R语言数据处理方法~小结(转)
文章目录
1. R自带函数
2. reshape2数据重构
3. dplyr
4. tidyr
5. 字符串处理
1. R自带函数
1.1 转置
使用函数t()可对一个矩阵或数据框进行转置,对于数据框,行名将变成变量(列)名。

数列array进行维度转换 aperm

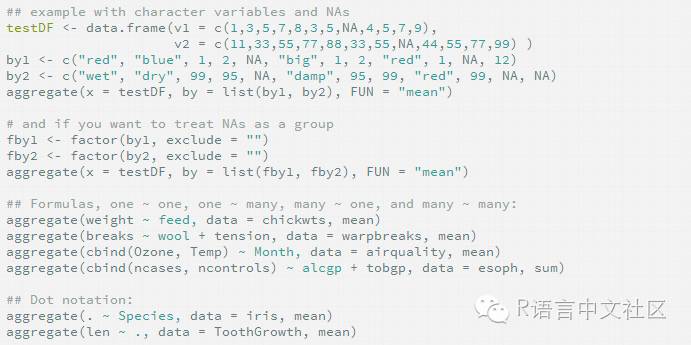
1.2 整合数据aggregate
在R中使用一个或多个by变量和一个预先定义好的函数来折叠(collapse)数据。调用格式为:
aggregate(x, by, FUN)
其中x是待折叠的数据对象,by饰一个变量名组成的列表,这些变量将被去掉以新的观测,而FUN则是用来计算表述性统计量的标量函数,它将被用来计算新观测中的值。

by中的变量必须在一个列表中(即使只有一个变量)。也可以在列表中为各组声明自定义的名称,例如by=list(Group.cyl=cyl,Group.gears=gear)。
1.3 apply
待整理
1.4 union和intersect

1.5 合并 cbind和rbind
纵向合并数据通常用于向数据框中添加观测。
(1)rbind() :纵向合并两个数据框(数据集)
(2)cbind() :横向合并两个数据框(数据集)
注:两个数据框行(列)数必须相同。如果x中拥有y中没有的变量,在合并它们之前需做以下处理:
(1)删除dataframeA中的多余变量;
(2)在dataframeB中创建追加的变量并将其值设为NA(缺失)。

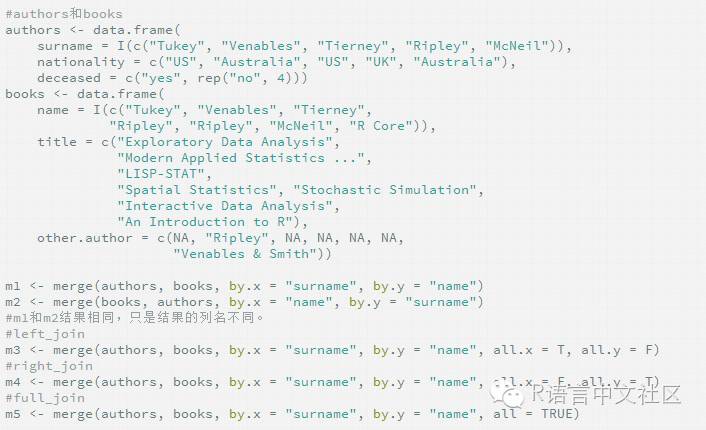
1.6 匹配合并 merge
merge效果同dplyr的join,join的效力更高。
(1)inner_join 等价于 merge(all=F)
(2)left_join 等价于 merge(all.x=T, all.y=F)
(3)right_join 等价于 merge(all.x=F, all.y=T)
(4)full_join 等价于 merge(all=T)
1.7 排除重复数据 unique
unique 函数可以去掉向量、数据框或类似数列的数据中重复的元素。

2. reshape2包
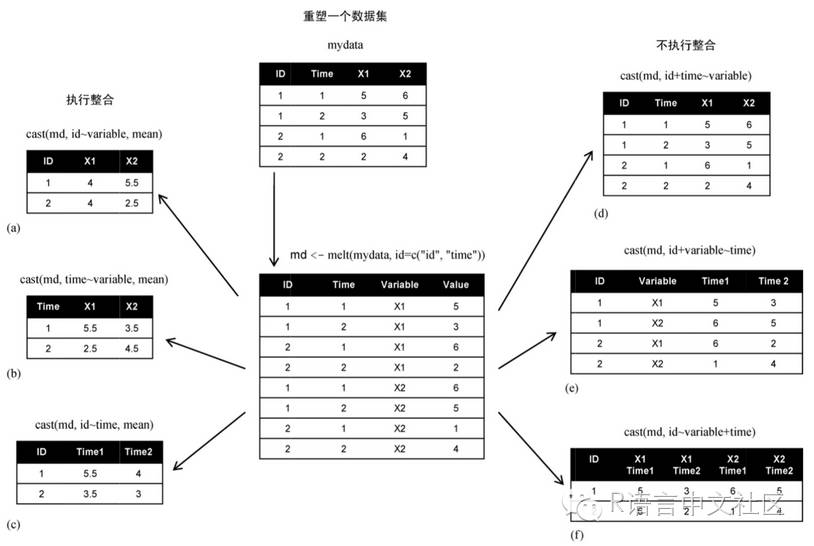
首先将数据“融合”(melt),以使每一行都是一个唯一的标识符-变量组合。然后将数据“重铸”(cast),可以使用任何函数对数据进行整合成想要的任何形状。
注:reshape包的重铸函数为cast(),reshape2包的重铸函数为dcast()和acast()

