RocksDB解析
0. 存储引擎基础
存储引擎的基本功能和数据结构
一个存储引擎需要实现三个基本的功能:
- write(key, value) 二分查找并插入
- read(key) -> return value 二分查找并返回
- scan(begin, end) -> return values 求key在某区间内的所有元素。先两次二分查找,确定begin和end的位置。两位置之间的数据就是结果集 values
上述的存储引擎和普通的哈希表不同。最大的区别就是存储引擎内要求数据的存储顺序是按照key有序的。这比哈希表更节省空间,也容易实现scan()操作。
乍一看使用普通的有序数组好像就可以解决问题啦,但是普通的有序数组也有个问题:当一个新元素要write插入进来时,为保证数组有序,需要把后面的数据都移动一位,这样开销是很大的。
还有一种有序的结构叫做平衡二叉树。如果把数据有序放入平衡二叉树好像也不是不行。但是平衡二叉树会占用很多的额外空间(用于存放节点指针),另外局部性很差,读性能(read/scan)低。
(在OS的页面置换这一节中我们学过工作集的概念,其实这个和局部性很像。硬件、操作系统等等系统,绝大部分时候,执行一次 操作流程会有额外的开销(overhead)。因此很多部件、模块都设计成:连续执行类似或相同 的操作、访问空间相邻的内容时,则将多次操作合并为一次,或多次之间共享上下文信息。这样能极大提升性能。这种时间、空间上的连续性,叫做局部性。)
那用什么数据结构才好呢?可以考虑把数组和二叉树结合一下,把平衡二叉树的每个节点都改成一片数组,做成一个大叶节点树。这样一方面通过把拆分成若干小数组,减少了数组插入时的开销(写操作)。另一方面,扩大了二叉树中每个节点的大小,增加了读操作的局部性,改善了scan的性能。那具体每个节点的数组要多大才好呢?这就要根据需求进行trade off啦。
- 叶节点大:局部性高 ● 插入成本高,慢 ● 读取性能高,快
- 叶节点小:局部性低 ● 插入成本低,快 ● 读取性能低,慢
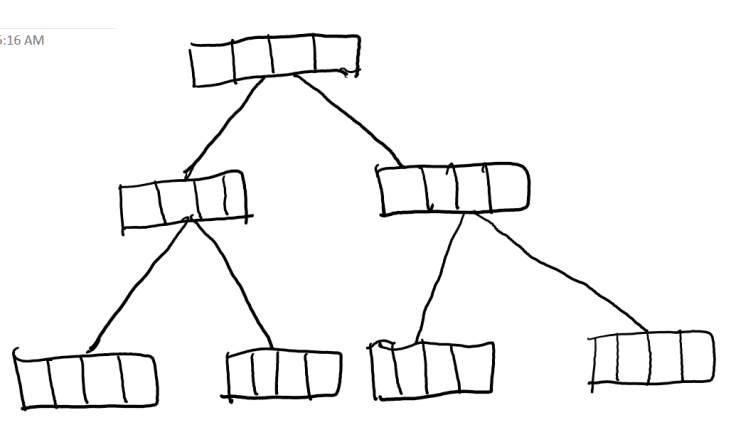
在实践中很多存储引擎会使用B+ Tree作为存储结构(比如MYSQL):
- 在插入过程中动态保持有序
- 把数组拆成多个小段,把小段作 为叶节点用 B+Tree 组织起来,让插入过程代价尽量小
- 每小段(也就是叶节点)是一个有序数组,插入数据时只需要移动插入点之后的数据,大大减少移动量
B+ Tree的灵魂基本就是上述的大叶节点树。具体细节可参考https://blog.csdn.net/b_x_p/article/details/86434387
存储引擎的持久化
为了保证比如关机重启之后数据仍然可以继续使用,我们需要把数据保存到硬盘上。但硬盘有以下几个特点:
- 速度比内存慢啊......
- 连续写入比随机写入快很多
因此硬盘上存储引擎的设计和之前要截然不一样。WAL(Write Ahead Log)就是一种成熟的解决方案。它是一种异构镜像方案(也叫做semi-DB):
- 异构:磁盘与内存的数据结构不一样。磁盘使用局部性高的结构,内存可以是任意结构
- 镜像:逻辑上两边的数据等价
- 用户进行写操作时,内存和WAL都写入。读操作时从内存读取。存储引擎重启时重新执行WAL里记录的所有写操作,恢复内存数据结构。
前面说的好抽象啊......其实WAL可以理解成是一个log文件,写 WAL 都在末尾追加写入,顺序地记录所有修改动作(类比数据库系统的日志)。为了存盘数据的安全,避免进程非正常退出丢数据,WAL 一般每次写完数据都执行 fsync 操作,否则数据可能还留在操作系统的 Page Cache 中没有写到盘上(不实时fsync会有丢失数据的风险,但fsync很占磁盘资源,可能成为性能瓶颈。因此数据库系统会提供参数设置fsync的频率)
WAL工作时其实就是[傻傻的]依次记录每次的写操作,但这样效率也不高:1. WAL 中可能存在相同 key 的多次 Write 的多个版本的数据,占用了 额外空间,也降低重放性能。2. WAL中记录的写入操作太多时,整体效率也会降低。 为解决这些问题,我们可以设计一个机制,在某些特定的时刻将WAL记录的所有操作做成一个快照(即相当于提前执行了到目前为止所有的WAL record,并将数据存盘)。这样既提高了重启时重放WAL的效率,也节省了空间。这个机制就叫做Compaction。compaction过程会占用一些IO资源,比如用户只插入了k GB的数据,由于compaction的存在,硬盘总共会执行大于k GB的IO写操作。这个问题就叫做写放大。假如硬盘是SSD,写放大太严重就会影响硬盘的寿命。compaction其实就是以写放大作为代价,换取更好的读取性能。
按照上面的方案让WAL和内存中的B+ tree配合,看起来就很完美啦!但是别忘了内存空间是有限的,不可能所有的写操作都能丢进内存。所以内存中就只能存放部分数据(相当于一个cache),硬盘中才存放所有数据。
另外,从硬盘向内存读数据也是需要较好的局部性的(还记得连续写入比随机写入快得多嘛?)。因此在实际操作时,我们在硬盘的WAL中,以B+tree中的叶节点大小作为单位存储,为B+tree的每个叶节点都启用WAL。内存中的B+tree在读取时,遇到当前不在内存的叶节点时,就去硬盘加载(类似于虚拟内存中遇到缺页中断的处理机制)。如图所示:
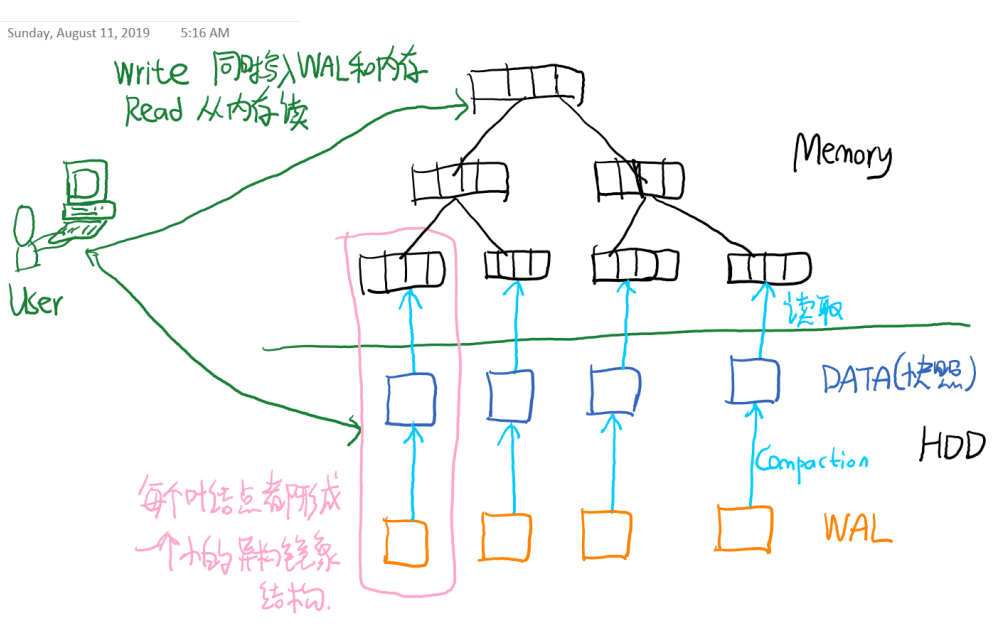
上图的结构中,B+ tree的每个叶子节点都有一个WAL。当叶子节点很多的时候这样也不大好....如果compaction的频率很高,而且WAL做compaction时,数据可以从内存获得,那么真正需要从WAL读数据的机会就很少。这样我们可以把一些叶子节点的WAL合并起来,以提高局部性。(具体实现暂时略)
