
并发编程之——多进程
一、基本概念
1.1 进程
其实进程就是正在进行的一个程序或者任务,而负责执行任务的是CPU,执行任务的地方是内存。跟程序相比,程序仅仅是一堆代码而已,而程序运行时的过程才是进程。另外同一个程序执行两次就是两个进程了。
1.2 并发与并行
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真是干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务。对于“并发”而言,是伪并行,即看起来是同时运行,单个cpu+多道技术就可以实现并发;而“并行”才是真正意义上的“同时运行”——仅有多核才能够实现“并行”。
需要强调的一点是:与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
二、Multiprocessing模块
python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu\_count\(\)查看),在python中大部分情况需要使用多进程。
Python提供了multiprocessing。 multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,>提供了Process、Queue、Pipe、Lock等组件。
2.1 开启子进程的两种方式
2.1.1 直接在Multiprocessing模块中导入Process类,利用这个类实例化进程对象


# -*- coding: utf-8 -*- # -*- Author: WangHW -*- #方式一 from multiprocessing import Process import time import os def task(name): print('%s is running...'%name) print('子进程的id为:',os.getpid()) print('子进程的父进程的id为:',os.getppid()) time.sleep(3) print('%s is done'%name) if __name__ == '__main__': #Process(target=task, kwargs={'name':'子进程1'}) #得到一个对象 p = Process(target=task,args=('子进程1',)) #start仅仅只是给操作系统发送了一个信号,发完信号以后父进程不会等子进程 #是完全独立的两个进程 p.start() print('主进程') print('主进程的id为:',os.getpid()) print('主进程的父进程id为:',os.getppid())
2.2.2 利用类的继承,自己定义一个MyProcessing类,继承自Process,但是需要注意的是:里面必须要有一个名为run的方法去执行主体:
