hudi clustering 数据聚集(二)
小文件合并解析
执行代码:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val t1 = "t1"
val basePath = "file:///tmp/hudi_data/"
val dataGen = new DataGenerator(Array("2020/03/11"))
// 生成随机数据100条
val updates = convertToStringList(dataGen.generateInserts(100))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 1));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t1).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
// 每次操作之后都会进行clustering操作
option("hoodie.clustering.inline", "true").
// 每4次提交就做一次clustering操作
option("hoodie.clustering.inline.max.commits", "4").
// 指定生成文件最大大小
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
// 指定小文件大小限制,当文件小于该值时,可用于被 clustering 操作
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
mode(Append).
save(basePath+t1);
// 创建临时视图,查看当前表内数据总个数
spark.read.format("hudi").load(basePath+t1).createOrReplaceTempView("t1_table")
spark.sql("select count(*) from t1_table").show()
以上示例中,指定了进行 clustering 的触发频率:每4次提交就触发一次,并指定了文件相关大小:生成新文件的最大大小、小文件最小大小。
执行步骤:
1、生成数据,插入数据。
查看当前磁盘上的文件:

查看表内数据个数:
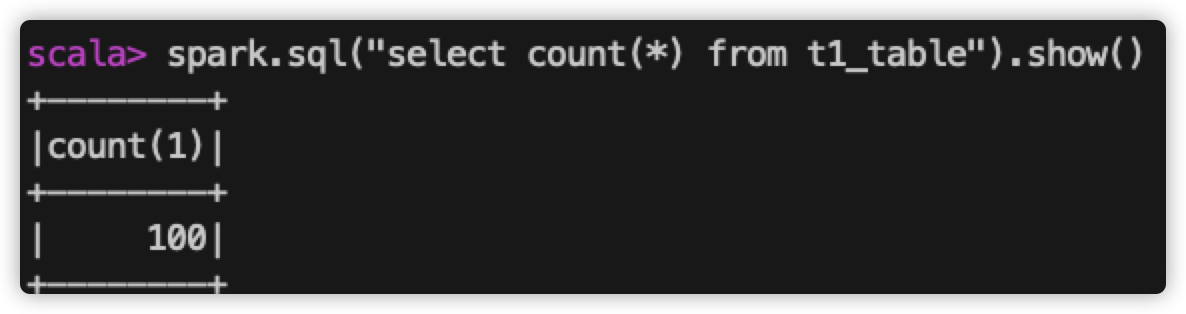
查看 spark-web 上 该 sql 执行读取的文件个数:

所以,当前表中共100条数据,磁盘上生成一个数据文件,在查询该表数据时,只读取了一个文件。
2、重复上面操作两次。
查看当前磁盘上的文件:

查看表内数据个数:
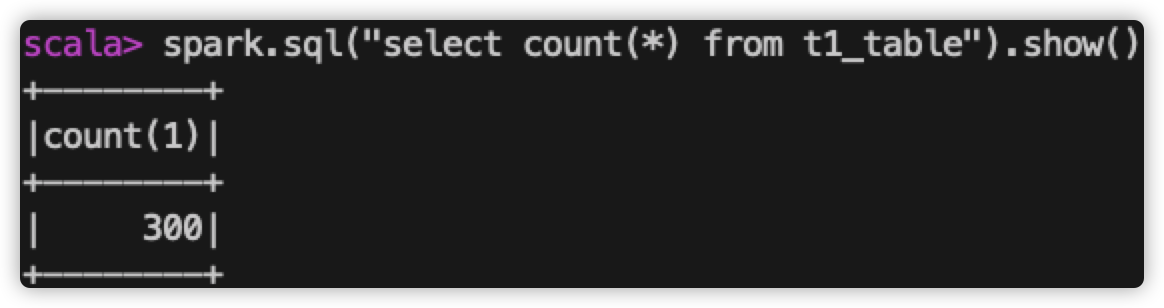
查看 spark-web 上 该 sql 执行读取的文件个数:

所以,目前为止,我们提交了3次写操作,每次生成1个数据文件,共生成了3个数据文件,当查询所有的数据时,需要从3个文件中读取数据。
3、再进行一次数据插入:
查看当前磁盘上的文件:

查看表内数据个数:

查看 spark-web 上 该 sql 执行读取的文件个数:

结论:
1、配置了hoodie.parquet.small.file.limit之后,每次提交新数据,都会生成一个数据文件。
2、在 clustering 之前,每次读取表所有数据的时候,都需要读取所有文件。
3、提交第4次数据之后,触发了 clustering ,生成了一个更大的文件,此时再读取所有数据的时候,就只需要读取合并后的大文件即可。在.hoodie文件夹下,也可以看到 replacecommit 的提交:

小文件合并+sort columns解析
执行代码:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val t1 = "t1"
val basePath = "file:///tmp/hudi_data/"
val dataGen = new DataGenerator(Array("2020/03/11"))
var a = 0;
for (a <- 1 to 8) {
val updates = convertToStringList(dataGen.generateInserts(10000))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 1));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t1).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
// 每次操作之后都会进行clustering操作
option("hoodie.clustering.inline", "true").
// 每4次提交就做一次clustering操作
option("hoodie.clustering.inline.max.commits", "8").
// 指定生成文件最大大小
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1400000").
// 指定小文件大小限制,当文件小于该值时,可用于被 clustering 操作
option("hoodie.clustering.plan.strategy.small.file.limit", "1400000").
// 指定排序的列
option("hoodie.clustering.plan.strategy.sort.columns", "fare").
mode(Append).
save(basePath+t1);
// 创建临时视图,查看当前表内数据总个数
spark.read.format("hudi").load(basePath+t1).createOrReplaceTempView("t1_table")
spark.sql("select count(*) from t1_table where fare > 50").show()
}
执行代码分析
该代码比之前代码修改了几个地方:
1、增加了for循环:
