
并发编程之——多线程基础
一、一些概念
线程,顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于cpu),而一条流水线必须属于一个车间,一个车间的工作过程是一个进程,车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一条流水线。
多线程(即多个控制线程)的概念是,在一个进程中存在多个线程,多个线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。
那么,为什么要开线程呢?当我们需要多个程序同时运行,但是还需要数据共享——开进程的话能保证第一点但是数据不能共享,所以要用同一个进程下的多个线程。
所以说,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。光开进程不能工作,需要进程里开线程才能正常工作,当一个进程开启时,对应的一个线程会随着同时开启。一个进程可以开启多个线程————一个进程内的多个线程是共享数据的。开进程的开销远远比开进程的开销大,因为开进程得申请空间,开线程是基于开好的空间进行的。
二、开启线程的两种方式
2.1 利用threading模块下的Thread类:


# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from threading import Thread import time import os def work(name): print('%s is running...id:%s'%(name,os.getpid())) time.sleep(1) print('%s is done...'%os.getpid()) if __name__ == '__main__': w = Thread(target=work,args=('whw',)) #开启线程开始start方法 w.start() #主进程开启是默认开启了主线程,进程要想执行必须要有一个线程 #现在有一个进程两个线程 #执行角度看这是主线程,资源角度讲是主进程 print('主线程~')
2.2 利用类的继承
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from threading import Thread import time import os class MYThread(Thread): def __init__(self,name): super().__init__() self.name = name def run(self): print('%s is running...id:%s' % (self.name,os.getpid())) time.sleep(1) print('%s is done...'% os.getpid()) if __name__ == '__main__': w = MYThread('whw') #start w.start() print('主线程')
三、线程与进程的区别:
3.1 首先,从开销的角度来讲,开进程的开销要远远大于开线程的开销,因为开进程涉及到空间的创建,而开启线程仅仅是在既有的空间的基础上进行的;其次,同一个进程的各个线程之间是共享资源的,而不同的进程之间的资源是不共享的。
3.2 我们现在验证一下进程与线程的资源共享问题:
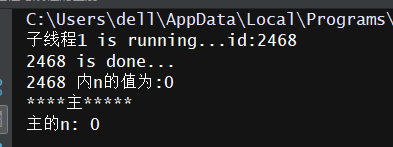
3.2.1 对于多线程来说:,我们全局定义的n=100,而经过子线程t1的处理,n的值不管是在主线程还是子线程都变成了0:
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from threading import Thread import time import os n = 100 #方法 def work(name): print('%s is running...id:%s'%(name,os.getpid())) global n n = 0 time.sleep(2) print('%s is done...'%os.getpid()) print('%s 内n的值为:%s'%(os.getpid(),n)) if __name__ == '__main__': t1 = Thread(target=work,args=('子线程1',)) t1.start() t1.join() print('主'.center(10,'*')) print('主的n:',n)
线程程序的运行结果:
3.2.2 对于多进程来说,多个进程之间是不共享资源的:
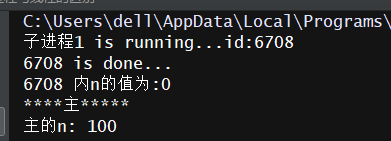