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from multiprocessing import Process import time #用类的继承方式实现 class MyProcessing(Process): def __init__(self,name): super().__init__() self.name = name #注意名字必须叫run def run(self): print('%s is running......'%self.name) time.sleep(3) print('%s is done...'%self.name) if __name__ == '__main__': p = MyProcessing('进程1') p.start() print('主进程')
2.2 Process类实例化出对象的join方法
在主进程运行过程中如果想并发地执行其他的任务,我们可以开启子进程,此时主进程的任务与子进程的任务分两种情况
情况一:在主进程的任务与子进程的任务彼此独立的情况下,主进程的任务先执行完毕后,主进程还需要等待子进程执行完毕,然后统一回收资源。
情况二:如果主进程的任务在执行到某一个阶段时,需要等待子进程执行完毕后才能继续执行,就需要有一种机制能够让主进程检测子进程是否运行完毕,在子进程执行完毕后才继续执行,否则一直在原地阻塞,这就是join方法的作用
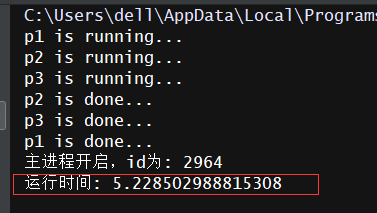
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from multiprocessing import Process import time import os def task(name,n): print('%s is running...'%name) time.sleep(n) print('%s is done...'% name) if __name__ == '__main__': start_time = time.time() # for i in range(5,8): # p = Process(target=task,args=('p%s'%(i+1),i)) # p.start() #p.join() p1 = Process(target=task,args=('p1',5)) p2 = Process(target=task,args=('p2',2)) p3 = Process(target=task,args=('p3',3)) #start仅仅是向操作系统发出信号,具体谁先执行不一定,由操作系统决定 p1.start() p2.start() p3.start() #保证有序,看着像“串行”,但实际上还是并行:最后一行的运行时间可以验证 p1.join() p2.join() p3.join() print('主进程开启,id为:',os.getpid()) #打印出来的结果可知,程序仍然是并发执行的,不是串行执行的 print('运行时间:',time.time()-start_time)
