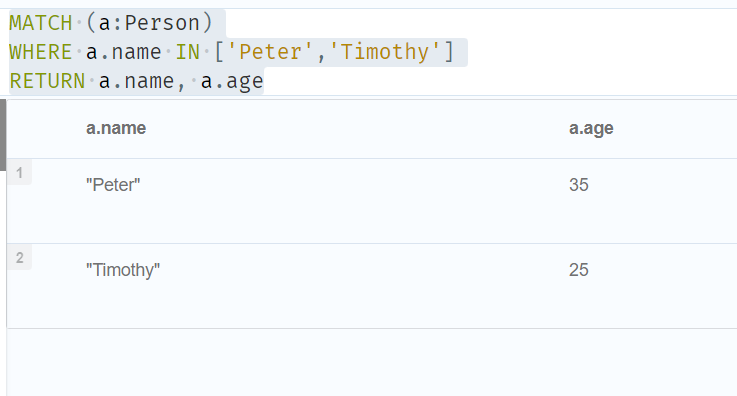
//Default to false if property is missing
MATCH (n:Person)
WHERE n.belt = 'white'
RETURN n.name, n.age, n.belt
//Default to true if property is missing
MATCH (n:Person)
WHERE n.belt = 'white' OR n.belt IS NULL
RETURN n.name, n.age, n.belt
ORDER BY n.name

//Using ranges
//Composite range 复合范围
MATCH (a:Person)
WHERE a.name > 'Andy' AND a.name < 'Timothy'
RETURN a.name, a.age
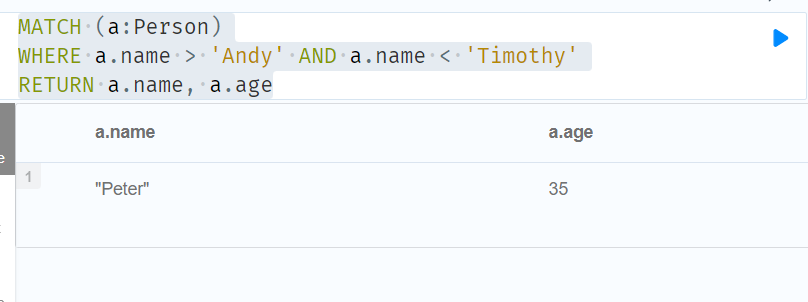
//Node pattern predicates
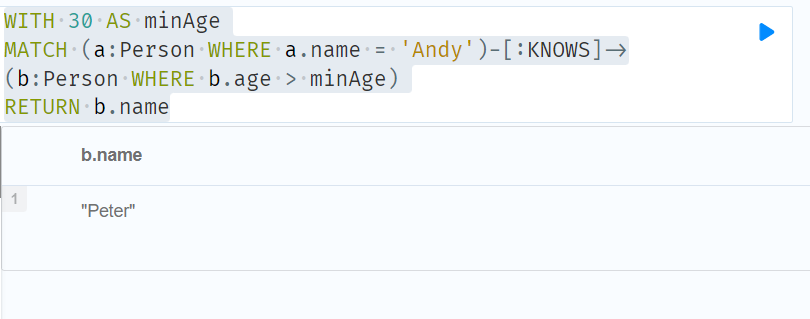
//WHERE 可以出现在 MATCH 子句或模式理解中的节点模式中:
WITH 30 AS minAge
MATCH (a:Person WHERE a.name = 'Andy')-[:KNOWS]->(b:Person WHERE b.age > minAge)
RETURN b.name
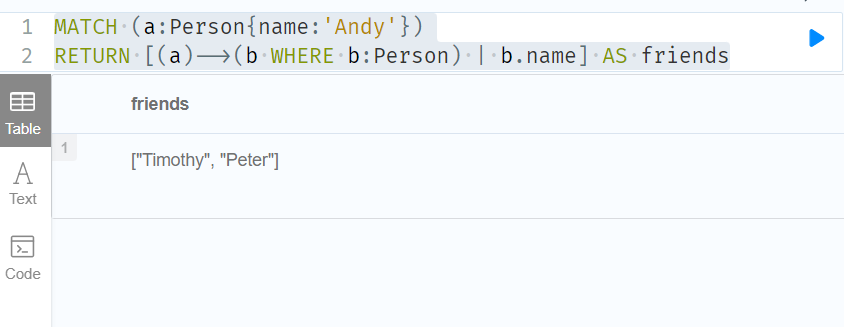
MATCH (a:Person{name:'Andy'})
RETURN [(a)-->(b WHERE b:Person) | b.name] AS friends
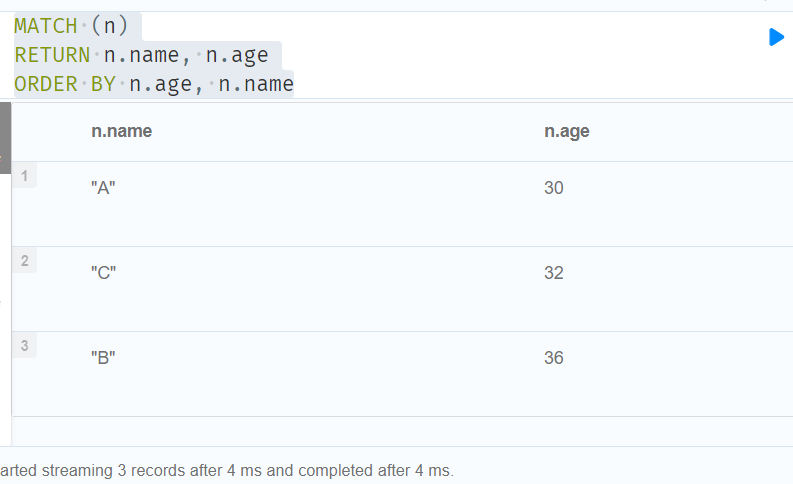
4.3.2ORDER BY
CREATE (a:Person{name:'A',age:30,length:150}),
(b:Person{name:'B',age:36}),
(c:Person{name:'C',age:32,length:177}),
(a)-[:KNOWS]->(b),(b)-[:KNOWS]->(c) RETURN a,b,c

MATCH (n)
RETURN n.name, n.age
ORDER BY n.age, n.name
MATCH (n)
RETURN n.name, n.age
ORDER BY id(n)
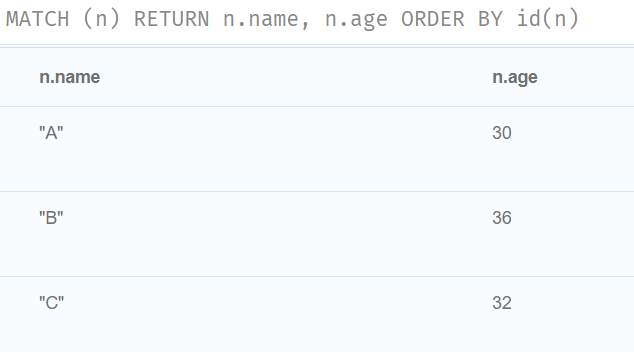
//返回节点,按其属性进行排序。
MATCH (n)
RETURN n.name, n.age, n.length
ORDER BY keys(n)
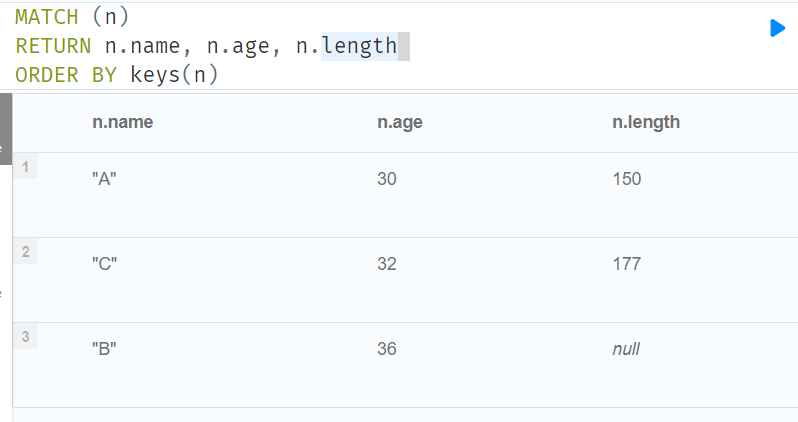
//Ordering in a WITH clause
MATCH (n)
WITH n ORDER BY n.age
RETURN collect(n.name) AS names

4.3.3SKIP
CREATE (a:Person{name:'A'}),
(b:Person{name:'B'}),(c:Person{name:'C'}),
(d:Person{name:'D'}),(e:Person{name:'E'}),
(a)-[:KNOWS]->(b),(a)-[:KNOWS]->(c),
(a)-[:KNOWS]->(d),(a)-[:KNOWS]->(e) RETURN a,b,c,d,e
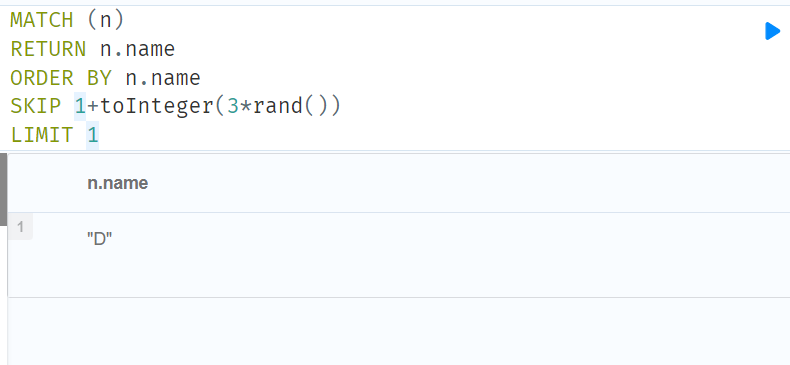
//Using an expression with SKIP to return a subset of the rows
//Skip 接受任何计算结果为正整数的表达式,只要它不引用任何外部变量:
//随机跳过第一行加0、1或2,所以随机跳过1、2或3行。
MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP 1+toInteger(3*rand())
LIMIT 1
4.3.4LIMIT
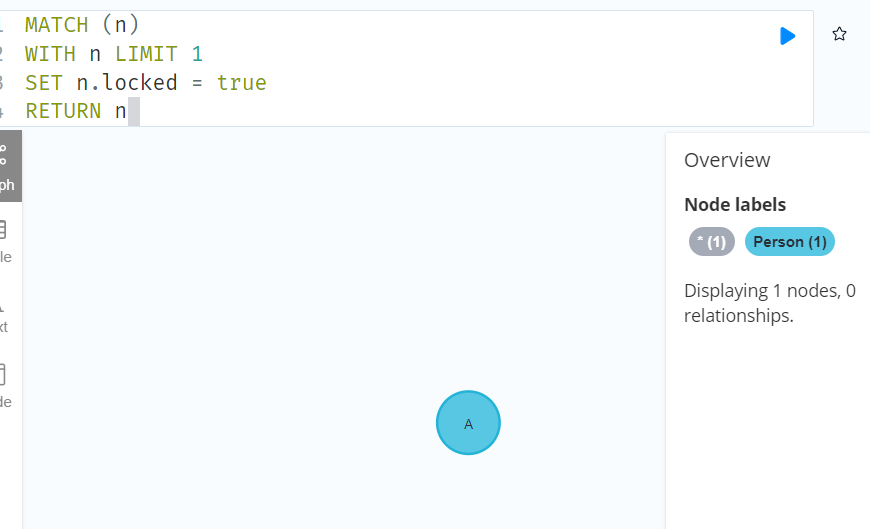
//如果我们想要限制更新的次数,我们可以使用 WITH 子句分割查询:
MATCH (n)
WITH n LIMIT 1
SET n.locked = true
RETURN n
4.4Reading hints
These comprise clauses used to specify planner hints when tuning a query. More details regarding the usage of these — and query tuning in general — can be found in Planner hints and the USING keyword.
这些子句包含用于在调优查询时指定计划提示的子句。在 Planner 提示和 USING 关键字中可以找到更多关于这些(以及一般的查询调优)的使用细节。
| Hint 提示 | Description 描述 |
|---|---|
USING INDEX使用索引 |
Index hints are used to specify which index, if any, the planner should use as a starting point.索引提示用于指定计划者应该使用哪个索引(如果有的话)作为起点。 |
USING INDEX SEEK使用索引搜索 |
Index seek hint instructs the planner to use an index seek for this clause.索引查找提示指示计划器为此子句使用索引查找。 |
USING SCAN使用扫描 |
Scan hints are used to force the planner to do a label scan (followed by a filtering operation) instead of using an index.扫描提示用于强制计划器进行标签扫描(然后是过滤操作) ,而不是使用索引。 |
USING JOIN使用 JOIN |
Join hints are used to enforce a join operation at specified points.连接提示用于在指定点执行连接操作。 |
4.5Writing clauses
These comprise clauses that write the data to the database.
