分布式系统知识总结
5105结课之后就该总结一下的,太懒了
(基本来自5105的笔记,省略了一些不太用得到的知识点,另外补充了一些6.824中出现的重要内容)
(Mark一个DDIA的读书笔记:https://www.cnblogs.com/happenlee/category/1124283.html,https://github.com/Little-Wallace/ddia-note,感觉看笔记就够了...)
1. RPC
Persistent communication(持久通信):Messages are stored until receiver is ready. Sender/receiver don’t have to be up at the same time
Transient communication(瞬时通信):Message is stored only so long as both sending/receiving applications are executing. Discard message if it can’t be delivered to receiver
Synchronous communication(同步通信):Sender blocks until message is delivered to receiver Variant: block until receiver processes the message
Asynchronous communication(异步通信):Sender continues immediately after it has submitted the message
RPC:client远程调用server上的函数
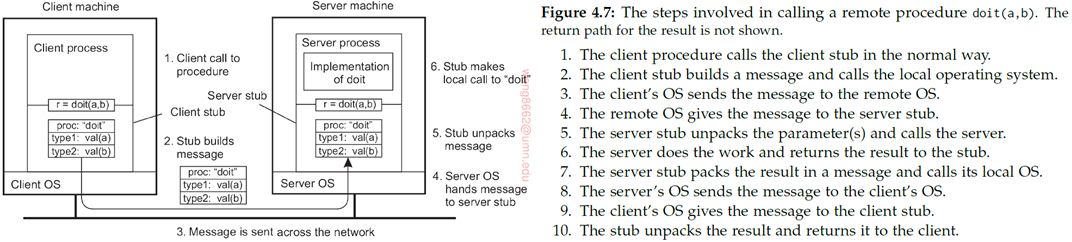
同步RPC和异步RPC:
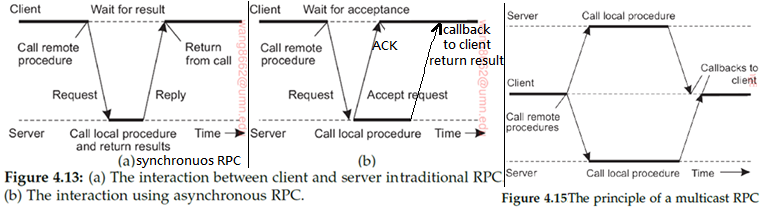
Stub: Hide communication details (相当于thrift生成的.java文件的内容)
- Client stub: Converts function call to remote communication | Passes parameters to server machine | Receives results
- Server stub: Receives parameters and request from client | Calls the desired server function | Returns results to client
Binding:set up communication between client and server
为解决不同机器上数据格式不一样的问题,stub需要进行parameter marshalling(将参数使用一种standard data format打包进消息)
parameter passing(略)
2. Message Oriented Communication, multicast
在rpc中,如果无法保证server正在运行,那么同步rpc会导致client被阻塞。所以需要消息传递系统
Message Oriented Transient Communication
1. Socket 应用程序通过网络发送数据时,可以把数据写入套接字,然后再从套接字读取数据。
2. MPI
3. ZeroMQ:Provide enhancement to sockets for a few simple communication patterns.
- ZeroMQ中的连接是异步的。connection request messages are queued at the sender’s side
- Built on top of TCP/IP -> ZeroMQ will automatically set up connection before message transmission
- In ZeroMQ, a socket can be bound to multiple addresses -> support many to one/one to many(multicasting)
Message Oriented Persistent Communication
Message-Queuing Model: Support asynchronous persistent communication -> Intermediate storage for message while sender or receiver are inactive.
Multicast
在传输信息时,结点会组织成一个覆盖网络(overlay network,建立在物理网络基础上的一层,可以类比VPN),然后用它来传播信息给成员。
Multicast Tree(略)
Flooding
In this case, each node simply forwards a message m to each of its neighbors, except to the one from which it received m. Furthermore, if a node keeps track of the messages it received and forwarded, it can simply ignore duplicates.
