
go-zero中好用的流处理利器fx与mr介绍
使用并发包前需要注意一个点 ***
实际业务中使用fx、mr确实能提高调用方的效率,但是对于加大了对被调用方的负担。
举个例子:服务A提供了通过一个用户id查询用户订单数据的接口,服务B有多个用户id需要查,此时当然可以使用fx或者mr调用A的RPC接口用多个用户id并发去查服务A的数据,这样避免了使用for循环去查RPC,节省了效率。但是,对于服务A来说负担就会比较大了!
此时的优化方案应该是服务A再提供一个通过多个用户id批量去查这些用户订单数据的接口,这样避免了在服务B中使用并发查A导致A的负担加大。
所以,实际中不要盲目去使用并发,也许在使用端虽然使用并发去做业务提高了效率,但是也要考虑到对下游服务的负担评估,通过多个角度综合去考虑自己的业务代码的实现方式。
另外,开并发之前要评估一下,是否要限制并发的数量!
参考资料
fx
mr
mapreduce的一个问题 ***
go-zero 官方文档中对mr的介绍-通过mr降低服务响应时间
mapreduce的原理讲解2-自己实现的一个mapreduce
fx与mr简介及适用场景
mr的finish和fx的Parallel都可以做并行处理,区别是Parallel不会有error返回,如果需要有error返回或者有一个依赖报错需要立即结束的,建议用mr的finish。
golang中流处理的简单使用


package a_go_zero_tests import ( "fmt" "testing" ) // golang中的流处理 type Student struct { Name string Age int Score float64 } func (s *Student) setName(name string) *Student { s.Name = name return s } func (s *Student) setAge(age int) *Student { s.Age = age return s } func (s *Student) setScore(score float64) *Student { s.Score = score return s } func TestST1(t *testing.T) { s1 := Student{} // 简单的流处理 s1.setScore(99).setAge(22).setName("naruto") fmt.Println("s1: ", s1) // s1: {naruto 22 99} }
fx
fx的详细的使用场景可以参考这篇文章:go-zero 数据的流处理利器 fx
fx包并发执行函数遇到的一个惰性计算的坑: 使用fx.Parallel方法并发执行函数时遇到的惰性计算的坑
Group+ForEach
package a_go_zero_tests import ( "fmt" "github.com/zeromicro/go-zero/core/fx" "testing" ) var dbNameLst = []string{"db1", "db2", "db3", "db4", "db3", "db1"} func TestT1(t *testing.T) { retLst := make([]string, 0) //var lock sync.Mutex fx.From(func(source chan<- interface{}) { for _, name := range dbNameLst { source <- name } }).Group(func(item interface{}) interface{} { //lock.Lock() //defer lock.Unlock() dbNam := item.(string) return dbNam }).ForEach(func(item interface{}) { for _, v := range item.([]interface{}) { currName := v.(string) retLst = append(retLst, currName) } }) fmt.Println("retLst: ", retLst) // retLst: [db3 db3 db4 db1 db1 db2] }