因为我们已经知道了在8次提交之后,小文件会合并大文件,所以一个for循环,做8次提交,我们直接看结果就行。
2、增加了 hoodie.clustering.plan.strategy.sort.columns 配置:
这是本次主要的测试点。该配置可以对指定的列进行排序。
即,当做 clustering 的时候,hudi 会重新读取所有文件,并根据指定的列做排序,这样可以把相关的数据聚集在一起,可以做更好的查询过滤(后面会演示说明),而我们要做的对比,就是以 fare 为条件查询数据,观察在 clustering 前后,hudi 会读取的文件个数。
我们想要的结果是,在 clustering 之前,由于没有根据 fare 对数据任何处理,符合过滤条件的数据会分布在各个文件,所以会读取的文件个数很多,过滤效果差。而在 clustering 之后,会根据 fare 列对数据做重新分布,符合过滤条件的数据较为集中,那么读取的数据就会比较少,过滤效果较好。
3、修改了 hoodie.clustering.plan.strategy.target.file.max.bytes 和 hoodie.clustering.plan.strategy.small.file.limit
我们想测的是,clustering 前后过滤的效果,所以文件个数不能够被改变(否则4个文件合并成1个文件后,读取数据时也只会读取1个文件,就看不出来sort是否有效果),所以这里把该值设置成两个较为近似的值,使其既能够触发 clustering,又能够在 clustering 前后文件个数相同。
执行结果:
查看当前磁盘文件:
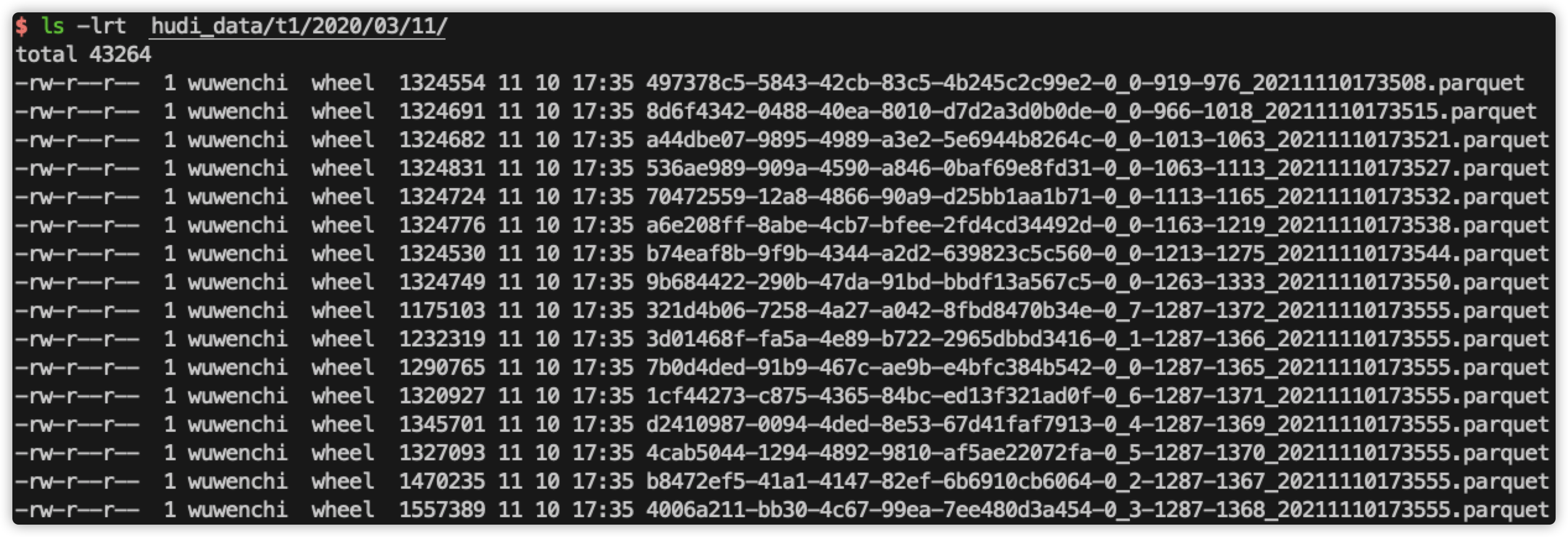
查看第5次的sql过滤结果:
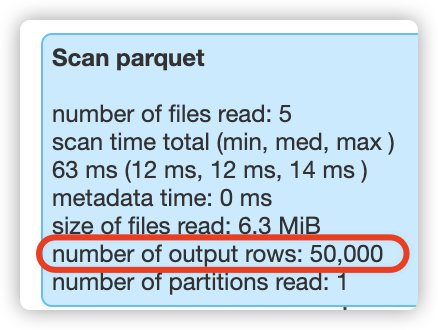
查看第6次的sql过滤结果:
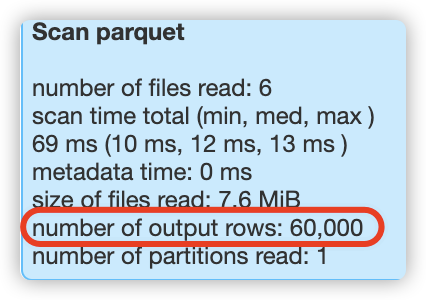
查看第7次的sql过滤结果:
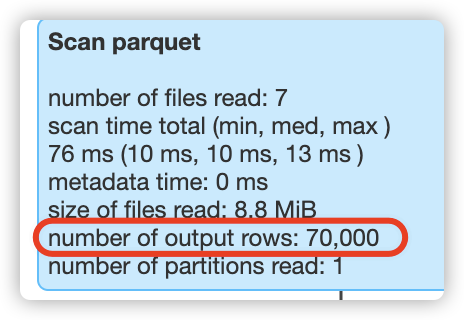
查看最后一次的sql过滤结果:
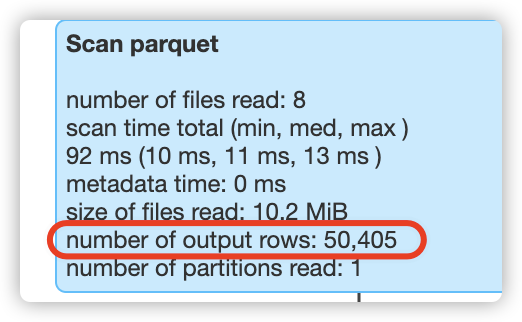
结论:
1、在 clustering 之前,过滤 fare 列时,会读取所有的数据。
比如,在执行第5次过滤时,此时表总共有50000行数据,hudi就会扫描50000行数据;在执行第6次过滤时,此时表总共有60000行数据,hudi就会扫描60000行数据;在执行第7次过滤时,此时表总共有70000行数据,hudi就会扫描70000行数据,
2、在 clustering 之后,数据文件个数不变的情况下(前后都是8个数据文件),在第8次过滤时,能够有效应用sort columns的重排列数据,将本应扫描80000行数据降低到只扫描了50405行数据,过滤效果明显提升很多!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号