- - Naïve flooding: Number of messages = number of edges O(N^2)
- - Probabilistic flooding: Send message with probability p_flood
Gossiping
模仿疾病传播的过程。用于large network
Ref:http://www.10tiao.com/html/151/201903/2665515873/1.html
1. Anti-Entropy
2. Rumor Spreading
3. Directional Gossiping
(略)
3. Naming
Naming system: resolve a name to its address Flat Naming / Structured Naming / Attribute-based Naming
Broadcasting && Multicasting
Broadcast the name -> the named entity(eg: machine) responds its address
Eg: ARP:计算机A向局域网广播,想要连接IP为172.18.72.5的计算机B。局域网中所有电脑都会收到该广播,但只有计算机B会响应,返回它的MAC地址。A收到这个报文后,就将B的mac地址记录下来,存在A的ARP缓存表。
Distributed Hash Table
参考5105 pa2:https://www.cnblogs.com/pdev/p/10621547.html
和hash专题:https://www.cnblogs.com/pdev/p/11332264.html
Linux NFS:用于访问远程主机的文件
(略)
DNS
Namespace: 路径名root: <cn, edu, hfut, ci> -> ci.hfut.edu.cn
(略)
4. MapReduce
参考MapReduce的笔记:https://www.cnblogs.com/pdev/p/11087826.html
和5105 pa1:https://www.cnblogs.com/pdev/p/11331792.html
5. Mutex election
Mutex Algorithm: 访问互斥资源用
(略)
Election Algorithm:用于在分布式系统中选出coordinator
每个node事先都知道所有node的id,但不知道哪些node还活着,所以要选举而不是直接本地sort取最大的...
(略)
5. consistency
Data Replication:建立多个副本 Data Consistency:保证任意时间/地点看到的事物是完全一致的
Data-centric consistency models:
解决共享数据的读/写操作中的一致性问题, from server’s perspective
- 1.1 strict consistency:要求全局同步,开销太高,仅存在于理论中
- 1.2 sequential consistency:Any process see the same sequence(order) of operations. (课本P204)
- 任何读写操作的有效交叉都是可接受的(不关心具体执行结果,No notion of absolute time),但所有进程都要看到相同的RW顺序(只关心一致性)。同一进程内对同一个变量的读写保持该进程本身的顺序。
- 1.3 casual consistency(因果一致性):Causally related writes must be seen in the same order by all processes. (课本P206)
- 不同机器必须以相同顺序看到具有因果关系(eg:对同一资源先W后R,会产生依赖关系)的写操作。可以以不同顺序看到并发的(无因果关系)写操作[这一点与sequential consistency不一样]。(同一进程内的R/W操作一定是有依赖关系的)
- 1.4 FIFO consistency: All write in one process are seen in the same order by all processes. 不同进程间的write顺序不要求
- 1.5 Synchronization-based consistency: All local writes are flushed out. All remote writes are gathered in. (in sync barrier)
- 1.6 Weak consistency:
Client-centric consistency models: 研究同一client在server的不同副本上操作的问题。大多数是read, write-write conflict很少, 只要求最终一致性(what’s visible to client), 相对data-centric开销更低(weaker consistency)
Read Set:client读过的writes Write Set:client发起的写操作
- Eventual consistency:如果很长时间内没有写过,整个系统会逐渐达到一致。用户能接受一段时间的不一致(更新较慢)
- An update should eventually propagate to all replicas. But nothing is assumed about the timeliness of update propagation.