关于join方法,需要注意的一点是:虽然我们看着像“串行”,但实际上还是并行:由上面程序最后一行的运行时间可以验证:
三、互斥锁
3.1 简介
虽然进程之间数据不共享,但是可以共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,而共享带来的是竞争,竞争带来的结果就是错乱。
如何控制,就是加锁处理。而互斥锁的意思就是互相排斥,如果把多个进程比喻为多个人,互斥锁的工作原理就是多个人都要去争抢同一个资源:卫生间,一个人抢到卫生间后上一把锁,其他人都要等着,等到这个完成任务后释放锁,其他人才有可能有一个抢到......所以互斥锁的原理,就是把并发改成穿行,降低了效率,但保证了数据安全不错乱。
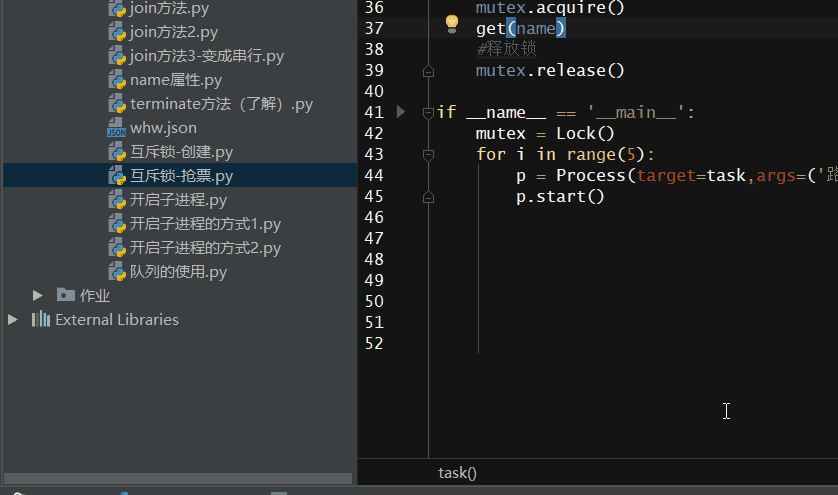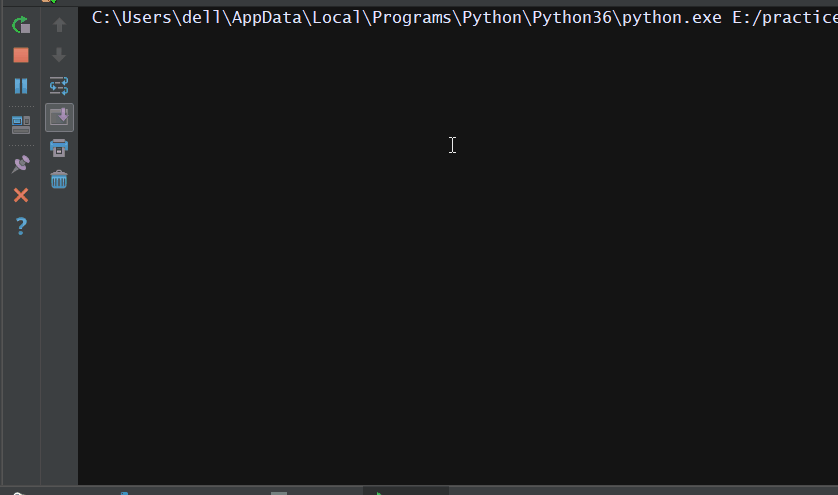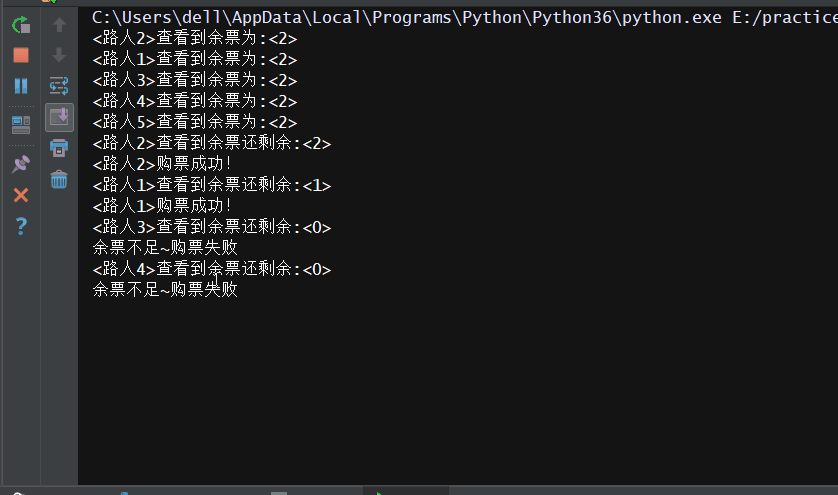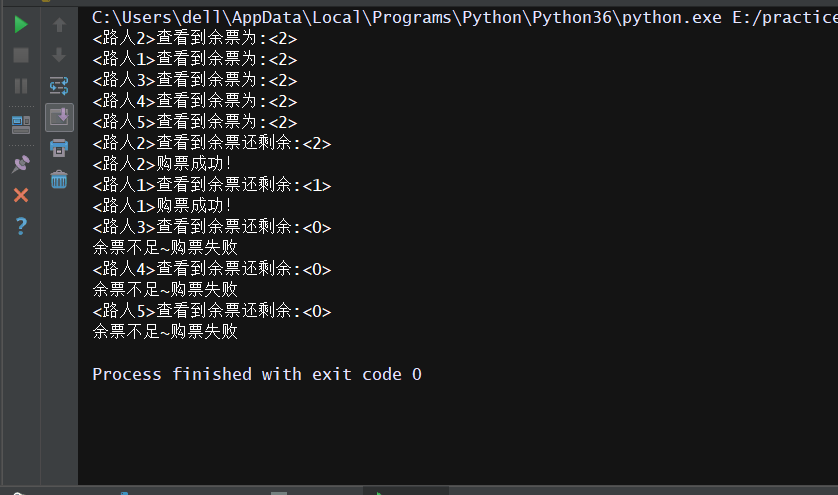
这里有一个利用互斥锁模拟抢票的程序(whw.json文件的内容为:{"count": 2}):
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from multiprocessing import Process,Lock import json import time #查票 def search(name): time.sleep(1) with open('whw.json','r') as f: ticket_dict = json.load(f) print('<%s>查看到余票为:<%s>'%(name,ticket_dict['count'])) #买票 def get(name): time.sleep(1) f = open('whw.json','r') ticket_dict = json.load(f) print('<%s>查看到余票还剩余:<%s>'%(name,ticket_dict['count'])) if ticket_dict['count'] > 0: ticket_dict['count'] -= 1 print('<%s>购票成功!' % name) time.sleep(1) else: print('余票不足~购票失败') f.close() #保存 f_new = open('whw.json','w') json.dump(ticket_dict,f_new) f_new.close() def task(name,mutex): search(name) #在购票前加锁 mutex.acquire() get(name) #释放锁 mutex.release() if __name__ == '__main__': mutex = Lock() for i in range(5): p = Process(target=task,args=('路人%s'%(i+1),mutex)) p.start()
