MVCC/分布式事务简介
之前我们学习了RocksDB,但这还只是一个最基础的存储引擎。如果想把它在生产环境中用起来,还需要解决很多问题:
- 如何从单机扩展到分布式?
- 如何实现事务,并对事务进行并发控制?
- 用户接口能不能高级一点?不要只有get/set?
这次我们就来解决这三个问题。
如何从单机扩展到分布式
分布式的一大意义就是把单机放不下的数据分散到多个节点上。我们不妨按照key将不同范围的key分成多个region:比如[a-c]是region1,[d-f]是region2。然后用这种方法存储:
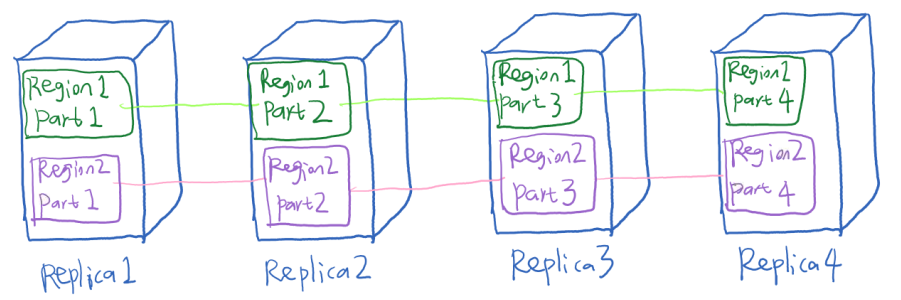
这样实现了一个基本的load balancing。一个Region里所有的数据分散存储在多个replica上,每个实例只会存一部分的region。当然分布式之后我们是要支持节点的动态增减的,具体细节暂时忽略
分布式之后还有一个重要的问题就是如何保证多个节点的一致性。还记得paxos嘛?就用它了!当然用Raft也可
如何实现事务,并对事务进行并发控制?
事务是数据库系统中一个很重要的概念。比如我们的数据库要拿给银行去用,然后银行要把账户A的100块钱转给账户B,就需要执行如下操作:
if (A.balance>=100){ A.balance-=100; B.balance+=100; return(DB_OK); } else{ return(DB_ERROR); }
当然在数据库系统中事务是用SQL实现的。
在事务的执行过程中,整段事务需要保证要么全都不执行,要么全都执行完,不允许出现执行到一半退出了的情况(即应该是个原子操作)。除此之外,像这样的约束条件还有很多,整理起来就是事务的ACID特性。
为了保证事务的执行能满足ACID特性,我们可以把事务的执行抽象成两种操作:commit(执行完整个事务)和rollback(比如事务跑到一半数据库崩溃了,重启后就要撤销之前执行到一半的工作,恢复到事务没执行的状态)。commit的实现很显然,直接执行就完事了......而为了实现rollback可以给数据库加上日志恢复技术,这样就可以恢复到过去的时间点了。
MVCC
如果事务是串行执行的,那么到这里差不多就可以了。但假设我们的数据库要拿去进行双十一秒杀,就需要支持多个事务的并发运行,这时候就需要进行并发控制。在数据库课本上我们学习过一些简单的并发控制模型和实现方法(如基本的加锁解锁、2pc)。但我们知道,一次事务执行时被加锁的资源越多,整个db的并行度就越低。简单的方法就没法保证用户能流畅的秒杀了......那么如何使得并行度尽可能高呢?MYSQL中使用了MVCC模型,这里我们也比葫芦画瓢用一下。
并发控制的作用就是防止出现并发一致性问题。还记得5105课上学过在Client-centric consistency models中,多个client对同一资源进行读写的几个模型吗(Monotonic-Read、Monotonic-write、Read your write、Write follow reads)?在5105课上我们学习了为了保证最终一致性,这些操作应该怎么执行、怎么加锁。这个思路放到数据库的并发控制中同样适用。
MVCC是一种多版本并发控制机制。MVCC可以在大多数情况下代替行级锁,降低系统开销。
MVCC的本质就是copy on write,能够做到写不阻塞读MVCC能够做到写读不冲突,读读不冲突,读写也不冲突,唯一冲突的就是写和写,这样系统并发读就可以非常高。MVCC 提供了时点(point in time)一致性视图。MVCC 并发控制下的读事务一般使用时间戳或者事务 ID去标记当前读的数据库的状态(版本),读取这个版本的数据。读、写事务相互隔离,不需要加锁。读写并存的时候,写操作会根据目前数据库的状态,创建一个新版本,并发的读则依旧访问旧版本的数据。一句话讲,MVCC就是用同一份数据临时保留多版本的方式 ,实现并发控制。MYSQL的并发控制就是用MVCC实现的。
那么怎么把MVCC用到我们的kv数据库中呢?我们可以给key-value键值对也加上timestamp。然后在运行的过程中,遵照以下规则:
- All modifies are adding a new version.
- The same row(就是同一个key-value键值对) may have multiple versions.
- Old versions dropped by GC.