B+ tree存储引擎分析与改进
经过上面这一顿操作后,我们暂时就有了这样一个存储引擎:
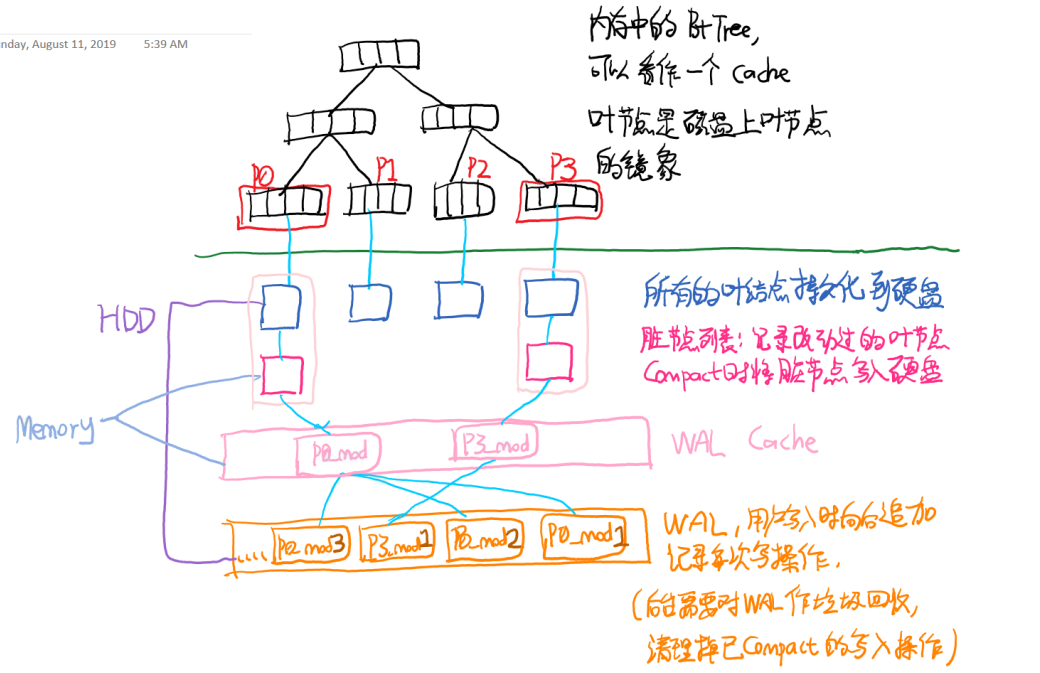
这个模型就很好了咩?我们来分析一下:
- Write 很快:
- 查找写入位置,性能为 O(Log2 n)
- Append 到 WAL,性能为 O(1)
- 更新到叶节点,性能可能略差但:○ 是内存操作 ○ 可以异步操作
- Scan / Read 很快:
- 在 B+Tree 中查找,性能接近 O(Log2 n)
- 如果数据所在的叶节点:
- 在内存,完成读取
- 不在内存,加载相关叶节点,再从中查找。有磁盘 IO、磁盘读放大(定义和写放大类似,表示 [系统实际硬盘读IO数量]大于[用户在前台需要读的数据总量])
另外,如果有奇怪的用户在不同的key值域上随机写入(可能每个key值域上写入量很小,但会写很多不同的key值域),那么WriteCache就很难覆盖所有用户写过的key值域。为了腾出writecache,叶节点必须在修改占比还很小的时候,就compact写盘。在这种情况下会造成巨大的写放大,还会造成写盘次数相对于总写入量过多(全是分散IO,写入效率就比较低)。其根本原因是B+tree中,每个叶子节点覆盖的key范围太小啦。而且存量数据越大,叶节点的key覆盖范围越窄。
另外,B+ tree的叶节点是分散存储在硬盘上的,也导致多次IO之间不存在连续性。
那么怎么办捏?我们可以用另一种局部性好的有序结构,叫做LSM Tree。这也就是RocksDB所用的结构。
LSM Tree
LSM Tree长酱紫:
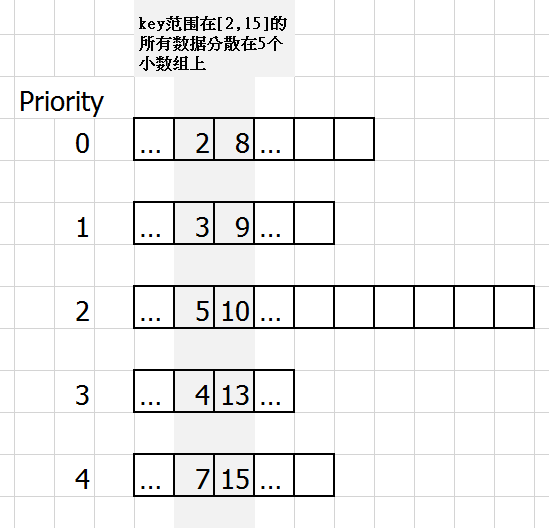
各个小有序数组的key覆盖范围是相互重叠的,它们合并起来可以看做一个大的虚拟有序数组。同时因为范围是重叠的,因此某个key有可能会在多个小数组上都存在,因此不同数组设置了不同的优先级。
这样设计既采纳了B+Tree中将数组分散存储以防止写开销太大的问题,又可以保证每个小数组都有局部性。
LSM Tree的Read操作:最简单的思路是按优先级从高到低,二分查找每个小数组。但这样会存在读放大问题(找了好多次才找到对应的小数组)。为解决这一问题,我们可以在数组生成时,对每个小数组都做一个Bloom Filter(可以理解为一个高效率的hashset)来记录当前小数组里都有哪些key。在读操作时先查Bloom Filter,如果不存在就不需要二分查找这个小数组了。
注意如果要读取暂存在硬盘上的小有序数组:因为这个数组还是比较大的,所以不能像B+Tree那样直接全load到内存再二分查找。对于硬盘上的数组文件,可以把它分成多个小的block。维护一个Bloom Filter记录每个key在哪个block,还有一个索引记录每个block的范围信息[begin, end]。读取到内存时以block作为单位。
LSM Tree的Scan操作:找到所有覆盖了begin、end范围的小数组,然后进行多路合并(merge k sorted array)。对于重复的key,取优先级高的数组里的元素。
LSM Tree的Write操作:分为两部分: 1. 纯内存的LSM Tree:write只插入到最上层的有序结构(最上层使用其他的有序结构而不是小有序数组啦,来避免插入时要移动其他元素的问题)。当最上层过大时将最上层下移一层,然后生成一个新的最上层。(这样一来,前面的优先级其实就成了根据写入时间从新到旧排序啦) 2. 磁盘的LSM Tree的write:和内存的基本一致,只是为最上层的有序结构加一个WAL防止数据丢失。
LSM Tree的Compaction
前面说到write会不停产生新数组,而数组个数太多了会影响scan/read的性能,因此LSM Tree也需要Compaction操作,把若干个小数组合并成一个新的有序数组,从而控制数组的个数不能太多。
- 在Compaction的过程中,每个新写下来、未经 Compact 的数组文件的大小是固定的(取决于 WriteBuffer 的大小),我们把它叫做 L0 文件。
- Compact 后的结果是 L0 的倍数。因此可以指定 L0 文件 Size = 1,为 L0 的 x 倍大小的文件则 Size = x
- 很容易推算出:优先 Compact 最小体积的数组可以最低成本地减少总数组个数。因此 Compation 总是从 L0 层开始,按文件体积从小到大地进行。
- 为了保证 Compact 后仍旧有明确的新旧排序,要求参与 Compaction 的数组是连续相邻的。否则数组之间的写入时间会产生重叠:导致读取时,无法以优先级进行 key 排重
- LSM Tree的过程中也会产生写放大。而且参与 Compaction 的输入数据通常不在内存,需要从磁盘上读起来,所以还会有IO读和cpu消耗。
LSM Tree有很多种Compaction策略。最简单的策略就是把相邻T层的数组进行合并。由于Compaction的次数不同,就会形成相应的多层结构。如下图(这里T=3)
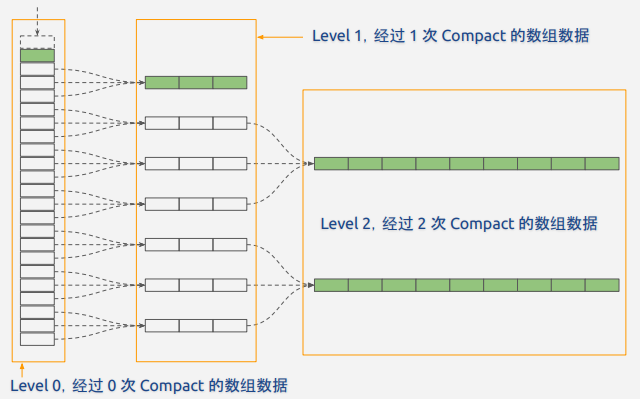
(上面只是一个最简单的Compaction策略,具体优化以及在RocksDB中的实现还涉及很多细节,暂时忽略)
RocksDB中的LSM Tree
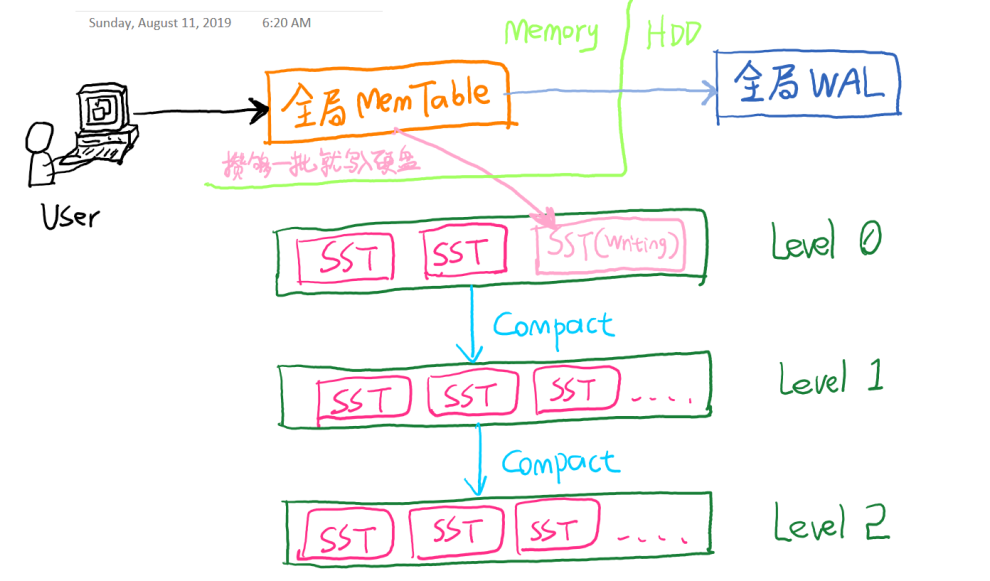
上图中,SST相当于之前提到的小有序数组,MemTable相当于LSM Tree的数据在内存中的Cache。
每层Level的意义相当于对数据按新旧顺序进行了时域切割。如下图:
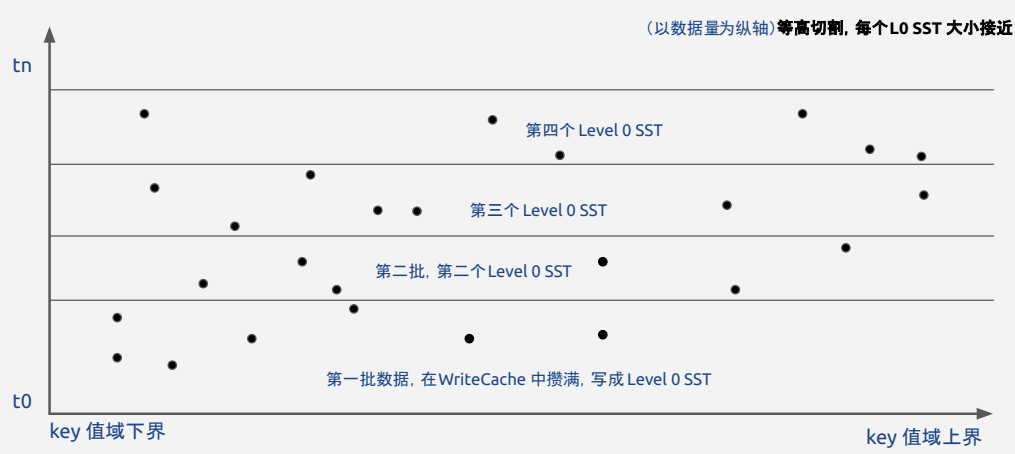