结果展示:
3.2关于互斥锁与join的区别:
用一句话来简单概括:“互斥锁”是将代码的“局部变成串行”,而如果用join的话会整个功能代码变为串行,所以对于本例而言互斥锁要灵活一些。
四、队列
4.1 简介
对于多进程有一个问题需要我们考虑:是否有一种方案能够同时兼顾一下两点:一是效率高(多个进程共享一块内存数据),另外一点是能够帮我们处理好锁的问题。
答案就是~~利用队列!
首先,队列是将数据存到内存中处理,这就满足了“效率高”这个要求,另外,队列是基于“管道+锁”设计的,所以另外一点也满足了。事实上,队列才是进程间通信(IPC)的最佳选择!
另外需要大家注意的是:队列是一种先进先出的数据结构。
创建队列用以下方式:
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from multiprocessing import Queue #队列中不应该放大文件,发的只是精简的消息 #可以不指定大小,但最终受限于内存的大小 q = Queue(3) q.put('hello') q.put({'a':1}) q.put(3333333) #判断一下队列满没有 print(q.full()) #取出来~先进先出 print(q.get()) print(q.get()) print(q.get())
4.2 队列的应用——生产者消费者模型
“生产者消费者模型”是并发编程的非常重要的一个模型,也是队列的一个非常重要的应用之一:
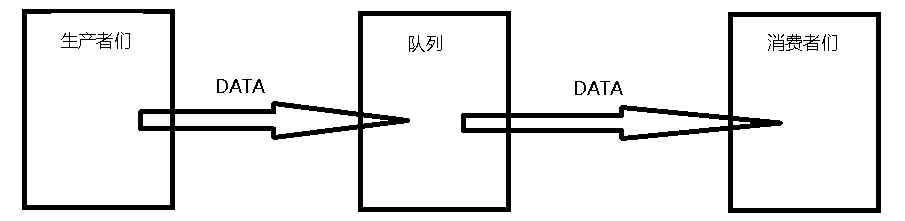
上图是一个简单的生产者与消费者模型:生产者将生产的DATA先放到队列里,消费者从队列中获取生产者生产的数据,这样使得程序的耦合性大大降低,而且也平衡了生产者与消费者之间的速度差:
具体代码如下:
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from multiprocessing import Process,Queue import time def producer(q): for i in range(5): res = '包子%s'%i time.sleep(0.5) print('生产者生产了%s'%res) q.put(res) def consumer(q): while 1: res = q.get() if res is None: break time.sleep(1) print('消费者吃了%s'%res) if __name__ == '__main__': q = Queue() p1 = Process(target=producer,args=(q,)) p2 = Process(target=producer,args=(q,)) c1 = Process(target=consumer,args=(q,)) c2 = Process(target=consumer,args=(q,)) p1.start() p2.start() c1.start() c2.start() p1.join() p2.join() #有两个消费者,需要最后put两次None q.put(None) q.put(None) #print('主进程'.center(20,'*'))