这些包括将数据写入数据库的子句。
| Clause 条款 | Description 描述 |
|---|---|
CREATE创造 |
Create nodes and relationships.创建节点和关系。 |
DELETE删除 |
Delete nodes, relationships or paths. Any node to be deleted must also have all associated relationships explicitly deleted.删除节点、关系或路径。要删除的任何节点还必须显式删除所有相关联的关系。 |
DETACH DELETE分离/删除 |
Delete a node or set of nodes. All associated relationships will automatically be deleted.删除一个节点或一组节点。所有相关联的关系将自动删除。 |
SET设置 |
Update labels on nodes and properties on nodes and relationships.更新节点上的标签以及节点和关系上的属性。 |
REMOVE移除 |
Remove properties and labels from nodes and relationships.从节点和关系中删除属性和标签。 |
FOREACH海洋环境学会 |
Update data within a list, whether components of a path, or the result of aggregation.更新列表中的数据,无论是路径的组件还是聚合的结果。 |
4.5.1CREATE命令
match (n) detach delete n //清除数据
CREATE (p:Person {name:"Peanut",from:"China"})
// CREATE从句可以用来生成数据
// CREATE ()表示生成一个node
// p:Person表示变量p和标签Person,p可以指示此节点
// {}中的键值对是节点内的属性
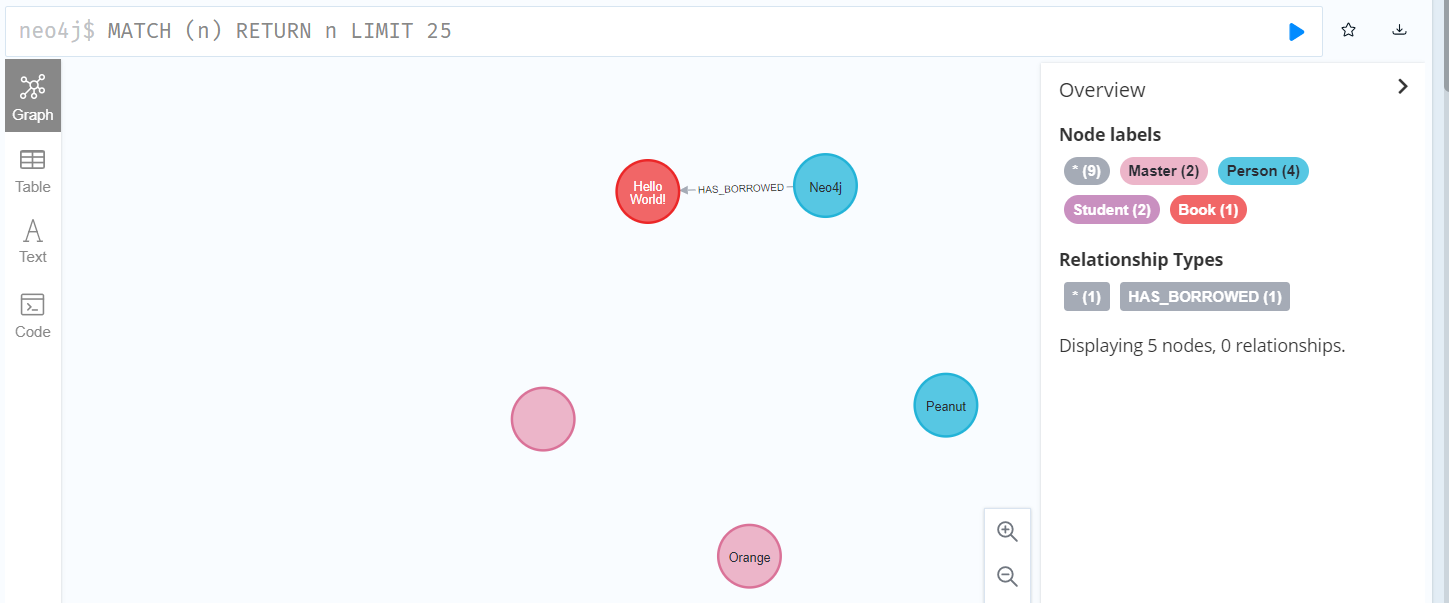
CREATE (p:Person{name:"Neo4j",from:"China"}),
(b:Book{title:"Hello World!",from:"China"}),
(p)-[:HAS_BORROWED{since:2022-10-11}]->(b)
// 若想同时生成多个数据需要使用','分隔
// ()-[]->()格式用来生成关系,()中写的是节点变量名,[]中的:后为关系的标签名,关系也可以使用{}生成关系的属性
//创建多个标签名称
create (p:Person:Student:Master{name:'Orange'})
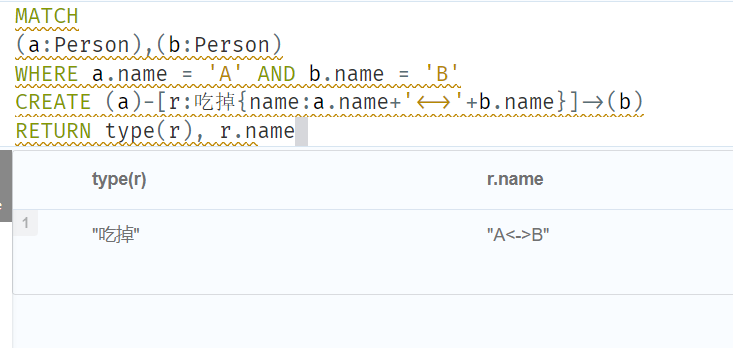
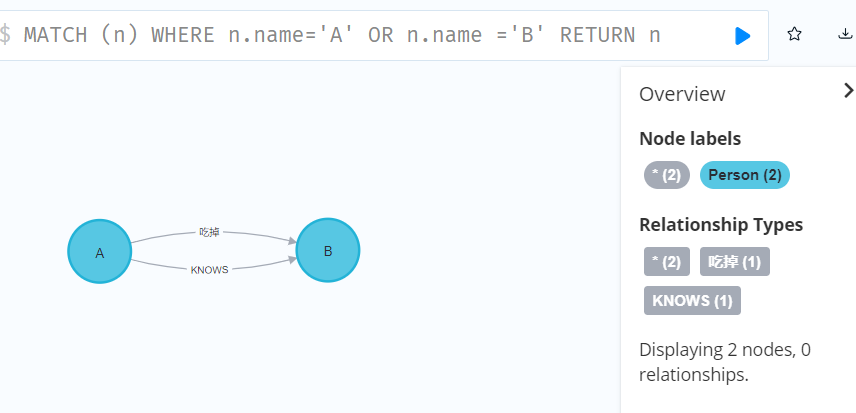
//Create a relationship and set properties
MATCH
(a:Person),(b:Person)
WHERE a.name = 'A' AND b.name = 'B'
CREATE (a)-[r:吃掉{name:a.name+'<->'+b.name}]->(b)
RETURN type(r), r.name
//Create a full path
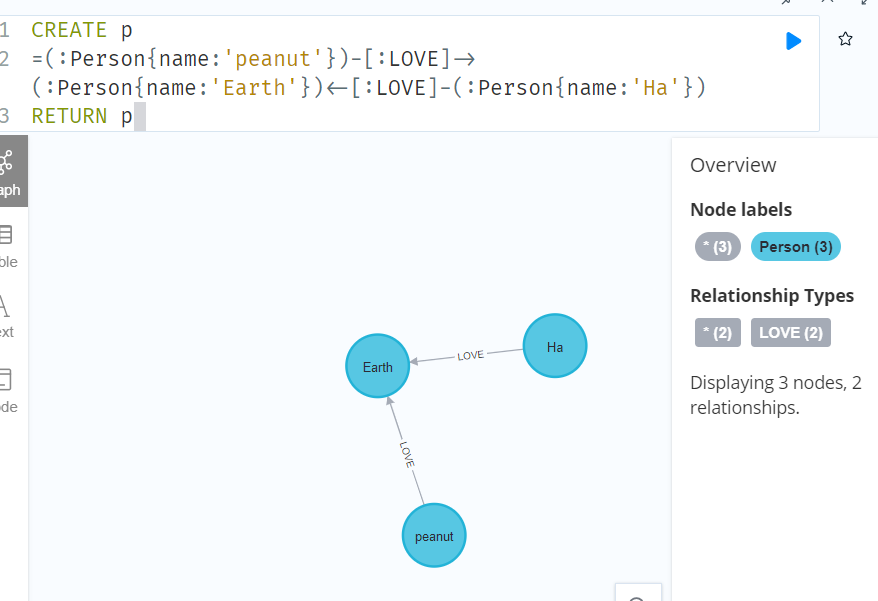
CREATE p
=(:Person{name:'peanut'})-[:LOVE]->(:Person{name:'Earth'})<-[:LOVE]-(:Person{name:'Ha'})
RETURN p
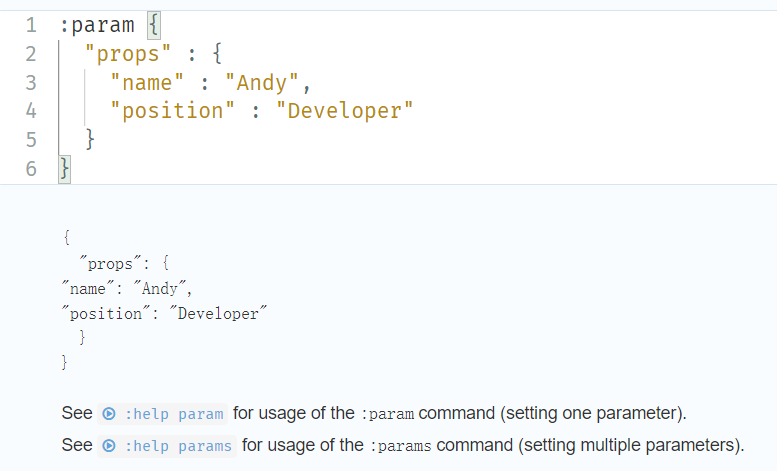
//:param {
"props" : {
"name" : "Andy",
"position" : "Developer"
}
}
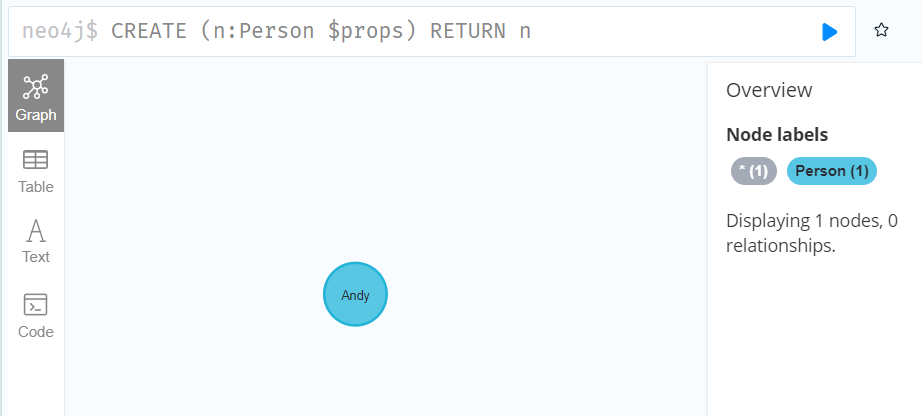
CREATE (n:Person $props)
RETURN n
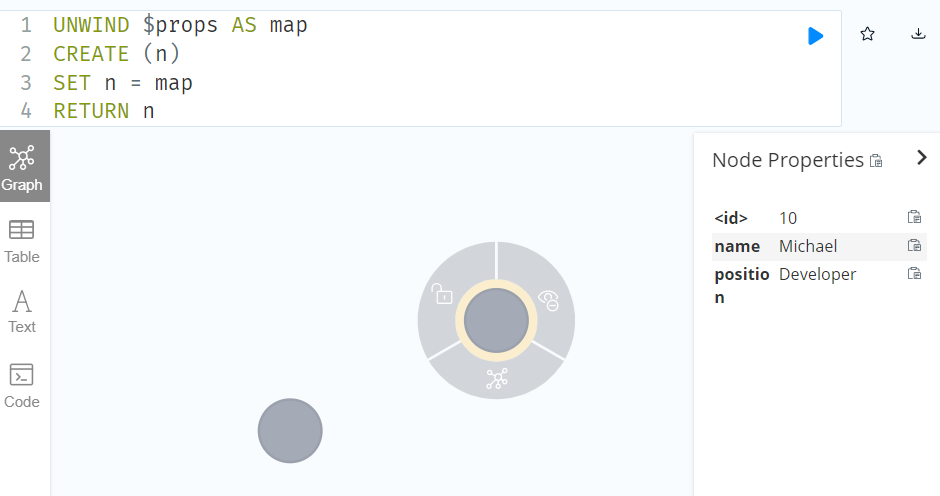
//Create multiple nodes with a parameter for their properties
:param {
"props" : [ {
"name" : "Andy",
"position" : "Developer"
}, {
"name" : "Michael",
"position" : "Developer"
} ]
}
UNWIND $props AS map
CREATE (n)
SET n = map
RETURN n
4.5.2DELETE
CREATE (a:Person{age:36,name:'Andy'}),
(u:Person{name:'UNKNOWN'}),
(t:Person{name:'Timothy',age:25}),
(p:Person{name:'Peter',age:34}),
(a)-[:KNOWS]->(t),
(a)-[:KNOWS]->(p)
RETURN a,t,p,u
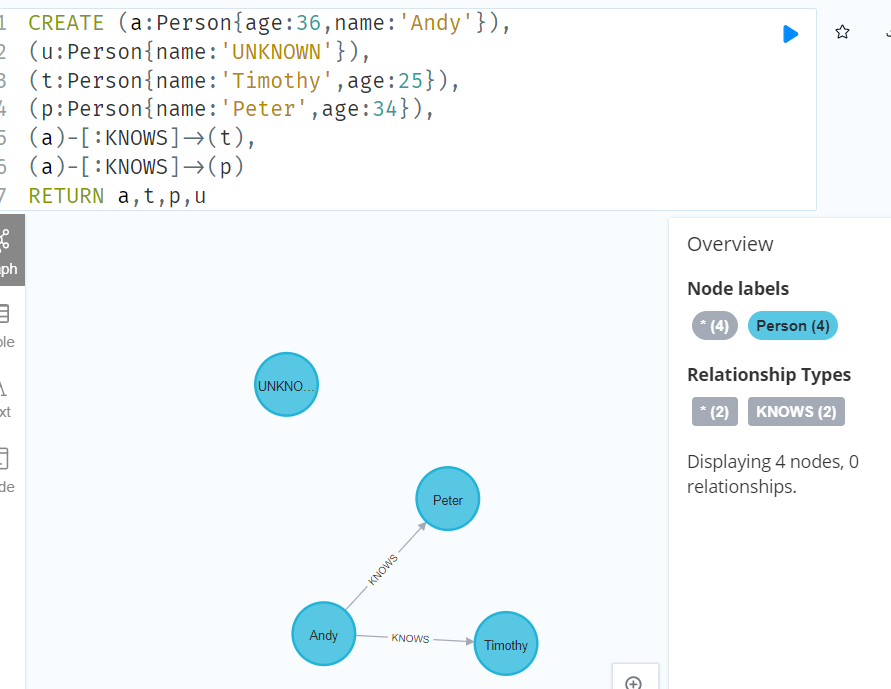
//Delete all nodes and relationships
//此查询不用于删除大量数据,但在试验小型示例数据集时非常有用。
MATCH (n)
DETACH DELETE n
4.5.3SET
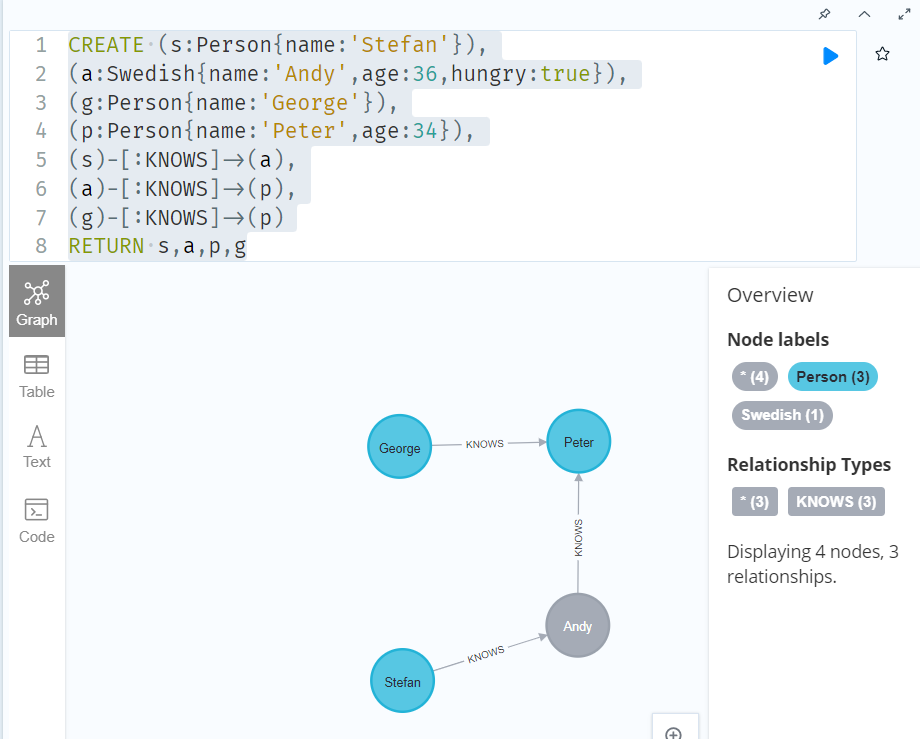
CREATE (s:Person{name:'Stefan'}),
(a:Swedish{name:'Andy',age:36,hungry:true}),