LSM Tree解决了B+Tree中攒批不足带来的写放大(参考B+Tree那一段中 某个奇怪的用户的操作) ,但带来的代价就是层层Compaction带来的新的写放大。所以说一个复杂的系统需要大量的取舍和平衡叭
1. 简介
RocksDB的项目起源于Facebook的一个实验,希望能够开发一个高效的数据库实现能够在快速存储设备(特别是Flash)上存储数据并服务服务器的负载,同时完全挖掘这类存储设备的潜能。RocksDB是一个C++库用于存储kv数据并且支持原子读写。RocksDB实现了在配置上的较高的灵活性并且可以运行到各种生产环境中,包括纯内存、Flash、HDD或者HDFS。RocksDB支持多种压缩算法以及多种工具用于生产支持以及debug。RocksDB借用了许多LevelDB的代码以及Apache HBase中的思想。最初是基于LevelDB1.5开发。
RocksDB是一个嵌入式的K-V(任意字节流)存储。所有的数据在引擎中是有序存储,可以支持Get(key)、Put(Key)、Delete(Key)和NewIterator()。RocksDB的基本组成是memtable、sstfile和logfile。
- memtable是一种内存数据结构,写请求会先将数据写到memtable中,然后可选地写入logfile。
- logfile是一个顺序写的文件。当内存表溢出的时候,数据会flush到sstfile中,然后这个memtable对应的logfile也会安全地被删除。
- sstfile中的数据也是有序存储以方便查找。
RocksDB中的key和value完全是byte stream,key和value的大小没有任何限制。Get接口提供用户一种从DB中查询key对应value的方法,MultiGet提供批量查询功能。DB中的所有数据都是按照key有序存储,其中key的compare方法可以用户自定义。Iterator方法提供用户RangeScan功能,首先seek到一个特定的key,然后从这个点开始遍历。Iterator也可以实现RangeScan的逆序遍历,当执行Iterator时,用户看到的是一个时间点的一致性视图。
Fault Torlerance
RocksDB通过checksum来检测磁盘数据损坏。每个sst file的数据块(4k-128k)都有相应的checksum值。写入存储的数据块内容不允许被修改。
Multi-Threaded Compactions
当用户重复写入一个key时,在DB中会存在这个key的多个value,compaction操作就是来删除这个key的冗余数据。当一个key被删除时,compation也可以用来真正执行这个底层数据的删除工作,如果用户配置合适的话,compation操作可以多线程执行。DB的数据都存储在sstfile中,当内存表的数据满的时候,会将内存数据(去重、删除无效数据后)写入到L0 文件中。每隔一段时间小文件中的数据会重新merge到更大的文件中,这就是compation。LSM引擎的写吞吐直接依赖于compation的性能,特别是数据存储在SSD或者RAM的情况。
RocksDB也支持多线程并行compaction。后台的compaction线程用来将内存数据flush到存储,当所有的后台线程都正在执行compaction时,瞬时大量写操作会很快将内存表写满,这就会引起写停顿。可以配置少一些的线程用于执行数据flush操作,
Block Cache -- Compressed and Uncompressed Data
RocksDB使用LRU cache提供block的读服务。block cache partition为两个独立的cache,其中一块可以cache未压缩RAM数据,另一块cache 压缩RAM数据。如果压缩cache配置打开的话,用户一般会开启direct io,以避免OS的也缓存重新cache相同的压缩数据。
可用配置
不论是在option string还是option map中,option name是目标类中的变量名,这些包括:DBOptions, ColumnFamilyOptions, BlockBasedTableOptions, or PlainTableOptions。DBOptions and ColumnFamilyOptions中的变量名和变量描述信息可以在options.h中找到,BlockBasedTableOptions, and PlainTableOptions中的变量信息可以在table.h中找到。需要注意的是,尽管绝大部分的配置项都可以在option string和option map中支持,仍然有一些例外。RocksDB支持的所有配置项可以在db_options_type_info, cf_options_type_info and block_based_table_type_info中查阅,源文件是util/options_helper.h。
LSM-Tree
RocksDB 是基于 LSM-Tree 的,大概如下

sst文件是在硬盘上的。SST files按照key 排序,且每个文件的key range互相不重叠。为了check一个key可能存在于哪一个一个SST file中,RocksDB并没有依次遍历每一个SST file然后去检查key是否在这个file的key range 内,而是执行二分搜索算法(FileMetaData.largest )去定位这个SST file。(更详细可以参考https://yq.aliyun.com/articles/669316)
首先,任何的写入都会先写到 WAL,然后在写入 Memory Table(Memtable)。当然为了性能,也可以不写入 WAL,但这样就可能面临崩溃丢失数据的风险。Memory Table 通常是一个能支持并发写入的 skiplist,但 RocksDB 同样也支持多种不同的 skiplist,用户可以根据实际的业务场景进行选择。