并发消费者的例子-From+Walk+Filter+ForEach
package main import ( "fmt" "github.com/zeromicro/go-zero/core/fx" "os" "os/signal" "syscall" "time" ) func main() { ch := make(chan int) // 多开几个生产者并发生产数据 go inputStream(ch) go inputStream(ch) go inputStream(ch) go inputStream(ch) // fx 并发数据流处理 go outputStream(ch) c := make(chan os.Signal, 1) signal.Notify(c, syscall.SIGTERM, syscall.SIGINT) <-c } func inputStream(ch chan int) { count := 0 for { ch <- count time.Sleep(time.Millisecond * 500) count++ } } func outputStream(ch chan int) { fx.From(func(source chan<- interface{}) { // Notice 轮询ch,有数据就往 source中 塞入 for c := range ch { source <- c } }). // Notice Walk 并发作用在流的每个item上!每个item都会执行Walk里面的逻辑! // Notice 可以控制并发数量。如设置 fx.UnlimitedWorkers() 则并发数无限制,但并发写入流中的数据由defaultWorkers限制 Walk(func(item interface{}, pipe chan<- interface{}) { count := item.(int) //fmt.Println("count:", count) pipe <- count }, fx.WithWorkers(10)). // 过滤 Filter(func(item interface{}) bool { itemInt := item.(int) if itemInt%2 == 0 { return true } return false }). // 遍历出每个 Filter过滤后的 item元素 ForEach(func(item interface{}) { fmt.Println(item) }) }
可以看到,消费者中并发去处理了生产者中的数据~,这样做起来效率非常高。
Just
func TestFxSplit(t *testing.T) { fx.Just(1, 2, 3, 4, 5, 6, 7, 8, 9, 10). Split(4). ForEach(func(item interface{}) { vals := item.([]interface{}) fmt.Println(len(vals), vals) }) } /* 4 [1 2 3 4] 4 [5 6 7 8] 2 [9 10] */
求1~100中每个数平方后的偶数之和
