深度学习目标检测
一、发展历程:

二、基于传统机器学习的目标检测方式:
在梳理深度学习目标检测前,个人还是喜欢首先梳理一下传统机器学习的目标检测方式,因为深度学习的目标检测方式是在传统机器学习目标检测方式的基础上进行发展的。个人在传统的机器学习目标检测方法也是进行过一些尝试,但是这种方法的瓶颈太明显了,后期就被淘汰了。
传统机器学习目标检测方式大致是分三步的:
区域提取 2. 求取特征 3. 特征过分类器
区域提取:
RCNN中提到使用的区域提取方法是Selective Search算法,个人对这个方法的大致理解就是,像素值相近的区域融合到一起,融合融合就融合出了一些比较大的区域,认为这些区域就是可能有目标的区域,用来求取特征。这个方法个人感觉不可能太准,就靠像素值这个真是有些扯,然后求取特征之前还要将长短不一的区域resize成统一的尺寸好求取特征,这个更伤,那长颈鹿和大象能是一个比例尺吗?resize成相同尺寸,这丢失了多么重要的信息呀
我们实际做的时候区域提取这个位置用的还是滑框的方式,什么是滑框,就是将你要检测的目标所有在图像中可能出现的框,在图像中逐像素滑一遍。在我看来这不就是穷举吗,这个方法真是除了慢没啥大缺点,全都不放过。
求取特征:
机器学习里求取特征这个位置也挺有意思,就是前人人为的设计了一些特征算子,然后根据这些算子去求取特征,比较有名的就是HOG、LBP、HAAR、SIFI等等。就像边缘检测一样,每一种算子都能表现出图像中的某些特征,还是挺厉害的。
分类器:
分类器这个位置比较有名的就是支持向量机(SVM)和Adaboost。每一种分类器都有自己的分类方法,因此都有和自己比较匹配的特征求取方式,比如说HOG\LBP+SVM,Haar+Adaboost。在深度学习没有崛起之前Haar+Adaboost就是人脸识别最牛的方式了。
SVM这个分类器不知道说点什么好,二分类,纯数学,个人推导过最底层的数学原理,真的是很崩溃,数学太难了。数学原理和深度学习里的sigmoid有些相似或者一样吧。都是E的X次幂,然后组合,具体形式有些记不太清了,曲线就是当x=0时,y=0.5,x趋近正无穷时,y趋近于1,x趋近负无穷时,y趋近于0,曲线在两侧特别平缓,在x=0附近陡峭,这样利于分类。数学博大精深呀。
Adaboost这个分类器有点意思,他的核心思想就是多次迭代,每次迭代都增加之前分类错误样本的权重。这个思想就像是什么呢,就像是老师教学生,开始的时候老师对每一个人的关注都是一样的,然后慢慢地老师开始将更多的精力放在那些学习不好的学生上,这样班级整体的及格率就会提高。虽然这个分类方法使用的越来越少了,但是个人觉得这个思想还是很有用的。
非极大值抑制:
以一张图像中检测一个车为例,理论上过完分类器之后,这个车四周会有很多框,因为比如说一个框框住了车的上半身,然后去过分类器,再牛的分类器也有很大的可能将其判定为车,因此图像中车的四周在过完分类器之后,会有很多框。然后需要做NMS(非极大值抑制),对于图像中每一个真实的目标,在过完分类器四周的框中只选择置信度最高的那个框,作为真实目标的检测框(真实项目中,也有试过将一些置信度都很高的框,进行融合,取平均值,作为检测输出框,效果也可以)。

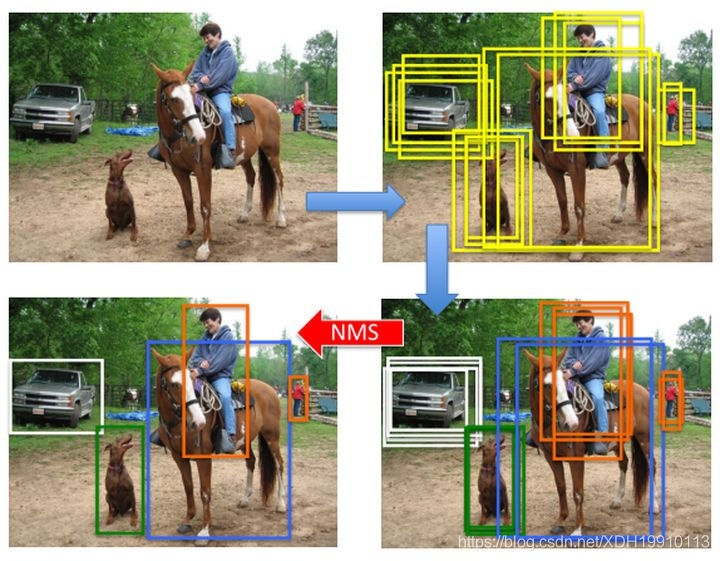

