
kratos项目中使用分布式锁介绍
单机程序加锁的场景以及sync.Mutex介绍
简单的并发问题以及解决方案
在单机程序并发或并行修改全局变量时,需要对修改行为加锁以创造临界区。看一下下面的例子:


type Counter struct { count int } func (c *Counter) incr() { c.count++ } func (c *Counter) countVal() int { return c.count } func TestT1(t *testing.T) { c1 := Counter{} wg := sync.WaitGroup{} for i := 0; i < 10000; i++ { wg.Add(1) go func() { defer wg.Done() // 不加锁,会有并发问题 c1.incr() }() } wg.Wait() fmt.Println("count: ", c1.countVal()) // 9618 }
不加锁的话并发去修改全局变量,由于 += 操作并不是原子操作,所以会导致结果有异常。
正确的写法应该在非原子操作+=时加一个锁,保证并发安全:
type Counter struct { count int sync.Mutex // 进程内的锁 } func (c *Counter) incr() { c.count++ } func (c *Counter) countVal() int { return c.count } func TestT2(t *testing.T) { c1 := Counter{} wg := sync.WaitGroup{} for i := 0; i < 10000; i++ { wg.Add(1) go func() { defer wg.Done() // 加锁保证操作线程安全 c1.Lock() defer c1.Unlock() c1.incr() }() } wg.Wait() fmt.Println("count: ", c1.countVal()) // 10000 }
等待锁与trylock(阻塞场景与非阻塞场景)
上面的代码中使用了golang内置的sync.Mutex实现了一个“等待锁”,所谓的等待,锁通俗地讲就是,并发情况下多个协裎都想要处理同一个全局的资源,如果此时代码中加了锁的话,只有抢到了锁的协裎会执行代码逻辑,而其他的协裎不会停止,会等着占用锁的协裎释放了锁以后继续抢占锁,直到抢到了锁执行了代码逻辑后再执行接下来的操作。
但是在某些场景,我们只是希望一个任务有单一的执行者。而不像计数器场景一样,所有 goroutine 都执行成功。后来的 goroutine 在抢锁失败后,需要放弃其流程。这时候就需要 trylock 了。
trylock 顾名思义,尝试加锁,加锁成功执行后续流程,如果加锁失败的话也不会阻塞,而会直接返回加锁的结果。
看下图可以知道lock与trylock的区别:
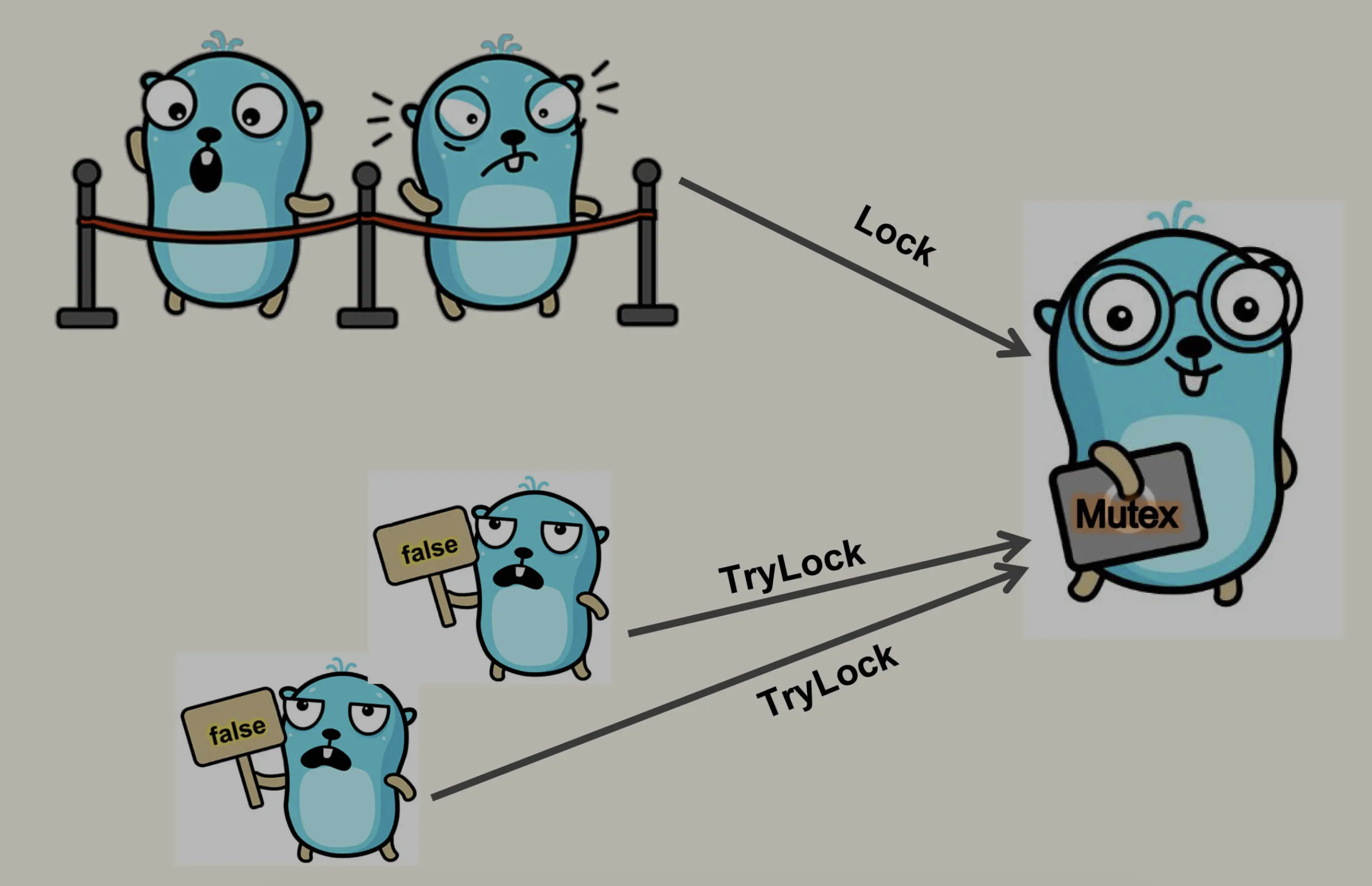
在go 1.18的标准库中官方为我们提供了Mutex结构体的Trylock方法,可以做一下测试:
func TestP41(t *testing.T) { var mu sync.Mutex var wg sync.WaitGroup for i := 0; i < 10; i++ { wg.Add(1) go func(val int) { defer wg.Done() t := mu.TryLock() fmt.Println("TryOut的返回: ", t, val) if t == true { defer mu.Unlock() } }(i) } wg.Wait() fmt.Println("程序跑完了.....") } /* TryOut的返回: false 9 TryOut的返回: false 3 TryOut的返回: false 4 TryOut的返回: false 5 TryOut的返回: false 6 TryOut的返回: false 7 TryOut的返回: false 8 TryOut的返回: false 1 TryOut的返回: true 2 TryOut的返回: true 0 程序跑完了..... */
另外我们可以用大小为 1 的 Channel 来模拟 trylock:
参考这里吧:《Go语言高级编程中使用channel实现一个Trylock》
