
结对第二次作业——某次疫情统计可视化的实现
作业概况
| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 结对学号 | 221701104,221701116 |
| 这个作业的目标 | 完成疫情webapp的基础功能包括: 显示全国地图数据,点击省份可以显示具体的变化趋势 |
| 作业正文 | 作业正文 |
| 其他参考文献 | ... |
giithub地址
成品展示
作业链接(服务器带宽很小,渲染和加载需要时间)
接口可能会因为不稳定导致获取不到数据,可将index.js中获取接口的.ajax的url更换为https://lab.ahusmart.com/nCoV/api/area进行尝试。(2020/3/19)
以上链接可能由于API的不稳定而失效,如果失效,请使用下面的链接(2020/3/22)
作业链接
此作业链接对应github中release的1.0.1版本
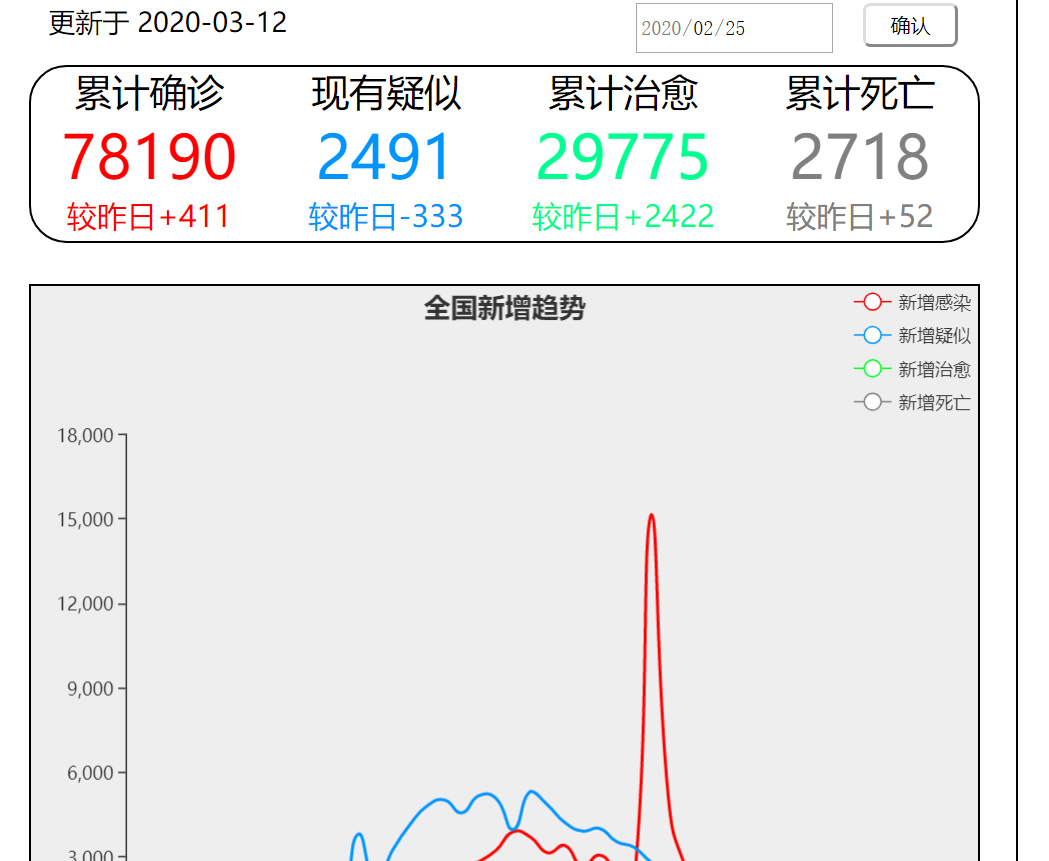
一、主页
1、在页面的左上角有个“首页”的标志,点击能够返回主页(也就是下方图片显示的页面)
2、点击全国趋势查看全国数据以及全国新增趋势图
3、时间戳会根据当天时间实时更新,地图采用API接口,也会实时更新数据
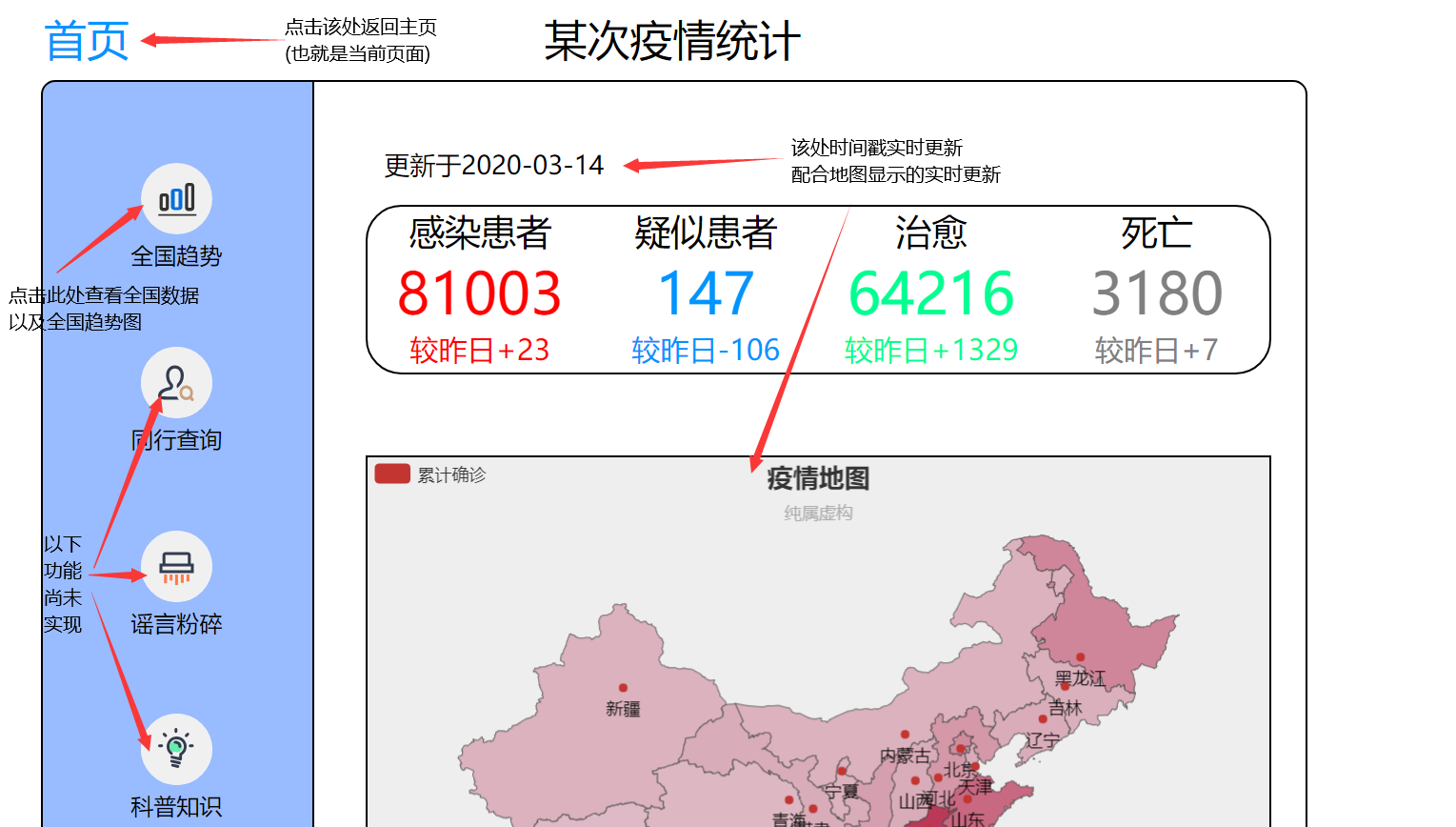
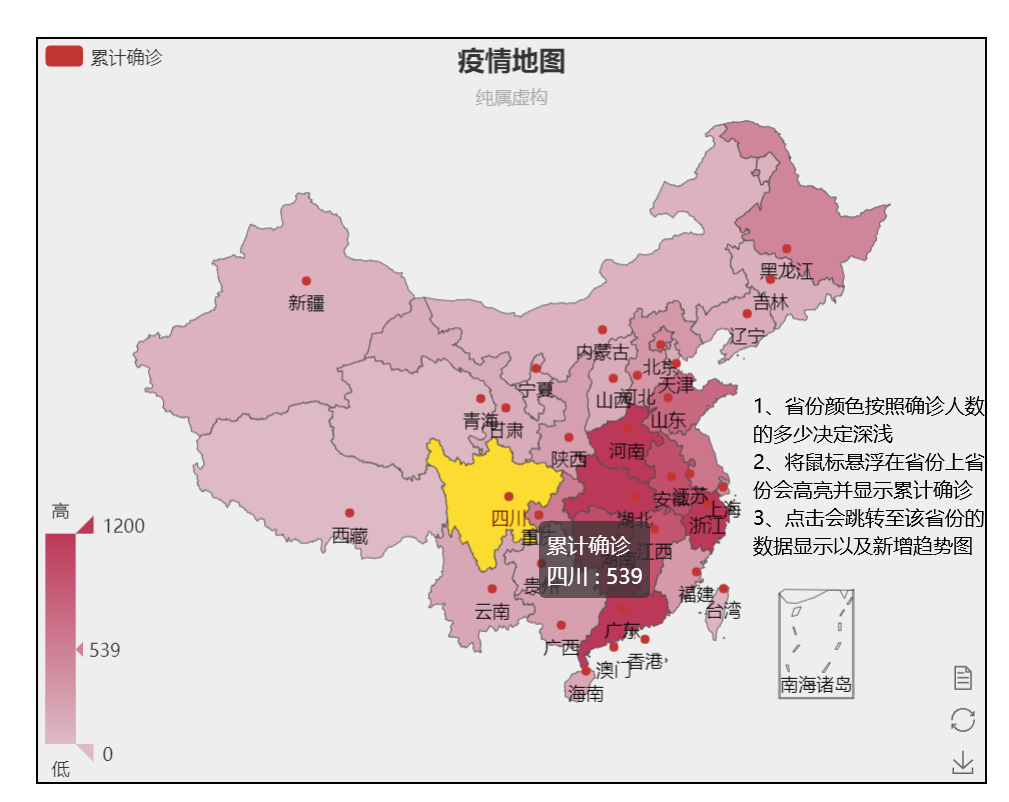
4、省份区块的颜色按照累计确诊人数的多少决定颜色的深浅
5、将鼠标悬浮在省份上,该省份区块会高亮显示并显示累计确诊人数(如下图)
6、点击该省份区块,会跳转至该省份数据显示以及新增趋势图的页面
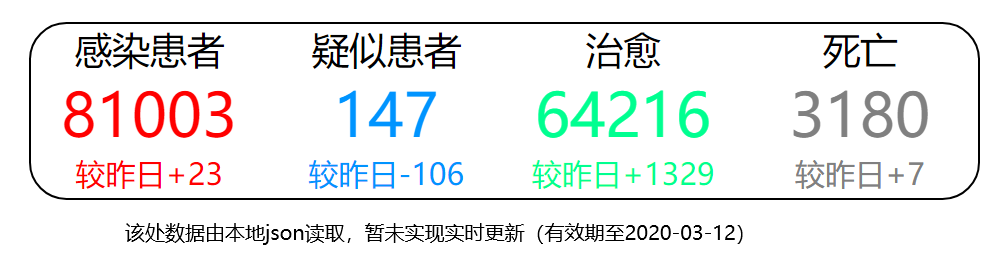
