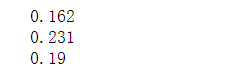python数据分析与挖掘实战第十一章


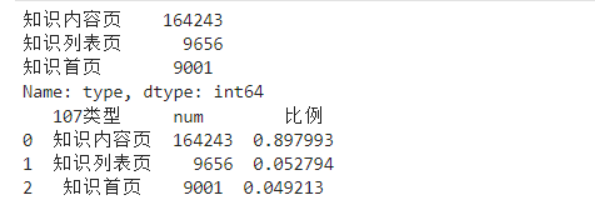
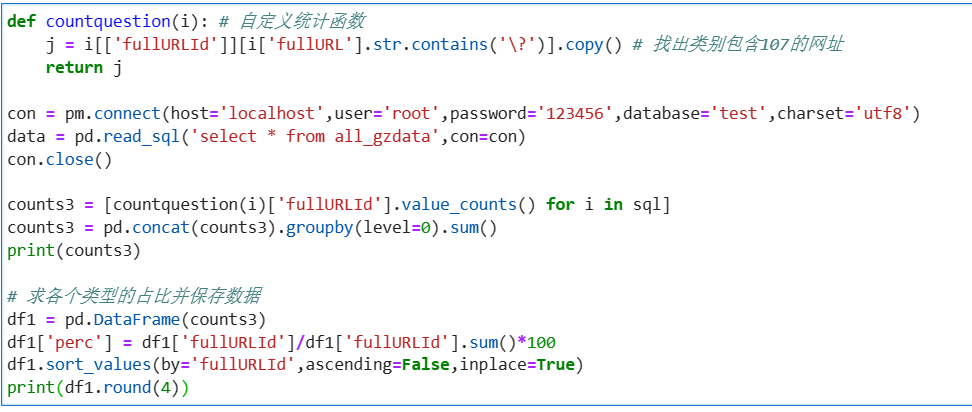


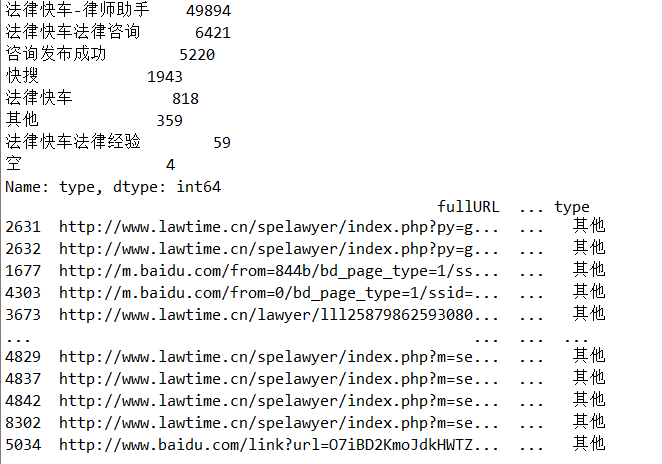

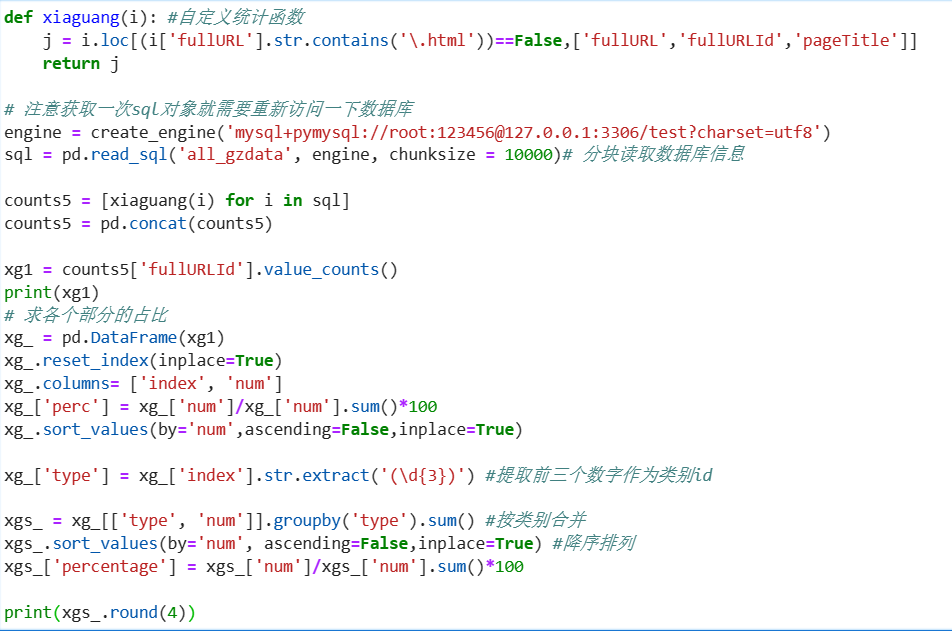
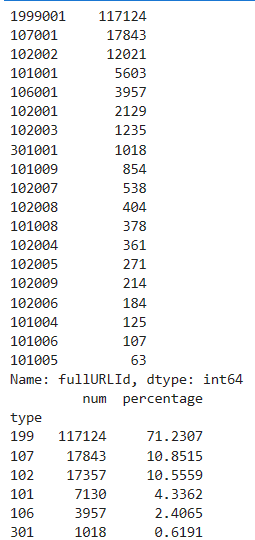