在人工智能目标检测中,去过分类器的正负样本并不是说包含有GroundTruth就是正样本,不包含的就是负样本。因为就算是传统机器学习的求特征过分类器的目标检测方式,也能够很准确的分类出哪些图像中有GroundTruth,哪些没有,而分类出哪些有GroundTruth大部分,哪些有小部分却是很难的。个人感觉这个位置的思想有些像adaboost的思想,就是将更多的关注放在那些不好区分的地方。
三、深度学习目标检测方式:
二阶深度学习目标检测方法:
RCNN、SPP-Net、FastRCNN、FasterRCNN、FPN、MaskRCNN
当前比较流行的目标检测方法是一阶深度学习的目标检测方法,但是个人觉得一阶深度学习的目标检测方法是在二阶深度学习的目标检测方法的基础上进行的改进,而二阶深度学习的目标检测方法是在传统的机器学习目标检测方法上进行的改进。
RCNN
RCNN所做的核心改变就是将传统机器学习目标检测方法中的求取特征部分,扔给了深度学习,就是不使用人为设计的特征算子了,使用深度学习来求取特征,其他地方不改变。
SPP-Net
SPP-Net提出了一个什么思想呢,就是Selective Search算法实在是太差了,Selective Search算法不管原始图像的大小、比例尺等等,就是啥也不管,特征生硬的把不同图像resize成固定尺寸了,然后求取特征,过分类器,这么做损失的信息实在是太多了。然后SPP-Net提出一个什么思想呢,就是面对特征各异的原始图像,我将他们做成一个4乘4的,做成一个2乘2的,做成一个1乘1的三张特征图,我将这三张特征图拼到一起,拼成一个21长度的特征去过分类器,这样能保证原始图像跟多的信息保留下来没有丢失。在当时还是很巧妙的一张方式。
FastRCNN
FastRCNN干了啥呢,就干了两件事,其中一件事就是使用SPP-Net,另一件事呢就是将分类器扔给了深度学习,就是我不用SVM、adaboost这种分类器了,我直接用深度学习去做分类。
FasterRCNN
FasterRCNN干了啥呢,就是选取候选区域这一块,SPP-Net也不太准。然后FasterRCNN就将候选区域这一块也扔给了深度学习,使用了RPN这么个网络(Region Proposal Network)。RPN引入了所谓anchor box的设计,anchor box是啥呢,就是在原始图像中加入了很多候选框,在我看来这是啥呢,就是蒙呗,我管你目标长啥样呢,先在全图上蒙一堆框,咋也有差不多蒙中的,回头我再回归,详细调位置,目标不就出来了。

一阶深度学习目标检测方法:
YOLOV1、YOLOV2、SSD、YOLOV3
一阶的深度学习目标检测方法是在二阶的基础上得到的,二阶深度学习目标检测方法一个很重要的缺点就是太慢了,RPN那个部分真的是太慢了,之前有测过,SSD的速度差不多比FasterRCNN快一倍,如果有实时性的需求,二阶这一块基本不用考虑。但是二阶是真准,之前有做过使用目标检测方法来辅助标注,干的是一个什么事呢,就是我们有采集到的数据,但是没有人标注,然后想要使用当前的目标检测进行标注。分别使用了MaskRCNN和SSD+FPN进行过测试,两个方法分类的准确率差异并不明显(可能也明显,是我没有使用大量数据进行统计,这个都能分类的差不多,几张图片看不出什么来),但是回归的准确率差异是真明显呀,SSD+FPN的分类基本没什么问题,但是他的回归效果照真实的标注差很多,什么意思呢,就是SSD+FPN出来的结果,分类是准的,但是基本每一张图回归效果照真实标注都要差一些,差的还不多。而这一点MASKRCNN就会好很多,到什么程度呢,就是时常有一些图像与真实的标注一样,基本不用调。