(g:Person{name:'George'}),
(p:Person{name:'Peter',age:34}),
(s)-[:KNOWS]->(a),
(a)-[:KNOWS]->(p),
(g)-[:KNOWS]->(p)
RETURN s,a,p,g
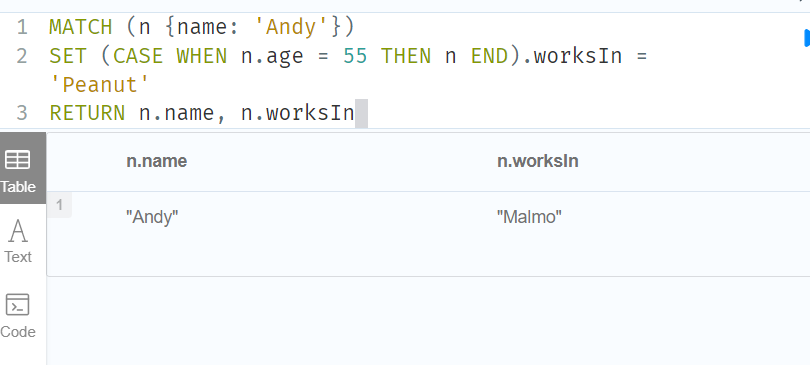
MATCH (n {name: 'Andy'})
SET (CASE WHEN n.age = 36 THEN n END).worksIn = 'Malmo'
RETURN n.name, n.worksIn

//没有节点匹配 CASE 表达式,所以表达式返回 null
MATCH (n {name: 'Andy'})
SET (CASE WHEN n.age = 55 THEN n END).worksIn = 'Peanut'
RETURN n.name, n.worksIn
//Update a property
MATCH (n {name: 'Andy'})
SET n.age = toString(n.age)
RETURN n.name, n.age
//Remove a property
MATCH (n {name: 'Andy'})
SET n.name = null
RETURN n.name, n.age
// Copy properties between nodes and relationships
MATCH
(at {name: 'Andy'}),
(pn {name: 'Peter'})
SET at = pn
RETURN at.name, at.age, at.hungry, pn.name, pn.age
// Replace all properties using a map and =
MATCH (p {name: 'Peter'})
SET p = {name: 'Peter Smith', position: 'Entrepreneur'}
RETURN p.name, p.age, p.position
//Remove all properties using an empty map and =
MATCH (p {name: 'Peter'})
SET p = {}
RETURN p.name, p.age
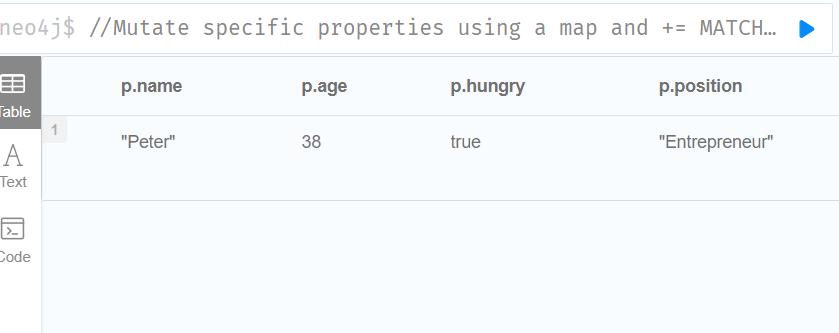
//Mutate specific properties using a map and +=
MATCH (p {name: 'Peter'})
SET p += {age: 38, hungry: true, position: 'Entrepreneur'}
RETURN p.name, p.age, p.hungry, p.position
//用逗号分隔多个属性,一次设置多个属性:
MATCH (n {name: 'Andy'})
SET n.position = 'Developer', n.surname = 'Taylor'
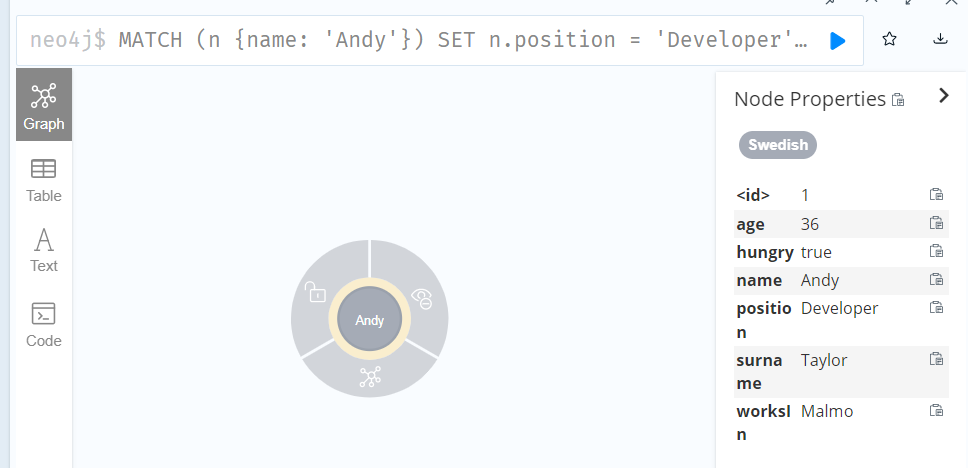
//Set a property using a parameter
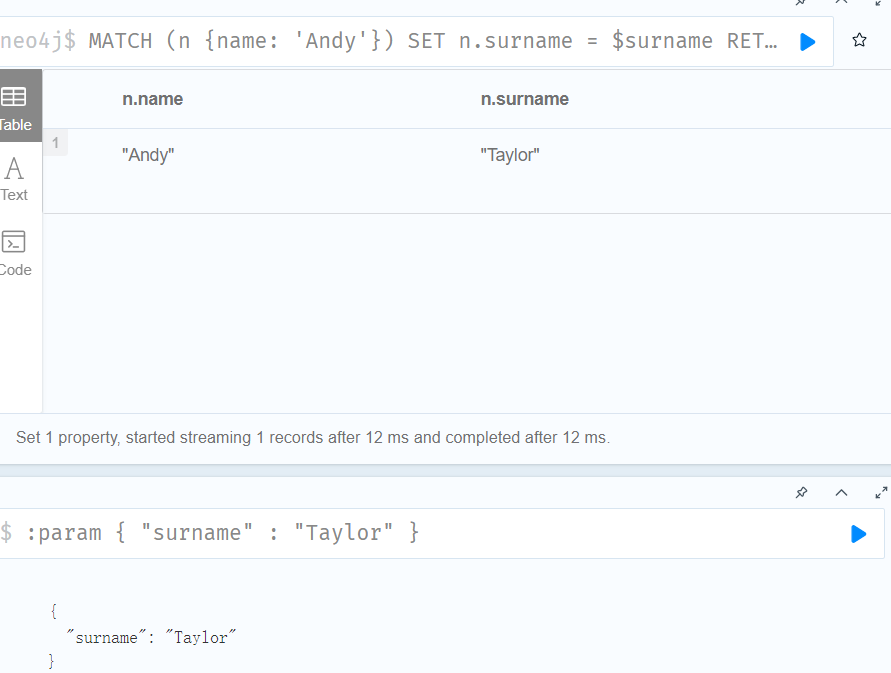
:param {
"surname" : "Taylor"
}
MATCH (n {name: 'Andy'})
SET n.surname = $surname
RETURN n.name, n.surname
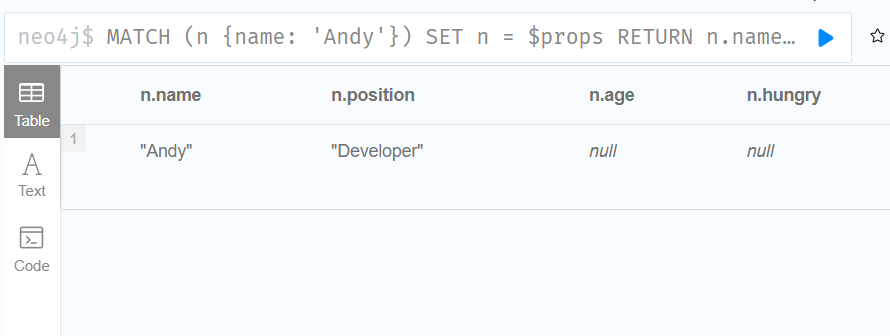
:param {
"props" : {
"name" : "Andy",
"position" : "Developer"
}
}
MATCH (n {name: 'Andy'})
SET n = $props
RETURN n.name, n.position, n.age, n.hungry
// Set a label on a node
MATCH (n{name:'Stefan'})
SET n:German
RETURN n.name, labels(n) AS labels

// Set multiple labels on a node
MATCH (n {name: 'George'})
SET n:Swedish:Bossman
RETURN n.name, labels(n) AS labels
4.5.4REMOVE
//Remove a property
MATCH (a {name: 'Andy'})
REMOVE a.age
RETURN a
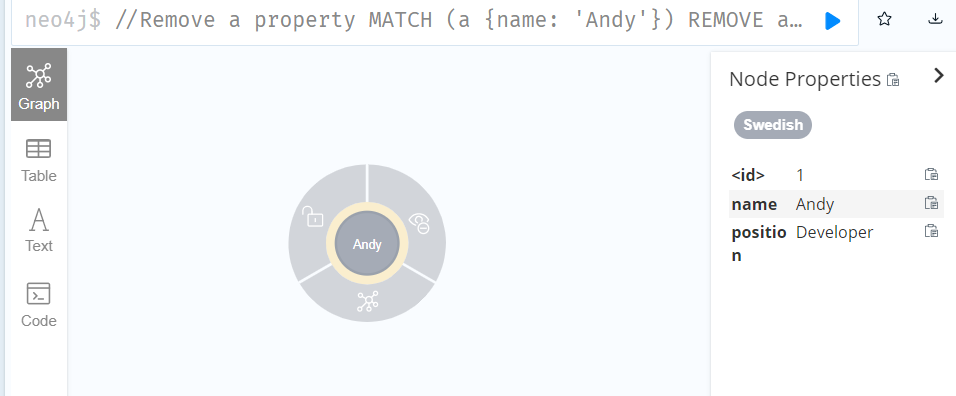
//Remove multiple labels from a node
MATCH (n {name: 'Peter'})
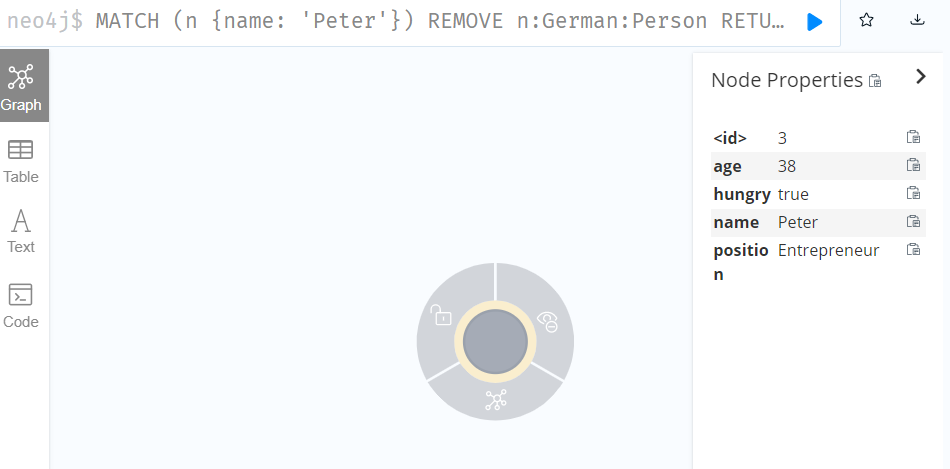
REMOVE n:German:Person
RETURN n
4.5.5FOREACH
FOREACH 子句用于更新集合中的数据,无论是路径的组件还是聚合的结果。
FOREACH 括号内的变量上下文与外部的变量上下文是分开的
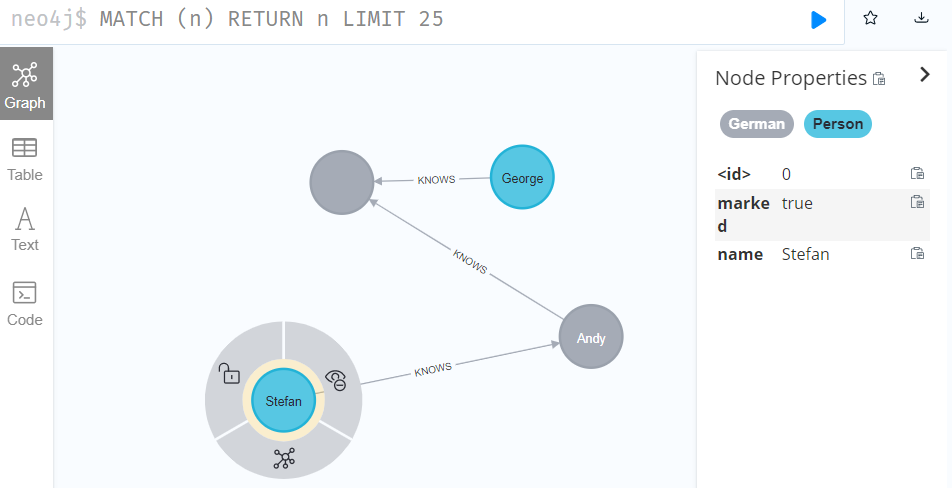
MATCH p=(start)-[*]->(finish)
WHERE start.name='Stefan' AND finish.name = 'Andy'
FOREACH (n IN nodes(p) | set n.marked = true)
4.6Reading/Writing clauses
These comprise clauses that both read data from and write data to the database.