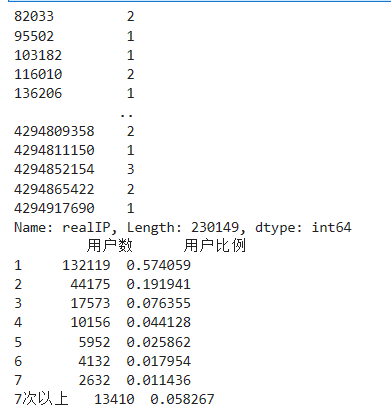

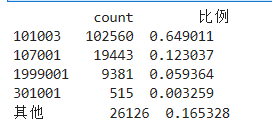
# 在浏览1次的前提下, 得到的网页被浏览的总次数 fullURL_count = pd.DataFrame(real_one.groupby("fullURL")["fullURL"].count()) fullURL_count.columns = ["count"] fullURL_count["fullURL"] = fullURL_count.index.tolist() fullURL_count.sort_values(by='count', ascending=False,inplace=True) # 降序排列 import os import re import pandas as pd import pymysql as pm from random import sample # 修改工作路径到指定文件夹 os.chdir('data6/demo') # 读取数据 con = pm.connect(host='localhost',user='root',password='123456',db='test',charset='utf8') data = pd.read_sql('select * from all_gzdata',con=con) con.close() # 关闭连接 # 取出107类型数据 index107 = [re.search('107',str(i))!=None for i in data.loc[:,'fullURLId']] data_107 = data.loc[index107,:] # 在107类型中筛选出婚姻类数据 index = [re.search('hunyin',str(i))!=None for i in data_107.loc[:,'fullURL']] data_hunyin = data_107.loc[index,:] # 提取所需字段(realIP、fullURL) info = data_hunyin.loc[:,['realIP','fullURL']] # 去除网址中“?”及其后面内容 da = [re.sub('\?.*','',str(i)) for i in info.loc[:,'fullURL']] info.loc[:,'fullURL'] = da # 将info中‘fullURL’那列换成da # 去除无html网址 index = [re.search('\.html',str(i))!=None for i in info.loc[:,'fullURL']] index.count(True) # True 或者 1 , False 或者 0 info1 = info.loc[index,:] # 找出翻页和非翻页网址 index = [re.search('/\d+_\d+\.html',i)!=None for i in info1.loc[:,'fullURL']] index1 = [i==False for i in index] info1_1 = info1.loc[index,:] # 带翻页网址 info1_2 = info1.loc[index1,:] # 无翻页网址 # 将翻页网址还原 da = [re.sub('_\d+\.html','.html',str(i)) for i in info1_1.loc[:,'fullURL']] info1_1.loc[:,'fullURL'] = da # 翻页与非翻页网址合并 frames = [info1_1,info1_2] info2 = pd.concat(frames) # 或者 info2 = pd.concat([info1_1,info1_2],axis = 0) # 默认为0,即行合并 # 去重(realIP和fullURL两列相同) info3 = info2.drop_duplicates() # 将IP转换成字符型数据 info3.iloc[:,0] = [str(index) for index in info3.iloc[:,0]] info3.iloc[:,1] = [str(index) for index in info3.iloc[:,1]] len(info3)
![]()
# 筛选满足一定浏览次数的IP IP_count = info3['realIP'].value_counts() # 找出IP集合 IP = list(IP_count.index) count = list(IP_count.values) # 统计每个IP的浏览次数,并存放进IP_count数据框中,第一列为IP,第二列为浏览次数 IP_count = pd.DataFrame({'IP':IP,'count':count}) # 3.3筛选出浏览网址在n次以上的IP集合 n = 2 index = IP_count.loc[:,'count']>n IP_index = IP_count.loc[index,'IP'] # 划分IP集合为训练集和测试集 index_tr = sample(range(0,len(IP_index)),int(len(IP_index)*0.8)) # 或者np.random.sample index_te = [i for i in range(0,len(IP_index)) if i not in index_tr] IP_tr = IP_index[index_tr] IP_te = IP_index[index_te] # 将对应数据集划分为训练集和测试集 index_tr = [i in list(IP_tr) for i in info3.loc[:,'realIP']] index_te = [i in list(IP_te) for i in info3.loc[:,'realIP']] data_tr = info3.loc[index_tr,:] data_te = info3.loc[index_te,:] print(len(data_tr)) IP_tr = data_tr.iloc[:,0] # 训练集IP url_tr = data_tr.iloc[:,1] # 训练集网址 IP_tr = list(set(IP_tr)) # 去重处理 url_tr = list(set(url_tr)) # 去重处理 len(url_tr)