YOLOV1
YOLO(You Only Look Once )
YOLOv1的思想很简单,就是我可以不准,但是必须快。他将图像分成了七七四十九块,然后每块两个框,进行分类和回归。总共才98个框,怎么可能准,图像中的目标长宽也不可能正好是图像长宽的七分之一吧,这个固定的尺寸想要回归太难了,分类也难,比如说一个大的目标占图像的四分之一,然后你所有的框都只能框住一部分,不能框住目标的大部分,分类效果不可能太好。因此YOLOv1确实是一个不错的思想,但是想要实际应用还不太可能。
SSD
SSD 的全称是Single Shot MultiBox Detector。它相比起YOLO v1 主要的改进点在于两个方面:1. 利用了先验框(Prior Box)的方法,预先给定scale 和aspect ratio,实际上就是之前Faster R-CNN 中的anchor box 的概念。2. 多尺度(multi-scale)预测,即对CNN 输出的后面的多个不同尺度的feature map 都进行预测。下图是SSD 论文作者给出的SSD 与YOLO 的结构的比较: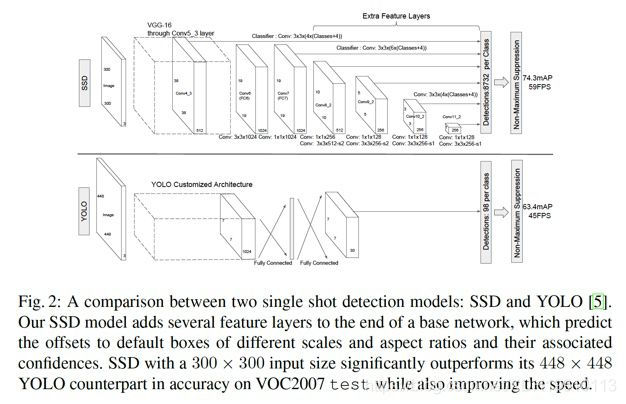
通过上面的改进,SSD 提高了速度,同时也提升了准确率,另外还对于低分辨率图像也能有较好的预测结果。
个人比较喜欢SSD,在我看来SSD算是第一个综合了二阶方法准而慢和一阶方法快而不准两者优点,能够使用的一个方法,准而不慢。
YOLOV2
YOLO v2 是对YOLO v1 的改进版本。论文中叫做YOLO9000,因为它可以识别9000+ 的类别的物体。
YOLO v2 的主要改进为以下几个方面:
1、对所有卷积层增加了BN(BatchNorm)层。
2、用高分辨率的图片fine-tune 网络10 个epoch。
3、通过k-means 进行聚类,得到k 个手工选择的先验框(Prior anchor box)。这里的聚类用到的距离函数为1 - IoU,这个距离函数可以很直接地反映出IoU 的情况。
4、直接预测位置坐标。之前的坐标回归实际上回归的不是坐标点,而是需要对预测结果做一个变换才能得到坐标点,即x = tx × wa − xa (纵坐标同理),其中tx 为预测的直接结果。从该变换的形式可以看出,对于坐标点的预测不仅和直接预测位置结果相关,还和预测的宽和高也相关。因此,这样的预测方式可以使得任何anchor box 可以出现在图像中的任意位置,导致模型可能不稳定。在YOLO v2 中,中心点预测结果为相对于该cell 的角点的坐标(0-1 之间),如下:
5、多尺度训练(随机选择一个缩放尺度)、跳连层(paththrough layer)将前面的fine-grained 特征直接拼接到后面的feature map 中。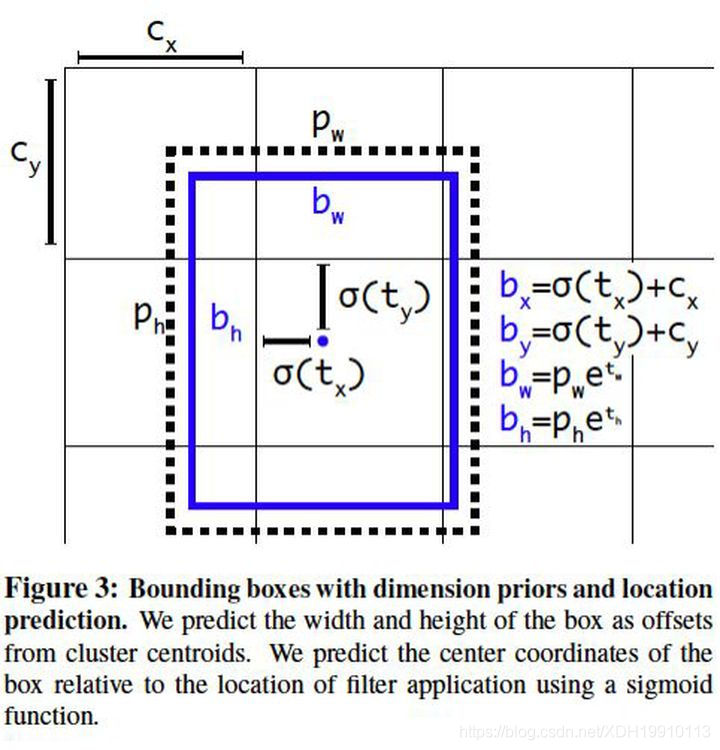
YOLOV3