- 3.2 Monotonic Read: If a process reads a value of x, any successive read of x by it will return the same or a more recent value. (eg client在不同地方读邮件。replica3从有更新副本的replica1上fetch ReadSet里的所有更改)
- 3.3 Monotonic Write: If a process writes to x, this write will be completed before any successive write to x by it. 关注写操作的顺序 (E.g.: All outgoing posts from different locations。replica3从有更新副本的replica1上fetch WriteSet里的所有操作)
- 3.4 Read you write: A write to x by a process will always be seen by a successive read of x by it. (eg see my earlier posts)
- 3.5 Write follows read: If a process reads a value of x, any successive write to x by it will take place on the same or a more recent value. (eg: Your post will reflect any postings you’ve read earlier)

Continuous consistency: 衡量系统内(不同replica之间)数据不一致性的程度,以及表述系统能容忍哪些不一致性的模型
Ref: https://blog.xiaohansong.com/Continuous-Consistency.html
Consistent unit (conit): 一致性单元表示的是在一致性模型中度量的数据单元(eg: 一个副本上的某个变量)
对于每个一致性单元,持续一致性可以用三维向量定义为:一致性 = (数值偏差,顺序偏差,新旧偏差)。当所有偏差都为 0 时,就达到了线性一致性的要求。
Ordering based consistency protocol(针对顺序一致性模型)
主备份协议/本地写协议
(略)
Replicated-Write protocol: Writes can be performed at multiple replicas (主备份协议中write只在一个replica上进行)
Quorum protocol
Operations are sent (from one replica) to a subset of replicas. 读写操作都要在一坨replicas上进行
For N replicas, where Read quorum need NR replicas to agree, and Write quorum need NW replicas to agree. Need to satisfy:
- NR + NW > N (Avoid read-write conflicts, 一坨NR读, 一坨NW写时, 读不到最新版本)
- NW > N/2 (Avoid write-write conflicts, 两坨NW同时读到的版本可能不一样)
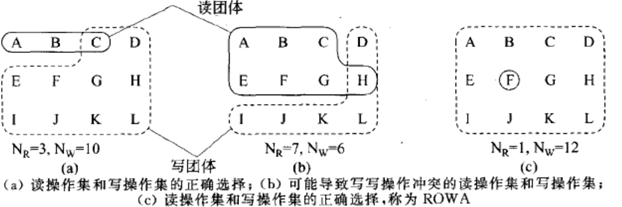
Quorum的实现:
参考5105 pa3:https://www.cnblogs.com/pdev/p/11331871.html
6. Fault Tolerance
Crash failure: server直接停机。在停机之前返回的结果都是正确的。可以被eventually detected
Byzantine(Arbitrary) failure: Incorrect but undetectable. Server可能没停机,但返回错误的结果,很难判断出这种failure
CAP Theorem
任何基于网络的数据共享系统最多只能满足数据一致性(Consistency)、可用性(Availability, 服务一直可用且保证正常响应时间)和网络分区容忍(Partition Tolerance, 当服务分散在多个replica/网络分区中, 且某个节点/网络分区出故障时, 仍能对外提供满足一致性和可用性的服务)三个特性中的两个。
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。分区容忍就提高了。然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。
Consensus Problem
多个server在Unreliable communication channel的情况下如何达成agreement on a common value
Consensus:只要所有replica最终达成一致即可。具体的值不一定(it depends)
1. Paxos
Assume there are only crash failures. proposer发起提案(value)给所有Acceptor,超过半数Acceptor获得批准后,proposer将提案写入Acceptor内,最终所有Acceptor获得一致性的确定性取值,且后续不允许再修改。
1. 准备阶段(占坑阶段)
第一阶段A:Proposer选择一个value v,向所有的Acceptor广播Prepare(value=v, timestamp=t)请求。
