使用encoder编码器-decoder解码器加GAN网络的生成式图像修复
论文链接
https://openaccess.thecvf.com/content_cvpr_2016/papers/Pathak_Context_Encoders_Feature_CVPR_2016_paper.pdf
简介
作者提出了一种基于上下文像素预测的无监督视觉特征学习算法,它既完成了特征提取,也完成了图像修复。
通过与自动编码器的类比,提出了上下文编码器(Context encoders),这是一种经过训练的卷积神经网络,可以根据周围环境生成任意图像区域的内容,也就是遮挡部分的内容。
为了成功完成这项任务,上下文编码器既需要理解整个图像的内容,也需要为缺失的部分生成一个合理的假设分布。
这篇论文结合了Encoder-Decoder网络结构和GAN网络,AlexNet网络和一些卷积神经网络,E-D阶段用于学习图像特征生成待修补区域对应的预测图,使用GAN对抗学习来优化模型。
网络结构1---Encoder-Decoder
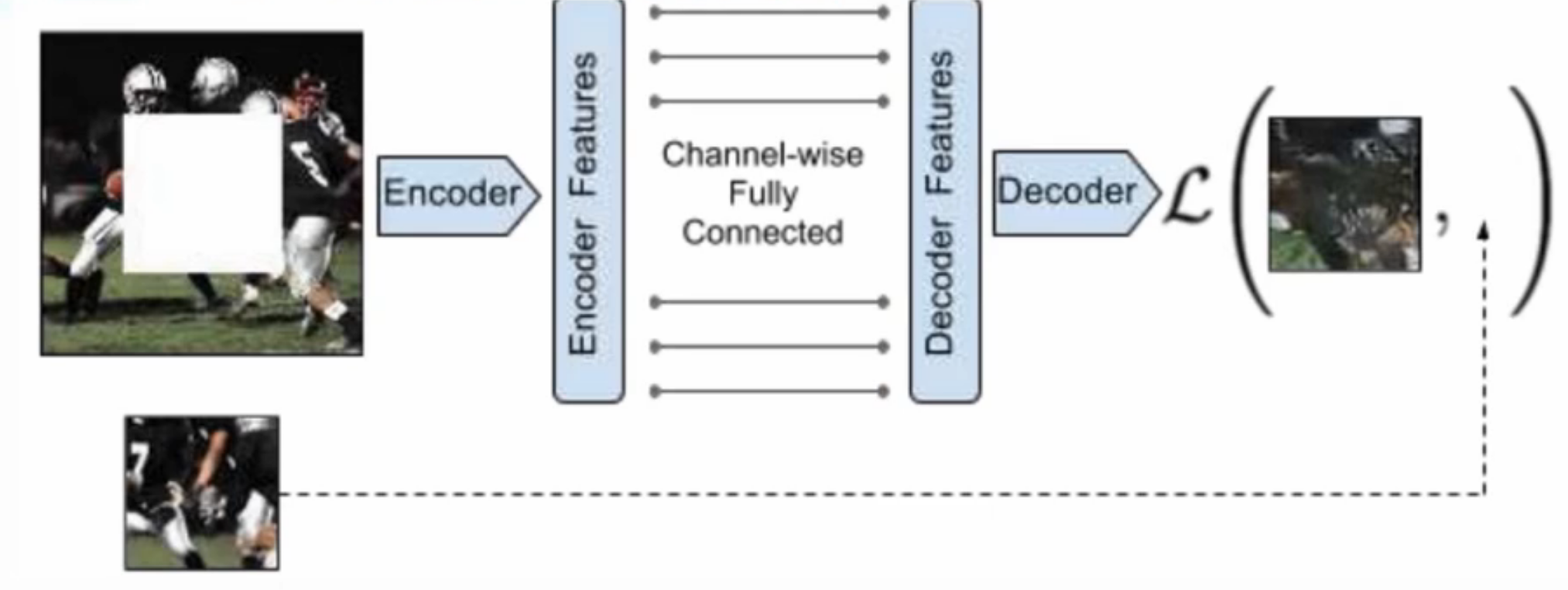
上下文编码器作为生成网络。通过编码器传递上下文图像,以获得使用全通道连接层连接到解码器的特征,随后解码器产生图像中缺失的区域。
此处的Channel-wise Fully Connected全通道连接层使得解码器中的每个单元可以对整个图像内容进行推理去解码,如果仅仅只使用全连接层而不是使用Channel-wise Fully Connected层来代替它的话会导致参数爆炸。
上述流程图产生的是缺失部分。
如果使用AlexNet网络进行特征提取、修复,它使用的也是编码器,解码器,但它解码生成的是原始尺寸大小的。
网络结构2---Encoder