7、由于全国数据部分(上半部分,非地图数据)是将爬取的数据转化成json文件读取,所以暂时未能实现实时更新,文件最新日期为2020-03-12
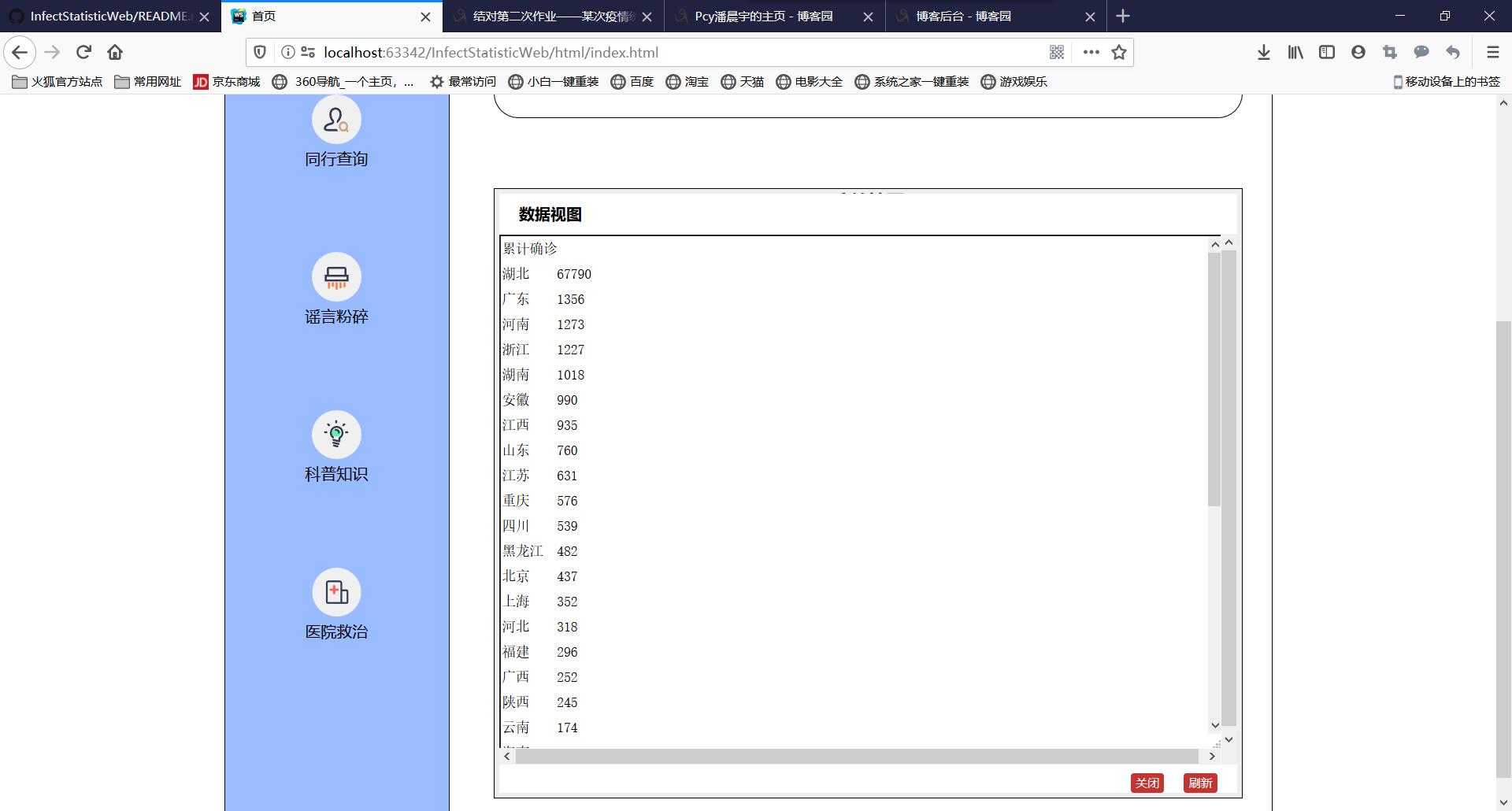
8、可以直接查看数据
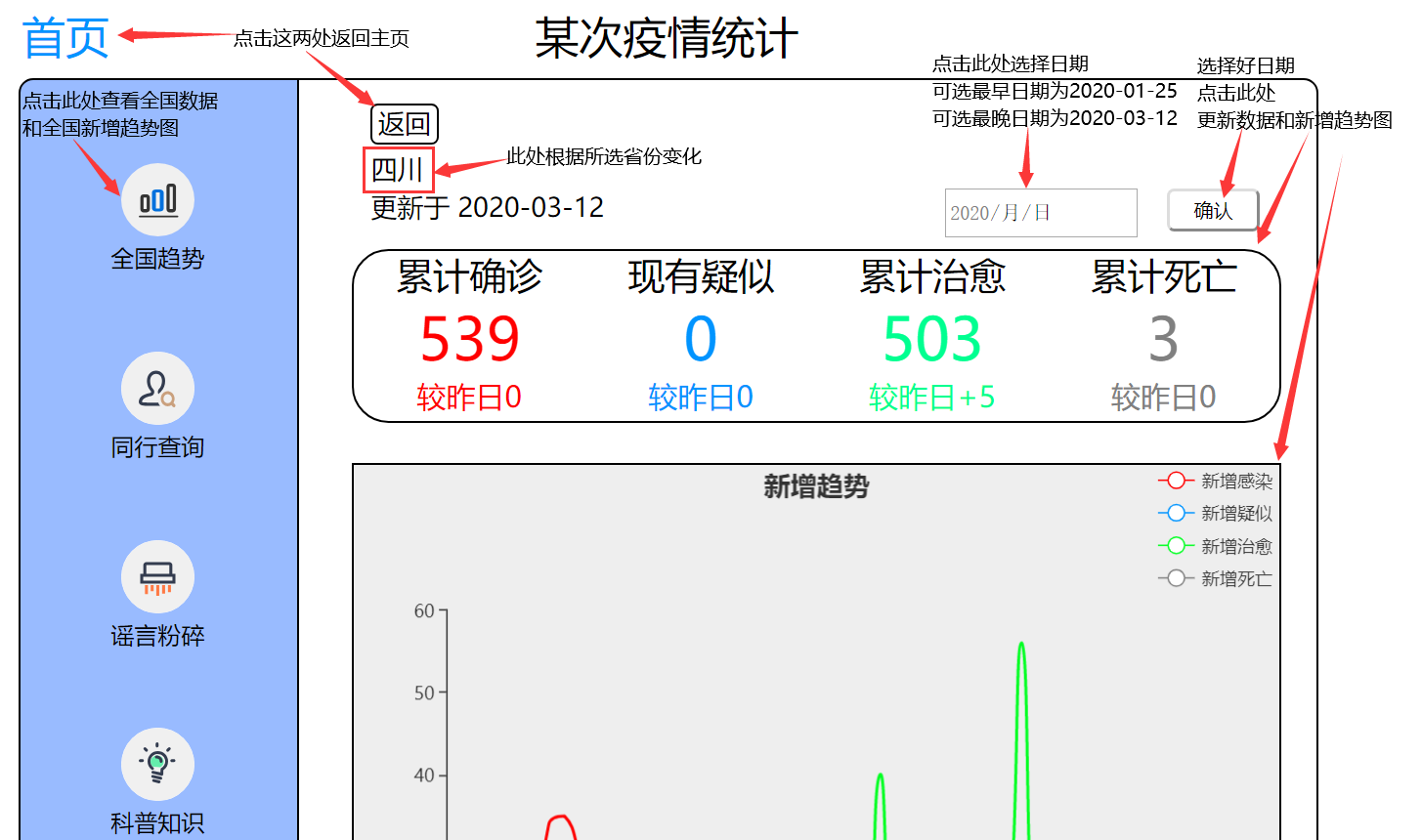
二、全国趋势
1、在页面的左上角有个“首页”的标志,下方还有个返回标志,点击两处都能够返回主页
2、点击全国趋势查看全国数据以及全国新增趋势图(也就是当前页面)
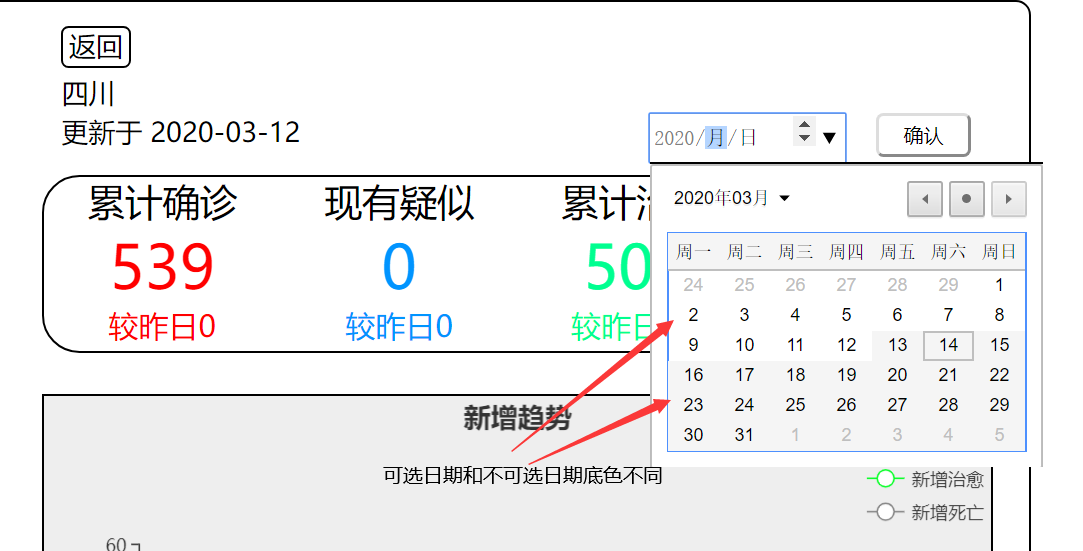
3、点击日期选择框能够选择日期,可选最早日期为2020-01-25,可选最晚日期为2020-03-12(因为数据部分是将爬取的数据转化成json文件读取,所以暂时未能实现实时更新,文件最新日期为2020-03-12)
4、选择日期后点击确认,下方的数据表和新增趋势图就会变换至选择日期的数据情况
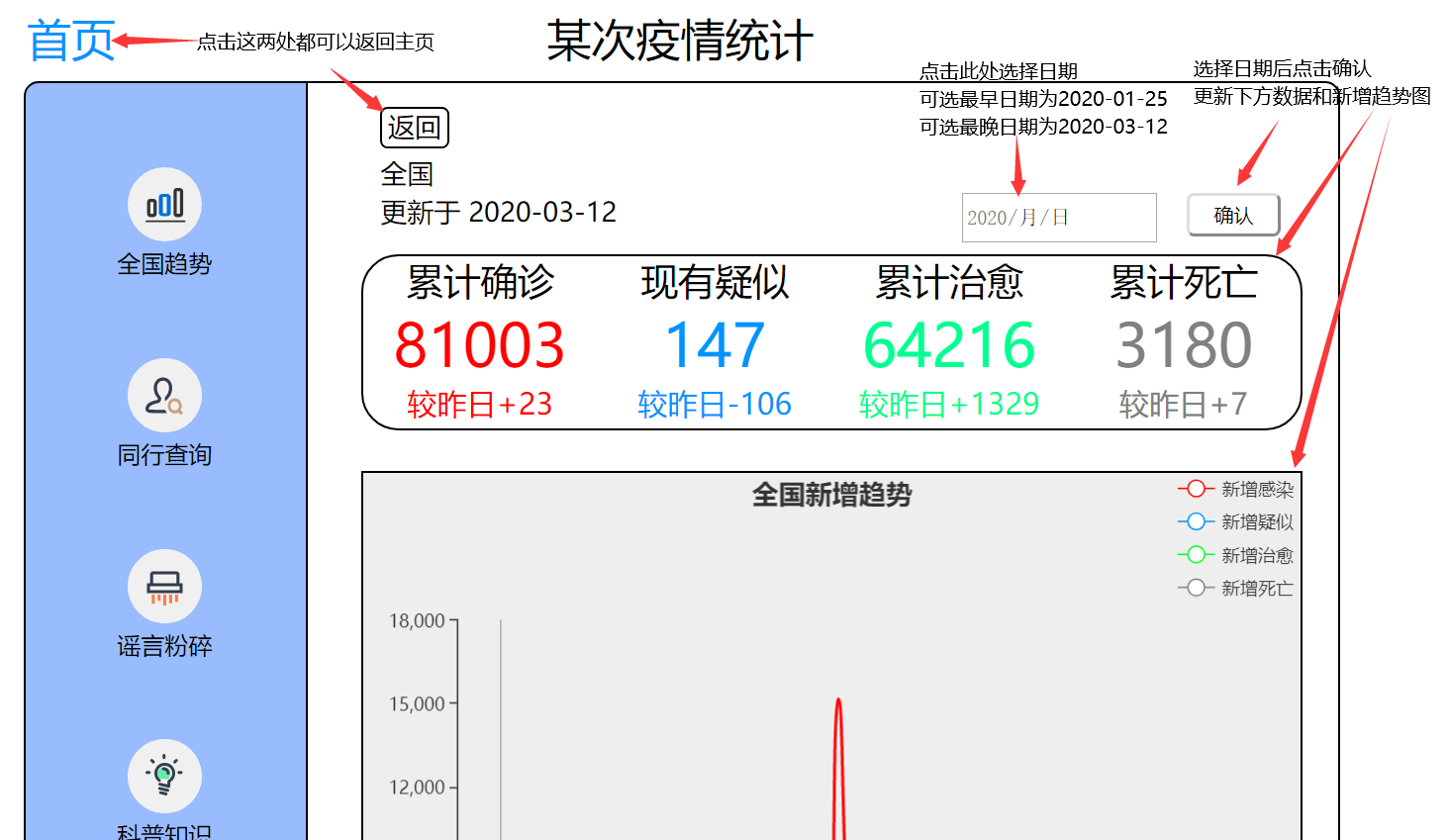
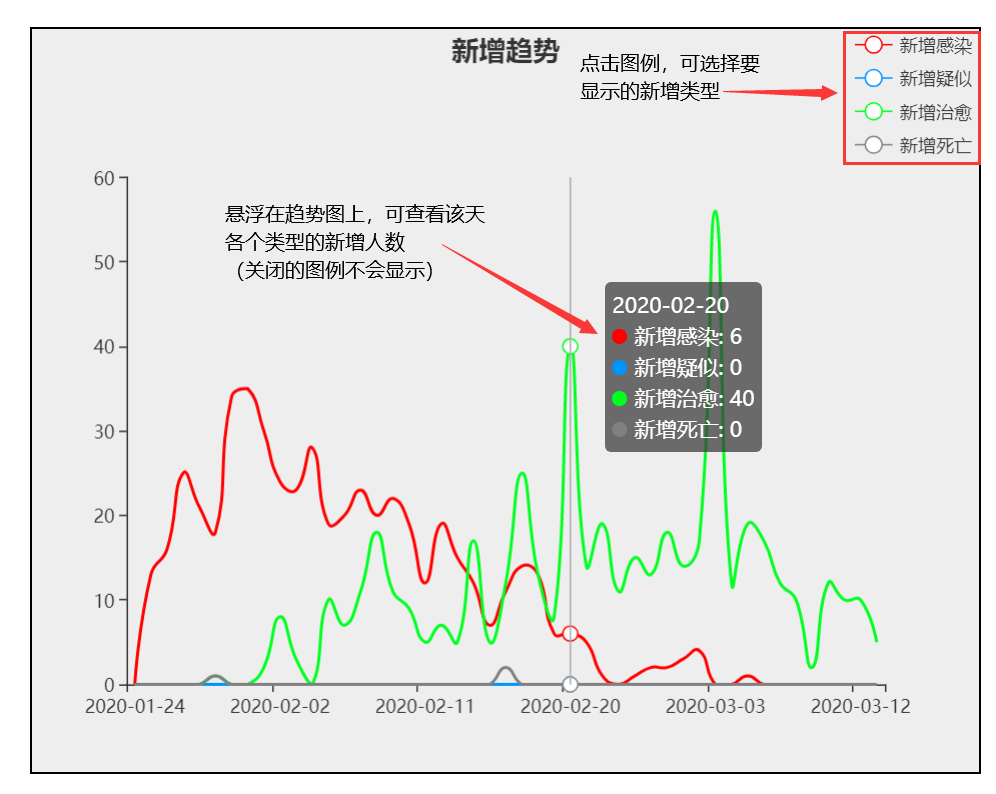
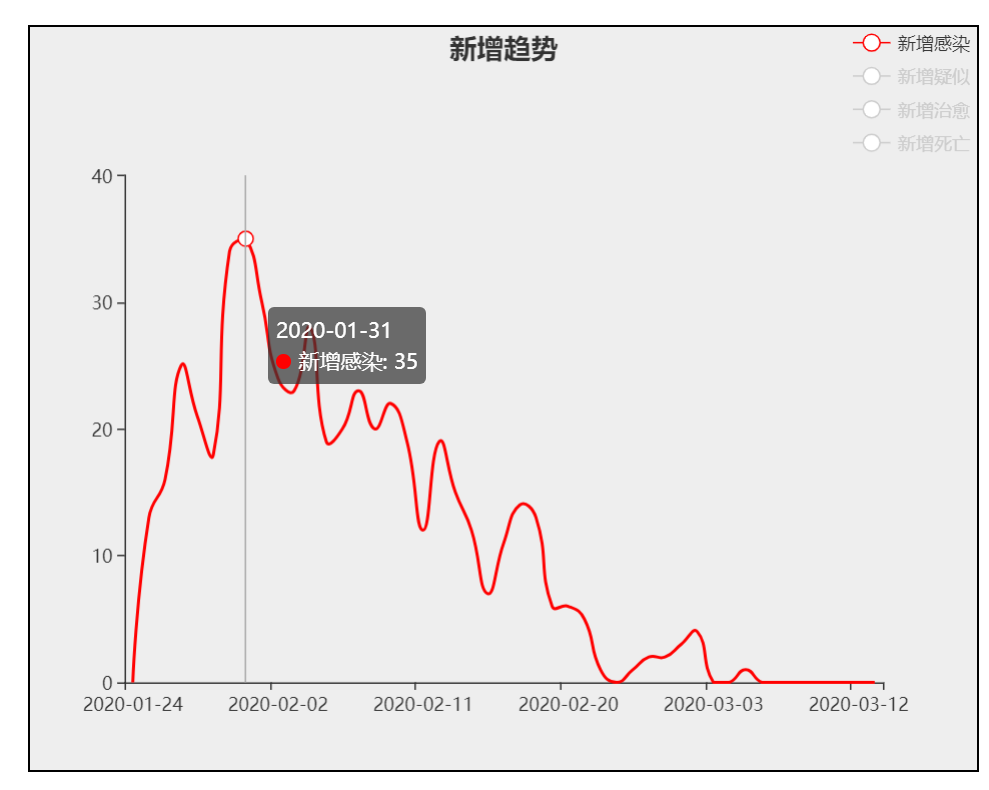
5、点击图例,可选择要显示的新增类型
6、悬浮在趋势图上,可查看某天各个类型的新增人数(已关闭的趋势图不会显示)
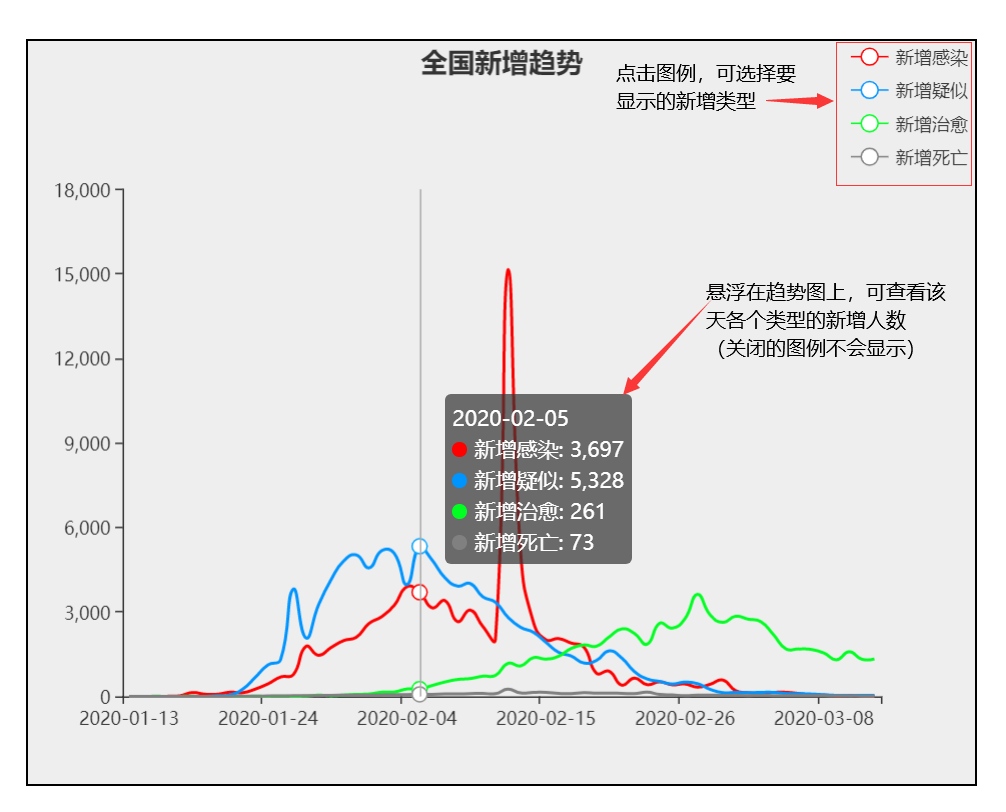
7、这里只显示新增疑似和新增治愈(点击新增感染和新增死亡的图例,将这两幅新增趋势图关闭)
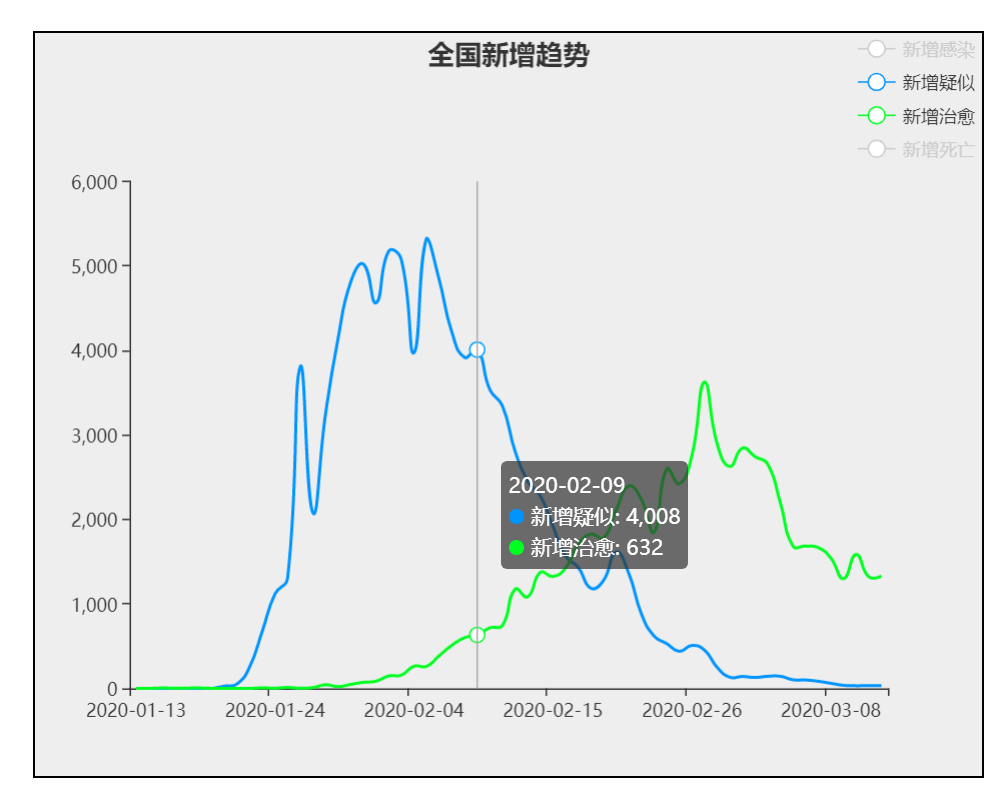