当一个 Memtable 写满了之后,就会变成 immutable 的 Memtable,RocksDB 在后台会通过一个 flush 线程将这个 Memtable flush 到磁盘,生成一个 Sorted String Table(SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会通过 Compaction 策略将其放到 Level 1 层,以此类推。
这里关键就是 Compaction,如果没有 Compaction,那么写入是非常快的,但会造成读性能降低,同样也会造成很严重的空间放大问题。为了平衡写入,读取,空间这些问题,RocksDB 会在后台执行 Compaction,将不同 Level 的 SST 进行合并。但 Compaction 并不是没有开销的,它也会占用 I/O,所以势必会影响外面的写入和读取操作。
对于 RocksDB 来说,他有三种 Compaction 策略,一种就是默认的 Leveled Compaction,另一种就是 Universal Compaction,也就是常说的 Size-Tired Compaction,还有一种就是 FIFO Compaction。对于 FIFO 来说,它的策略非常的简单,所有的 SST 都在 Level 0,如果超过了阈值,就从最老的 SST 开始删除,其实可以看到,这套机制非常适合于存储时序数据。
实际对于 RocksDB 来说,它其实用的是一种 Hybrid 的策略,在 Level 0 层,它其实是一个 Size-Tired 的,而在其他层就是 Leveled 的。
这里在聊聊几个放大因子,对于 LSM 来说,我们需要考虑写放大,读放大和空间放大,读放大可以认为是 RA = number of queries * disc reads,譬如用户要读取一个 page,但实际下面读取了 3 个 pages,那么读放大就是 3。而写放大则是 WA = data writeen to disc / data written to database,譬如用户写入了 10 字节,但实际写到磁盘的有 100 字节,那么写放大就是 10。而对于空间放大来说,则是 SA = size of database files / size of databases used on disk,也就是数据库可能是 100 MB,但实际占用了 200 MB 的空间,那么就空间放大就是 2。
2. compaction
LSM-Tree 能将离散的随机写请求都转换成批量的顺序写请求(WAL + Compaction),以此提高写性能。但也带来了一些问题:
- 读放大(Read Amplification)。LSM-Tree 的读操作需要从新到旧(从上到下)一层一层查找,直到找到想要的数据。这个过程可能需要不止一次 I/O。特别是 range query 的情况,影响很明显。
- 空间放大(Space Amplification)。因为所有的写入都是顺序写(append-only)的,不是 in-place update ,所以过期数据不会马上被清理掉。
RocksDB 和 LevelDB 通过后台的 compaction 来减少读放大(减少 SST 文件数量)和空间放大(清理过期数据),但也因此带来了写放大(Write Amplification)的问题。
- 写放大。实际写入 HDD/SSD 的数据大小和程序要求写入数据大小之比。正常情况下,HDD/SSD 观察到的写入数据多于上层程序写入的数据。
在 HDD 作为主流存储的时代,RocksDB 的 compaction 带来的写放大问题并没有非常明显。这是因为:
- HDD 顺序读写性能远远优于随机读写性能,足以抵消写放大带来的开销。
- HDD 的写入量基本不影响其使用寿命。
现在 SSD 逐渐成为主流存储,compaction 带来的写放大问题显得越来越严重:
- SSD 顺序读写性能比随机读写性能好一些,但是差距并没有 HDD 那么大。所以,顺序写相比随机写带来的好处,能不能抵消写放大带来的开销,这是个问题。
- SSD 的使用寿命和其写入量有关,写放大太严重会大大缩短 SSD 的使用寿命。因为 SSD 不支持覆盖写,必须先擦除(erase)再写入。而每个 SSD block(block 是 SSD 擦除操作的基本单位) 的平均擦除次数是有限的。
所以,在 SSD 上,LSM-Tree 的写放大是一个非常值得关注的问题。而写放大、读放大、空间放大,三者就像 CAP 定理一样,需要做好权衡和取舍。
Ref:https://cloud.tencent.com/developer/article/1352666
RocksDB 的写放大分析:
+1 - redo log 的写入
+1 - Immutable Memtable 写入到 L0 文件
+2 - L0 和 L1 compaction(L0 SST 文件的 key 范围是重叠的,出于性能考虑,一般尽量保持 L0 和 L1 的数据大小是一样的,每次拿全量 L0 的数据和全量 L1 的数据进行 compaction)
+11 - Ln-1 和 Ln 合并的写入(n >= 2,默认情况下,Ln 的数据大小是 Ln-1 的 10 倍,见max_bytes_for_level_multiplier )。
所以,总的写放大是 4 + 11 * (n-1) = 11 * n - 7 倍。关键是 n 的取值。
假设 max_bytes_for_level_multiplier 取默认值 10,则 n 的取值受 L1 的大小和 LSM-Tree 的大小影响。
L1 的大小由 max_bytes_for_level_base 决定,默认是 256 MB。
