hadoop常遗忘点
hadoop安装:
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限 (若文件夹名hadoop-3.1.3没有进行修改,则修改文件权限应该这样写sudo chown -R hadoop ./hadoop-3.1.3)
伪分布:
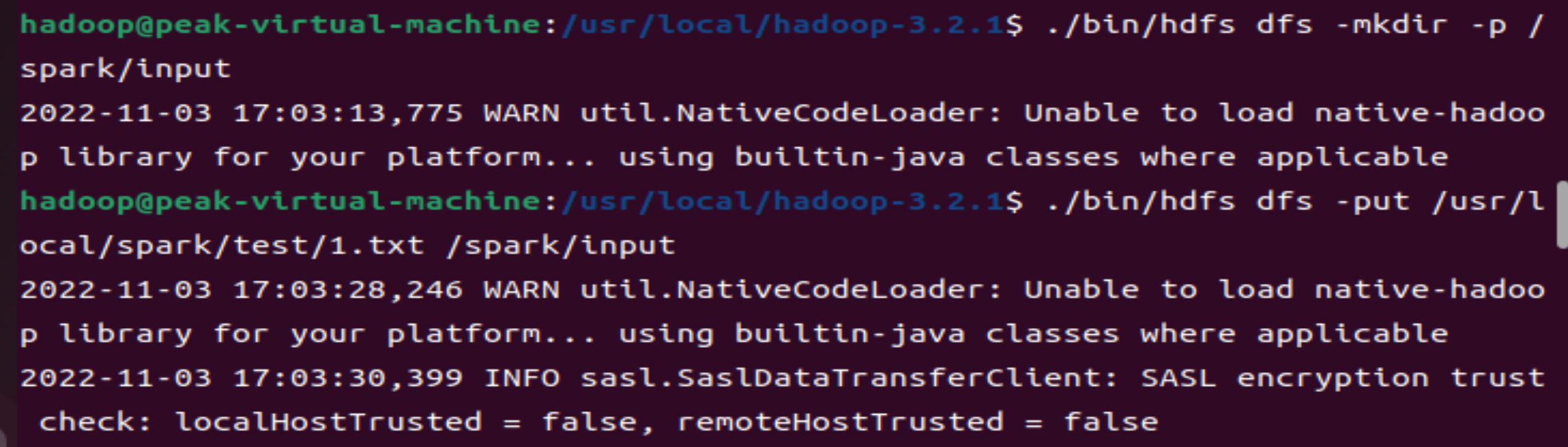
在hdfs上创建文件夹:./bin/hdfs dfs -mkdir -p /spark/input
注解:hdfs的路径须得明确在hadoop的bin下,即下图的根路径是/usr/local/hadoop-3.2.1,因此hdfs的路径为./bin/hdfs;而/spark/input该路径指的是在伪分布里新创的文件夹。
put上传: ./bin/hdfs dfs -put /usr/local/spark/test/1.txt /spark/input
注解:将文件1.txt上传到伪分布中的/spark/input目录中,其中1.txt的路径得写全,且我的1.txt文件里面写的内容是hello world。
查看上传的文件: ./bin/hdfs dfs cat /spark/input/1.txt
代码:
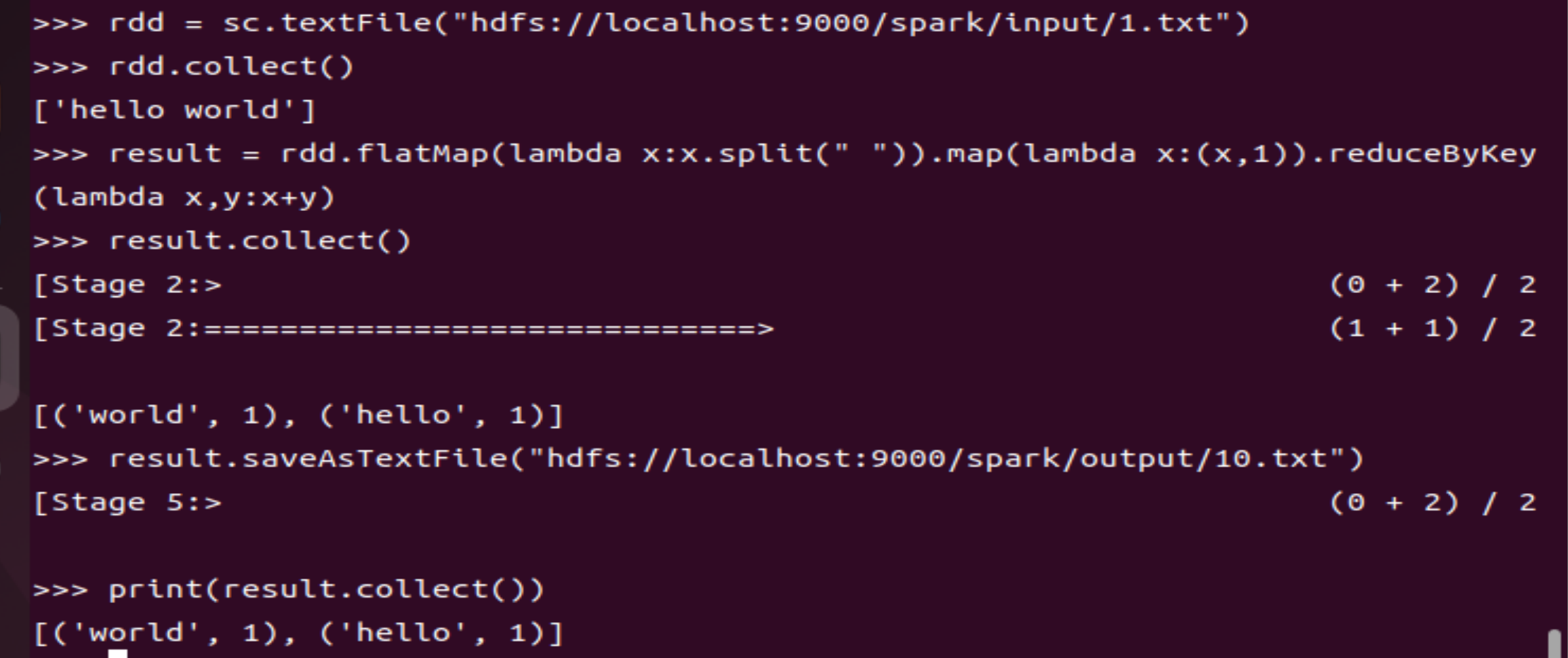
rdd = sc.textFile("hdfs://localhost:9000/spark/input/1.txt") #代码展示主要关于伪分布中的/spark/input/1.txt
result = rdd.flatMap(lambda x:x.split(" ")).map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y) #map-reduce
result.saveAsTextFile("hdfs://localhost:9000/spark/output/10.txt") #将map-reduce所形成的结果存放在伪分布的文件/spark/output/10.txt中,其中output及10.txt不用另外创建,只用此代码即可进行显示
print(result.collect()) #将存放在10.txt中的map-reduce结果显示出来
注解:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号