CUDA[1] Introductory
Section 0 :Induction of CUDA
CUDA是啥?CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
为什么用显卡就可以实现比CPU高得多的运算性能呢?这要从GPU的结构讲起:
GPU天生是为了图像处理而设计的,讲道理的话它能处理一些简单的运算工作(比如单独的顶点和线段)。但是在一个GPU中包含了许多个流处理器(Stream Processor),这些流处理器都可以并行工作。In this sense, GPUs are stream processors – processors that can operate in parallel by running one kernel on many records in a stream at once. [Reference]
对于CPU来说,12核已经是上天了的配置。然而今天,随意一个亮机卡GPU都有96个CUDA计算单元(每个相当于一个计算核心)。其并行计算能力不可同日而语。
Section 1 :Thread Hierarchy
在CUDA的计算模型中,有如下几个concept:
1.thread
这里的线程和CPU中其实是一个意思。是执行运算的最小单位。
在执行时,每个线程都有一个自己独特的标识符 threadIdx。threadIdx可以是一维/二维/三维的。(threadIdx.x,threadIdx.y,threadIdx.z)
2.block (thread block)
一个线程块包含了多个线程
3.Streaming Multiprocessor
每个SM相当于一个计算单元,里面又包含很多个Streaming Processor。每个SM可并行运行一个block里的线程。
4.Kernel
kernel可以理解成一个函数。同一个kernel函数可以在多个线程中被执行。
比如下面的向量加法的程序:
1 // Kernel definition 2 __global__ void VecAdd(float* A, float* B, float* C) 3 { 4 int i = threadIdx.x; 5 C[i] = A[i] + B[i]; 6 } 7 int main() 8 { 9 ... 10 // Kernel invocation with N threads 11 VecAdd<<<1, N>>>(A, B, C); 12 ... 13 }
line 2:用__global__关键字定义了一个kernel函数
line 4:threadIdx表示当前执行该kernel函数的这个thread的一个标号(可以理解为this指针的用途)
line 11:在调用kernel函数时,需要分配<<number_of_blocks , threads_per_block>> 。上述程序中分配了一个block,每个block中N个thread
虽然多个线程调用的都是同一个kernel function,但是它们分别在不同的数据空间进行加法运算(注意A、B、C的数组下标)。因此将一个大向量的加法运算给分解开了。