import pandas as pd # 利用训练集数据构建模型 UI_matrix_tr = pd.DataFrame(0,index=IP_tr,columns=url_tr) # 求用户-物品矩阵 for i in data_tr.index: UI_matrix_tr.loc[data_tr.loc[i,'realIP'],data_tr.loc[i,'fullURL']] = 1 sum(UI_matrix_tr.sum(axis=1)) # 求物品相似度矩阵(因计算量较大,需要耗费的时间较久) Item_matrix_tr = pd.DataFrame(0,index=url_tr,columns=url_tr) for i in Item_matrix_tr.index: for j in Item_matrix_tr.index: a = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)==2) b = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)!=0) Item_matrix_tr.loc[i,j] = a/b # 将物品相似度矩阵对角线处理为零 for i in Item_matrix_tr.index: Item_matrix_tr.loc[i,i]=0 # 利用测试集数据对模型评价 IP_te = data_te.iloc[:,0] url_te = data_te.iloc[:,1] IP_te = list(set(IP_te)) url_te = list(set(url_te)) # 测试集数据用户物品矩阵 UI_matrix_te = pd.DataFrame(0,index=IP_te,columns=url_te) for i in data_te.index: UI_matrix_te.loc[data_te.loc[i,'realIP'],data_te.loc[i,'fullURL']] = 1 # 对测试集IP进行推荐 Res = pd.DataFrame('NaN',index=data_te.index,columns=['IP','已浏览网址','推荐网址','T/F']) Res.loc[:,'IP']=list(data_te.iloc[:,0]) Res.loc[:,'已浏览网址']=list(data_te.iloc[:,1]) # 开始推荐 for i in Res.index: if Res.loc[i,'已浏览网址'] in list(Item_matrix_tr.index): Res.loc[i,'推荐网址'] = Item_matrix_tr.loc[Res.loc[i,'已浏览网址'],:].argmax() if Res.loc[i,'推荐网址'] in url_te: Res.loc[i,'T/F']=UI_matrix_te.loc[Res.loc[i,'IP'],Res.loc[i,'推荐网址']]==1 else: Res.loc[i,'T/F'] = False # 保存推荐结果 Res.to_csv('data6/Res.csv',index=False,encoding='utf8') import pandas as pd # 读取保存的推荐结果 Res = pd.read_csv('data6/Res.csv',keep_default_na=False, encoding='utf8') # 计算推荐准确率 Pre = round(sum(Res.loc[:,'T/F']=='True') / (len(Res.index)-sum(Res.loc[:,'T/F']=='NaN')), 3) print(Pre) # 计算推荐召回率 Rec = round(sum(Res.loc[:,'T/F']=='True') / (sum(Res.loc[:,'T/F']=='True')+sum(Res.loc[:,'T/F']=='NaN')), 3) print(Rec) # 计算F1指标 F1 = round(2*Pre*Rec/(Pre+Rec+0.01),3) print(F1)