分布式系统中的锁
但是Mutex也有使用的局限性,因为他只是进程内的锁,在单节点应用中使用Mutex是ok的,但是在分布式系统中由于请求的节点不一样,就不能使用Mutex了。
此时应该使用分布式锁去规避业务中“全局资源”并发修改的问题了。
使用redis的SETNX方法实现一个非阻塞的TryLock
大家都知道,redis使用单线程的worker处理命令,所以redis中对一个业务中全局的数据资源的处理是线程安全的,另外redis对string类型提供了一个setNx命令:
SETNX key value
将 key 的值设为 value ,当且仅当 key 不存在。
若给定的 key 已经存在,则 SETNX 不做任何动作。
实现的方案是:并发情况下,所有的协裎在redis中执行 setnx 命令,它们同时设置一个相同的key(比如叫:redisLockerKey),此时只会有一个协裎设置成功(设置成功/失败,setNx会有不同的返回值),设置成功的协裎将这个全局的key设置一个TTL值(占用锁的时间,一般会大于业务处理的时间),当占用锁的协裎处理完业务逻辑后再主动将这个全局key删除掉(为了安全起见,可以先判断一下key是否存在再执行删除操作!)。而其他没有抢到锁的协裎(其实就是setNx命令返回了设置失败的值)在收到setNx命令失败的结果后可以不执行锁中的逻辑,直接执行锁下面的业务逻辑。
使用SETNX实现一个非阻塞的TryLock:
package main import ( "context" "fmt" "sync" "testing" "time" "github.com/go-redis/redis/v8" ) const ( lockKey = "counter_lock_key" ) var num = 0 func incrNum() { client := redis.NewClient(&redis.Options{ Addr: "192.168.110.175:6379", Password: "", DB: 0, }) // lock resp := client.SetNX(context.TODO(), lockKey, 1, time.Second*5) // 最多5秒超时机制 // Notice lockSuccess返回false表示lockKey已经存在了!也就是说有其他协裎抢到锁了 lockSuccess, errLock := resp.Result() if errLock != nil || !lockSuccess { fmt.Println("errLock:", errLock, "lock result: ", lockSuccess) return } // num ++ num++ // unlock // Notice 注意下面的判断方法 unlockSuccess, errUnlock := client.Del(context.TODO(), lockKey).Result() if errUnlock == nil || unlockSuccess > 0 { fmt.Println("unlock success!") } else { fmt.Println("unlock failed!", errUnlock) } } func TestT2(t *testing.T) { var wg sync.WaitGroup for i := 0; i < 500; i++ { wg.Add(1) go func() { defer wg.Done() incrNum() }() } wg.Wait() // Notice tryLock机制: 没有抢到锁的协裎直接返回了,不会等待!适用于“非阻塞场景” fmt.Println("num: ", num) // 8 }
通过代码和执行结果可以看到,我们远程调用 setnx 运行流程上和单机的 trylock 非常相似,如果获取锁失败,那么相关的任务逻辑就不应该继续向前执行。
setnx 很适合在高并发场景下,用来争抢一些 “唯一” 的资源。比如交易撮合系统中卖家发起订单,而多个买家会对其进行并发争抢。这种场景我们没有办法依赖具体的时间来判断先后,因为不管是用户设备的时间,还是分布式场景下的各台机器的时间,都是没有办法在合并后保证正确的时序的。哪怕是我们同一个机房的集群,不同的机器的系统时间可能也会有细微的差别。
