solr5.3.1 集成IK中文分词器
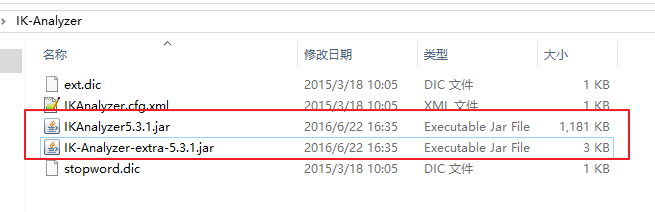
1.下载IK分词器包。
链接:http://pan.baidu.com/s/1i4D0fZJ 密码:bcen
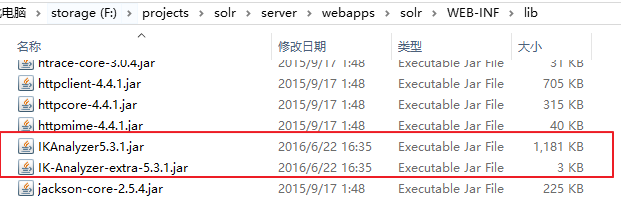
2.解压并把IKAnalyzer5.3.1.jar 、IK-Analyzer-extra-5.3.1.jar拷贝到tomcat/webapps/solr/WEB-INF/lib下。
3.修改schema.xml配置文件,如下:
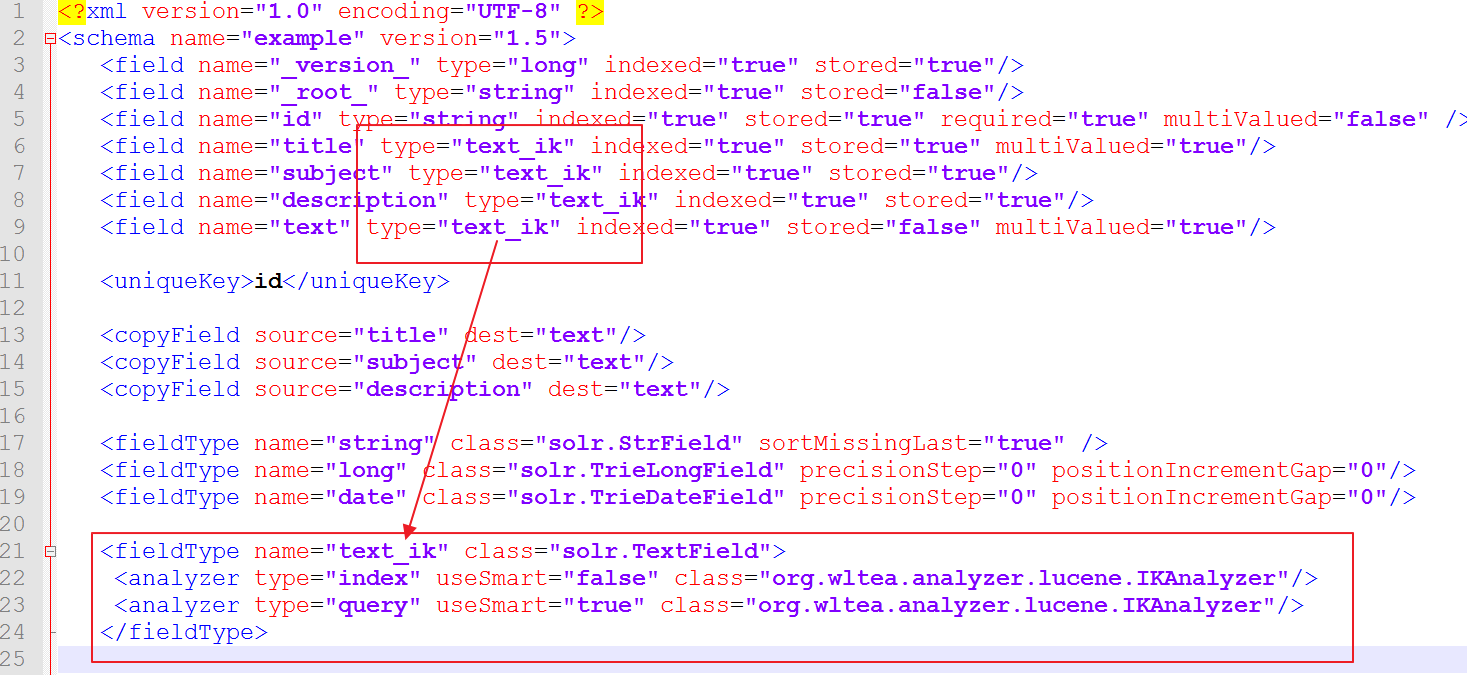
修改后的配置文件
1 <?xml version="1.0" encoding="UTF-8" ?> 2 <schema name="example" version="1.5"> 3 <field name="_version_" type="long" indexed="true" stored="true"/> 4 <field name="_root_" type="string" indexed="true" stored="false"/> 5 <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> 6 <field name="title" type="text_ik" indexed="true" stored="true" multiValued="true"/> 7 <field name="subject" type="text_ik" indexed="true" stored="true"/> 8 <field name="description" type="text_ik" indexed="true" stored="true"/> 9 <field name="text" type="text_ik" indexed="true" stored="false" multiValued="true"/> 10 11 <uniqueKey>id</uniqueKey> 12 13 <copyField source="title" dest="text"/> 14 <copyField source="subject" dest="text"/> 15 <copyField source="description" dest="text"/> 16 17 <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> 18 <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> 19 <fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/> 20 21 <fieldType name="text_ik" class="solr.TextField"> 22 <analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> 23 <analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> 24 </fieldType> 25 26 <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> 27 <analyzer type="index"> 28 <tokenizer class="solr.StandardTokenizerFactory"/> 29 <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> 30 <filter class="solr.LowerCaseFilterFactory"/> 31 </analyzer> 32 <analyzer type="query"> 33 <tokenizer class="solr.StandardTokenizerFactory"/> 34 <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> 35 <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> 36 <filter class="solr.LowerCaseFilterFactory"/> 37 </analyzer> 38 </fieldType> 39 </schema>
修改完成之后保存并重启solr服务器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号