默认情况下 L0 的大小和 L1 一样大,也是 256 MB。不过 L0 比较特殊,当 L0 的 SST 文件数量达到 level0_file_num_compaction_trigger 时,触发 L0 -> L1 的 comapction。所以 L0 的最大大小为 write_buffer_size * min_write_buffer_number_to_merge * level0_file_num_compaction_trigger。
write_buffer_size 默认 64 MB
min_write_buffer_number_to_merge 默认 1
level0_file_num_compaction_trigger 默认 4
所以 L0 默认最大为 64 MB * 1 * 4 = 256 MB
因此,RocksDB 每一层的默认大小为 :
L0 - 256 MB
L1 - 256 MB
L2 - 2.5 GB
L3 - 25 GB
L4 - 250 GB
L5 - 2500 GB
Tiered Compaction vs Leveled Compaction
大家应该都知道,对于 LSM 来说,它会将写入先放到一个 memtable 里面,然后在后台 flush 到磁盘,形成一个 SST 文件,这个对写入其实是比较友好的,但读取的时候,很可能会遍历所有的 SST 文件,这个开销就很大了。同时,LSM 是多版本机制,一个 key 可能会被频繁的更新,那么它就会有多个版本留在 LSM 里面,占用空间。
为了解决这两个问题,LSM 会在后台进行 compaction,也就是将 SST 文件重新整理,提升读取的性能,释放掉无用版本的空间,通常,LSM 有两种 Compaction 方式,一个就是 Tiered,而另一个则是 Leveled。

上图是两种 compaction 的区别,当 Level 0 刷到 Level 1,让 Level 1 的 SST 文件达到设定的阈值,就需要进行 compaction。对于 Tiered 来说,我们会将所有的 Level 1 的文件 merge 成一个 Level 2 SST 放在 Level 2。也就是说,对于 Tiered 来说,compaction 其实就是将上层的所有小的 SST merge 成下层一个更大的 SST 的过程。
而对于 Leveled 来说,不同 Level 里面的 SST 大小都是一致的,Level 1 里面的 SST 会跟 Level 2 一起进行 merge 操作,最终在 Level 2 形成一个有序的 SST,而各个 SST 不会重叠。
上面仅仅是一个简单的介绍,大家可以参考 ScyllaDB 的两篇文章 Write Amplification in Leveled Compaction,Space Amplification in Size-Tiered Compaction,里面详细的说明了这两种 compaction 的区别。
3. Block Cache
Block Cache是RocksDB把数据缓存在内存中以提高读性能的一种方法。开发者可以创建一个cache对象并指明cache capacity,然后传入引擎中。cache对象可以在同一个进程中供多个DB Instance使用,这样开发者就可以通过配置控制所有的cache使用。Block cache存储的是非压缩的数据块内容。用户也可以设置另外一个block cache来存储压缩数据块。读数据时首先从非压缩数据块cache中读数据、然后读压缩数据块cache。当Direct-IO打开的话,压缩数据库可以作为系统页缓存的替代。RocksDB中有两种cache的实现方式,分别为LRUCache和CLockCache。这两种cache都会被分片,来降低锁压力。用户设置的容量平均分配给每个shard。默认情况下,每个cache都会被分片为64块,每块大小不小于512K字节。
LRU Cache
默认情况,RocksDB使用LRU Cache,默认大小为8M。cache的每个分片都有自己的LRU list和hash表来查找使用。每个shard都有个mutex来控制数据并发访问。不管是数据查找还是数据写入,线程都要获取cache分片的锁。开发中也可以调用NewLRUCache()来创建一个LRU cache。这个函数提供了几个有用的配置项来设置cache:
Capacity cache的总大小
num_shard_bits 去cache key的多少字节来选择shard_id。cache将会被分片为2^num_shard_bits
strict_capacity_limit 很少会出现block cache的size超过容量的情况,这种情况发生在持续不断的read or iteration 访问block cache,pinned blocks的总大小会超过容量。如果有更多的读请求将block数据写入block cache时,且strict_capacity_limit=false(default),cache服务会不遵循容量限制并允许写入。如果host没有足够内存的话,就会导致DB instance OOM。如果将这个配置设置为true,就可以拒绝将更多的数据写入cache,fail掉那些read or iterator。这个参数配置是以shard为控制单元的,所以会出现某一个shard在capcity满时拒绝继续写入cache,而另一个shard仍然有extra unpinned space。
high_pri_pool_ratio 为高优先级block预留的capacity 比例
Clock Cache