其中一个编码器结构就是源自于AlexNet结构,但不是为了Imagenet分类而训练的,而是用随机初始化的权重重新为上下文预测而训练的网络,也就是为了我们的提取特征进行解码而训练的编码器AlexNet结构。
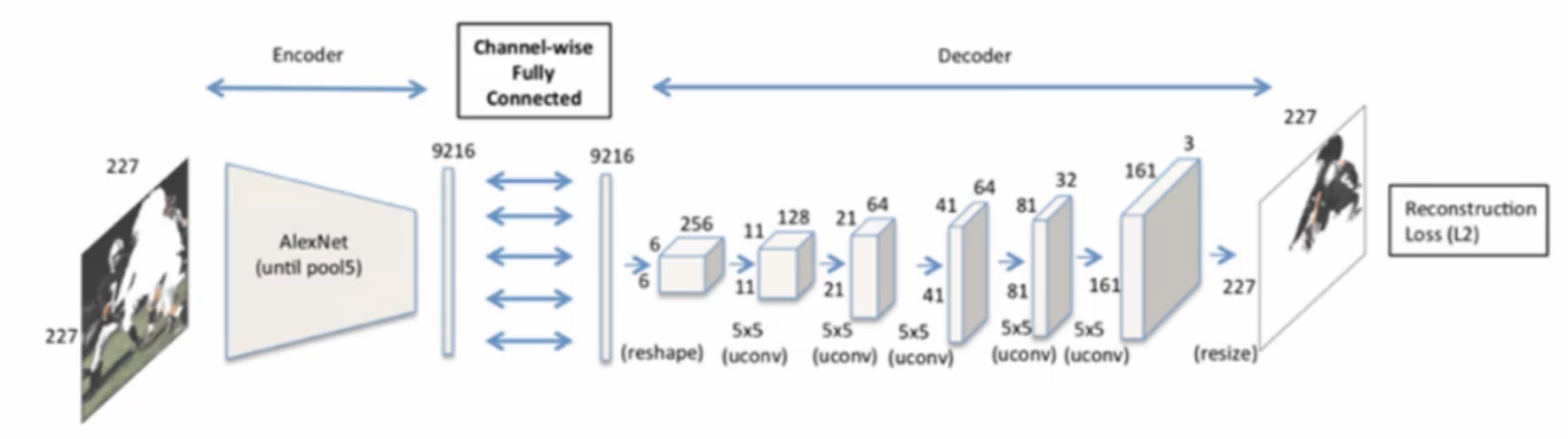
Encoder:我们使用的是pool5,也就是第五层卷积层之后的那一层池化层之前的所有内容,(AlexNet是由5层卷积层+3层池化层构成的,pool5表示为最后一层池化层对应的第五层卷积层,因此叫做pool5,也就是处在第五层卷积的池化层,即全连接层之前的那个AlexNet架构,把他提取出来使用到我们的编码器里,然后再经过全通道连接层连接我们的解码器,使用解码器+上采样把他生成到和原始图一样的尺寸的内容。)
网络结构3---Channel-wise fully connected layer
全通道连接层是对普通全连接层fc的一种改进,传统的fc层参数太多,因此作者提出可以在fc中去掉feature map层间的信息交流,从而减少参数规模,在fc之后会接一个步长stride为1的卷积层,来实现层间的信息交流,从而达到参数规模的效果。
网络结构4---Decoder
使用编码器产生的特征生成像素图像,然后在全通道连接层之后设置5个具有学习能力的filter的up-conv层,每一层都使用ReLu激活,产生解码,产生我们想要的图像。
损失函数1---Reconstruction Loss(重建loss)
使用的是MSE(L2)的损失函数,捕获缺失区域的整体结构,让重建结果与周围的信息一致。

M:代表遮挡矩阵,表示只去计算遮挡部分的损失,里面是由1和0构成的,1代表被遮挡,0代表不被遮挡
x:代表原始的输入图,即原始没有破损的那个输入图
![]() :代表逐元素相乘
:代表逐元素相乘