5.Grid
不同种类的kernel,每种kernel可以调度若干个block。这些block逻辑上被判为一个Grid。
thread、block和Streaming Multiprocessors的关系如下:
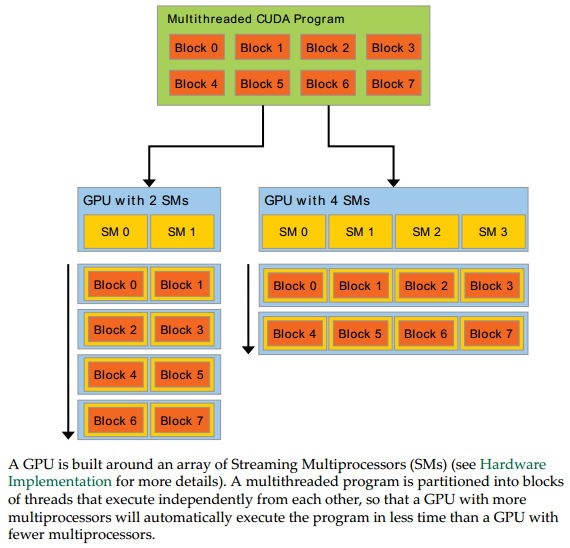
[Source: CUDA C Programming Guide.pdf]
如图,每个SM可以处理一个block,从而实现了并行计算。
两个层次的并行: • grid内多个block的并行 • block内多个thread的并行
注意:block和thread都是逻辑上的概念,物理上只存在SM。并不是一个SM一定严格对应一个block
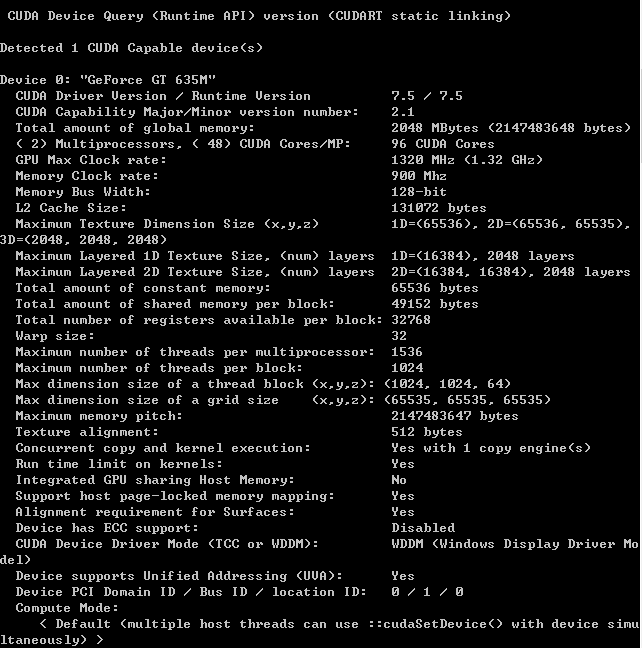
比如对于我的亮机卡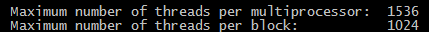
每个SM可以跑1536个线程,而每个block最多1024个
但是实际上因为寄存器大小不一定够,并不一定能全部跑满这些线程。如果强行跑,就可能会爆掉
Section 2:Memory Hierarchy
[注意这里说的Memory都是指显存。CPU无法直接访问显存中的数据。][Reference]
因此,一个CUDA程序必然少不了以下三步:
☻cudaMalloc:创建新的动态显存堆
☻cudaMemcpy:将主机(Host)内存复制到设备(Device)显存
☻显存处理完之后,cudaMemcpy:设备(Device)显存复制回主机(Host)内存,释放显存cudaFree
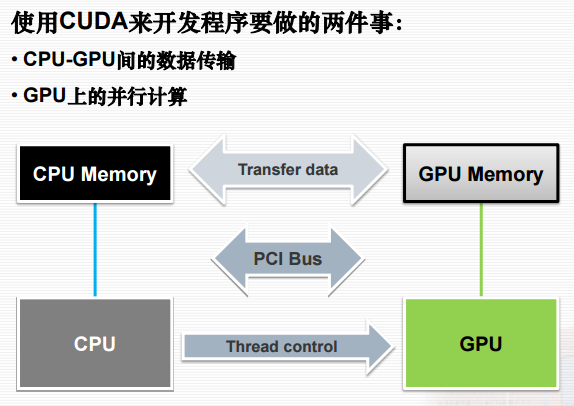
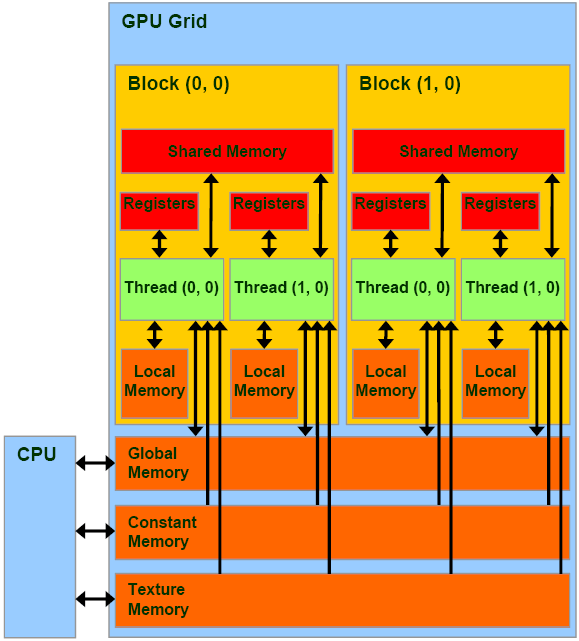
CPU/RAM与GPU/VRAM的关系如图:[Reference]
Gird、block、thread的内存访问/共享机制如下图:
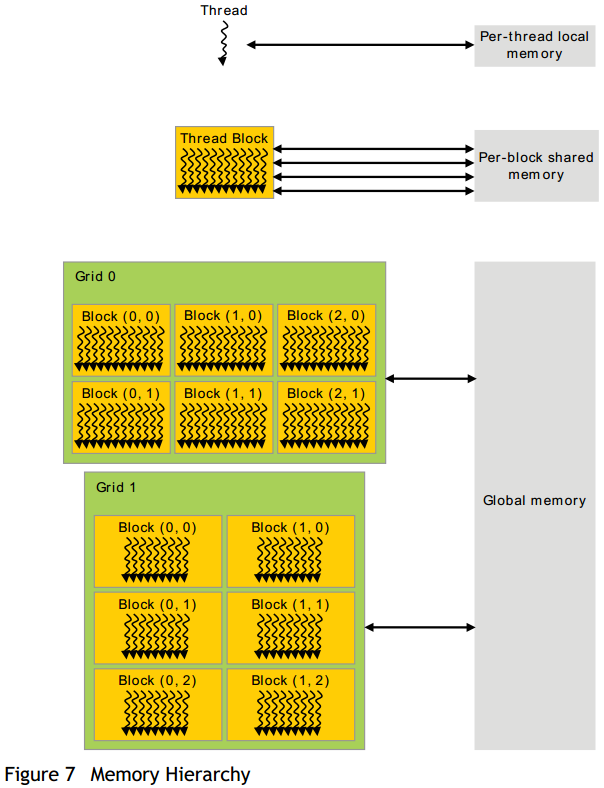
这里有几个概念:
Local Memory:单个线程内使用的内存空间
Shared Memory:一个block内所有线程共享的内存空间,常用于线程之间的通信。
每个SM(StreamingMultiprocessor)大约有16KB的shared memory
Global Memory:所有的block共享的内存空间。比shared速度慢,但是大许多
Constant Memory:存储常量。一块显卡大约有64KB的constant memory
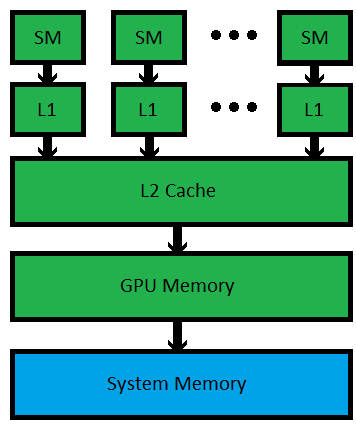
从硬件的角度来看结构是这样的:[Reference] [Reference]
posted on 2016-04-14 13:40 Pentium.Labs 阅读(361) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