第一阶段B:Acceptor接收到Prepare(v, t)请求:若t比之前接收的Prepare请求都要大,则 1)承诺将不会接收比t旧的提议,2)将v写入本地,3)返回the value of previous highest timestamp accepted proposal(这个value比(v, t)要旧一个. 是为了保证该proposer见过目前为止最新的value);否则不予理会。
2. 接受阶段(提交阶段)
第二阶段A:整个协议最为关键的点:Proposer得到了Acceptor响应
如果未超过半数Acceptor响应,直接转为提议失败;
如果收到超过多数Acceptor的promise,又分为不同情况(都针对该majority里的acceptor):
如果这一majority里所有Acceptor都未接收过值(都为null),那么向所有Acceptor发起自己的值(propose(v, t))
如果这一majority里有至少一个Acceptor接收过值,那么proposer从所有接受过的值中选择对应的timestamp最大的(vo, to)作为accept 提议的值,timestamp仍然为t(propose(vo, t))。但此时Proposer就不能提议自己的值,只能信任Acceptor通过的值(因为value一但获得过确定性取值,就不能再被更改);
第二阶段B:Acceptor接收到propose后:如果它的版本号不等于自己第一阶段记录的版本号t(违反了自己的承诺),不接受该请求;相等则写入本地。
1. 理解第一阶段Acceptor的处理流程:如果本地已经写入了,不再接受和同意后面的所有请求,并返回本地写入的值;如果本地未写入,则本地记录该请求的版本号,并不再接受其他版本号的请求,简单来说只信任最后一次提交的版本号的请求,使其他版本号写入失效;
2. 理解第二阶段proposer的处理流程:未超过半数Acceptor响应,提议失败;超过半数的Acceptor值都为空才提交自身要写入的值,否则选择非空值里版本号最大的值提交,最大的区别在于是提交的值是自身的还是使用以前提交的。
有些情况下paxos会有两种可能的共识结果,但这是可以接受的(只要所有replica最终达成一致即可。具体的值不一定)


Suppose there are 2 proposers(P1, P2) and 3 acceptors(A1, A2, A3). All the 3 acceptors have null value at first. STEP1: P1 propagate Prepare(v1, t1) to 3 acceptors, but only A1 received(due to network failure), wrote (v1, t1) to its local place, and returned a promise. A2, A3 remains null. STEP2: P1 received only 1 respond, so this preparation is failed. STEP3: P2 propagate Prepare(v2, t2) to 3 acceptors, but only A2 received(due to network failure), wrote (v2, t2) to its local place, and returned a promise. A3 remains null and A1 remains (v1, t1). STEP4: P2 received only 1 respond, so this preparation is failed. STEP5: P1 propagate Prepare(v3, t3) to 3 acceptors again, but only 2 of them received(due to network failure). Then there will be 3 situations: 1) A1(v1, t1) and A2(v2, t2) received: (v2, t2) will be chosen in the second phase, and the final value is v2. 2) A1(v1, t1) and A3(null, null) received: (v1, t1) will be chosen in the second phase, and the final value is v1. 3) A2(v2, t2) and A3(null, null) received: (v2, t2) will be chosen in the second phase, and the final value is v2.
2. Byzantine Fault Tolerance
for Byzantine Failure. 保证在有几个节点是traitor的情况下, 整个系统仍保持consistency
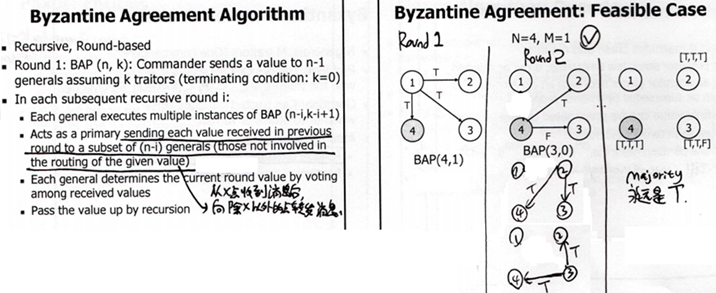
定理:OM(m): 对于一共有3M+1个节点的系统,最多可以容纳M个traitor
正常节点:会严格转发它所收到的value。 Traitor:会搞破坏(收到了a,但转发给别人b,c,d)
Byzantine Agreement Algorithm:在存在Traitor的网络中,如何保证可靠的传输?
3. Raft
7. Reliable Communication
Reliable RPC
(略)
Reliable Multicast
(略)
8. Recovery
checkpoint
logging
(略)
9. Coordination
Clock Sync
Logical Clock -- Timestamps
(略)
posted on 2019-08-10 15:24 Pentium.Labs 阅读(1147) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