实现效果如下:
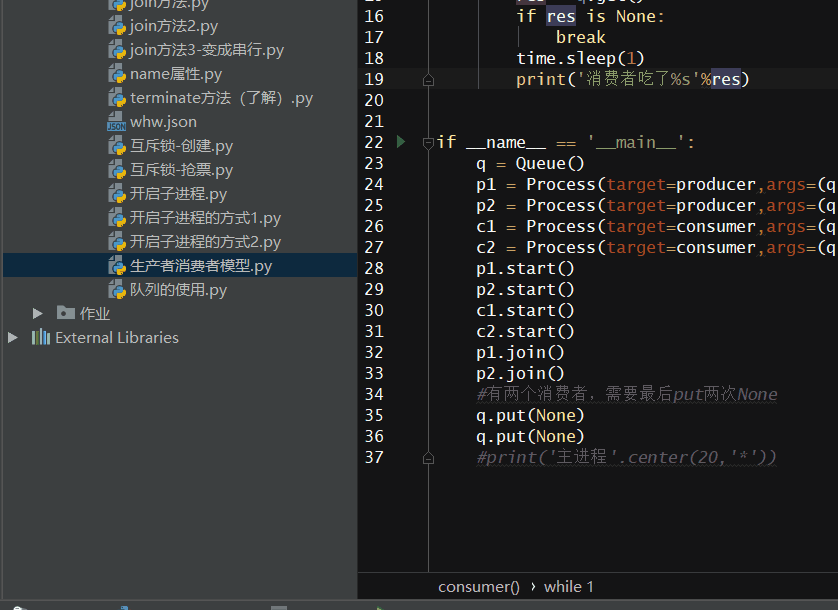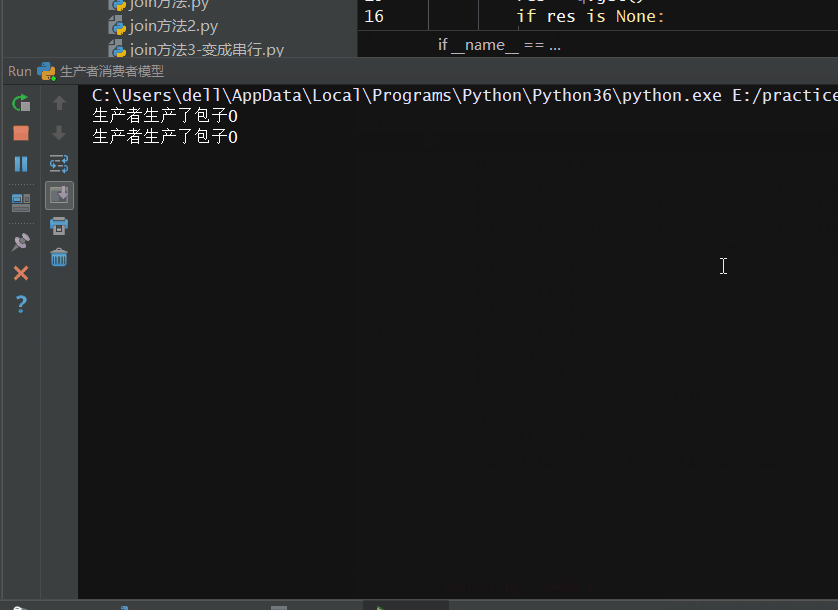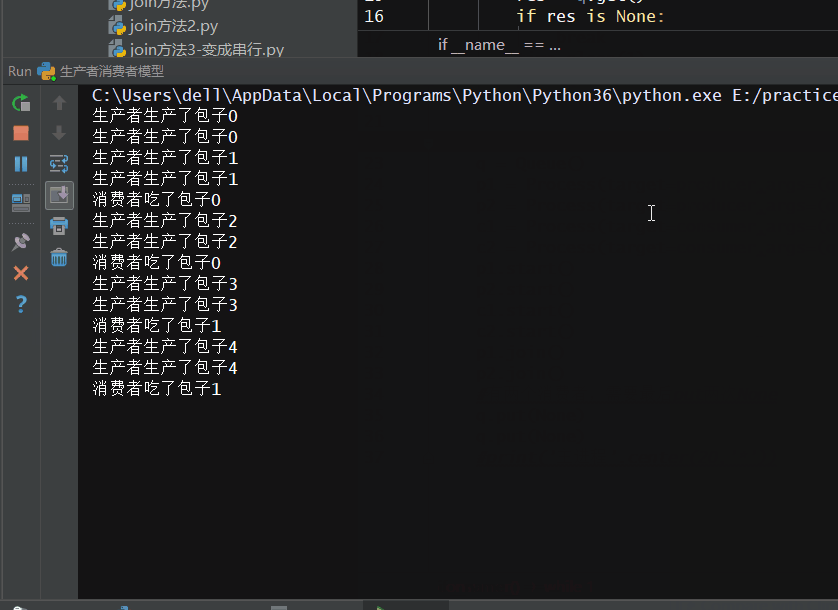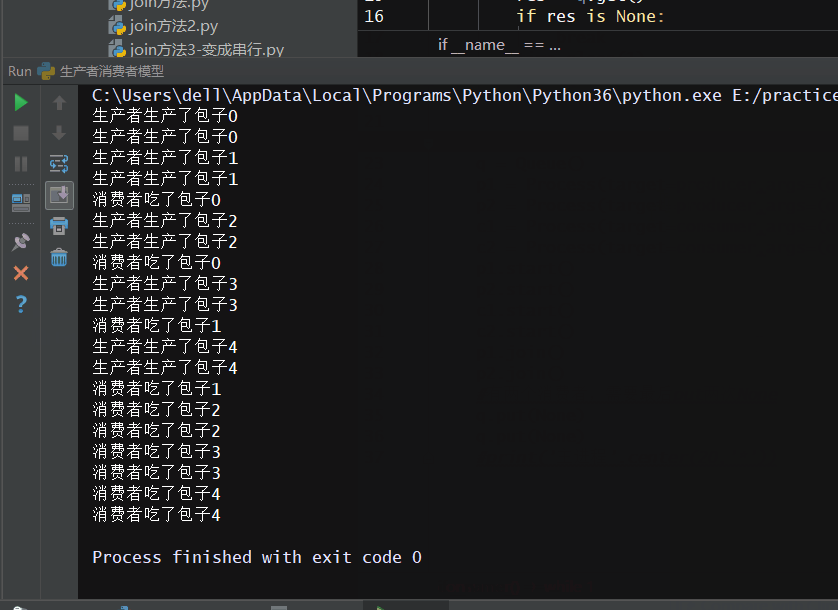
当然上面的代码可以利用“守护进程”优化一下(作为了解),将消费者进程设置为守护进程,随着主程序进程一起消除:
# -*- coding: utf-8 -*- # -*- Author: WangHW -*- from multiprocessing import Process,JoinableQueue import time def producer(q): for i in range(5): res = '包子%s'%i time.sleep(0.5) print('生产者生产了%s'%res) q.put(res) q.join() def consumer(q): while 1: res = q.get() if res is None: break time.sleep(1) print('消费者吃了%s'%res) q.task_done() if __name__ == '__main__': q = JoinableQueue() p1 = Process(target=producer,args=(q,)) p2 = Process(target=producer,args=(q,)) c1 = Process(target=consumer,args=(q,)) c2 = Process(target=consumer,args=(q,)) #将消费者进程设置为守护进程,随着主程序一起消除 c1.daemon = True c2.daemon = True p1.start() p2.start() c1.start() c2.start() p1.join() p2.join()
五、其他补充
5.1 需要注意的一点
进程之间的内存空间是相互隔离的,看如下程序:
from multiprocessing import Process n = 100 def work(): global n n = 0 print('子进程内的n为:',n) if __name__ == '__main__': p = Process(target=work) p.start() print('主进程的n为:',n)
运行结果为:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号