这些子句包括从数据库读取数据和将数据写入数据库的子句。
| Clause 条款 | Description 描述 |
|---|---|
MERGE合并 |
Ensures that a pattern exists in the graph. Either the pattern already exists, or it needs to be created.确保图形中存在模式。要么模式已经存在,要么需要创建它。 |
--- ON CREATE——关于创造 |
Used in conjunction with MERGE, this write sub-clause specifies the actions to take if the pattern needs to be created.这个 write 子句与 MERGE 一起使用,它指定在需要创建模式时要采取的操作。 |
--- ON MATCH——-ON MATCH |
Used in conjunction with MERGE, this write sub-clause specifies the actions to take if the pattern already exists.这个 write 子句与 MERGE 一起使用,它指定了如果模式已经存在时要采取的操作。 |
CALL ... [YIELD ... ]呼叫... [屈服... ] |
Invokes a procedure deployed in the database and return any results.调用部署在数据库中的过程并返回任何结果。 |
4.6.1MERGE(完全模式)
无论何时,我们从外部系统获取数据时,都无法确定某些信息是否在图中已经存在。这时可以使用MERGE语句,它的工作方式类似于MATCH和CREATE的结合。MERGE语句在增加数据时会首先检查数据是否存在,如果存在则进行匹配,否则便会创建新的数据。MERGE子句后可以显式指定ON CREATE或ON MATCH子句,通过MERGE子句可以指定图形中必须存在一个节点且必须具有特定的标签和属性等,如果不存在则会创建相应的节点。但是MERGE语句会增加执行时间,因为其需要首先检查存在性,所以在确定不会新增重复数据时,建议使用CREATE。
// 若我们不知道电影是否存在,且需要为它添加新属性,则可以使用MERGE
// 如果需要创建节点,则执行ON CREATE子句,更新节点数据
// 如果节点已存在,则执行ON MATCH子句,修改节点数据
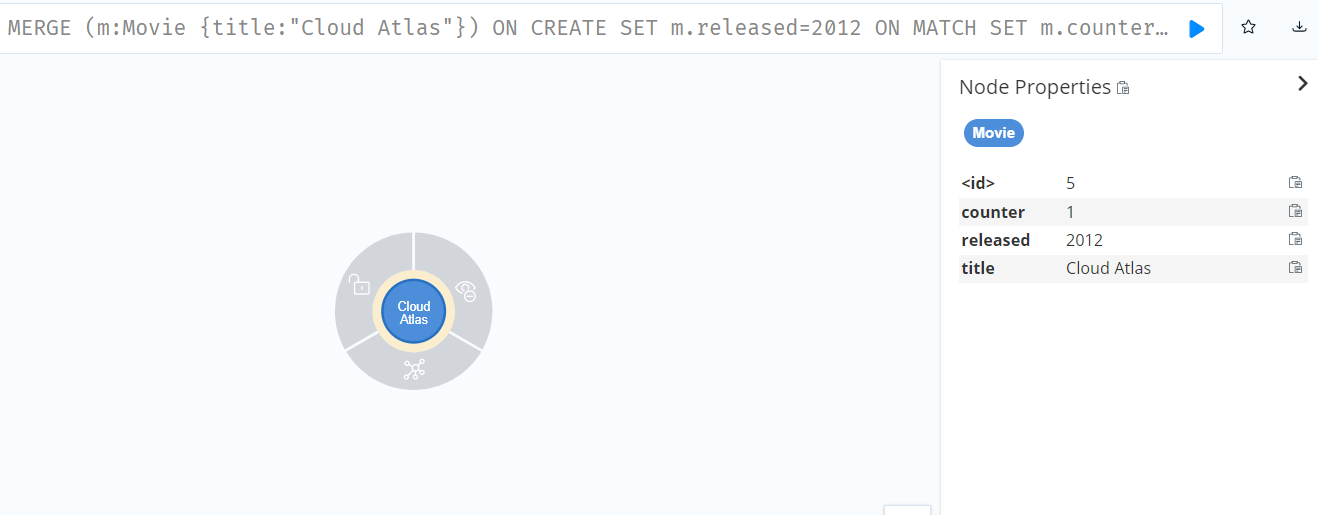
MERGE (m:Movie {title:"Cloud Atlas"})
ON CREATE SET m.released=2012
ON MATCH SET m.counter = coalesce(m.counter,0)+1
RETURN m
// 在两个节点之间查找或新建一个关系
MATCH (a:Person {name:"Peanut"}),(b:Person {name:"Neo4j"})
MERGE (a)-[:LOVES]->(b)
// 如果只传入一个节点,MERGE会查找匹配该模式的另一节点或增加一个节点
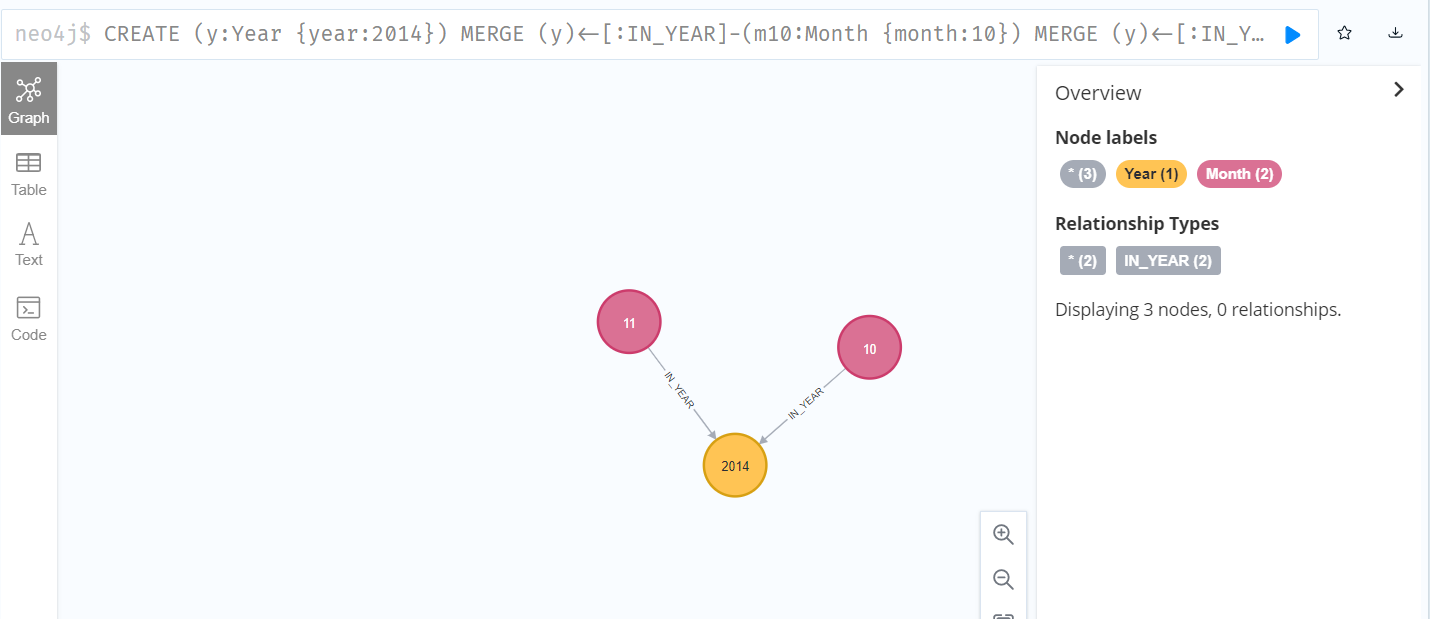
CREATE (y:Year {year:2014})
MERGE (y)<-[:IN_YEAR]-(m10:Month {month:10})
MERGE (y)<-[:IN_YEAR]-(m11:Month {month:11})
RETURN y,m10,m11
//
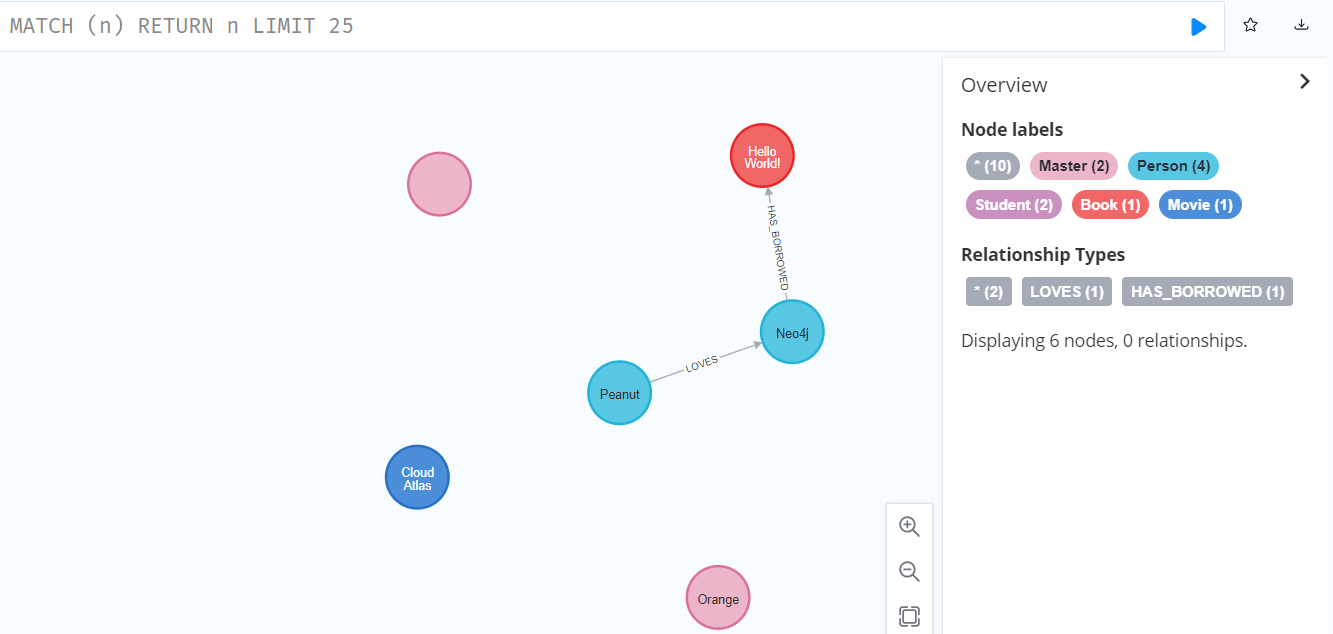
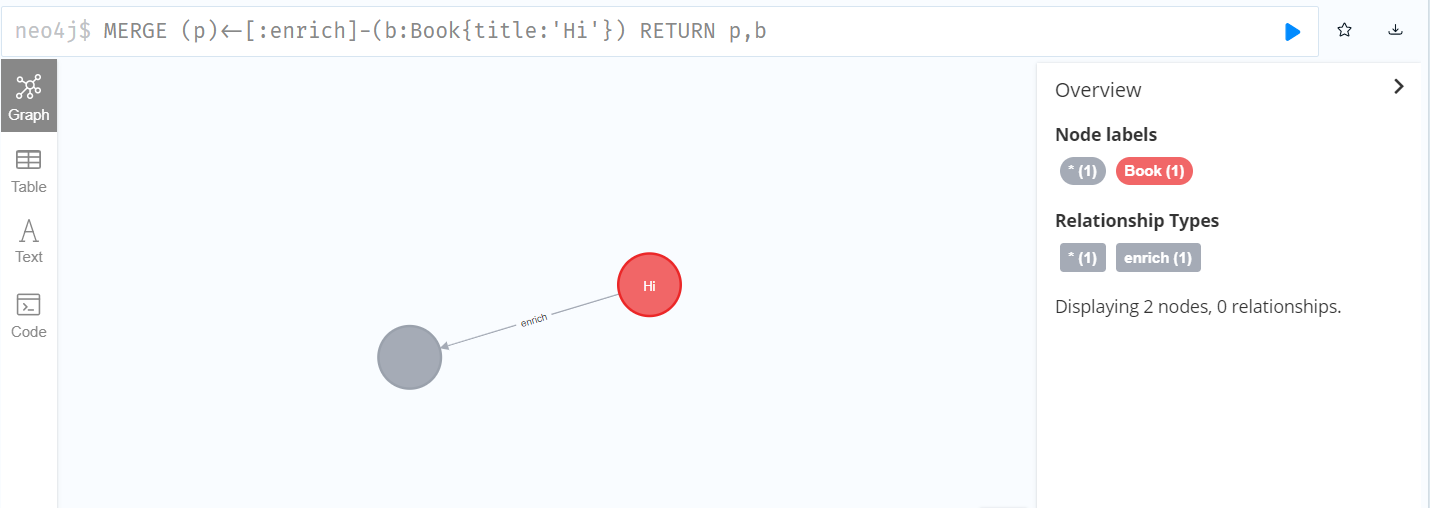
MERGE (p)<-[:enrich]-(b:Book{title:'Hi'})
RETURN p,b
//Merge nodes
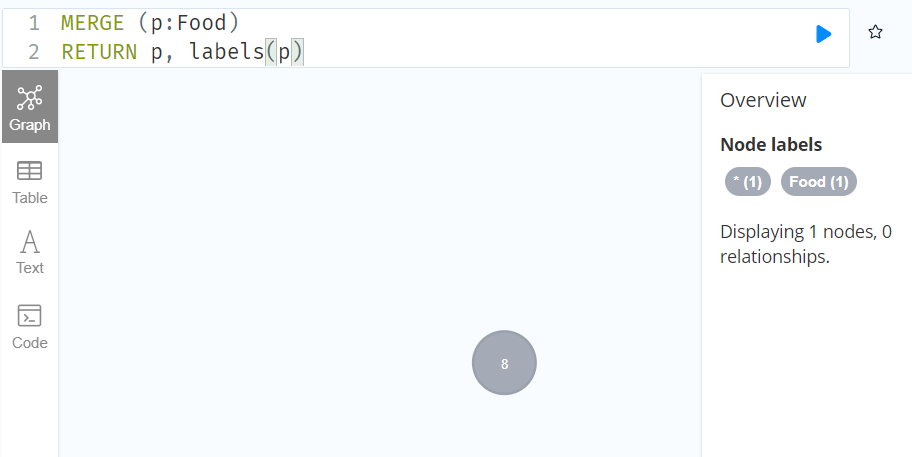
//A new node is created because there are no nodes labeled Food in the database.
MERGE (p:Food)
RETURN p, labels(p)
//Merge single node with properties
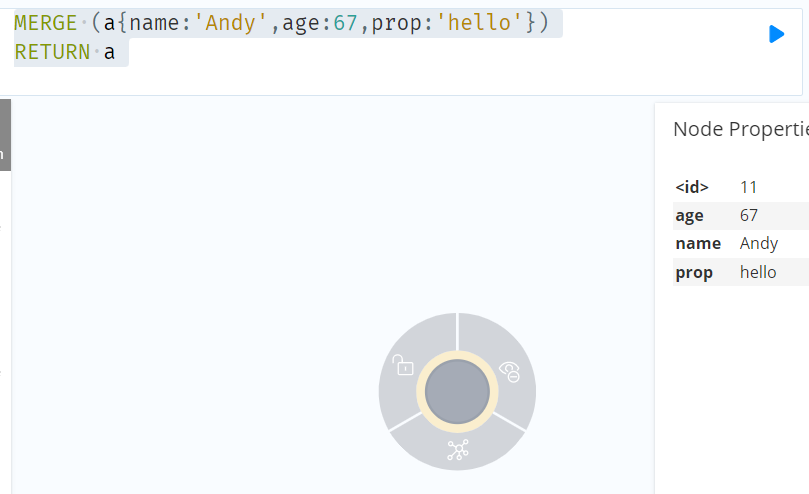
//一个名为“Andy”的新节点将被创建,因为并非所有的性能都与现有的“Andy”节点相匹配。
MERGE (a{name:'Andy',age:67,prop:'hello'})
RETURN a
CREATE (p:Person{name:'Peanut',borrowBook:'Love Study'}),(m:Person{name:'Hello',borrowBook:'Hello World'}),(p)-[:LOVE{since:2022}]->(m) RETURN p,m
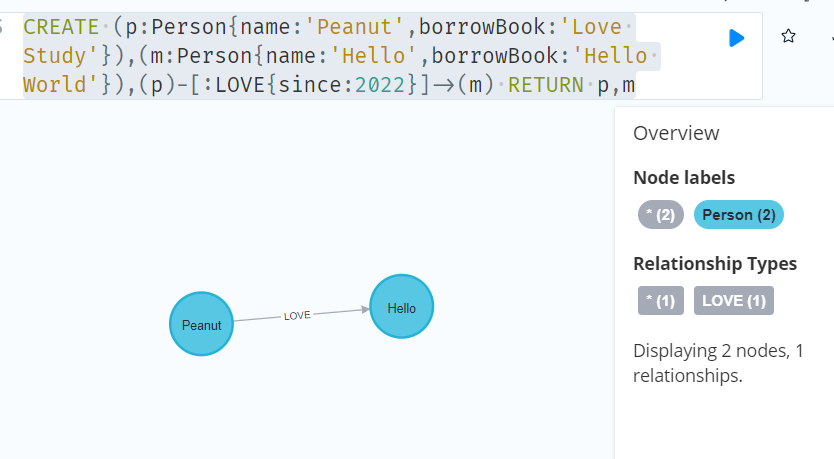
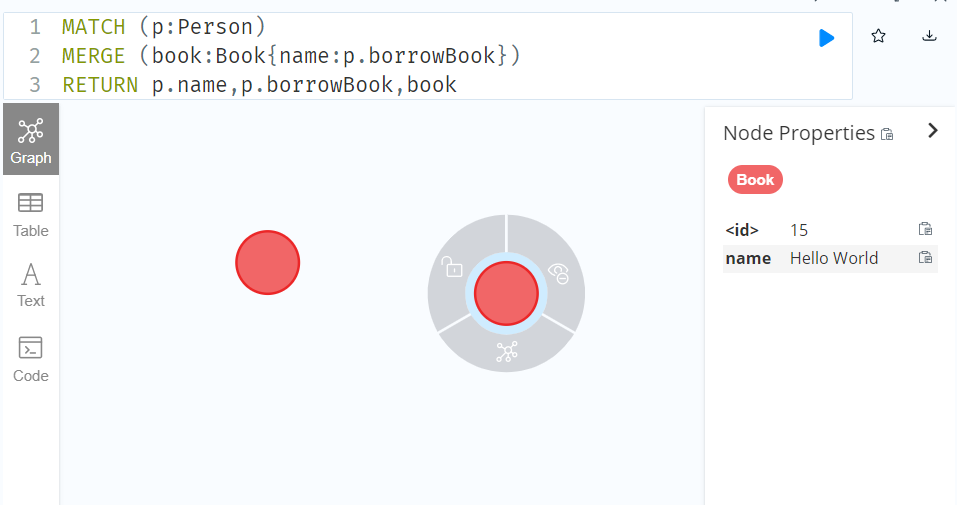
////Merge single node derived from an existing node property
MATCH (p:Person)
MERGE (book:Book{name:p.borrowBook})
RETURN p.name,p.borrowBook,book
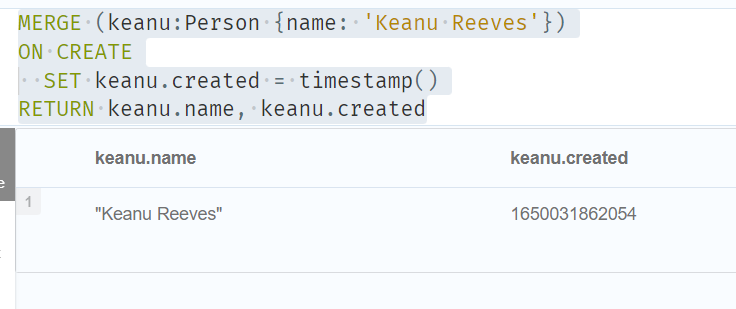
//Merge with ON CREATE
//该查询创建“ keanu”节点并在创建时设置时间戳。
MERGE (keanu:Person {name: 'Keanu Reeves'})
ON CREATE
SET keanu.created = timestamp()
RETURN keanu.name, keanu.created
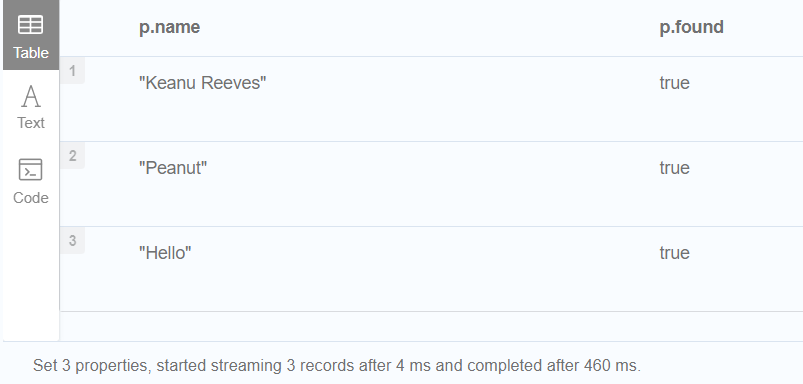
//Merge with ON MATCH
//查询查找所有的 Person 节点,在它们上面设置一个属性,并返回它们。
MERGE (person:Person)
ON MATCH
SET person.found = true
RETURN person.name, person.found
//Merge with ON CREATE and ON MATCH
//该查询创建“ keanu”节点,并在创建时设置时间戳。如果“基努”已经存在,就会设置一个不同的属性。
MERGE (keanu:Person {name: 'Keanu Reeves'})
ON CREATE
SET keanu.created = timestamp()
ON MATCH
SET keanu.lastSeen = timestamp()
RETURN keanu.name, keanu.created, keanu.lastSeen