8、点击日期选择框,会发现可选日期和不可选日期的底色上有差异
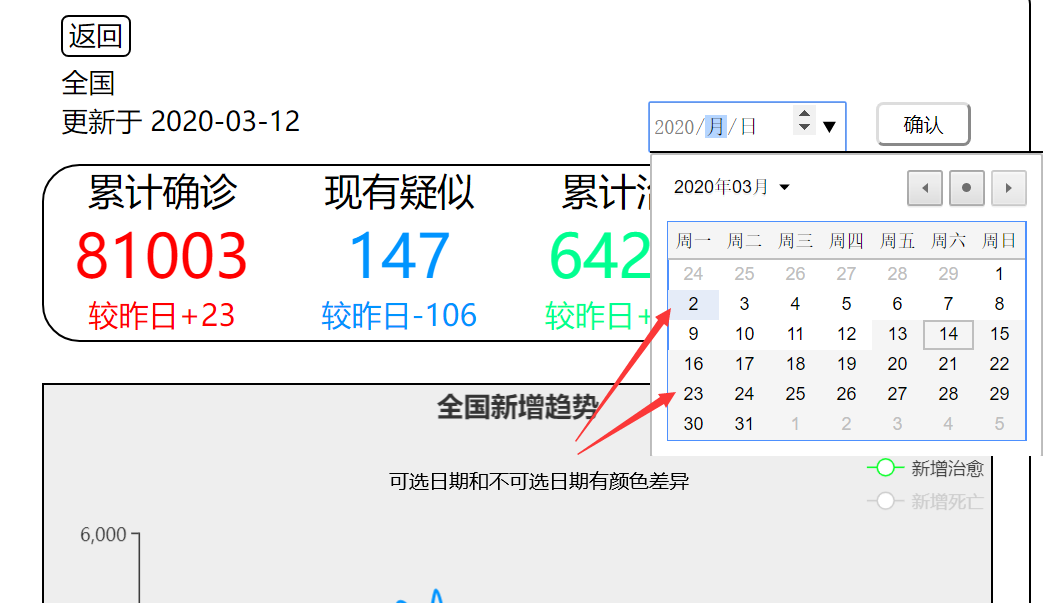
9、选择好日期点击确认,下方数据表和趋势图已变化。
三、省份趋势
此处效果与全国趋势图大同小异,不同点为省份位置的位置会根据所选省份发生变化

结对过程展示
刚刚拿到作业觉得这次作业的问题并不多,因为上次原型制作的时候就使用了Echarts,这次对我们来说的主要难度就是数据的获取,数据的处理和数据的渲染。
0. 前期工作
创建仓库和dev,.ignore和ReadMe等部分。沟通GitHub的使用方法。新建代码规范。
讨论GitHub的使用细节
1. 分工
一个人将原型的样子用前端CSS代码复现出来,另一个人去寻找相关网页爬取下来各省数据和全国历史数据。
2. 数据爬下来后进行数据处理,对Echarts进行渲染
3. 文件合并,实现跳转和整体逻辑

设计实现过程
设计过程
-
网页设计
- 网页架构形成
- CSS处理
- Echarts导入
-
数据爬取
-
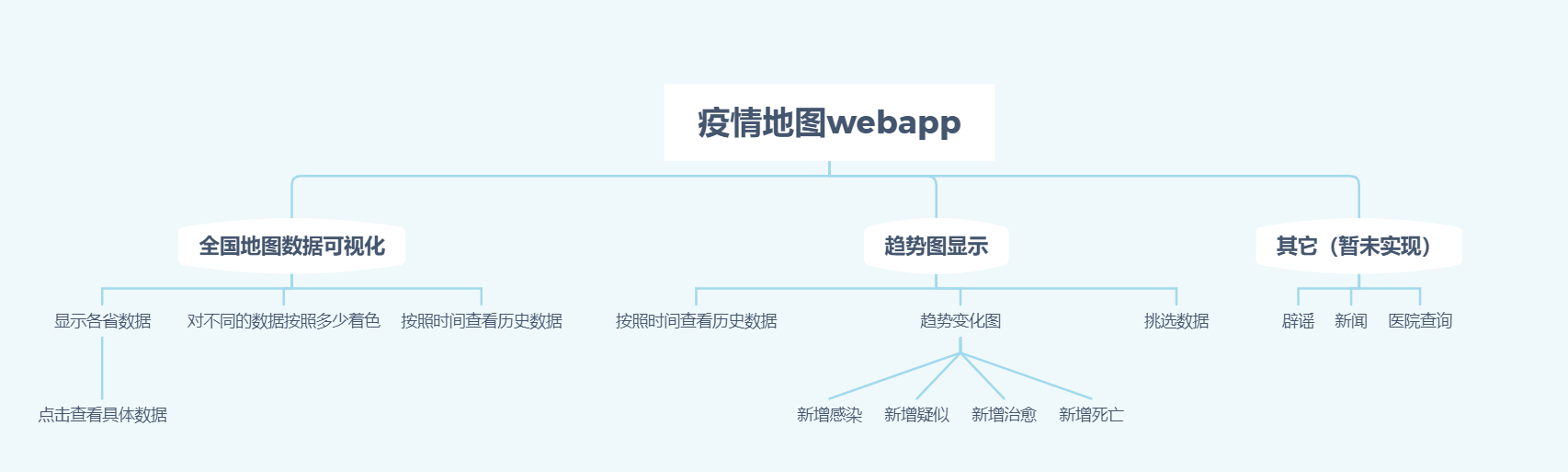
功能实现
- 将功能分为:地图展示和趋势图展示。两个模块分开设计
- 地图展示需要获取全国各地的最新数据,通过爬虫获取数据之后返回到页面,页面挑选参数,通过js代码获取每个地区的数据,然后渲染到Echarts上
- 趋势图展示
- 地图展示部分和趋势图展示的链接和跳转
- 通过Echarts的onclick函数获取到选取的地图块位置,点击后跳转传递url,附带参数name,通过name传递被点击的地区。
- 趋势图展示接收到传过来的地区,读取对应的数据文件,进行处理,得出时间对应的数据。
- 数据渲染到Echarts图标上,允许对图例操作进而进行筛选。
功能结构图
