列表(有序):
 序列的每个元素都可以用2种索引的表达方式,一种是正数索引,另一种是负数索引。
序列的每个元素都可以用2种索引的表达方式,一种是正数索引,另一种是负数索引。
序列切片,作用是访问序列中一定范围的元素,格式“序列名[A:B]”,其中A为所切片的第一个元素的索引号,而B为切片后剩下的第一个元素的索引号。data[:]是整个data列表
data=[1,2,3,4,5,6,7,8,9] print(data[3:6]) #>>>[4, 5, 6] print(data[:]) #指没有进行切片 #>>>[1,2,3,4,5,6,7,8,9] print( data[-3:]) #包含最后一个元素 #>>>[7, 8, 9]
“步长”的引用,格式“序列名[A:B:C]”,作用按照步长进行切片,C可以为正数也可以为负数,正数是从左向右进行切片;负数时,从右向左进行切片。
data=[1,2,3,4,5,6,7,8,9] print(data[::-1]) ##反向输出,步长默认为-1 # >>>[9, 8, 7, 6, 5, 4, 3, 2, 1] print(data[::1]) ##正向输出,默认为1 # >>>[1, 2, 3, 4, 5, 6, 7, 8, 9] print(data[-3::-2]) ##步长为负数,改变了切片方向 # >>>[7, 5, 3, 1]
遍历列表:
方法一:
alist=["a","b","c","d","e"]
for index in range(len(alist)):
print (alist[index]+ " index is {0:d}.".format(index))
方法二:
alist=["a","b","c","d","e"]
for index,item in enumerate(alist):##使用enumerate函数
print ("{0:s} index is {1:d}" .format(item,index))
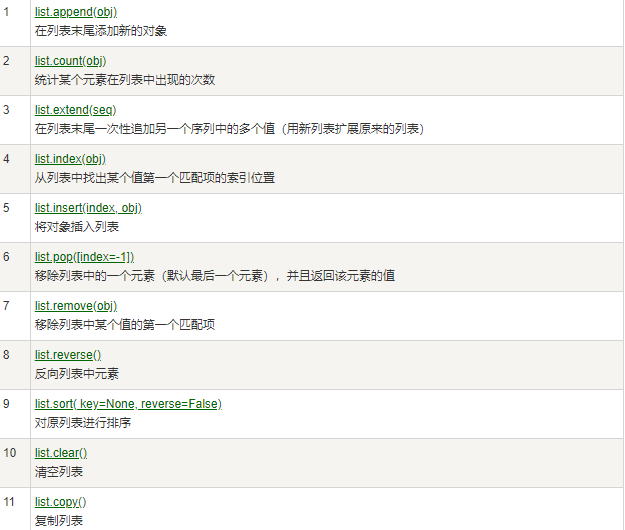
列表的常用内置方法:
range()函数
#语法range[start, end) # 步长默认为1 range(1,5) #代表从1到5(不包含5) #>>> [1, 2, 3, 4] range(5) #代表从0到5(不包含5) 实际等于range(0,5,1) #>>> [0, 1, 2, 3, 4] range(1,5,2) #代表从1到5,步长为2(不包含5) # >>>[1, 3]
元组(有序):
用“()”包裹,也叫只读的列表。关系:列表可以改变值,元组不可以做任何更改,一般用于存储配置信息。
list(tuple): 把元组转换为列表
tuple=("a","b","c")
list=list(tuple) #把元组转换为列表
print(list)
#>>>['a', 'b', 'c']
字典(无序):
dic={} #创建空字典
dic["prot"]=80 #向空字典添加键值对
dic["local"]="TJ"
dic["host"]="paulwinflo"
print (dic)
#>>>{'prot': 80, 'host': 'paulwinflo'}
del dic["host"]##删除host键值对
print (dic.keys())##获取字典的所有键,返回是一个list迭代器,可以用list() 转换为列表
print (dic.values())##获取字典所有值,返回是一个list迭代器,可以用list() 转换为列表
print (dic.items())##获取键值对元组
dic.clear()##清空指点
del dic ##删除字典
dict():工厂函数用来创建字典,若无任何参数,则创建空字典
a=dict() ##创建空字典
b=dict(zip(("x","y"),(2,4)))##借用zip创建字典,zip有点像拧麻花
print(b)
#>>>{'x': 2, 'y': 4}
c=dict([["x",1],["y",2]])##借用序列创建字典
print(c)
#>>>'y': 2, 'x': 1}
d=dict(x=1,y=3,c=3)##借用等式创建字典
print(d)
#>>>{'y': 3, 'x': 1, 'c': 3}
fromkeys():dict.fromkeys(seq[, value])
创建一个元素具有相同值的字典。fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
list={}.fromkeys(("x","y"),(2,4))
print(list)
#>>>{'x': (2, 4), 'y': (2, 4)}
dict.update(dict2):函数把字典dict2的键/值对更新到dict里
dict = {'Name': 'Zara', 'Age': 7}
dict2 = {'Sex': 'female'}
dict.update(dict2)
print(dict)
#>>>{'Name': 'Zara', 'Age': 7, 'Sex': 'female'}
遍历字典
#方法一
dic = {'x': 'A', 'y': 'B', 'z': 'C' }
for k, v in dic.items():
print (k, '=', v)
#方法二
dic = {'x': 'A', 'y': 'B', 'z': 'C' }
for item in dic:
print (item+ "="+dic.get(item)) ##使用get比使用dic[item]安全些
集合(无序):
集合(set)是一个无序的不重复元素序列,他可以做关系运算(交,差、并)。 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} ##元组
print(basket)
#>>>{'apple', 'banana', 'orange', 'pear'}
word = set('abracadabra')
print(word)
#>>>{'r', 'c', 'b', 'a', 'd'}
"""关系运算"""
list1={1,3,5,7,9}
list2={1,3,4,5,6}
##交集
print(list1.intersection(list2))
print(list1&list2)
#>>>{1, 3, 5}
##并集
print(list1.union(list2))
print(list1|list2)
#>>>{1, 3, 4, 5, 6, 7, 9}
##差集(in list1 not in list2)
print(list1.difference(list2))
print(list1-list2)
#>>>{9, 7}
"""操作"""
group={"a","b","c","d"}
group.add("e")
print(group)
#>>>{'e', 'a', 'd', 'b', 'c'}
group.remove("a")
print(group)
#>>>{'e', 'd', 'b', 'c'}
group.discard("b") ##都是删除元素,与remove 类似,但是discard 删除不存在的元素时候不会报错,而使用remove的时候会
print(group)
#>>>{'e', 'd', 'c'}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号