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from multiprocessing import Process import time import os n = 100 #方法 def work(name): print('%s is running...id:%s'%(name,os.getpid())) global n n = 0 time.sleep(2) print('%s is done...'%os.getpid()) print('%s 内n的值为:%s'%(os.getpid(),n)) if __name__ == '__main__': p1 = Process(target=work,args=('子进程1',)) p1.start() p1.join() print('主'.center(10,'*')) print('主的n:',n)
运行结果如下:
四、Thread对象的其他属性及方法:
Thread对象支持下列需求的方法:
4.1 找到当前线程的名字与id:
找到当前线程的名字需要引入current_thread类,用到getName方法:
print(current_thread().getName())
而找id还可以利用os模块小的getpid方法:
print(os.getpid())
4.2 查看当前存活的线程的名字与数量(注意需要在threading模块导入相应的类):
# 查看当前存活的线程 print(active_count()) #查看当前存活的具体的线程 print(enumerate())
4.3 查看线程是否存活:
#造线程对象的时候可以用name=写名字 t = Thread(target=work,name='whw1') t.start() #查看线程是否存活 print(t.is_alive())
4.4 设置线程名字
#造线程对象的时候可以用name=写名字 t = Thread(target=work,name='whw1') t.start() #设置线程的名字 t.setName('儿子线程1') #设置主线程的名字 current_thread().setName('主线程')
4.5 当然,还有join方法,等子线程执行完毕再执行主线程
#造线程对象的时候可以用name=写名字 t = Thread(target=work,name='whw1') t.start() #等子线程执行完再执行主线程 t.join() #找到主线程的名字--默认MainThread print('主'.center(10,'*'),current_thread().getName())
具体的完整代码以及执行效果如下:
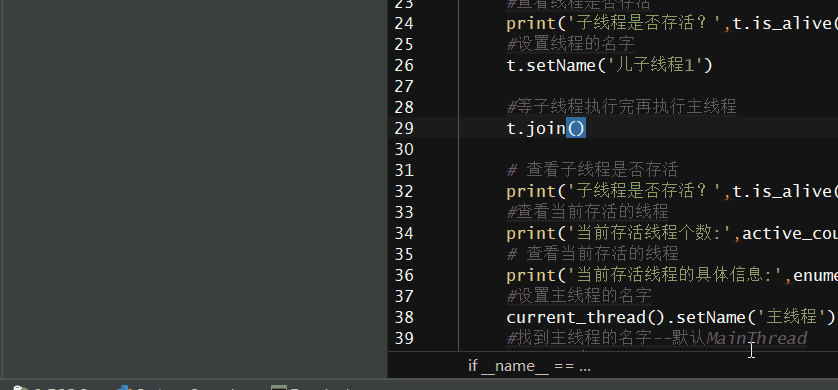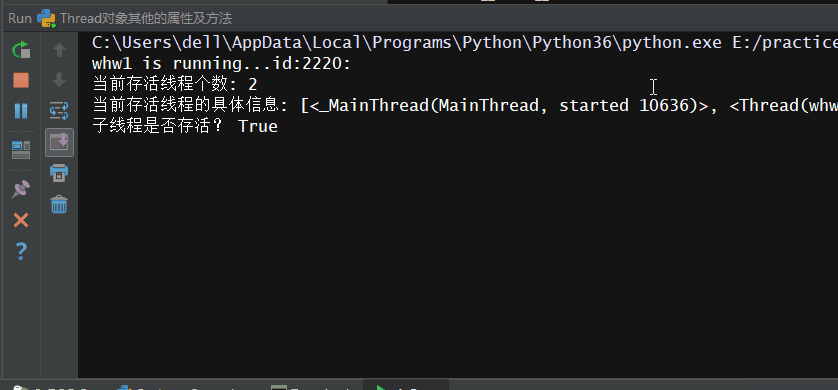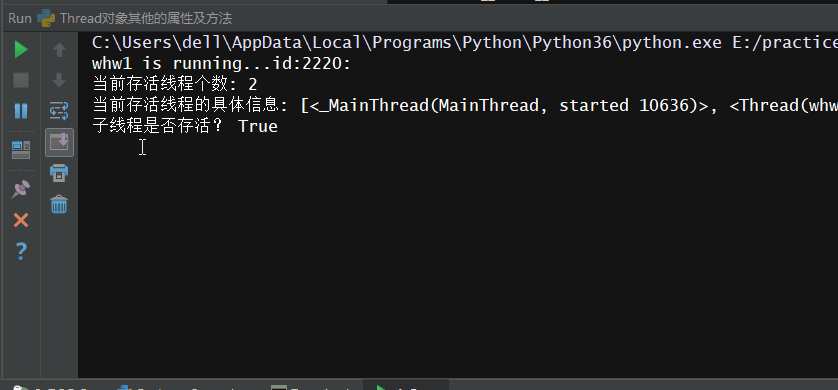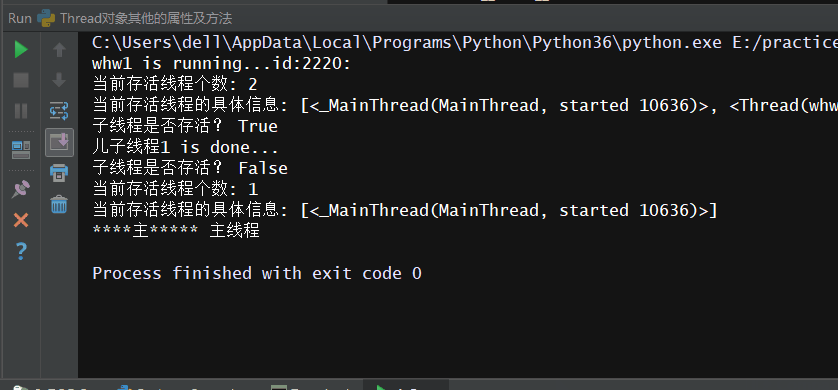
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from threading import Thread,current_thread,active_count,enumerate import os import time def work(): #找到当前线程的名字与id print('%s is running...id:%s:'%(current_thread().getName(),os.getpid())) time.sleep(2) print('%s is done...'%current_thread().getName()) if __name__ == '__main__': #造线程对象的时候可以用name=写名字 t = Thread(target=work,name='whw1') t.start() # 查看当前存活的线程 print('当前存活线程个数:',active_count()) #查看当前存活的具体的线程 print('当前存活线程的具体信息:',enumerate()) #查看线程是否存活 print('子线程是否存活?',t.is_alive()) #设置线程的名字 t.setName('儿子线程1') #等子线程执行完再执行主线程 t.join() # 查看子线程是否存活 print('子线程是否存活?',t.is_alive()) #查看当前存活的线程 print('当前存活线程个数:',active_count()) # 查看当前存活的线程 print('当前存活线程的具体信息:',enumerate()) #设置主线程的名字 current_thread().setName('主线程') #找到主线程的名字--默认MainThread print('主'.center(10,'*'),current_thread().getName())
执行效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号