ClockCache实现了CLOCK算法。CLOCK CACHE的每个shard都有一个cache entry的圆环list。算法会遍历圆环的所有entry寻找unspined entry来回收,但是如果上次scan操作这个entry被使用的话,也会有继续留在cache中的机会。寻找并回收entry使用tbb::concurrent_hash_map。
使用LRUCache的一个好处是有一把细粒度的锁。在LRUCache中,即使是查找操作也需要获取分片锁,因为有可能会更改LRU-list。在CLock cache中查找并不需要获取分片锁,只需要查找当前hash_map就可以了,只有在insert时需要获取分片锁。使用clock cache,相比于LRU cache,写吞吐有一定提升。
当创建clock cache时,也有一些可以配置的信息。
Capacity same as LRUCache
num_shard_bits same as LRUCache
strict_capacity_limit same as LRUCache
Simulated Cache
SimCache是当cache capacity或者shard num发生改变时预测cache hit的方法。SimCache封装了真正的Cache 对象,运行一个shadow LRU cache模仿具有同样capacity和shard num的cache服务,检测cache hit和miss。这个工具在下面这种情况很有用,比如:开发者打开了一个DB 实例,配置了4G的cache size,现在想知道如果将cache size调整到64G时的cache hit。
SimCache的基本思想是根据要模拟的容量封装正常的block cache,但是这个封装后的block cache只有key,没有value。当插入数据时,把key插入到两个cache中,但是value只插入到normal cache。value的size会在两种cache中都计算进去,但是SimCache中因为只有key,所以并没有占用那么多的内存,但是以此却可以模拟block cache的一些行为。
4. MemTable
MemTable是一种在内存中保存数据的数据结构,然后再在合适的时机,MemTable中的数据会flush到SST file中。MemTable既可以支持读服务也可以支持写服务,写操作会首先将数据写入Memtable,读操作在query SST files之前会首先从MemTable中query数据(因为MemTable中的数据一直是最新的)。
一旦MemTable满了,就会转换为只读的不可改变的,然后会创建一个新的MemTable来提供新的写操作。后台线程负责将MemTable中的数据flush到SST file,然后这个MemTable就会被销毁。
重要的配置:
memtable_factory:memtable的工厂对象。通过这个工厂对象,用户可以改变memtable的底层实现并提供个性化的实现配置。
write_buff_size :单个内存表的大小限制
db_write_buff_size: 所有列族的内存表总大小。这个配置可以管理内存表的总内存占用。
write_buffer_manager : 这个配置不是管理所有memtable的总内存占用,而是,提供用户自定义的write buffer manager来管理整体的内存表内存使用。这个配置会覆盖db_write_buffer_size。
max_write_buffer_number:内存表的最大个数
memtable的默认实现是skiplist。除了默认memtable实现外,用户也可以使用其他类型的实现方法比如 HashLinkList、HashSkipList or Vector 来提高查询性能。
Skiplist MemTable
基于Skiplist的memtable在支持读、写、随机访问和顺序scan时提供了较好的性能。此外,还支持了一些其他实现不能支持的feature比如concurrent insert和 insert with hint。
HashSkiplist MemTable
如其名,HashSkipList是在hash table中组织数据,hash table中的每个bucket都是一个skip list,HashLinkList也是在hash table中组织数据,但是每一个bucket是一个有序的单链表。这两种结构实现目的都是在执行query操作时可以减少比较次数。一种使用场景就是把这种memtable和PlainTable SST格式结合在一起,然后将数据保存在RAMFS中。当执行检索或者插入一个key时,key的前缀可以通过Options.prefix_extractor来检索,之后就找到了相应的hash bucket。进入到 hash bucket内部后,使用全部的key数据来进行比较操作。使用hash实现的memtable的最大限制是:当在多个key前缀上执行scan操作需要执行copy和sort操作,非常慢且很耗内存。
flush
在以下三种情况下,内存表的flush操作会被触发:
- 内存表大小超过了write_buffer_size
- 全部列族的所有内存表大小超过了db_write_buffer_size,或者wrtie_buffer_manager发出了flush的指令。这种情况下,最大的内存表会被选择进行flush操作。
- 全部的WAL文件大小超过max_total_wal_size。在这种场景下,内存中数据最老的内存表会被选择执行flush操作,然后这个内存表对应的WAL file会被回收。
所以,内存表也可以在未满时执行flush操作。这也是产生的SST file比对应的内存表小的一个原因,压缩是是另一个原因(内存表总的数据是没有压缩的,SST file是压缩过的)。
Concurrent Insert