在分布式并发事务的具体实现中,会用到一个Percolator Transaction Model。它是来自Google的一篇paper。Percolator的设计是为了解决2pc在分布式环境中的一些问题,相当于是2pc的增强版。用于在保证分布式一致性的基础上保证事务执行的ACID特性。
Percolator:分布式并发事务的实现
rocksdb提供了Column Families (CF) 特性,可以用来实现上面的Percolator事务模型。CF是对数据库做的一个logical partition,可以类比关系数据库中的视图,但比视图支持更多的高级功能:
- Atomic writes across Column Families are supported. This means you can atomically execute Write({cf1, key1, value1}, {cf2, key2, value2}).
- Consistent view of the database across Column Families.
- Ability to configure different Column Families independently.
- On-the-fly adding new Column Families and dropping them. Both operations are reasonably fast.
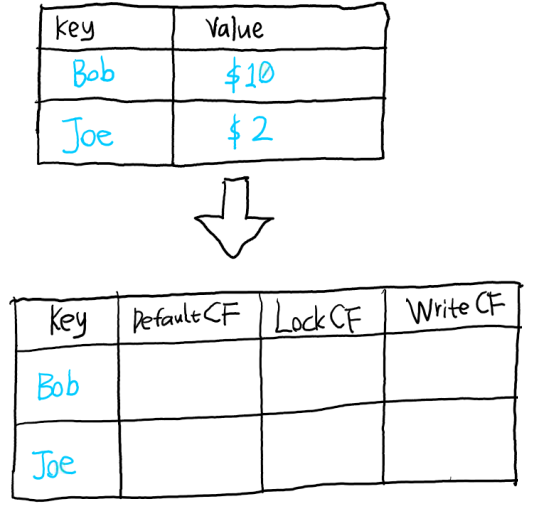
为了实现Percolator事务模型,比如我们可以设置如下三个CF:
- DefaultCF:存储数据
- WriteCF:存储已提交的事务commit时的timestamp
- LockCF:存储正在执行,还未提交的事务产生的锁
比如一开始我们有一个用来存储账户存款的key-value数据库,我们可以这样给它扩展成三个CF:
Percolator的核心就是2pc的改进版。通过利用client作为协调者,解决了协调者挂了对整体服务能力的影响,而在事务相关信息的一致性和持久性上充分利用了BigTable的简单事务支持以及GFS的多副本可靠性能力,另外Percolator在数据模型上是mvcc。
比如我们要执行一个事务,把Bob的7块钱转给Joe。使用Percolator执行事务的过程如下:
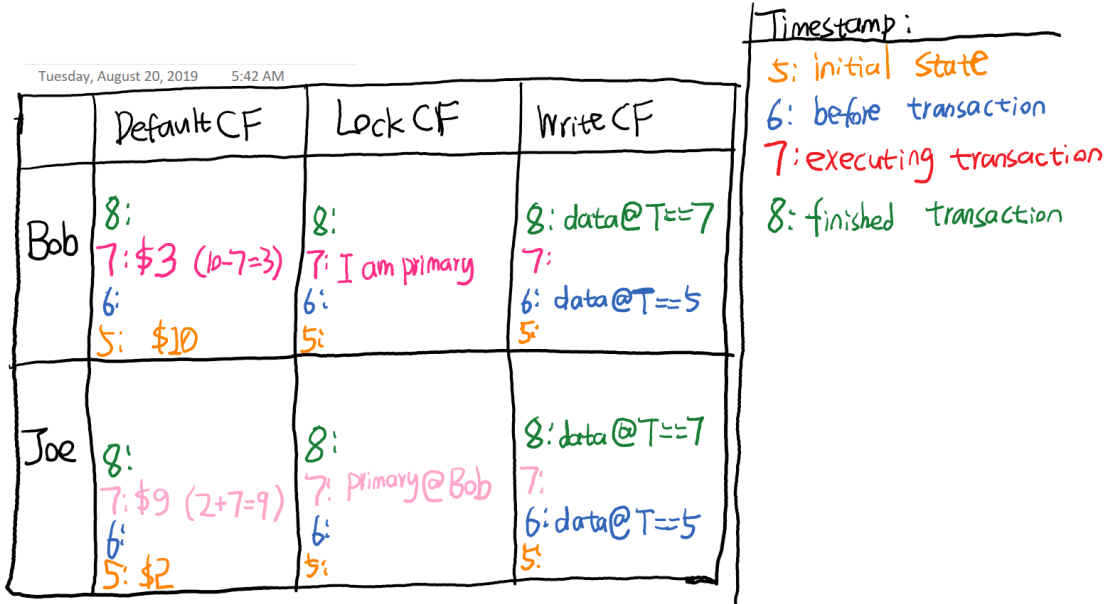

1111111
使用Percolator模型实现MVCC
Ref:
MVCC
https://blog.csdn.net/zzti_erlie/article/details/81094178
https://blog.csdn.net/whoamiyang/article/details/51901888
分布式事务
https://www.cnblogs.com/FengGeBlog/p/10278368.html
https://blog.csdn.net/maxlovezyy/article/details/88572692
https://blog.csdn.net/u013045749/article/details/50855823
https://xiking.win/2018/06/22/percolator-paper/
https://github.com/pingcap/blog/blob/master/2016-11-17-mvcc-in-tikv.md
http://int64.me/2017/MVCC%20In%20TiKV.html
https://andremouche.github.io/tidb/transaction_in_tidb.html
https://dzone.com/articles/how-to-do-performance-tuning-on-tidb-a-distributed
posted on 2019-08-20 18:52 Pentium.Labs 阅读(1548) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