YOLO v3 是针对YOLO 模型的又一次改进版本,如作者自称,是一个incremental improvement,并无太大创新,基本都是一些调优和trick。主要包括以下几个方面。
用单类别的binary logistic 作为分类方式,代替全类别的softmax(和mask R-CNN 的mask 生成方式类似)。这样的好处在于可以处理有些数据集中有目标重叠的情况。
YOLO v3 采用了FPN 网络做预测,并且沿用了k-means 聚类选择先验框,v3 中选择了9 个prior box,并选择了三个尺度。
backbone 做了改进,从darknet-19 变成了darknet-53,darknet-53 除了3x3 和1x1 的交替以外,还加入了residual 方法,因此层数得到扩展。
YOLO的论文实在是太难复现了,不看源码,有些细节的东西真是整不了,SSD的论文在YOLOv3之前发表的,SSD的页数快有YOLOV3的一倍了,YOLO论文太糙了
YOLOV4,YOLOV5......
之后的论文就没有太仔细的阅读了,我知道V4使用了很多数据增强的方法。感觉基于布框的目标检测方式,基本的东西都出来了,就看怎么用了。YOLOV3之前的这些主要的目标检测论文无论是二阶还是一阶的都比较值得阅读,因为每一篇论文都有一些新的想法提出来,YOLOV3之后包括YOLOV3,感觉就更偏实用了,检测的准确率更高,但是没有什么新的设计被提出来。RCNN、FastRCNN、FasterRCNN、SSD、FPN这些论文感觉都会实现目标检测方面一些质的提升,感觉其他的都是一些小修小补,虽然也挺厉害的,但是不高级。
我也阅读了几篇没有anchor的目标检测论文,有的核心思想是一堆下采样将图像缩小,然后再一堆上采样上来形成与原始图像一样大的特征图,网络结构就像沙漏一样,然后对每一个像素进行处理,这样太慢了,当前没有硬件能够实时带的起来。我觉得摒弃anchor的这个思路还是挺好的,因为人眼识别目标的时候有anchor吗??我觉得是没有的,在我看来深度学习整体的发展趋势是越来越黑的,从二阶的目标检测发展历程也能看的出来,人为设计的东西越来越少,更多的过程由深度学习自己来完成。无anchor的思路是可行的,但是还在发展阶段没有成熟。
Yolo发展史(v4/v5的创新点汇总!):
https://mp.weixin.qq.com/s/bINKktFpWYiStYcejS4Gmg
参考链接:
https://blog.csdn.net/f290131665/article/details/81012556
https://blog.csdn.net/electech6/article/details/95240278
https://blog.csdn.net/yegeli/article/details/109861867
https://zhuanlan.zhihu.com/p/32525231
https://zhuanlan.zhihu.com/p/34142321
https://zhuanlan.zhihu.com/p/242424344
https://github.com/hoya012/deep_learning_object_detection
最后这个参考链接非常好,第一张图就是从这里偷的,里面总结有论文下载地址,有的还有代码
网易面试原题|简述Yolo系列网络的发展史:
https://mp.weixin.qq.com/s?__biz=MzU4NTY4Mzg1Mw==&mid=2247508396&idx=4&sn=8534c5038c80e00620644c5e92af6fe3&chksm=fd84274ecaf3ae584b60b8f0b7d2f61210fcd149df6a9cbb7a298b42782615c8a7ed5599caf5&scene=21#wechat_redirect
四、为目标检测制作PASCAL VOC2007格式的数据集
一、前言
在利用诸如Faster R-CNN等深度学习网络进行目标检测的时候一定需要训练自己的数据集,一般有两种方法:
按照VOC2007的格式修改自己的数据格式
根据自己的数据格式修改源码
一般推荐第一种方法,因为第一种方法比较简单而且不容易出错,在制作为VOC2007格式的数据集之前,这里可以下载原始VOC2007数据集:VOC2007数据集,来看看这个数据集到底是什么样的:
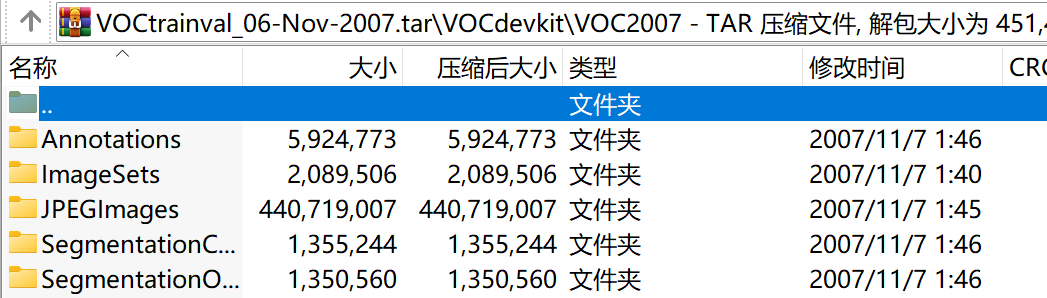
解压VOC2007数据集后可以看到VOC2007文件夹下有以下5个文件夹:
Annotations文件夹
该文件下存放的是xml格式的标签文件,每个xml文件都对应于JPEGImages文件夹的一张图片。
JPEGImages文件夹
该文件夹下存放的是数据集图片,包括训练和测试图片。这些图像的像素尺寸大小不一,但是横向图的尺寸大约在500*375左右,纵向图的尺寸大约在375*500左右,基本不会偏差超过100。(在之后的训练中,第一步就是将这些图片都resize到300*300或是500*500,所有原始图片不能离这个标准过远。
ImageSets文件夹
ImageSets存放的是每一种类型的challenge对应的图像数据。
该文件夹下存放了三个文件,分别是Layout、Main、Segmentation。在这里我们只用存放图像数据的Main文件,其他两个暂且不管。
Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)
Main下存放的是图像物体识别的数据,总共分为20类。
Segmentation下存放的是可用于分割的数据。
在这里主要考察Main文件夹。
Main文件夹下包含了每个分类的train.txt、val.txt和trainval.txt。
这些txt中的内容都差不多如下:
000005 -1
000007 -1
000009 1
000016 -1
000019 -1
前面的表示图像的name,后面的1代表正样本,-1代表负样本。
_train中存放的是训练使用的数据
_val中存放的是验证结果使用的数据
_trainval将上面两个进行了合并
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能有重复,在选取训练数据的时候 ,也应该是随机产生的。
SegmentationClass文件和SegmentationObject文件。
这两个文件都是与图像分割相关,跟本文无关,暂且不管。
二、制作PASCAL VOC形式的数据集
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