package a_go_zero_tests import ( "fmt" "github.com/zeromicro/go-zero/core/fx" ) // Notice 计算 1~100 中,每个数平方后的偶数之和 func Sum1(num int) { sum := 0 for i := 0; i < num; i++ { currSqu := i * i if currSqu%2 == 0 { sum += currSqu } } fmt.Println("sum: ", sum) } func Sum2(num int) { result, err := fx.From(func(source chan<- interface{}) { for i := 0; i < num; i++ { source <- i } }).Map(func(item interface{}) interface{} { i := item.(int) return i * i // 给每个数平方 }).Filter(func(item interface{}) bool { i := item.(int) return i%2 == 0 // 筛选平方后的数中的偶数 }).Distinct(func(item interface{}) interface{} { return item }).Reduce(func(pipe <-chan interface{}) (interface{}, error) { var result int for item := range pipe { i := item.(int) result += i // 累加 } return result, nil }) if err != nil { fmt.Println(err) } else { fmt.Println("result: ", result) } }
package a_go_zero_tests import "testing" var num int = 100 // 运行测试用例参考:https://geektutu.com/post/hpg-benchmark.html // go test -bench='Sum1$' . func BenchmarkSum1(b *testing.B) { Sum1(num) } // go test -bench='Sum2$' . // Notice 这个效率稍微低点 func BenchmarkSum2(b *testing.B) { Sum2(num) }
使用Stream.Parallel方法并发处理1——先使用From方法接收数据
package main import ( "fmt" "github.com/gogf/gf/util/gconv" "github.com/zeromicro/go-zero/core/fx" "os" "os/signal" "syscall" "time" ) func main() { ch := make(chan string) // 多个生产者 go inputStream(ch) go inputStream(ch) go inputStream(ch) // fx 并发数据流处理 go outputStream(ch) c := make(chan os.Signal, 1) signal.Notify(c, syscall.SIGTERM, syscall.SIGINT) <-c } func inputStream(ch chan string) { id := 0 for { ch <- gconv.String(id) time.Sleep(time.Millisecond * 500) id++ } } func outputStream(ch chan string) { fx.From(func(source chan<- interface{}) { // Notice 轮询ch,有数据往 source中 塞入 for c := range ch { source <- c } }).