CPU 软件性能分析指标解释
Profiler 工具有很多术语和指标,这里进行介绍、说明和总结。
Retired & Executed 指令
处理器执行的指令数量,往往会比程序流需要的指令数量要多。这是因为处理器会预测指令(分支预测等)。对于一般的指令,CPU 提交计算结果后就会 Retired(指令退役)。但是,处理器预测出来的指令不会,CPU 会保留它们。当 CPU 判断出预测是正确的,这些被保留的指令才会像正常指令那样执行。若 CPU 判断出预测结果是错误的,CPU 会将丢掉所以预测指令的执行结果并且不会 Retired 这些指令。所以,CPU 执行的指令数量并不等于退役的指令数量。一个好的程序应该有较多的指令执行和较少的指令退役。
可以通过Linux pref工具获得指令退役的数量:
perf stat -e instructions ./a
CPU 利用率
CPU 利用率就是 CPU 繁忙时间同占据总运行时间的比值。
\(CPU 利用率={{CPU\_CLK\_UNHALTED.REF\_TSC(CPU繁忙周期)} \over {TSC(运行总周期)}}\)
CPU 利用率通常用来衡量程序的性能好坏的一个指标,通常情况下 CPU 的利用率越高越好。但是,有些情况下可能并不是。例如:CPU 停滞等待内存中的数据;在多线程的情况下,线程可能在等待一些让其运转必要的资源;因此,提出了 CPU 有效利用率这个指标,相较于 CPU 利用率,剔除了上述这些等待时间。
可以通过Linux pref工具获得 CPU 利用率:
perf stat -- a
0.634874 task-clock (msec) # 0.634 CPUs 利用率
CPI & IPC
- Cycles Per Instruction (CPI) - 平均使一条指令退役(失效)需要多少个周期。
- Instructions Per Cycle (IPC) - 平均每个周期退役(失效)的指令数。
\(IPC={{INS\_RETIRED.ANY(指令退役数)}\over{CPU\_CLK\_UNHALTED}(CPU 周期)}\)
\(CPI={1 \over {IPC}}\)
这两个指标是分析软件和硬件性能的常用指标。软件工程师在优化应用程序时会关注 IPC 和 CPI。通常情况下,我们希望 CPI 越低越好 IPC 越高越好。这两个指标我们依旧可以通过pref 工具获取:
perf stat -e cycles,instructions -- a
2369632 cycles
1725916 instructions
# 我们可以根据这两个指标做除法可得
UOPs
关于UOPs的更详细的文章
x86体系结构的微处理器将复杂的类 CISC 指令转换为简单的类 RISC 微操作(缩写为 µops 或 uops)。这样做的主要优点是可以利用 µops 可以乱序执行的。譬如说有这样一个指令ADD EAX,[MEM] 可能会拆成两个 µops :一个操作是将内存中的数据加载到寄存器中,另外一个操作是执行加法。微指令的划分通常取决于 CPU。
除了将指令进行拆分,也可以将指令进行合并,在现代 Intel CPUs 下存在两种融合情况:
- Microfusion——融合同种机器指令。例如:融合内存写入操作和读取修改操作。
- Macrofusion——融合不同类型机器指令。例如:解码器可以将算术或逻辑指令与后续条件跳转指令融合到单个计算中。
Micro-Fusion 和 Macro-Fusion 都可以节省带宽。
通过pref 可以获得相关的指标:
perf stat -e uops_issued.any,uops_executed.thread,uops_retired.all -- a
2856278 uops_issued.any
2720241 uops_executed.thread
2557884 uops_retired.all
有关最新 x86 体系结构指令的延迟、吞吐量、端口使用率和 UOP 数,访问<uops.info>。
Pipeline Slot
指令流水槽(Pipeline Slot)表示处理一个uop所需的硬件资源。现代 x86 CPU 通常情况下 pipline 宽度为 4。如下图所示,这段程序只使用了一半的 slot。从体系结构的角度来说,该程序只发挥了硬件一半的性能。
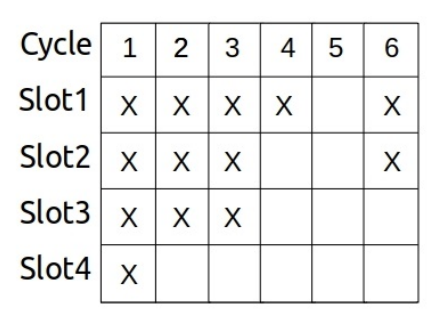
核心 & 参考周期
现在 x86 CPU 执行指令并没有固定的频率。它们都使用了 动态频率缩放 技术。在 Intel 上叫 Turbo Boost ,在 AMD 上叫 Turbo Core 。它允许CPU动态地增加和减少其频率–缩小频率以牺牲性能为代价降低功耗,而放大频率可以提高性能,但会牺牲功耗。
可以通过pref 工具获取相关指标,这里以 Skylake i7-6000为例:
perf stat -e cycles,ref-cycles ./a
43340884632 cycles # 3.97 GHz
37028245322 ref-cycles # 3.39 GHz
其中 ref-cycles 结果为 CPU 没有进行动态频率缩放的周期,如果我们对其进行时钟增益缩放,就可以得到这款CPU的基础频率。
指标 cycles 计算的是真实 CPU 周期(也就是加入了动态频率缩放后的周期),我们还可以计算动态频率缩放功能的利用程度:
\(Turbo 利用率 = {{cycles} \over {ref-cycles}}\)
Cache 丢失
现代 CPU 通常具备多级缓存,当 CPU 需要的数据不存在于当前缓存,那么将从其下一级缓存中查找。如下表所示,不同级别的缓存访问的周期不同。倘若最后一级 Cache (LLC)依旧没有命中,我们需要付出很大的代价去从主存中获取数据。缓存丢失包括了指令和数据缓存丢失。
| 内存层级 | 延时 |
|---|---|
| L1 | 4 cycles (~1ns) |
| L2 | 10-25 cycles (5-10 ns) |
| L3 | ~40 cycles (20 ns) |
| 主存 | 200+ cycles (100 ns) |
我们可以通过pref 获取 L
perf stat -e mem_load_retired.fb_hit,mem_load_retired.l<N>_miss,mem_load_retired.l<N>_hit,mem_inst_retired.all_loads -- a
29580 mem_load_retired.fb_hit
19036 mem_load_retired.l<n>_miss # LN 缓存丢失数
497204 mem_load_retired.l<n>_hit # LN 缓存命中数
546230 mem_inst_retired.all_loads
预测错误的分支
现代处理器都会对分支进行预测,若预测正确,可以给性能带来很大的提升,倘若预测错误,将会造成 10~20 时钟周期的惩罚。我们可以通过pref 工具来查看分支预测错误的数量:
perf stat -e branches,branch-misses -- a
358209 branches
14026 branch-misses # 3,92% 分支预测错误率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号