2.1融合-melt
数据集的融合是将它重构为这样一种格式:每个测量变量独占一行,行中带有要唯一确定这个测量所需的标识符变量。

2.2重铸-dcast和acast
Use acastor dcastdepending on whether you want vector/matrix/array output or data frame output. Data frames can have at most two dimensions.
1.dcast——返回的结果是一个数据框
2.acast——返回的结果可以是向量、矩阵或者数组
调用格式为:

其中md为已融合的数据,formula描述想要的结果,FUN是(可选的)数据整合函数。
接受的公式形如:
在这个公式中,rowvar1 + rowvar2 + ... 定义了要划掉的变量集合,以确定各行的内容,而colvar1 + colvar2 + ... 则定义了要划掉的、确定各列内容的变量集合。

3. dplyr
3.1 基本操作
3.1.1 数据类型
将过长过大的数据集转换为显示更友好的 tbl_df 类型

3.1.2 筛选filter
按给定的逻辑判断筛选出符合要求的子数据集, 类似于 base::subset() 函数

用R自带函数实现:
除了代码简洁外, 还支持对同一对象的任意个条件组合, 如:
3.1.3 排列 arrange

用R自带函数实现:

3.1.4 选择select
用列名作参数来选择子数据集:

排除列名:
select的特殊函数
(1)starts_with(x, ignore.case = TRUE): names starts with x
(2)ends_with(x, ignore.case = TRUE): names ends in x
(3)contains(x, ignore.case = TRUE): selects all variables whose name contains
(4)matches(x, ignore.case = TRUE): selects all variables whose name matches the regular expression x
(5)num_range("x", 1:5, width = 2): selects all variables (numerically) from x01 to x05.
(6)one_of("x", "y", "z"): selects variables provided in a character vector.
(7)everything(): selects all variables.

":" 选择连续列,contains来匹配列名
同样类似于R自带的subset() 函数.

3.1.5 添加新变量mutate
对已有列进行数据运算并添加为新列:

mutate_each()
对每一列运行窗体函数。
plyr::mutate() 与 base::transform() 相似, 优势在于可以在同一语句中对刚增加的列进行操作。

通过data.frame有可以实现
3.1.6 汇总summarise

count()

3.1.7 tally

3.2 分组group_by
当对数据集通过 group_by() 添加了分组信息后,mutate(), arrange() 和 summarise() 函数会自动对这些 tbl 类数据执行分组操作 (R语言泛型函数的优势).

另: 一些汇总时的小函数
n(): 计算个数 n_distinct(x): 计算 x 中唯一值的个数
3.3 链式操作(管道) %>% 或 %.%
dplyr包还新引进了一个操作符,读成then,使用时把数据名作为开头, 然后依次对此数据进行多步操作。比如:

按数据处理的思路写代码, 一步步深入, 既易写又易读, 接近于从左到右的自然语言顺序, 对比一下用R自带函数实现的.

文章里还表示: 通过 %>% 那段代码比跑上面这段代码,运算速度提升很多倍.
至于这个新鲜的概念会不会和 ggplot2 里的 + 连接号一样, 发挥出种种奇妙的功能呢? 还是在实际使用中多体验感受吧.
3.5 数据匹配合并join
(1)inner_join(x, y) :只包含同时出现在x,y表中的行
(2)left_join(x, y) :包含所有x中以及y中匹配的行
(3)semi_join(x, y) :包含x中,在y中有匹配的行,结果为x的子集
(4)anti_join(x, y) :包含x中,不匹配y的行,结果为x的子集,与semi_join相反
(5)full_join(x, y) :包含所以x、y中的行
(6)right_join(x, y) :包含所有y中以及x中匹配的行

3.6 连接数据库
(1)dplyr 可以连接数据库
(1)使用与本地数据框操作一样的语法
(3)只支持生成SELECT语句
(4)支持SQLite, PostgreSQL/Redshift, MySQL/MariaDB, BigQuery, MonetDB
3.7 利用窗体函数变换数据

4. tidyr
tidyr包的作者也是Hadley Wickham, 与dplyr包结合使用,是reshape2包的替代。(先挖坑...)
5. 字符串处理
5.1 字符个数 nchar
nchar()能够获取字符串的长度,它和length()的结果是有区别的。

5.2 连接字符 paste
paste()不仅可以连接多个字符串,还可以将对象自动转换为字符串再相连,另外它还能处理向量,所以功能更强大。

paste默认的分隔符是空格,必须指定sep=""。还有一个collapse参数,可以把这些字符串拼成一个长字符串,而不是放在一个向量中。
5.3 分割字符 strsplit

5.4 提取字符 substr与substring

5.5 替换字符 sub和gsub
(1)sub 只做一次替换(不管有几次匹配)
(2)gsub 把满足条件的匹配都做替换

虽然sub和gsub是用于字符串替换的函数,但严格地说R语言没有字符串替换的函数,因为R语言不管什么操作对参数都是传值不传址。所以原字符串并没有改变,要改变原变量我们只能通过再赋值的方式。

sub和gsub函数可以使用提取表达式(转义字符+数字)让部分变成全部

5.6 字符查询匹配 grep
(1)grep 返回匹配项的下标
(2)grepl 返回所有查询结果的逻辑向量
(3)regexpr
(4)gregexpr
(5)regexecregexpr、gregexpr和regexec这三个函数返回的结果包含了匹配的具体位置和字符串长度信息,可以用于字符串的提取操作。

5.7 其他
(1)大小写转换 tolower与toupper
(2)列表转换为向量unlist
(3)unlist(x, recursive = TRUE, use.names = TRUE)
(4)重复输入rep()

转自:http://mt.sohu.com/20161021/n470849946.shtml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号