如果不支持concurrent insert to memtable的话,来自多个线程的concurrent 写会顺序地写入memtable。默认是打开concurrent insert to memtable,也可以通过设置allow_concurrent_memtable_write来关闭。
5. Write Ahead Log
对RocksDB的每一次update都会写入两个位置:1) 内存表(内存数据结构,后续会flush到SST file) 2)磁盘中的write ahead log(WAL)。在故障发生时,WAL可以用来恢复内存表中的数据。默认情况下,RocksDB通过在每次用户写时调用fflush WAL文件来保证一致性。
6. Write Buffer Manager
Write buffer mnager帮助开发者管理列族或者DB instance的内存表的内存使用。
- 管理内存表的内存占用在阈值内
- 内存表的内存占用转移到block cache
Write buffer manager与rate_limiter和sst_file_manager类似。用户创建一个write buffer manager对象,传入 column family或者DBs的配置中。可以参考write_buffer_manager.h的注释部分来学习如何使用。
Limit total memory of memtables
在创建write buffer manager对象时,内存限制的阈值就已经确定好了。RocksDB会按照这个阈值去管理整体的内存占用。
在5.6或者更高版本中,如果整体内存表使用超过了阈值的90%,就会触发正在写入的某一个column family的数据执行flush动作。如果DB instance实际内存占用超过了阈值,即使全部的内存表占用低于90%,那也会触发更加激进的flush动作。在5.6版本以前,只有在内存表内存占用的total超过阈值时才会触发flush。
在5.6版本及更新版本中,内存是按照arena分配的total内存计数的,即使这些内存不是被内存表使用。在5.6之前版本中,内存使用是按照内存表实际使用的内存
Cost memory used in memtable to block cache
从5.6版本之后,用户可以将内存表的内存使用的占用转移到block cache。不管是否打开内存表的内存占用,都可以这样操作。
大部分情况下,block cache中实际使用的blocks远比block cache中的数据少很多,所以如果用户打开了这个feature后,block cache的容量会覆盖掉block cache和内存表的内存占用。如果用户打开了cache_index_and_filter_blocks的话,这三种内存占用都在block cache中。
具体实现如下,针对内存表分配的每一个1M内存,WriteBufferManager都会在block cache中put一个dummy 1M的entry,这样block cache就可以正确的计算内部占用,而且可以在需要时淘汰掉一些block以便腾出内存空间。如果内存表的内存占用降低了,WriteBufferManager也不会立马三除掉dummmy blocks,而是在后续慢慢地释放掉。这是因为内存表空间占用的up and down太正常不过了,RocksDB不需要对此太过敏感。
- 把使用的block cache传递给WriteBufferManager
- 把WriteBufferManager的参数传入RocksDB内存表占用的最大内存
- 把block cache的容量设置为 data blocks和memtables的内存占用总和
7. ycsb
YCSB, 英文全称:Yahoo! Cloud Serving Benchmark (YCSB) 。是 Yahoo 公司的一个用来对云服务进行基础测试的工具, 目标是促进新一代云数据服务系统的性能比较。由于它集成了大多数常用的数据库的测试代码,所以,它也是数据库测试的一大利器.
1. 核心YCSB属性
所有工作量文件可以指定以下属性:
workload:要使用的工作量类(例如com.yahoo.ycsb.workloads.CoreWorkload)
db:要使用的数据库类。可选地,这在命令行可以指定(默认:com.yahoo.ycsb.BasicDB)
exporter:要是用的测量结果的输出类(默认:com.yahoo.ycsb.measurements.exporter.TextMeasurementsExporter)
exportfile:用于替代stdout的输出文件路径(默认:未定义/输出到stdout)
threadcount:YCSB客户端的线程数。可选地,这可以在命令行指定(默认:1)
measurementtype:支持的测量结果类型有直方图和时间序列(默认:直方图)
2. 核心工作量包属性
和核心工作量构造器一起使用的属性文件可以指定以下属性的值:
fieldcount:一条记录中的字段数(默认:10) (字段的意义类似于关系数据库中表的每一列)
fieldlength:每个字段的大小(默认:100)
readallfields:是否应该读取所有字段(true)或者只有一个字段(false)(默认:true)
readproportion:读操作的比例(默认:0.95)
updateproportion:更新操作的比例(默认:0.05)
insertproportion:插入操作的比例(默认:0)
scanproportion:遍历操作的比例(默认:0)
readmodifywriteproportion:读-修改-写一条记录的操作的比例(默认:0)
requestdistribution:选择要操作的记录的分布——均匀分布(uniform)、Zipfian分布(zipfian)或者最近分布(latest)(默认:uniform)