主要代码
python部分
爬取数据的代码类似如下,其他爬取函数类似不再赘述:
def get_tecent_china_data():
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_other'
r = requests.get(url)
res = json.loads(r.text)
data_all = json.loads(res['data'])
history = {} # 历史数据
for i in data_all["chinaDayList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds,"%Y.%m.%d")
ds = time.strftime("%Y-%m-%d",tup)
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {"confirm":confirm, "suspect":suspect, "heal":heal, "dead":dead}
for i in data_all["chinaDayAddList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds,"%Y.%m.%d")
ds = time.strftime("%Y-%m-%d",tup)
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds].update({"confirm_add":confirm, "suspect_add":suspect, "heal_add":heal, "dead_add":dead})
return history
找到腾讯的疫情地图,通过开发者模式的网页模式获取腾讯前端请求的json页面,也即url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_other',然后通过requests组件发出读取请求读取到json文件,随后进行爬取。
def insert_history():
cursor = None
conn = None
try:
dic = get_tecent_china_data()
print(f"{time.asctime()}开始插入历史数据")
conn, cursor = get_conn()
sql = "insert into history values(%s, %s, %s, %s, %s, %s, %s, %s, %s)"
for k, v in dic.items():
cursor.execute(sql,[k, v.get("confirm"),v.get("confirm_add"),v.get("suspect")
, v.get("suspect_add"), v.get("heal"), v.get("heal_add")
, v.get("dead"),v.get("dead_add")])
conn.commit()
print(f"{time.asctime()}插入历史数据完毕")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
用python连接MySql数据库,实现数据的本地化储存。
html部分
设置日期选择框,可选最早日期为2020-01-25,最晚为2020-03-12