// 并发处理 Parallel(func(item interface{}) { id := item.(string) handler1(id) }) } func handler1(id string) { fmt.Printf("处理 %v 的日志! \n", id) }
使用fx.Parallel方法并发处理2——处理并发任务
package a_go_zero_tests import ( "fmt" "github.com/zeromicro/go-zero/core/fx" "testing" ) func TestParallel2(t *testing.T) { id := "123" fx.Parallel(func() { handler2(id) }, func() { handler1(id) }, func() { handler3(id) }, func() { handler4(id) }) } func handler1(id string) { fmt.Printf("处理 %v 的日志! \n", id) } func handler2(id string) { fmt.Printf("处理 %v 的kafka!\n", id) } func handler3(id string) { fmt.Printf("处理 %v 的NSQ!\n", id) } func handler4(id string) { fmt.Printf("处理 %v 的ES!\n", id) }
fx.Walk方法返回另外的类型然后交给ForEach方法处理
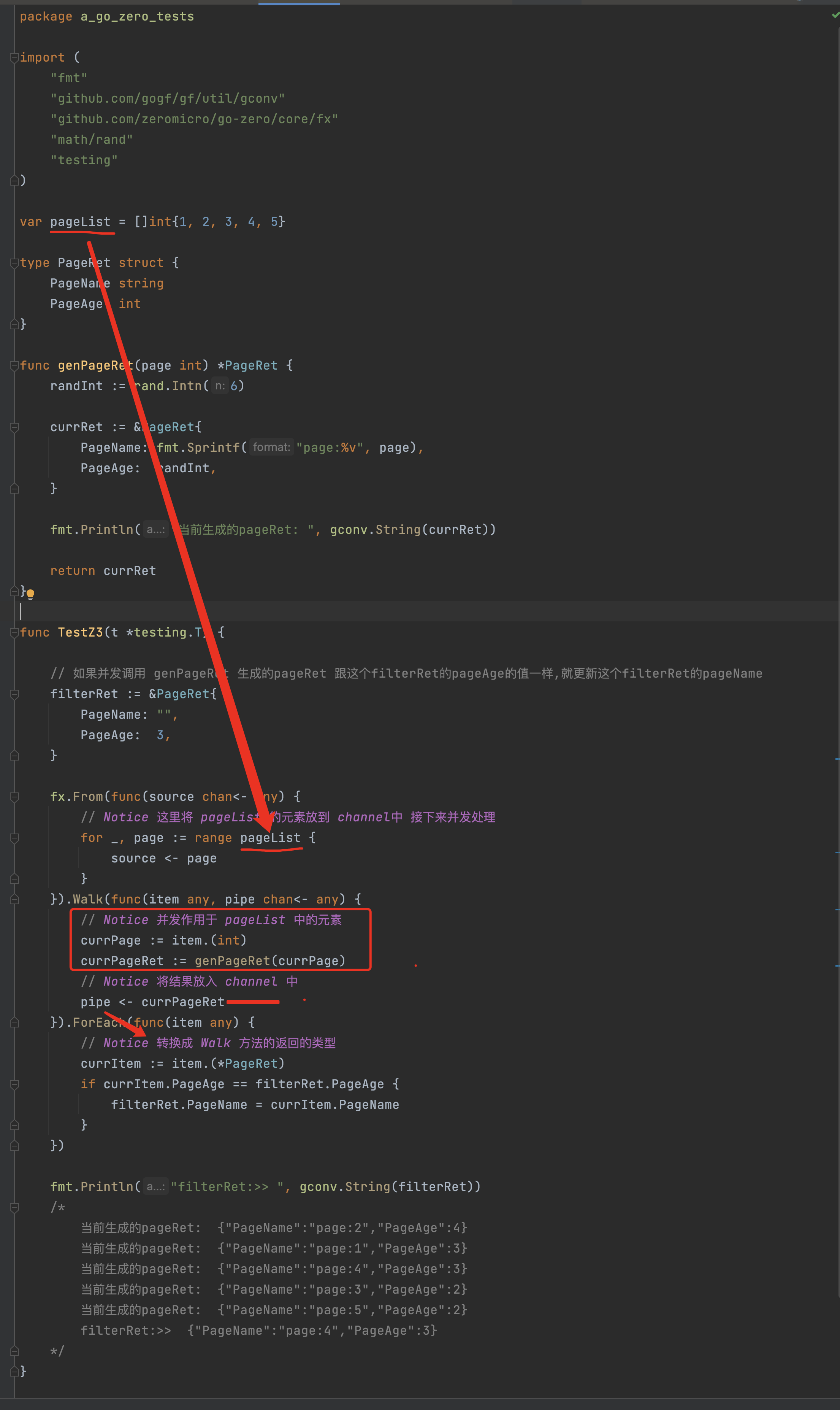
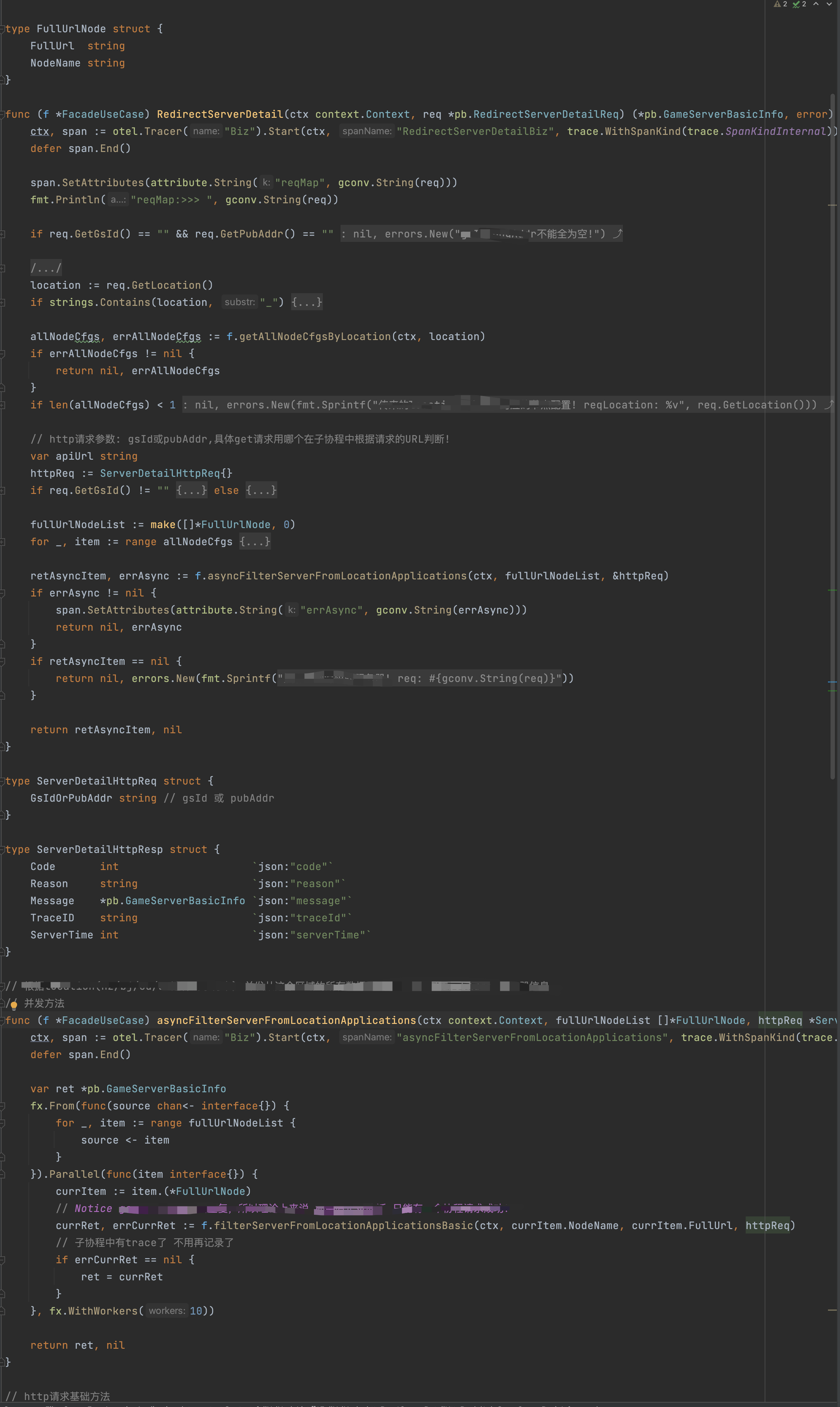
*** fx并发请求RPC:From+Walk+ForEach —— 从并发请求获取的结果中过滤

*** fx并发请求http(带并发控制):From+Parallel(在Parallel流处理中加fx.WithWorkers进行并发控制)—— 并发请求http接口获取结果

fx.Parallel方法使用限制
注意fx.Parallel进行依赖并行处理的时候不会有error返回,如需有error返回或者有一个依赖报错需要立马结束依赖请求请使用MapReduce工具进行处理。
mr包的使用 —— 新版本改成了泛型的写法 *****
为什么需要 MapReduce
在实际的业务场景中我们常常需要从不同的 rpc 服务中获取相应属性来组装成复杂对象。
比如要查询商品详情:
- 商品服务-查询商品属性
- 库存服务-查询库存属性
- 价格服务-查询价格属性
- 营销服务-查询营销属性
如果是串行调用的话响应时间会随着 rpc 调用次数呈线性增长,所以我们要优化性能一般会将串行改并行。
简单的场景下使用 waitGroup 也能够满足需求,但是如果我们需要对 rpc 调用返回的数据进行校验、数据加工转换、数据汇总呢?另外实际业务场景中多个依赖如果有一个出错我们期望能立即返回而不是等所有依赖都执行完再返回结果,而且WaitGroup中对变量的赋值往往需要加锁,每个依赖函数都需要添加Add和Done对于新手来说比较容易出错,继续使用 waitGroup 就有点力不从心了,go 的官方库中并没有这种工具(java 中提供了 CompleteFuture),go-zero 作者依据 mapReduce 架构思想实现了进程内的数据批处理 mapReduce 并发工具类。
Finish方法异步调用RPC获取属性 ***