1-M代表遮挡部分置为0,去乘以x我们的原始图,说明我们被遮挡的部分就被置成了空白图像,因为rgb三通道的彩图之后,被设置为0就代表着白色,然后1-M代表我们需要遮挡部分置为0,其余部分置为1,那么不被遮挡的部分就不变,被遮挡的部分被置为0,那就说明对x已经作用到了
![]() :代表原始图像减去遮挡部分,即被遮挡图形,不完整的图形
:代表原始图像减去遮挡部分,即被遮挡图形,不完整的图形
F:代表使用遮挡之后的原始图生成的图像,就是作用在被遮挡图像,通过编码器、解码器进行还原原始图的那个过程,它生成了一张修复图像,那么我们的重建损失就建立在正确的图减去我们修复好的图,如果我们的原始图x和我们修复的图一样,就是修复达到了原始图一样的效果,那么我们的损失函数就达到了0,把损失函数降到了最低,即达到了最优的效果
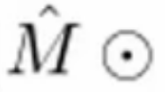 :代表我们只关注遮挡部分的损失,只去计算遮挡部分的损失,那么总的损失函数就表示了我们生成的原始图像被遮挡了送入进去生成了修复后的图像,然后就只计算遮挡部分的原图和生成图之间的损失,即MSE(L2)的损失函数。
:代表我们只关注遮挡部分的损失,只去计算遮挡部分的损失,那么总的损失函数就表示了我们生成的原始图像被遮挡了送入进去生成了修复后的图像,然后就只计算遮挡部分的原图和生成图之间的损失,即MSE(L2)的损失函数。
如下是重建损失的网络结构图:
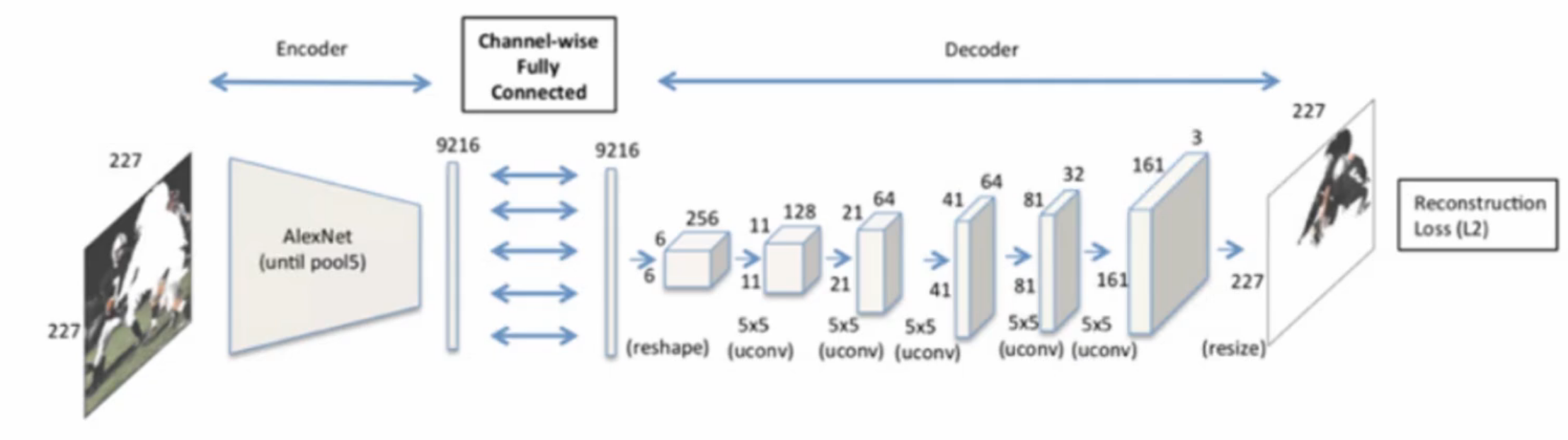
使用AlexNet架构作为编码器时,去认识重建损失,通过上图进行解析,左图的遮挡后的输入图像经过我们的编码器和解码器,也就是F作用,生成了修复后的遮挡内容,然后用x原始图与之作比较,比较只是遮挡部分的区域损失,当这个损失值达到最小时,达到最优,至此损失函数就可以理解到位了。
