浅谈软件性能提升相关的概念
浅谈软件性能提升相关的概念
原文链接为<Making your program run faster: the key concepts of software performance - Johny's Software Lab>
所有的工程师在其职业生涯的某个阶段都不得不处理软件性能问题——让程序运行得更快。在大学时代,我们认为程序的性能主要是算法性能。但在实际上还有很多其他方面的内容让你的程序或你的系统运行得更快。下面我将介绍一下软件性能工程的一些概念。
提高软件性能的时机
我们需要思考的第一个问题是何时需要我们去考虑提高软件性能?当写下第一行代码时?或者当产品已经上线了,但有性能问题时才考虑?
回答这个问题之前,我们需要考虑以下几件事情。第一件事情就是你要开发什么样的软件,程序要处理的数据量是多少。如果写的是一个 Word 转 PDF 的工具,即使最大的文件有几千页,而大部分文件只有几百页。那么就没必要太过关注性能问题。遵循良好的开发实践是正确的做法,将你的精力集中在代码的可读性、可维护性和可移植性上。
但是,如果你的程序将处理大量的数据集,或者有延迟要求,程序必须在一定的时间范围内做出反应,或者程序可能会在非常慢的计算机上运行,那么从一开始就应该考虑性能问题。
例如,如果一款游戏的帧率很低,就无法发售。这就是为什么许多游戏开发者使用一种不同的编程范式——面向数据的设计,以实现良好的性能。在这种模式下的编程与在面向对象模式下的编程是完全不同的,但是会给游戏带来倍数的性能。
当确实有性能提升方面的需求时,你需要提前考虑一些事情:使用应用程序通常架构来避免不必要的操作和具有较大延迟的操作,高质量的数据结构和算法,用来避免性能问题。在编写技术规范和进行代码审查时,你应该考虑到性能问题。并非每行代码都很关键,但有些性能问题如果不事先考虑到,就会非常困难,甚至无法解决。
找到瓶颈
当出现性能问题时,开发人员通常使用 *profilers 工具来找到瓶颈在地方。profilers *的输出是一份报告,它告诉你哪些函数或源代码是你的程序花费时间最多的地方。性能提升应当从这些瓶颈着手:这是提高性能最有可能带来速度改进的地方。
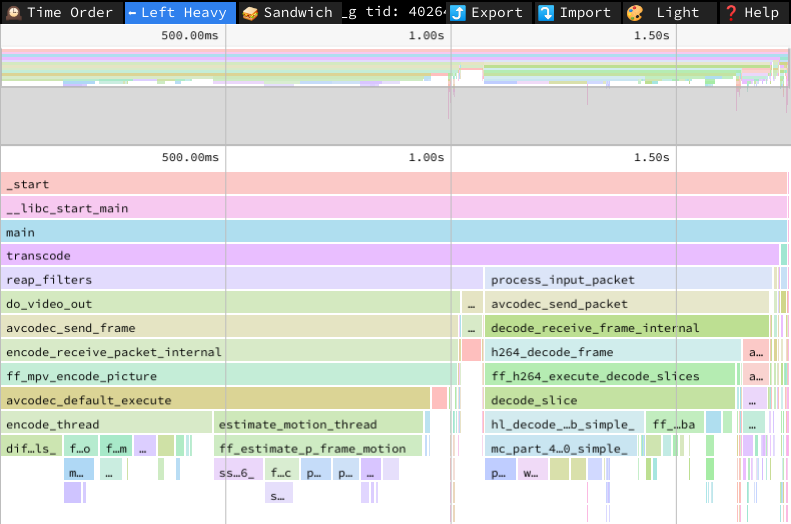
*profiler *会指出花了太多时间的代码,但它所指示的内容不一定准确。在一个简单的、单线程的应用程序中,花费时间最多的函数或循环是明显的瓶颈。在多线程或多进程应用中,情况不一定如此。看起来是瓶颈的函数实际上可能是在等待其他操作的完成。因此,需要在其他地方寻找瓶颈。有专门的 *profiler *用于多线程和多处理器应用程序——Coz。
性能问题的种类
当发现瓶颈时,并不总是很清楚可以做什么。导致一个功能缓慢的原因可能有很多:架构方面(例如,不必要地多次调用该函数)、性能差的算法 (例如,线性搜索而不是二分查找)、对操作系统资源的使用效率低下(例如,在一个循环中 lock 和 unlock 一个 mutex 会导致其他线程的饥饿)、 过度使用系统内存分配器(例如,内存碎片化)、对标准库的低效率的使用(例如,没有在哈希图中预留足够的空间,导致了代价高昂的 rehash)、没有充分的使用编程语言的一些特性 (在C++中通过值而不是通过引用来移动大类)、 内存子系统的使用效率低下 (例如,太多的指针解除引用,也就是 chasing pointer)、 对CPU单元的使用效率不高 (例如,热循环不使用CPU的矢量引擎)、编译器参数选择错误 (例如,禁用内联)等等。
这里提到的一些类型比其他类型更容易被发现。例如,不必要地调用一个函数太多次,会被团队中的大多数工程师发现。但是,没有最佳地使用内存子系统的问题,通常只有那些对软件性能非常熟悉的人才能发现。
峰值性能
有时,热循环是以最高性能运行的。它正在以最佳方式使用硬件,而且只做必要的操作。检查热循环是否以峰值性能运行是了解是否存在性能改进空间的另一种方法。
在科学计算中,他们使用 Roofline 模型来衡量一个算法对硬件资源的使用效率。这些信息具有一定的局限性:很多时候,最佳的硬件效率是不可能的,那么问题来了,什么是峰值?