注意:如果操作的是一个 非并发安全的数据结构 比如slice或者map productDetail方法中给结构体赋值那段逻辑之前需要加锁!!!
package main import ( "fmt" "log" "time" "github.com/zeromicro/go-zero/core/mr" "github.com/zeromicro/go-zero/core/timex" ) type user struct{} func (u *user) User(uid int64) (interface{}, error) { time.Sleep(time.Millisecond * 30) return fmt.Sprintf("user:%v", uid), nil } type store struct{} func (s *store) Store(pid int64) (interface{}, error) { time.Sleep(time.Millisecond * 50) return fmt.Sprintf("store:%v", pid), nil } type order struct{} func (o *order) Order(pid int64) (interface{}, error) { time.Sleep(time.Millisecond * 40) return fmt.Sprintf("order:%v", pid), nil } var ( userRpc user storeRpc store orderRpc order ) func main() { start := timex.Now() // Notice 用 Finish 方法 并发获取不同RPC的结果去构建pd的属性 proItem, err := productDetail(123, 456) if err != nil { log.Printf("product detail error: %v", err) return } log.Printf("productDetail, val: %v, time: %v", proItem, timex.Since(start)) // val: &{user:123 store:456 order:456}, time: 1.052405s } type ProductDetail struct { User interface{} Store interface{} Order interface{} } func productDetail(uid, pid int64) (*ProductDetail, error) { var pd ProductDetail // Notice 并发获取不同RPC的结果去构建pd的属性 err := mr.Finish(func() (err error) { time.Sleep(1 * time.Second) pd.User, err = userRpc.User(uid) return }, func() (err error) { time.Sleep(1 * time.Second) pd.Store, err = storeRpc.Store(pid) return }, func() (err error) { time.Sleep(1 * time.Second) pd.Order, err = orderRpc.Order(pid) return }) if err != nil { return nil, err } return &pd, nil }
MapReduce方法中如果有一个协程出错就停止或不停止其他协程的写法 *****
出错了使用cancel方法控制停止或不停止其他协程!