使用AlexNet架构作为编码器时,作者们没有能使对抗损失与AlexNet收敛,因此在这个过程当中只使用了重建损失进行不规则的区域修复以及不规则的特征提取。
损失函数2---Adversarial Loss(对抗loss)
对抗损失是基于GAN结构的,为了学习一个数据分布的G生成模型。
GAN网络的损失函数:
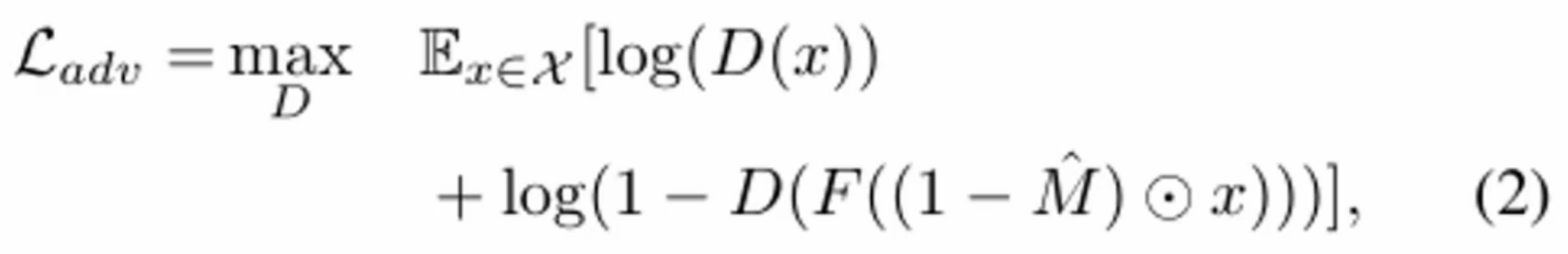
生成器与判别器都是使用交替的SGD优化器优化的:这里的D和F(生成模型)都是使用交替的SGD优化器优化的,F就是我们的编码器、解码器结构。
最终就由我们的对抗损失和重建损失产生了联合损失:
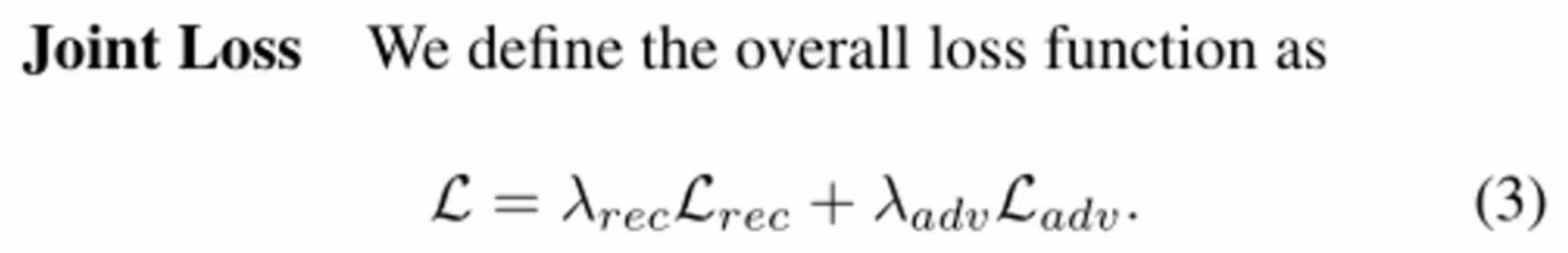
损失函数2---Joint Loss(联合loss)---规则图像,不用AlexNet作为编码器的一个网络结构

此时的输入就不是AlexNet的输入大小了,而是128*128像素的一张图像(遮挡的图片),它经过编码器编码,进行提取特征,然后解码生成的不是同像素大小的图片了,而是生成一张只有遮挡部分大小的图片。
输入:被遮挡的图片
输出:被遮挡部分的图片
右上方产生了一个重建损失的函数,希望我们生成的遮挡部分的图片和我们被遮挡的图片尽可能是一样的,它们尽可能一样的时候损失函数降到最小,这个过程就是求损失函数最小的情况;结合对抗训练过程,此时我们就把真实的被遮挡的64*64部分的图作为真实输入输入进判别器网络,然后再把我们生成器生成的虚假的这个被遮挡的图片也送入判别器网络进行判别,然后去对抗训练判别器网络,不断更新判别器网络以及我们的生成器网络,通过什么去更新呢,就是通过我们的对抗损失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号