在追求峰值性能的过程中,另一套有用的工具是基于硬件计数器的特殊*profiler *(最著名的是英特尔的 VTUNE 和 pmu-tools )。这些工具将帮助你了解一个循环有什么样的硬件瓶颈(计算、内存访问、条件等),让你在正确的地方发力。

但是请注意! 硬件效率并不代表一切:线性搜索使用硬件资源的效率比二分查找高得多,但二分查找更快,因为它做的工作更少!
应用性能与系统性能
性能工程的一个重要方面是对应用性能和系统性能进行区分。
当谈及应用程序的性能时,我们指的是一个程序或一组程序单独运行的性能(没有其他程序在并行运行)。在这种情况下,我们通常使用 *profiler *观察程序的性能,并通过修改程序的源代码来解决出现的问题。 本网站上的文章大多涉及应用程序的性能。相反,当谈论系统性能时,我们指的是整个系统的性能:所有不同的进程在特定硬件上一起运行。程序可能在无负载的系统中可能运行良好,但有时,当该进程与其他进程一起运行时,问题就会出现。在这种情况下,问题的出现主要是因为某项硬件资源被耗尽了。CPU、内存带宽、硬盘带宽或网络带宽。例如,如果计算机的物理内存用完了,进程将开始将内存交换到硬盘上。这可以看作是系统性能的急剧下降的原因。
系统性能作为一门学问,在服务器领域非常重要,因为许多不同的进程都在同一硬件上执行。用于调试系统性能的工具与用于调试应用程序性能的工具完全不同:各种可视化的工具,测量 CPU 使用率、CPU 执行中的异常情况、IO 子系统的使用率、内存使用率等。而修复方法也是不同的:改变系统的配置、删除进程或给 CPU 增加冷却器都有助于解决问题。
应用和系统性能问题之间的主要区别是应用性能问题持续地再现,而系统性能问题只在适当的情况下再现。一般来说,系统性能问题更难调试,但更容易修复。
延迟和吞吐量
当我们说 "某个东西很慢 "时,取决于上下文,我们可能有两种意思。可以指我们的程序没有及时响应其输入,也可以指我们的程序处理数据的速度不令人满意。不要理所应当的认为,这两个句子听起来可以互换,但在更深层次上,它们是不同的。让我们用一个例子来说明:一个音频处理系统必须在其到达输入端后 20ms 内输出处理过的音频。在这里,我们感兴趣的是优化延迟:我们希望系统对输入作出反应,要么满足约定的某个时间,要么尽快作出反应。
第二个例子是一个训练神经网络的高性能系统。在这里,响应时间并不关键。模型可能需要训练几个小时,甚至几天。我们感兴趣的是处理率:每单位时间处理的数据量应该是尽可能大的。希望任务能尽快完成,但在给定的时间内做出回应并不是我们的首要任务,我们要提高的是原始速度。
在这种情况下,我们正在优化吞吐量:我们正尝试在每单位时间内处理尽可能多的数据。对延迟敏感的系统在实时系统(如汽车或航空系统)、高频交易系统(系统必须尽快对来自市场的数据作出反应)或游戏中很常见。吞吐量敏感的系统在其他地方也很常见:视频渲染、神经网络训练等。
延迟敏感的系统建立在吞吐量敏感的系统之上。在实现最大吞吐量之后,整个系统,包括硬件、操作系统、网络堆栈等,都会针对延迟进行优化。
在结束这个话题之前还有一件事:延迟和吞吐量在一定程度上是并存的,超过一定的阶段它们开始分道扬镳。你不可能同时拥有它们。如果你将系统配置为高延迟,你的一些工作将被打断,这将降低系统的吞吐量。
现在的大多数操作系统都是为高吞吐量而配置的。对于那些想要创建优化的高延迟系统的人来说,需要对操作系统进行特殊配置。(如. Low Latency Performance Tuning for Red Hat Enterprise Linux 7, Configuring and tuning HPE ProLiant Servers for low-latency applications)。
如果你对延迟相关的性能话题感兴趣,我强烈推荐Mark Dawson的博客。
最后提一下
性能提升并不是独立的。在设计软件系统时还有其他考虑因素:可维护性、可移植性、可读性、可扩展性、可靠性、安全性、上线时间,等等。其中有些是与业务相关联的,一些则不是。每个软件项目都有自己的具体需求,而性能也只是一部分。有时它是一个非常重要的部分,有时则不是这样。因此,每个软件团队都需要做出决策,需要在性能上花费多少时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号