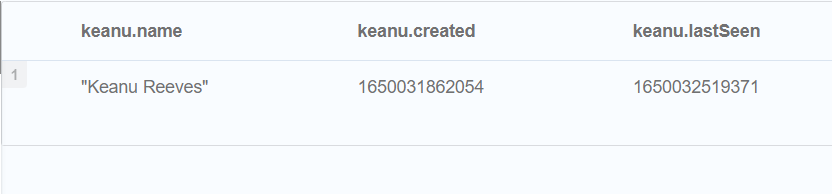
//Merge withON MATCH setting multiple properties
MERGE (p:Person)
ON MATCH
SET
p.found = true,
p.lastAccessed = timestamp()
RETURN p.name, p.found, p.lastAccessed

//Merge on a relationship
MATCH
(p:Person{name:'Peanut'}),
(h:Person{name:'Hello'})
MERGE (p)-[r:LOVE]->(h)
RETURN p.name, type(r), h.name

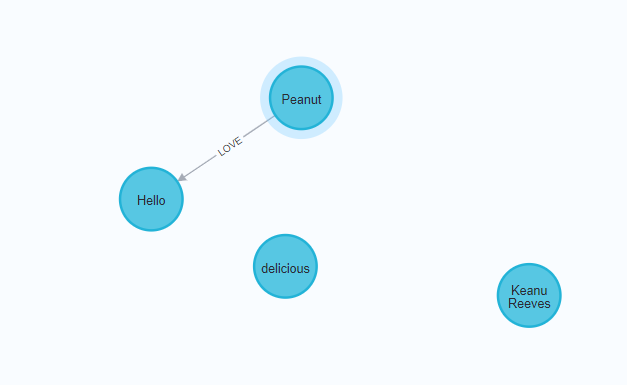
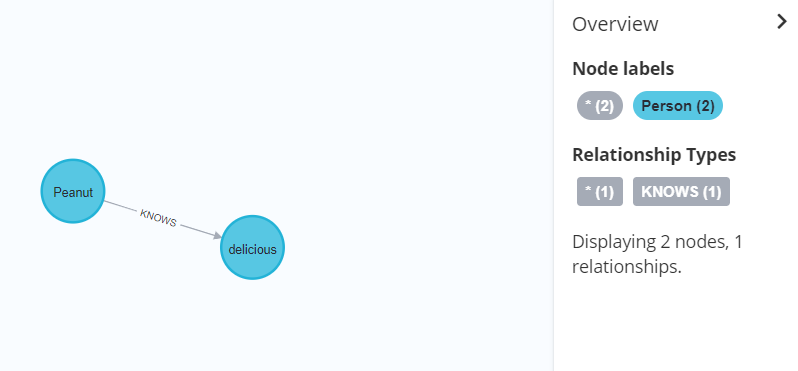
//由于“Peanut”和“delicious”互不认识,这个 MERGE 查询将在他们之间创建一个“知道”关系。创建关系的方向是任意的
MATCH
(p:Person{name:'Peanut'}),(d:Person{name:'delicious'})
MERGE (p)-[r:KNOWS]-(d)
RETURN p,d
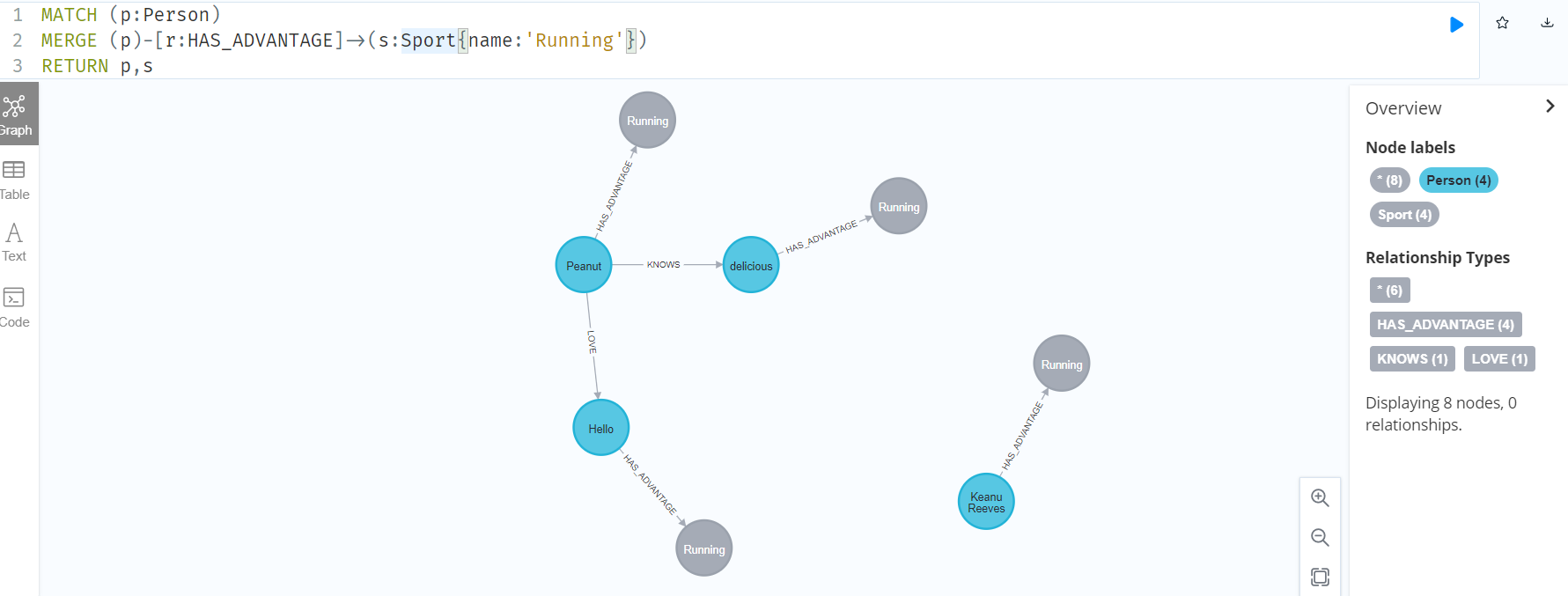
//MERGE 可用于同时创建新节点“ n”和绑定节点“ m”与“ n”之间的关系。
MATCH (p:Person)
MERGE (p)-[r:HAS_ADVANTAGE]->(s:Sport{name:'Running'})
RETURN p,s
//Using unique constraints with MERGE
//请注意,下面的例子假定存在使用以下方法创建的唯一约束:
CREATE CONSTRAINT FOR (n:Person) REQUIRE n.name IS UNIQUE;
//查询创建“ laurence”节点。如果“ laurence”已经存在,那么 MERGE 将匹配现有的节点。
MERGE (laurence:Person {name: 'Laurence Fishburne'})
RETURN laurence.name
4.6.2CALL procedure
YIELD 子子句用于显式选择哪些可用结果字段作为过程调用中新绑定的变量返回给用户,或者由其余查询进行进一步处理。因此,为了能够对显式列使用 YIELD,需要事先知道输出参数的名称(和类型)。
CREATE (a:Person:Child{name:'Alice',age:20}),
(b:Person{name:'Bob',age:27}),
(c:Person:Parent{name:'Charlie',age:65}),
(d:Person{name:'Dora',age:30}),
(a)-[:FRIEND_OF]->(b),
(a)-[:CHILD_OF]->(c)
RETURN a,b,c,d
//Call a procedure using
CALL db.labels()
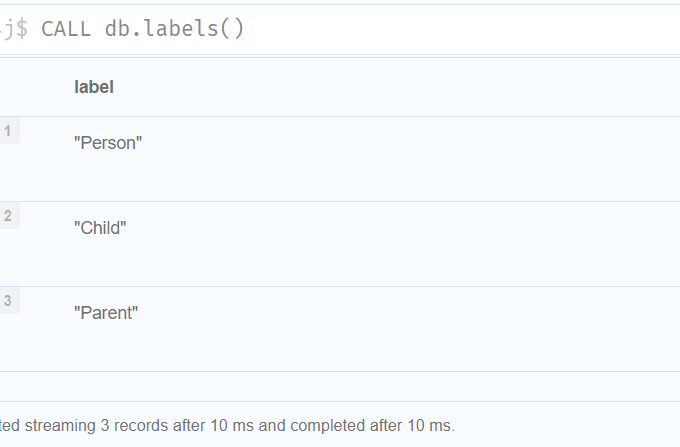
//View the signature for a procedure
CALL dbms.procedures() YIELD name, signature
WHERE name='dbms.listConfig'
RETURN signature
//我们可以看到 dbms.listConfig 有一个输入参数 searchString 和三个输出参数 name、 description 和 value。

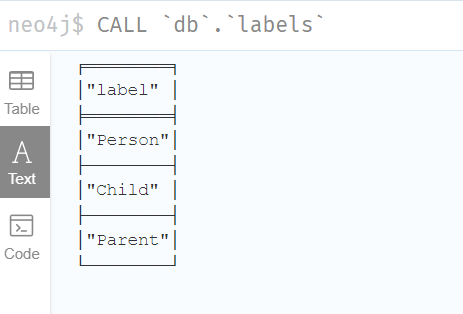
//Call a procedure using a quoted namespace and name 使用带引号的名称空间和名称调用过程
CALL `db`.`labels`
//Call a procedure within a complex query and rename its outputs 在复杂查询中调用过程并重命名其输出
CALL db.propertyKeys() YIELD propertyKey AS prop
MATCH (n)
WHERE n[prop] IS NOT NULL
RETURN prop, count(n) AS numNodes

4.7Set operations
| Clause 条款 | Description 描述 |
|---|---|
UNION联盟 |
Combines the result of multiple queries into a single result set. Duplicates are removed.将多个查询的结果组合到一个结果集中。删除重复项。 |
UNION ALL联合所有 |
Combines the result of multiple queries into a single result set. Duplicates are retained.将多个查询的结果组合到一个结果集中。保留重复值。 |
4.7.1UNION
//Combine two queries and retain duplicates
//使用 UNION ALL 组合两个查询的结果。
MATCH (n:Actor)
RETURN n.name AS name
UNION ALL
MATCH (n:Movie)
RETURN n.title AS name
//The combined result is returned, including duplicates.返回组合结果,包括重复值。
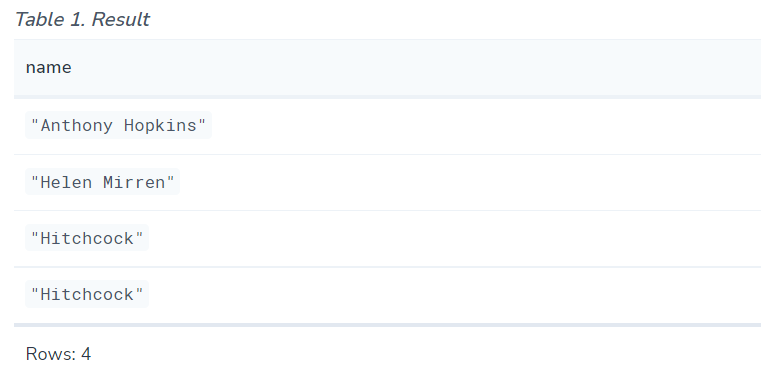
//Combine two queries and remove duplicates
//如果不在 UNION 中包含 ALL,则会从合并的结果集中删除重复项
MATCH (n:Actor)
RETURN n.name AS name
UNION
MATCH (n:Movie)
RETURN n.title AS name
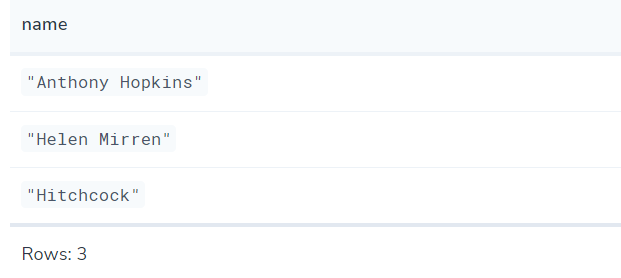
4.8Subquery clauses
| Clause 条款 | Description 描述 |
|---|---|
CALL { ... }1. CALL |
Evaluates a subquery, typically used for post-union processing or aggregations.计算子查询,通常用于联合后处理或聚合。 |
CALL { ... } IN TRANSACTIONS事务中的 CALL |
Evaluates a subquery in separate transactions. Typically used when modifying or importing large amounts of data.在单独的事务中计算子查询。通常用于修改或导入大量数据。 |