<input type="date" required min="2020-01-25" max="2020-03-12" id="date">
<input type="button" id="confirm" value="确认">
设置好需要改变数据的位置,便于之后编写js文件的改变html内容
<!--ip_num:累计确诊-->
<div class="num" id="ip_num"></div>
<!--sp_num:现有疑似-->
<div class="num" id="sp_num"></div>
<!--cure_num:累计治愈-->
<div class="num" id="cure_num"></div>
<!--dead_num:累计死亡-->
<div class="num" id="dead_num"></div>
<!--ip_incrs:(较昨日)新增确诊-->
<div class="increase" id="ip_incrs"></div>
<!--sp_incrs:(较昨日)新增疑似-->
<div class="increase" id="sp_incrs"></div>
<!--cure_incrs:(较昨日)新增治愈-->
<div class="increase" id="cure_incrs"></div>
<!--dead_incrs:(较昨日)新增死亡-->
<div class="increase" id="dead_incrs"></div>
设置绘制图表位置,引入相应的js文件
<!--趋势图-->
<div id="province"></div>
<script src="../js/province.js"></script>
javaScript部分
地图渲染
function fuc() {
var list
$.ajax({
url:"https://lab.isaaclin.cn/nCoV/api/area",
async:false,
type:"get",
data:{
"latest":"1"
},
dataType:"json",
success:function (data) {
list = data["results"];
},
error:function () {
alert("读取失败")
}
})
return list
}
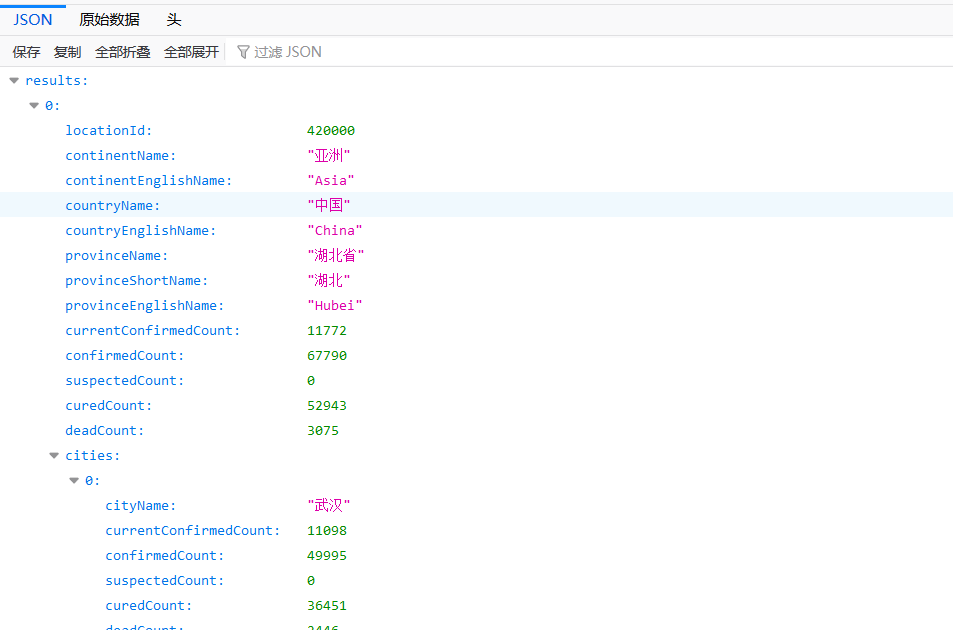
利用ajax调用API获取各地区的数据列表,返回一个json数据类型。
然后简单地通过js函数实现数据返回
function getNum (province) {
var l = fuc()
for (var i in l) {
if (l[i]["provinceName"] == province) {
return l[i]["confirmedCount"]
}
}
}
数据获取
1、根据点击省份区块传入的参数,选择json文件
2、使用javascript原生XMLHttpRequest的方法来读取json
window.onload = function () { //加载页面时
var string = location.search; //获取url中"?"符后的字串
var province = decodeURI(string).replace("?","");
var url;
switch (province) { //根据得到的字符串,选择对应的json文件
case "安徽":
url = "../json/areaAnHui.json";
break;
...