所以,我们需要依赖于这些请求到达 Redis 节点的顺序来做正确的抢锁操作。如果用户的网络环境比较差,那也只能自求多福了。
使用etcd实现一个阻塞的等待Lock
具体参考:https://learnku.com/articles/71368
etcdv3版本官方提供了可以直接使用锁的API,还拿之前那个全局变量的例子举例,不过这次使用etcd实现一个分布式的Lock:
package etcdLocker import ( "fmt" "sync" "testing" "time" v3 "go.etcd.io/etcd/client/v3" "go.etcd.io/etcd/client/v3/concurrency" ) var sg sync.WaitGroup type Counter struct { count int } func (m *Counter) Incr() { m.count++ } func (m *Counter) Count() int { return m.count } func TestT12(*testing.T) { cli, errCli := v3.New(v3.Config{ Endpoints: []string{"http://192.168.110.175:2380"}, Username: "root", Password: "", DialTimeout: time.Second * 5, }) fmt.Println("cli: ", cli) if errCli != nil { fmt.Println("errCLi: ", errCli) return } defer cli.Close() counter := &Counter{} sg.Add(150) for i := 0; i < 150; i++ { go func() { // Notice 注意这里模拟分布式系统,session可能会在不同的节点中生成,但是它们用的etcd的client是一样的,所以要把NewSession的逻辑写在这里 // 这里会生成租约,默认是60秒(在第二个参数可以使用concurrency.WithTTL(5)设置租约为5秒) session, err := concurrency.NewSession(cli) if err != nil { panic(err) } defer session.Close() locker := concurrency.NewLocker(session, "/my-test-lock") locker.Lock() counter.Incr() locker.Unlock() sg.Done() }() } sg.Wait() // Notice: 本地演示由于机器性能问题耗时会比较长,所以加的数不要太大 fmt.Println("count:", counter.Count()) // 150 }
注意一下租约与超时的问题:
当某个客户端持有锁时,由于某些原因导致锁未释放,就会导致这个客户端一直持有这把锁,其他客户端一直获取不到锁。所以需要分布式锁实现超时机制,当锁未释放时,会因为 etcd 的租约会到期而释放锁。当业务正常处理时,租约到期之前会继续续约,知道业务处理完毕释放锁。
使用etcd实现一个非阻塞的TryLock
与Lock相对的,也有一个TryLock方法的,
package etcdLocker import ( "context" "fmt" "sync" "testing" "time" v3 "go.etcd.io/etcd/client/v3" "go.etcd.io/etcd/client/v3/concurrency" ) var sg sync.WaitGroup type Counter struct { count int } func (m *Counter) Incr() { m.count++ } func (m *Counter) Count() int { return m.count } func TestT12(*testing.T) { cli, errCli := v3.New(v3.Config{ Endpoints: []string{"http://192.168.110.175:2380"}, Username: "root", Password: "", DialTimeout: time.Second * 5, }) fmt.Println("cli: ", cli) if errCli != nil { fmt.Println("errCLi: ", errCli) return } defer cli.Close() counter := &Counter{} sg.Add(10) for i := 0; i < 10; i++ { go func(a int) { defer sg.Done() // Notice 这里模拟分布式系统,session可能会在不同的节点中生成,但是它们用的etcd的client是一样的,所以要把NewSession的逻辑写在这里 // 这里会生成租约,设置为5秒 session, err := concurrency.NewSession(cli, concurrency.WithTTL(5)) if err != nil { panic(err) } defer session.Close() // Notice 此处使用NewMutex初始化 locker := concurrency.NewMutex(session, "/my-test-lock") // Notice TryLock,获取锁失败就返回,不做业务处理 errTryLock := locker.TryLock(context.Background()) if errTryLock != nil { fmt.Printf("%d 获取锁失败!直接返回! \n", a) return } else { fmt.Printf("%d 获取锁成功! \n", a) } counter.Incr()
errUnlock := locker.Unlock(context.Background()) if errUnlock != nil { fmt.Printf("%d 解锁失败! \n", a) return } fmt.Printf("%d 释放了锁! \n", a) }(i) } sg.Wait() fmt.Println("count:", counter.Count()) /* 5 获取锁成功! 0 获取锁失败!直接返回! 5 释放了锁! 3 获取锁失败!直接返回! 1 获取锁失败!直接返回! 9 获取锁失败!直接返回! 6 获取锁失败!直接返回! 7 获取锁失败!直接返回! 2 获取锁失败!直接返回! 8 获取锁失败!直接返回! 4 获取锁失败!直接返回! count: 1 */ }
~~~
在kratos项目中使用分布式锁介绍1: etcd_locker
项目地址:https://gitee.com/huoyingwhw/kratos_etcd_locker
在kratos项目中使用分布式锁介绍2: 使用SETNX实现一个简单的非等待的分布式锁
项目地址:https://gitee.com/huoyingwhw/kratos_rockscache
在项目中根据实际情况选择合适的锁 ***
业务还在单机就可以搞定的量级时,那么按照需求使用任意的单机锁方案就可以。
如果发展到了分布式服务阶段,但业务规模不大,qps 很小的情况下,使用哪种锁方案都差不多。如果公司内已有可以使用的 ZooKeeper、etcd 或者 Redis 集群,那么就尽量在不引入新的技术栈的情况下满足业务需求。
业务发展到一定量级的话,就需要从多方面来考虑了。首先是你的锁是否在任何恶劣的条件下都不允许数据丢失,如果不允许,那么就不要使用 Redis 的 setnx 的简单锁。
对锁数据的可靠性要求极高的话,那只能使用 etcd 或者 ZooKeeper 这种通过一致性协议保证数据可靠性的锁方案。但可靠的背面往往都是较低的吞吐量和较高的延迟。需要根据业务的量级对其进行压力测试,以确保分布式锁所使用的 etcd 或 ZooKeeper 集群可以承受得住实际的业务请求压力。需要注意的是,etcd 和 Zookeeper 集群是没有办法通过增加节点来提高其性能的。要对其进行横向扩展,只能增加搭建多个集群来支持更多的请求。这会进一步提高对运维和监控的要求。多个集群可能需要引入 proxy,没有 proxy 那就需要业务去根据某个业务 id 来做分片。如果业务已经上线的情况下做扩展,还要考虑数据的动态迁移。这些都不是容易的事情。
在选择具体的方案时,还是需要多加思考,对风险早做预估。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号