4.8.1CALL {} (subquery)
CALL 允许执行子查询,即其他查询中的查询。子查询允许您撰写查询,这在处理 UNION 或聚合时特别有用。
CREATE (a:Person:Child{name:'Alice',age:20}),
(b:Person{name:'Bob',age:27}),
(c:Person:Parent{name:'Charlie',age:65}),
(d:Person{name:'Dora',age:30}),
(a)-[:FRIEND_OF]->(b),
(a)-[:CHILD_OF]->(c)
RETURN a,b,c,d
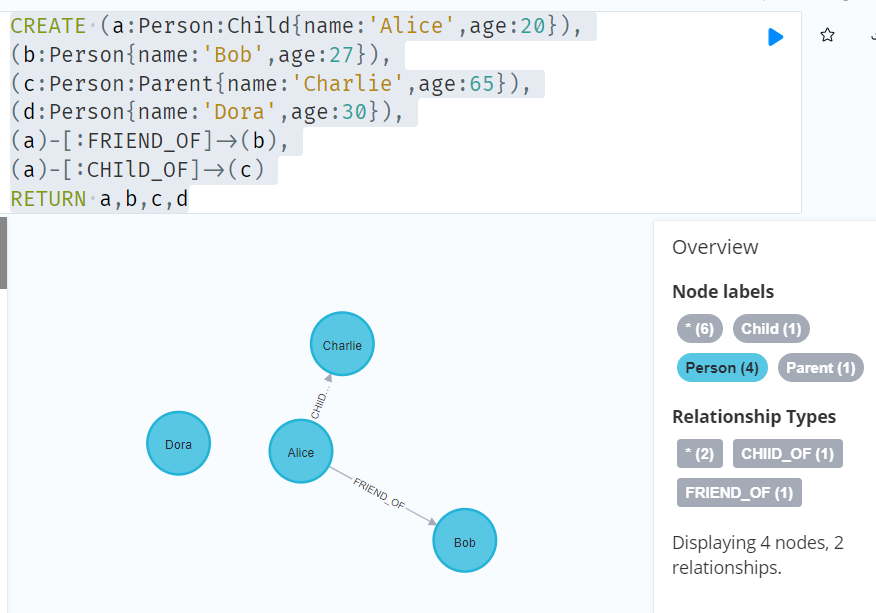
//Importing variables into subqueries
UNWIND [1,2,3] AS x
CALL {
WITH x
RETURN x * 10 AS y
}
RETURN x, y
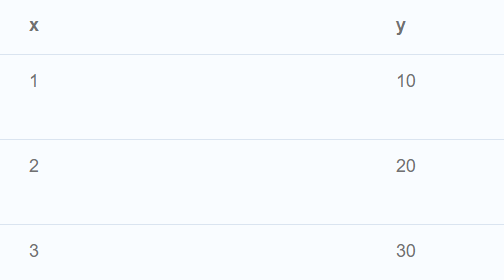
//Post-union processing
//子查询可用于进一步处理 UNION 查询的结果。此查询示例查找数据库中最年轻和最年长的人,并按名称对他们进行排序。
CALL {
MATCH (p:Person)
RETURN p
ORDER BY p.age ASC
LIMIT 1
UNION
MATCH (p:Person)
RETURN p
ORDER BY p.age DESC
LIMIT 1
}
RETURN p.name, p.age
ORDER BY p.name
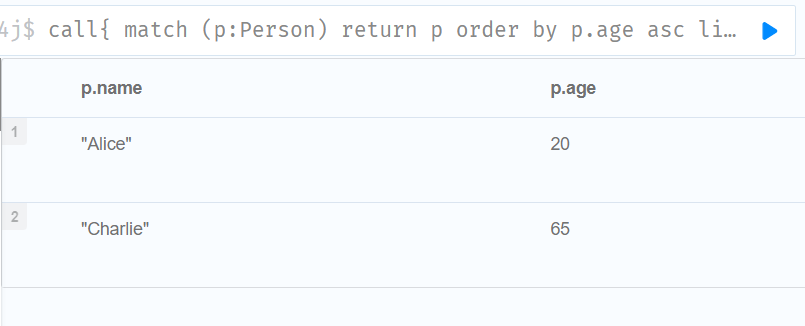
//如果没有找到匹配项,OPTIONAL MATCH 将对模式中缺少的部分使用 null。
MATCH (p:Person)
CALL {
WITH p
OPTIONAL MATCH (p)-[:FRIEND_OF]->(other:Person)
RETURN other
UNION
WITH p
OPTIONAL MATCH (p)-[:CHILD_OF]->(other:Parent)
RETURN other
}
RETURN DISTINCT p.name, count(other)
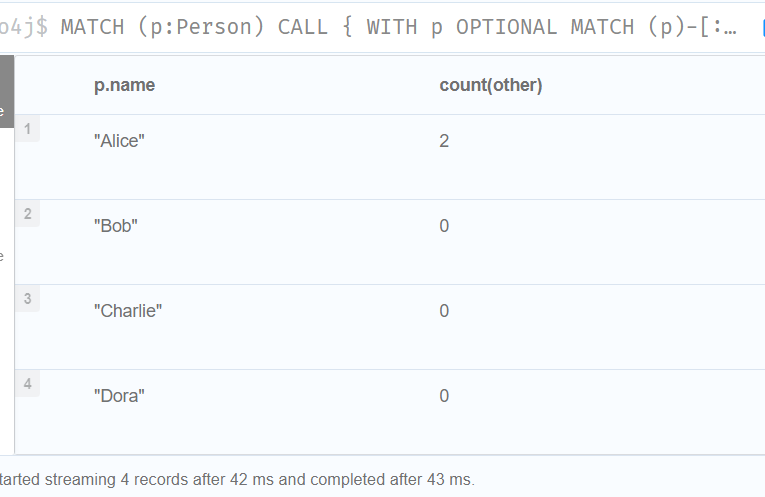
//我们还可以使用子查询来执行隔离聚合
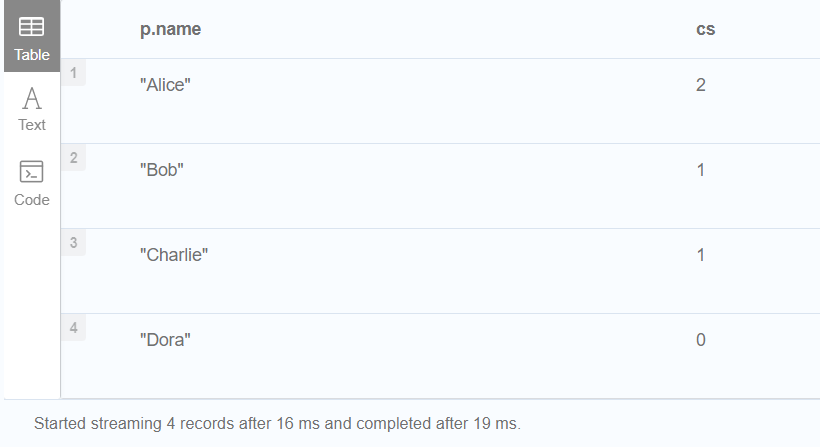
MATCH (p:Person)
CALL {
WITH p
MATCH (p)--(c)
RETURN count(c) AS cs
}
RETURN p.name, cs
//Unit subqueries and side-effects
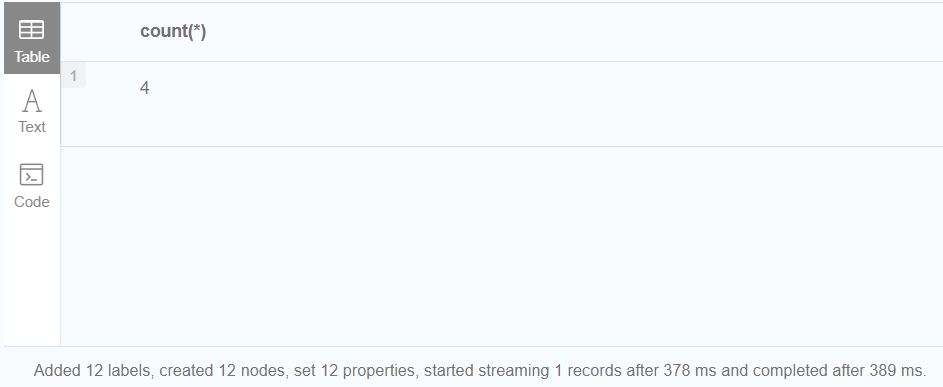
//此查询示例创建每个现有人的五个克隆。由于子查询是一个单元子查询,因此它不会更改所包含查询的行数
MATCH (p:Person)
CALL {
WITH p
UNWIND range (1, 5) AS i
CREATE (:Person {name: p.name})
}
RETURN count(*)
//Errors
//在下面的示例中,第二个内部事务中的最后一个子查询执行失败,原因是被零除。
UNWIND [4, 2, 1, 0] AS i
CALL {
WITH i
CREATE (:Example {num: 100/i})
} IN TRANSACTIONS OF 2 ROWS
RETURN i
//发生故障时,第一个事务已经提交,因此数据库包含两个示例节点
4.9Multiple graphs
| Clause 条款 | Description 描述 |
|---|---|
USE使用 |
Determines which graph a query, or query part, is executed against.确定对查询或查询部分执行的图形。 |
4.9.1USE
USE 子句确定针对哪个图执行查询或查询部分。它支持查询和模式命令。
4.10Importing data
| Clause 条款 | Description 描述 |
|---|---|
LOAD CSV |
Use when importing data from CSV files.从 CSV 文件导入数据时使用。 |
--- USING PERIODIC COMMIT——使用 PERIODIC COMMIT |
This query hint may be used to prevent an out-of-memory error from occurring when importing large amounts of data using LOAD CSV.此查询提示可用于防止在使用 loadcsv 导入大量数据时发生内存不足错误。 |
4.10.1LOAD CSV
Loadcsv 用于从 CSV 文件导入数据。
1.CSV file format
-
the character encoding is UTF-8;
字符编码是 UTF-8;
-
the end line termination is system dependent, e.g., it is
\non unix or\r\non windows;结束行终止是系统相关的,例如,它在 unix 上是 n,在 windows 上是 rn;
-
the default field terminator is
,;默认的字段终结符是,;
-
the field terminator character can be change by using the option
FIELDTERMINATORavailable in theLOAD CSVcommand;可以使用 loadcsv 命令中的 FIELDTERMINATOR 选项更改字段终止符;
-
quoted strings are allowed in the CSV file and the quotes are dropped when reading the data;
在 CSV 文件中允许使用带引号的字符串,并且在读取数据时删除引号;
-
the character for string quotation is double quote
";字符串引号的字符是双引号”;
-
if
dbms.import.csv.legacy_quote_escapingis set to the default value oftrue,\is used as an escape character;如果 dbms.import.csv.legacy _ quote _ escaping 设置为缺省值 true,则用作转义字符;
-
a double quote must be in a quoted string and escaped, either with the escape character or a second double quote.