1、在mr.MapReduce流处理中如果加上 cancel(err) 返回 [],并且执行时间是1s多
2、在mr.MapReduce流处理中不加 cancel(err)返回 [111,222],因为里面的代码写了只有checkUid为true的时候才会writer.Write对应的uid,并且执行时间是2s多
package main import ( "errors" "fmt" "github.com/zeromicro/go-zero/core/mr" "time" ) // Notice MapReduce方法: 如果一个协程出错了,停止 或 不停止 其他协程~ func main() { start := time.Now() res, err := checkLegal([]int64{111, 222, 333}) if err != nil { fmt.Println("err: ", err) } fmt.Println("checkRes: ", res, "执行时间: ", time.Since(start)) /* err: uid 333 不合法 checkRes: [] 执行时间: 1.001175541s */ } func checkLegal(uids []int64) ([]int64, error) { r, err := mr.MapReduce(func(source chan<- int64) { for _, uid := range uids { source <- uid } }, func(item int64, writer mr.Writer[int64], cancel func(error)) { uid := item ok, err := checkUid(uid) if err != nil { // Notice 如果不加 cancel(err),会返回校验成功的id; 如果加上cancel(err),返回的结果会是一个空列表 // Notice 实际上,如果这里返回错误,其他协程直接就退出了! // Notice 看实际中业务的需求情况来定了... cancel(err) } // Notice 这个必须加 if ok { fmt.Printf("write %v \n", uid) writer.Write(uid) } }, func(pipe <-chan int64, writer mr.Writer[[]int64], cancel func(error)) { var rets []int64 for p := range pipe { rets = append(rets, p) } // Notice 这个必须加 writer.Write(rets) }) if err != nil { return nil, err } return r, nil } func checkUid(uid int64) (bool, error) { if uid == 111 || uid == 222 { time.Sleep(time.Second * 2) fmt.Printf("check uid %v success! \n", uid) } if uid == 333 { time.Sleep(time.Second) return false, errors.New(fmt.Sprintf("uid %v 不合法", uid)) } return true, nil }
MapReduce基本使用 *** 新版本加了泛型的写法
package main import ( "fmt" "log" "strconv" "github.com/zeromicro/go-zero/core/mr" ) type User struct { Uid int Name string } // Notice 新版本 使用 泛型的写法!!! func main() { uids := []int{111, 222, 333} res, err := mr.MapReduce(func(source chan<- int) { for _, uid := range uids { source <- uid } }, func(item int, writer mr.Writer[*User], cancel func(error)) { uid := item user := &User{ Uid: uid, Name: strconv.Itoa(uid), } writer.Write(user) }, func(pipe <-chan *User, writer mr.Writer[[]*User], cancel func(error)) { // missing writer.Write(...), should not panic var ps []*User for p := range pipe { ps = append(ps, p) } writer.Write(ps) }) if err != nil { log.Print(err) return } fmt.Println(len(res), res) // 3 [0x140000a8060 0x14000186000 0x1400000c018] for _, user := range res { fmt.Println(">> ", user.Name, user.Uid) } /* >> 333 333 >> 111 111 >> 222 222 */ }
MapReduceVoid并发构建 ***
package main import ( "fmt" "github.com/zeromicro/go-zero/core/timex" "time" "github.com/zeromicro/go-zero/core/mr" ) // Notice MapReduceVoid并发构建 func main() { retSlice := make([]int, 0) start := timex.Now() mr.MapReduceVoid(func(source chan<- int) { for i := 0; i < 10; i++ { source <- i } }, func(item int, writer mr.Writer[int], cancel func(error)) { // Notice 这里是并发处理的~~~ i := item if i == 0 { time.Sleep(10 * time.Second) fmt.Println("睡了10秒...") } else { time.Sleep(5 * time.Second) fmt.Println("睡了5秒...") } // Notice 这个必须写 writer.Write(i) }, func(pipe <-chan int, cancel func(error)) { // 轮询channel是线程安全的 for i := range pipe { retSlice = append(retSlice, i) } }) fmt.Println("运行时间:", timex.Since(start)) // 运行时间: 10.000938s fmt.Println("retSlice: ", retSlice) // [7 3 6 8 1 5 4 9 2 0] }
FinishVoid与Finish ***