将devkitVOCdevkit_08-Jun-2007.jar、测试集VOCtest_06-Nov-2007.jar、训练集/验证集VOCtrainval_06-Nov-2007.jar分别下载到本地文件夹下,如下图所示。

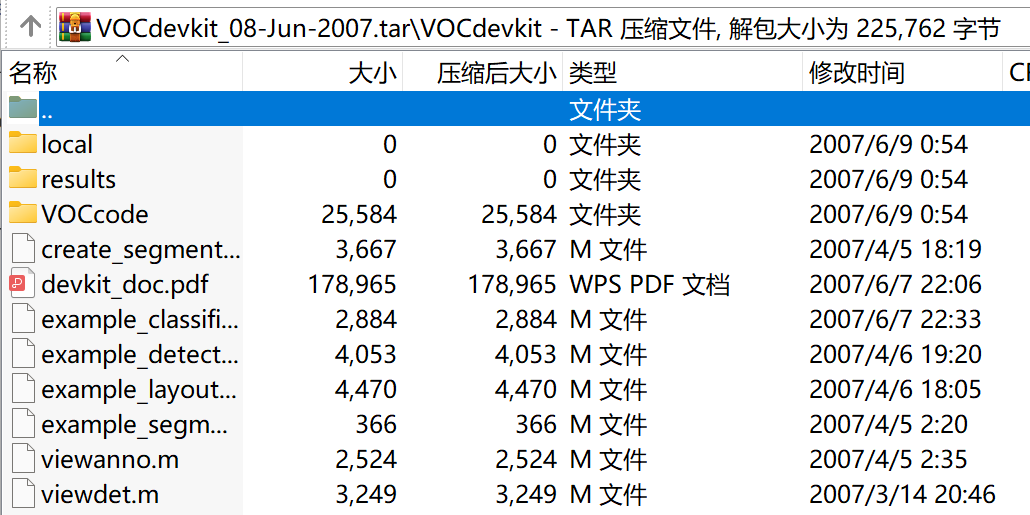
其中,devkitVOCdevkit_08-Jun-2007.jar中的文件是 development kit code and documentation ,即一些开发工具包代码和文档,如下图所示。有一些MATLAB代码,就是用这些代码处理的这个数据集,还有一个devkit_doc.pdf, 是一个比较详细的说明书。
测试集VOCtest_06-Nov-2007.jar和训练集/验证集VOCtrainval_06-Nov-2007.jar中的文件均为一个VOC2007文件夹,如下图所示。



Annotations
这个文件夹里都是.xml文件,文件名是图像名称,如下图所示。每个文件里面保存的是每张图像的标注信息,训练时要用的label信息其实就来源于此文件夹。
ImageSets
这个文件夹里面是图像集合 ,打开之后有3个文件夹:Layout 、 Main、 Segmentation,这3个文件夹对应的是 VOC challenge 3类不同的任务。
VOC challenge的Main task,其实是classification和detection,所以在Main文件夹中,包含的就是这两个任务要用到的图像集合。共有84个.txt文件,其中4个文件为训练集train.txt、验证集val.txt、训练集和验证集汇总trainval.txt、测试集test.txt,这4个文件里面保存的是图像的ID号;还有20类目标,每个类别有该类的类别名_train.txt、类别名_val.txt、类别名_trainval.txt、类别名_test.txt这4个文本,共80个文件。这80个文件中每一行的图像ID后面还跟了一个数字,要么是-1, 要么是1,有时候也可能会出现0,意义为:-1表示当前图像中,没有该类物体;1表示当前图像中有该类物体;0表示当前图像中,该类物体只露出了一部分。
此外还有两个taster tasks :Layout和Segmentation,这两个任务也有各自需要用到的图像,就分别存于Layout和Segmentation两个文件夹中,分别有4个文件:训练集train.txt、验证集val.txt、训练集和验证集汇总trainval.txt、测试集test.txt。
JPEGImages
这个文件夹里面保存的是数据的原始图片,打开之后全是.jpg图片,如下图所示,共有9963张图像。
SegmentationClass
这个文件夹里面保存的是专门针对Segmentation任务做的图像,里面存放的是Segmentation任务的label信息。
SegmentationObject
这个任务叫做Instance Segmentation(样例分割),就同一图像中的同一类别的不同个体要分别标出来,也是单独给的label信息,因为每个像素点要有一个label信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号