双引号必须位于带引号的字符串中,并用转义符或第二个双引号进行转义。
2.Import data from a CSV file

1,ABBA,1992
2,Roxette,1986
3,Europe,1979
4,The Cardigans,1992
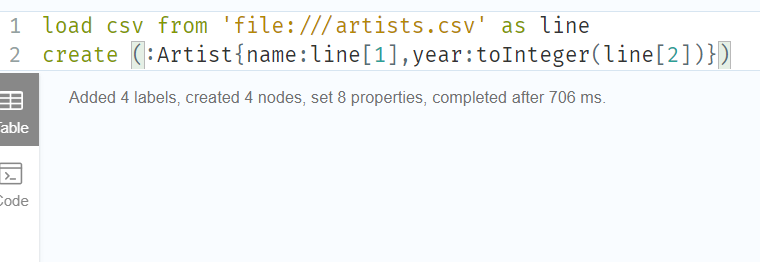
LOAD CSV FROM 'file:///artists.csv' AS line
CREATE (:Artist {name: line[1], year: toInteger(line[2])})
3.Import data from a CSV file containing headers
Id,Name,Year
1,ABBA,1992
2,Roxette,1986
3,Europe,1979
4,The Cardigans,1992
//该文件从包含列名的单行开始。使用 withheaders 表示这一点,您可以通过相应的列名访问特定的字段。
LOAD CSV WITH HEADERS FROM 'file:///artists.csv' AS line
CREATE (:Artist {name: line.Name, year: toInteger(line.Year)})
4.Import data from a CSV file with a custom field delimiter
LOAD CSV FROM 'file:///artists-fieldterminator.csv' AS line FIELDTERMINATOR ';'
CREATE (:Artist {name: line[1], year: toInteger(line[2])})
5.Importing large amounts of data
USING PERIODIC COMMIT LOAD CSV FROM 'file:///artists.csv' AS line
CREATE (:Artist {name: line[1], year: toInteger(line[2])})
6.Setting the rate of periodic commits
USING PERIODIC COMMIT 500 LOAD CSV FROM 'file:///artists.csv' AS line
CREATE (:Artist {name: line[1], year: toInteger(line[2])})
4.11Listing functions and procedures
| Clause 条款 | Description 描述 |
|---|---|
SHOW FUNCTIONS显示函数 |
List the available functions.列出可用的功能。 |
SHOW PROCEDURES展示程序 |
List the available procedures.列出可用的程序。 |
4.11.1SHOW FUNCTIONS
SHOW FUNCTIONS EXECUTABLE BY CURRENT USER YIELD *
4.12Transaction Commands
| Clause 条款 | Description 描述 |
|---|---|
SHOW TRANSACTIONS显示交易 |
List the available transactions.列出可用的事务。 |
TERMINATE TRANSACTIONS终止交易 |
Terminate transactions by their IDs.通过事务的 id 终止事务。 |
4.13Administration clauses
These comprise clauses used to manage databases, schema and security; further details can found in Database management and Access control.
这些子句用于管理数据库、模式和安全性; 进一步的细节可以在数据库管理和访问控制中找到。
| Clause 条款 | Description 描述 |
|---|---|
| `CREATE | DROP |
| `CREATE | DROP INDEX`创建 | 删除索引 |
| `CREATE | DROP CONSTRAINT`创建 | 删除约束 |
| Access control访问控制 | Manage users, roles, and privileges for database, graph and sub-graph access control.管理数据库、图形和子图形访问控制的用户、角色和特权。 |
5.函数
https://neo4j.com/docs/cypher-manual/current/functions/#header-query-functions-predicate
6.索引
6.1Create a single-property b-tree index for nodes
为节点创建一个单属性 b 树索引
CREATE INDEX node_index_name FOR (n:Person) ON (n.surname)
//Note that the index name must be unique.
6.2Create a single-property b-tree index for relationships
CREATE INDEX rel_index_name FOR ()-[r:KNOWS]-() ON (r.since)
6.3 Create a single-property b-tree index only if it does not already exist
CREATE INDEX node_index_name IF NOT EXISTS FOR (n:Person) ON (n.surname)
//请注意,如果已经存在具有相同架构和类型、相同名称或两者兼有的索引,则不会创建索引。
6.4 Create a composite b-tree index for nodes
CREATE INDEX node_index_name FOR (n:Person) ON (n.age, n.country)
6.5Listing indexs
SHOW INDEXES
6.6Deleting indexes
DROP INDEX index_name
//Drop a non-existing index
DROP INDEX missing_index_name IF EXISTS
7.Full-text search index
全文索引由 Apache Lucene 索引和搜索库提供,可以通过字符串属性索引节点和关系。全文索引允许您编写与索引字符串属性内容匹配的查询。例如,前面几节中描述的 b 树索引只能对字符串进行精确匹配或前缀匹配。全文索引将转而标记已索引的字符串值,以便它可以匹配字符串中的任何位置.