}
var request = new XMLHttpRequest(); //发送http请求
request.open("get", url);
request.send(null);
request.onload = function () {
if (request.status == 200) { //如果成功
var json = JSON.parse(request.responseText); //解析json字符串
...
之后进行相应读取和保存数据的操作
}
}
绘制图表
}
数据处理
1、时间格式处理(json文件中遇到时间格式为1545299299910,需要转化为yyyy-mm-dd的格式)
var date = new Date(json.results[0].updateTime);
var month = date.getMonth() + 1 < 10 ? "0" + (date.getMonth() + 1) : date.getMonth() + 1;
var currentDate = date.getDate() < 10 ? "0" + date.getDate() : date.getDate();
var string = date.getFullYear() + "-" + month + "-" + currentDate; //string就为所需格式
2、某天数据可能不止一条,所以某天时间可能重复出现,采用判断,将已记录的时间数据忽略(该方法限于时间按顺序出现)
if(temp != dateList[j-1]){ //如果该时间已经记录过
dateList[j] = date.getFullYear() + "-" + month + "-" + currentDate;
ip_num[j] = json.results[i].confirmedCount;
sp_num[j] = json.results[i].suspectedCount;
cure_num[j] = json.results[i].curedCount;
dead_num[j] = json.results[i].deadCount;
j++;
} else {
ip_num[j-1] = json.results[i].confirmedCount;
sp_num[j-1] = json.results[i].suspectedCount;
cure_num[j-1] = json.results[i].curedCount;
dead_num[j-1] = json.results[i].deadCount;
}
3、新增人数的获取:由于爬取的数据并非包含所有的数据,例如各类型新增数据;使用当天该类型人数减前一天该类型人数得到新增数据。
var ip_incrs = new Array(); //(较昨日)新增确诊
ip_incrs[0] = 0;
for(var i = 1; i < ip_num.length; i++){
ip_incrs[i] = ip_num[i] - ip_num[i-1]; //今日-昨日
}
4、根据所选日期处理时间数组,再通过新的时间数组长度限制其他数组
var dateList1 = new Array();
for(i = 0; i < dateList.length; i++){
if(date_limit < dateList[i]) //如果该日期超过选择日期
break;
dateList1[i] = dateList[i];
}
var ip_incrs = new Array(); //(较昨日)新增确诊
ip_incrs[0] = 0;
for(var i = 1; i < dateList1.length; i++){ //使用限制时间下的时间数组长度
ip_incrs[i] = ip_num[i] - ip_num[i-1];
}
心路历程、收获和对队友的评价
221701104 潘晨宇
本次的作业在一开始估计的时候以为应该会比较简单,毕竟只是数据的爬取和处理渲染,应该不会太难。但是实际操作的时候还是问题多多。我自己负责数据的爬取和固定化,先要去摸索一个新的python语言的语法和方法,然后去寻找各个网页找到自己需求的数据,最后固定化下来。这个过程其实并不像我想象的简单,相反还花了很多的时间,后来在渲染全国地图的时候调用爬虫返回的数据也没有很快,还需要读取觉得水平有待提高。
对我的队友221701116 陈炎:我觉得他是一个很棒的实干者,说做就做,效率也很高,当时处理数据的时候把json包传过去后他很快就着手进行处理,在写代码上毫不含糊。他写代码也十分可靠,在写代码的时候,趋势图的数据处理完全由他自己进行函数处理,是个很可靠的队友。

221701116 陈炎
在本次作业发布当天就去浏览了作业内容,大致浏览完,便发现了很多新知识、新技术,当时便觉得有些不知所措。在之后的实现中,先采取从最必要的开始,也就是GitHub的使用,建立结对仓库,这样才能保证代码写完后能够commit,并与队友共享使用。之后因为爬取数据需要python但并没有接触过,也就产生了焦虑心理。在队友接下爬取数据的重任后,开始按部就班设计页面样式,学习读取数据。在学习读取数据过程中,也出现了许多问题。之后不断查找资料,不断尝试,虽然每次失败后会烦躁,但还是会再次搜索出现的问题,浏览一个个解决办法。在本次作业的收获里,最主要的并非是技术,而是那种学习完成项目中不断尝试所磨练的耐心。通过本次作业还发觉自己在新技术面前的学习力还不够强大,不能够以更好地心态去面对,这些还需要再做提升。
对我的队友221701104 潘晨宇:他是一个学习力很强、思维灵活、体贴的队友,能够很好地学习新技术,并应用到项目中来;在方法选择上,能采取更高效的方式;在分工上也很照顾队友,主动挑起更重的担子。他像是将管理和工作的结合体,不仅能更好地发挥团队合作能力,也能够将自己项目的部分完成得井井有条。
版本更新
1.0.1版本解决了之前的API失效的问题。但代码尚有不完全的地方,请助教帮忙指正如下:
js代码
function fuc() {
var list
$.ajax({
url:"https://lab.ahusmart.com/nCoV/api/area",
async:false,
type:"get",
data:{
"latest":"1"
},
dataType:"json",
success:function (data) {
list = data["results"]
console.log(list);
},
error:function () {
alert("读取失败")
}
})
return list
}
function f() {
dataList = fuc().filter(r => {
return r.country == "中国" && r.provinceName !="待明确地区"
}).map(r => {
return {
name:r.provinceShortName,
value:r.confirmedCount
}
})
}
以上代码用以处理API返回的数据,但是每次读取页面都需要重复执行function f()导致页面的渲染很慢。希望助教能提出建议改进。
现有想法两点:1.将API的处理放到服务器上,直接返回处理好的数据。2.将处理好的数据放到本地localstorage或cookie中,这样只需要第一次读取,之后的读取都不会很慢。
以上希望助教能予以思路上的帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号