maxscanlength:对于遍历操作,最大的遍历记录数(默认:1000)
scanlengthdistribution:对于遍历操作,要遍历的记录数的分布,在1到maxscanlength之间(默认:uniform)
insertorder:记录是否应该有序插入(ordered),或者是哈希顺序(hashed)(默认:hashed)
operationcount:要进行的操作数数量
maxexecutiontime:最大的执行时间(单位为秒)。当操作数达到规定值或者执行时间达到规定最大值时基准测试会停止。
table:表的名称(默认:usertable)
recordcount:装载进数据库的初始记录数(默认:0)
3. 测量结果属性
这些属性被应用于每一个测量结果类型:
直方图
histogram.buckets:直方图输出的区间数(默认:1000)
时间序列
timeseries.granularity:时间序列输出的粒度(默认:1000)
另外还有两个重要的option:
delayed_write_rate:参考https://github.com/facebook/rocksdb/wiki/Write-Stalls。
RocksDB has extensive system to slow down writes when flush or compaction can't keep up with the incoming write rate. Without such a system, if users keep writing more than the hardware can handle, the database will:
- Increase space amplification, which could lead to running out of disk space;
- Increase read amplification, significantly degrading read performance.
The idea is to slow down incoming writes to the speed that the database can handle.
Whenever stall conditions are triggered, RocksDB will reduce write rate to delayed_write_rate, and could possiblely reduce write rate to even lower than delayed_write_rate if estimated pending compaction bytes accumulates. One thing worth to note is that slowdown/stop triggers and pending compaction bytes limit are per-column family, and write stalls apply to the whole DB, which means if one column family triggers write stall, the whole DB will be stalled.
对于全是写的workload,delayed_write_rate肯定是越大越好。对于全是读/读写混合的workload,应该是设置为某个值比较好(因为有read amplification)
target_file_size_base:这个是在Level Style Compaction中会用到的。target_file_size_base and target_file_size_multiplier -- Files in level 1 will have target_file_size_base bytes. Each next level's file size will be target_file_size_multiplier bigger than previous one. However, by default target_file_size_multiplier is 1, so files in all L1..Lmax levels are equal. Increasing target_file_size_base will reduce total number of database files, which is generally a good thing. We recommend setting target_file_size_base to be max_bytes_for_level_base / 10, so that there are 10 files in level 1.
Ref:
Tuning RocksDB – Options https://www.jianshu.com/p/8e0018b6a8b6
https://www.jianshu.com/u/aa9cae571502
https://www.jianshu.com/p/9b7437b5ea5b
https://zhuanlan.zhihu.com/p/37193700
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
posted on 2019-08-12 08:37 Pentium.Labs 阅读(19937) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