CREATE (m:Movie {title: "The Matrix"}) RETURN m.title
//我们还有一个关于电影和书籍的标题和描述属性的全文索引。
CREATE FULLTEXT INDEX titlesAndDescriptions FOR (n:Movie|Book) ON EACH [n.title, n.description]
//Query full-text indexes 查询全文索引
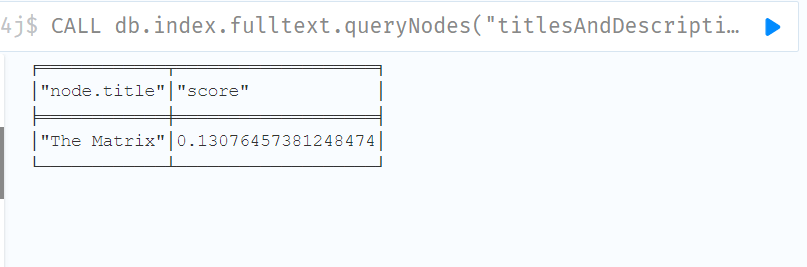
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", "the") YIELD node, score
RETURN node.title, score
8.neo4j连接MySQL数据库
- 下载配置APOC、mysql-connector-java。
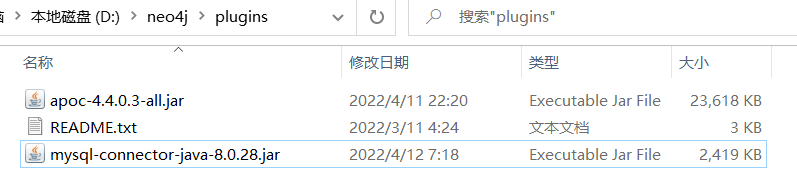
- 将jar包放在plugins目录下
- 配置neo4j使其能够使用APOC

用记事本打开,搜索dbms.security.prodedures,修改如下

- 启动Neo4j,验证
Enter in the neo4j browsercall
return apoc.version()
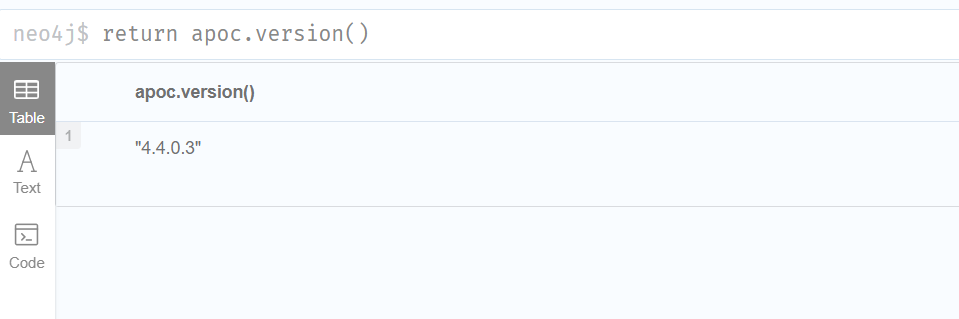
- 启动mysql服务,连接表student
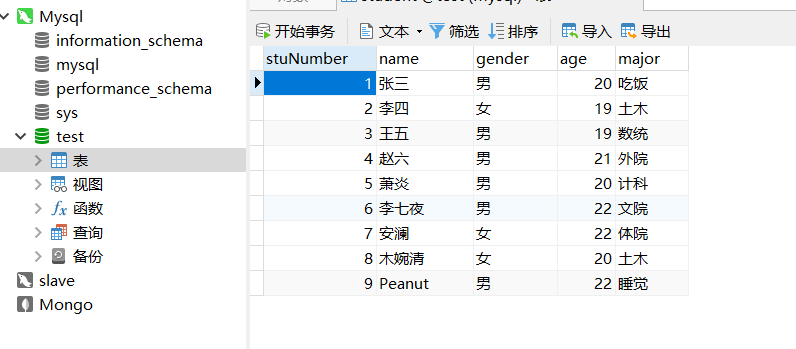
//删除原始数据
match (n) detach delete n
CALL apoc.periodic.iterate(
'CALL apoc.load.jdbc("jdbc:mysql://localhost:3306/test?user=root&password=123456","select * from student") YIELD row ',
'CREATE (s:Student) SET s =row',
{ batchSize:10000, parallel:true}
)
8.1小栗子
1.创建标签为Person的节点
CALL apoc.periodic.iterate(
'CALL apoc.load.jdbc("jdbc:mysql://localhost:3306/test?user=root&password=123456","select * from person_node") YIELD row',
'CREATE (p:Person) set p = row',
{ batchSize:10000, parallel:true}
)
2.创建标签为Book的节点
CALL apoc.periodic.iterate(
'CALL apoc.load.jdbc("jdbc:mysql://localhost:3306/test?user=root&password=123456","select * from book_node") YIELD row',
'CREATE (b:Book) set b = row',
{ batchSize:10000, parallel:true}
)
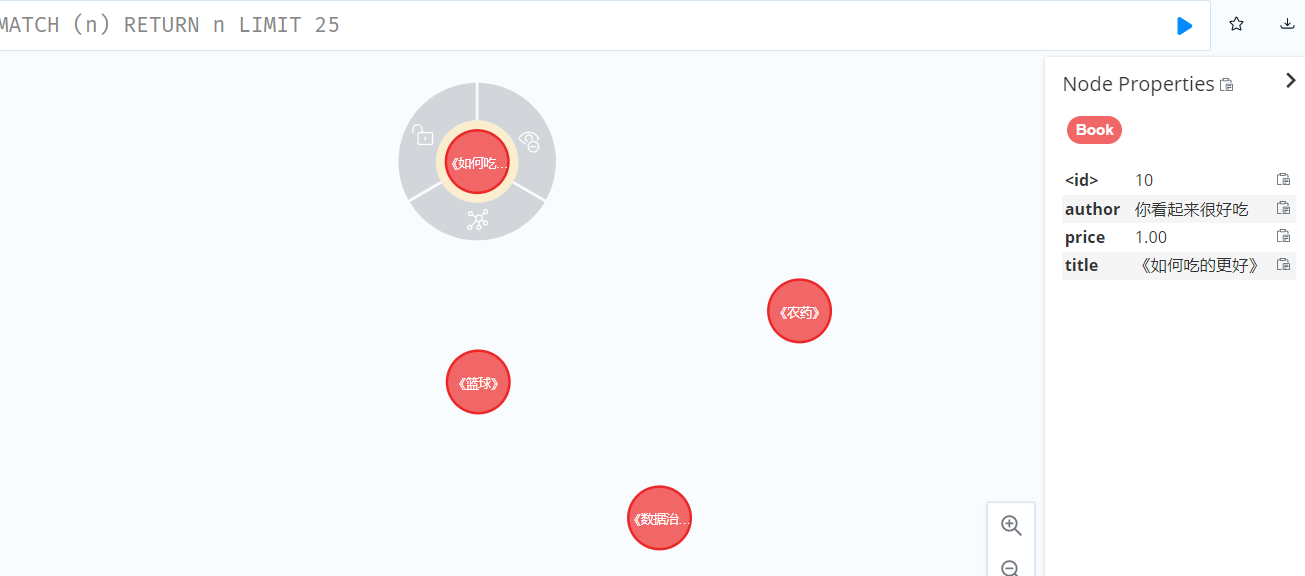
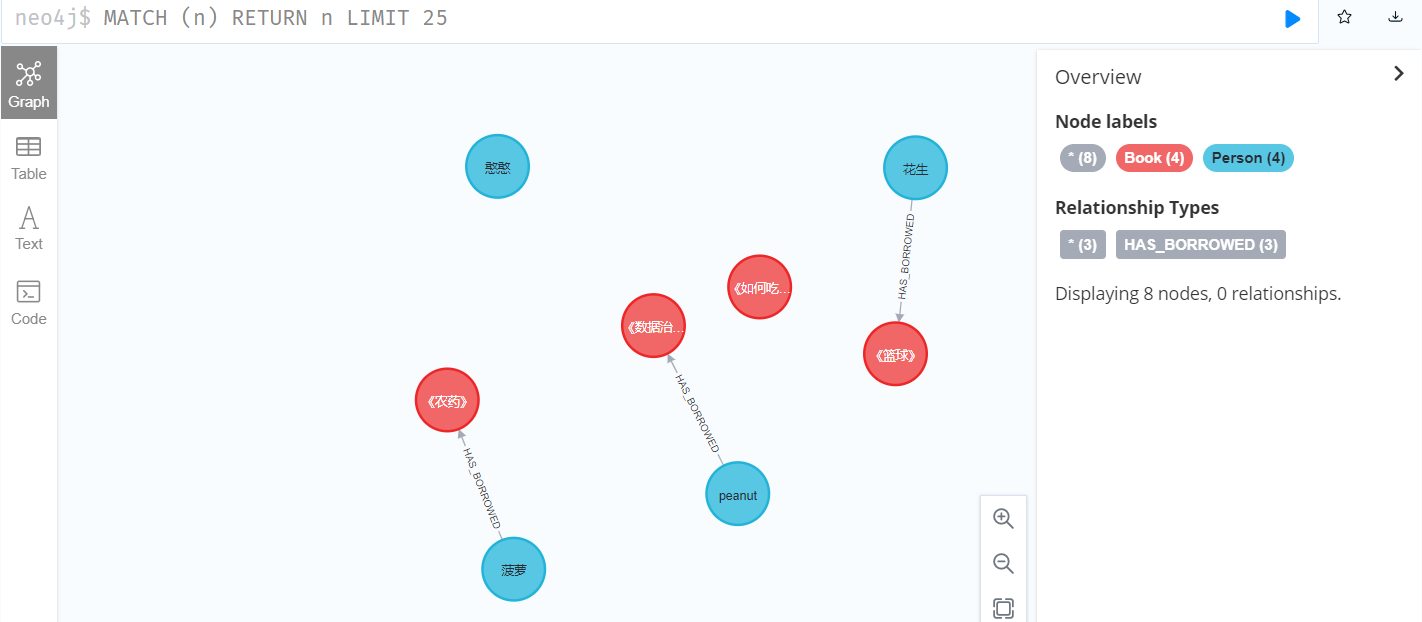
3.创建人和书的关系
MATCH (n:Person),(m:Book)
WHERE n.borrowBook = m.title
MERGE (n)-[:HAS_BORROWED]->(m)
9.参考资料
[1]佚名. (11条消息) Neo4j中导入RDF数据_爱摸鱼的ZZ的博客-CSDN博客_neo4j导入rdf[EB/OL].[2022–04–14].https://blog.csdn.net/weixin_43797818/article/details/114853434.
[2]佚名. (11条消息) OWL/RDF导入neo4j前缀消除,踩坑总结_yaminne的博客-CSDN博客[EB/OL].[2022–04–14].https://blog.csdn.net/yaminne/article/details/118768139.
[3]佚名. Introduction — Owlready2 0.36 documentation[EB/OL].[2022–04–14].https://owlready2.readthedocs.io/en/v0.37/intro.html.
[4]佚名. (11条消息) 知识图谱的基础知识_a堅強的泡沫的博客-CSDN博客[EB/OL].[2022–04–14].https://blog.csdn.net/weixin_43973415/article/details/123086248?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164983362216780271532047%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164983362216780271532047&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~times_rank-3-123086248.nonecase&utm_term=owl%E5%8F%91%E5%B8%83#5_MySQLRDF_600.
[5]佚名. Maven Repository: org.neo4j » neosemantics » 4.4.0.1[EB/OL].[2022–04–14].https://mvnrepository.com/artifact/org.neo4j/neosemantics/4.4.0.1.
[6]佚名. APOC User Guide 4.4 - APOC Documentation[EB/OL].[2022–04–12].https://neo4j.com/labs/apoc/4.4/.
[7]佚名. Home | Neo4j Bolt Driver 4.4 for JavaScript[EB/OL].[2022–04–12].https://neo4j.com/docs/api/javascript-driver/current/.
[8]佚名. InteractiveGraph[M]. grapheco, 2022.
[9]佚名. Py2neo[M]. py2neo.org, 2022.
[10]佚名. Maven Repository: mysql » mysql-connector-java[EB/OL].[2022–04–12].https://mvnrepository.com/artifact/mysql/mysql-connector-java.
[11]佚名. Use the APOC plug-in of neo4j to extract data from Mysql to neo4j | Develop Paper[EB/OL].[2022–04–12].https://developpaper.com/use-the-apoc-plug-in-of-neo4j-to-extract-data-from-mysql-to-neo4j/.
[12]佚名. (11条消息) Neo4j:入门基础(三)之APOC插件_Dawn_www的博客-CSDN博客_apoc neo4j[EB/OL].[2022–04–11].https://blog.csdn.net/sinat_36226553/article/details/108569048.
[13]佚名. Atom_notebook/07-09_neo4j.md at master · leondgarse/Atom_notebook · GitHub[EB/OL].[2022–04–10].https://github.com/leondgarse/Atom_notebook/blob/master/public/2018/07-09_neo4j.md.
[14]佚名. 5分钟了解OWL本体建模语言 - zhongzh - 博客园[EB/OL].[2022–04–10].https://www.cnblogs.com/zhongzihao/p/11328020.html.
[15]佚名. OWL本体语言学习笔记 | C_Meng PSNA[EB/OL].[2022–04–10].https://imonce.github.io/2019/03/18/owl本体语言学习笔记/.
[16]佚名. Neo4j基础入门 - 星朝 - 博客园[EB/OL].[2022–04–10].https://www.cnblogs.com/jpfss/p/11474190.html.
[17]佚名. neo4j基础入门教程 - 易水风萧[EB/OL].[2022–04–10].http://www.yishuifengxiao.com/2021/11/03/neo4j基础入门教程/.
[18]佚名. Neo4j Cypher Refcard 4.4[EB/OL].[2022–04–08].https://neo4j.com/docs/cypher-refcard/current/.
[19]佚名. The Neo4j Cypher Manual v4.4 - Neo4j Cypher Manual[EB/OL].[2022–04–08].https://neo4j.com/docs/cypher-manual/current/.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号