package main import ( "fmt" "time" "github.com/zeromicro/go-zero/core/mr" "github.com/zeromicro/go-zero/core/timex" ) // Notice FinishVoid与Finish func main() { start := timex.Now() mr.FinishVoid(func() { time.Sleep(time.Second) }, func() { time.Sleep(time.Second * 2) }, func() { time.Sleep(time.Second * 5) }, func() { time.Sleep(time.Second * 3) }, func() { // Notice 里面再嵌套一个带error的Finish if err := mr.Finish(func() error { time.Sleep(time.Second) return nil }, func() error { time.Sleep(time.Second * 8) return nil }); err != nil { fmt.Println(err) } }) fmt.Println(timex.Since(start)) // 8.001392s }
ForEach ***
package main import ( "fmt" "github.com/zeromicro/go-zero/core/mr" "sync" ) // Notice ForEach方法 var ( persons = []string{"john", "mary", "alice", "bob"} friends = map[string][]string{ "john": {"harry", "hermione", "ron"}, "mary": {"sam", "frodo"}, "alice": {}, "bob": {"jamie", "tyrion", "cersei"}, } ) func main() { var ( allFriends []string lock sync.Mutex ) mr.ForEach(func(source chan<- interface{}) { for _, each := range persons { source <- each } }, func(item interface{}) { // Notice 这里可以并发根据persons中的每个元素获取结果:调用RPC或http // 切片是非并发安全的,在append之前需要加锁 lock.Lock() defer lock.Unlock() allFriends = append(allFriends, friends[item.(string)]...) }) fmt.Println("allFriends: ", allFriends) // 每次的顺序不一样 [sam frodo harry hermione ron jamie tyrion cersei] }
使用mr统计指定目录中.go文件的数量 *****
go run main.go -d ../../mapreduce -s -m 1 -mode return
~~
package main import ( "bufio" "errors" "flag" "fmt" "io" "log" "os" "path" "path/filepath" "strings" "sync/atomic" "time" "github.com/google/gops/agent" "github.com/zeromicro/go-zero/core/mr" ) var ( dir = flag.String("d", "", "dir to enumerate") stopOnFile = flag.String("s", "", "stop when got file") maxFiles = flag.Int("m", 0, "at most files to process") mode = flag.String("mode", "", "simulate mode, can be return|panic") count uint32 ) func enumerateLines(filename string) chan string { output := make(chan string) go func() { file, err := os.Open(filename) if err != nil { return } defer file.Close() reader := bufio.NewReader(file) for { line, err := reader.ReadString('\n') if err == io.EOF { break } if !strings.HasPrefix(line, "#") { output <- line } } close(output) }() return output } // Notice 加了 泛型的写法 func mapper(filename string, writer mr.Writer[int], cancel func(error)) { if len(*stopOnFile) > 0 && path.Base(filename) == *stopOnFile { fmt.Printf("Stop on file: %s\n", *stopOnFile) cancel(errors.New("stop on file")) return } var result int for line := range enumerateLines(filename) { if strings.HasPrefix(strings.TrimSpace(line), "func") { result++ } } switch *mode { case "return": if atomic.AddUint32(&count, 1)%10 == 0 { return } case "panic": if atomic.AddUint32(&count, 1)%10 == 0 { panic("wow") } } writer.Write(result) } // Notice 加了 泛型的写法 func reducer(input <-chan int, writer mr.Writer[int], cancel func(error)) { var result int for count1 := range input { v := count1 if *maxFiles > 0 && result >= *maxFiles { fmt.Printf("Reached max files: %d\n", *maxFiles) cancel(errors.New("max files reached")) return } result += v } writer.Write(result) } func main() { if err := agent.Listen(agent.Options{}); err != nil { log.Fatal(err) } flag.Parse() if len(*dir) == 0 { flag.Usage() } fmt.Println("Processing, please wait...") start := time.Now() result, err := mr.MapReduce(func(source chan<- string) { filepath.Walk(*dir, func(fpath string, f os.FileInfo, err error) error { if !f.IsDir() && path.Ext(fpath) == ".go" { source <- fpath } return nil }) }, mapper, reducer) if err != nil { fmt.Println(err) } else { fmt.Println(result) fmt.Println("Elapsed:", time.Since(start)) fmt.Println("Done") } }
~~~
