
Python与Golang中给列表中字典按照某个key排序以及Go中给切片中的结构体排序
Golang中使用sort包按照结构体多个字段排序的正确方法!!!
type Bird struct { A1 int `json:"a1"` A2 int `json:"a2"` A3 int `json:"a3"` A4 int `json:"a4"` } func TestBirdSort(t *testing.T) { b1 := Bird{A1: 1, A2: 10, A3: 20, A4: 30} b2 := Bird{A1: 2, A2: 10, A3: 20, A4: 30} b3 := Bird{A1: 2, A2: 15, A3: 20, A4: 30} b4 := Bird{A1: 3, A2: 10, A3: 20, A4: 30} b5 := Bird{A1: 3, A2: 12, A3: 20, A4: 30} b6 := Bird{A1: 3, A2: 12, A3: 22, A4: 30} // Notice 注意切片中的元素最好是 指针!!! birds := []*Bird{&b2, &b4, &b5, &b6, &b1, &b3} // Notice 根据结构体切片中多个字段排序!!!!!注意判断逻辑不要有等于~ sort.SliceStable(birds, func(i, j int) bool { // 先根据 a1 降序排序 if birds[i].A1 > birds[j].A1 { return true } if birds[i].A1 < birds[j].A1 { return false } // 再根据 a2 降序排序 if birds[i].A2 > birds[j].A2 { return true } if birds[i].A2 < birds[j].A2 { return false } // 最后根据 a3 降序排序 if birds[i].A3 > birds[j].A3 { return true } if birds[i].A3 < birds[j].A3 { return false } return true }) fmt.Println("ret1:>>>> ", gconv.String(birds)) dump.P(birds) /* []*scripts_stroage.Bird [ #len=6 & scripts_stroage.Bird { A1: int(3), A2: int(12), A3: int(22), A4: int(30), }, & scripts_stroage.Bird { A1: int(3), A2: int(12), A3: int(20), A4: int(30), }, & scripts_stroage.Bird { A1: int(3), A2: int(10), A3: int(20), A4: int(30), }, & scripts_stroage.Bird { A1: int(2), A2: int(15), A3: int(20), A4: int(30), }, & scripts_stroage.Bird { A1: int(2), A2: int(10), A3: int(20), A4: int(30), }, & scripts_stroage.Bird { A1: int(1), A2: int(10), A3: int(20), A4: int(30), }, ], */ }
参考文章
golang sort包 排序 ***
前言
最近写业务学到了在Golang中给slice中的map按照key排序的方法,想到Python中也有相关的需求与写法,总结一下方便以后使用。
Golang中的实现
在Go中有一个内置的sort模块可以实现:
package test1 import ( "fmt" "sort" "testing" ) /* 数据的格式如下: s=[ {"no":21,"score":90}, {"no":21,"score":80}, {"no":25,"score":100}, {"no":20,"score":66}, ] */ func TestSortSliceMap(t *testing.T) { m1 := map[string]int{"no": 21, "score": 90} m2 := map[string]int{"no": 21, "score": 80} m3 := map[string]int{"no": 25, "score": 100} m4 := map[string]int{"no": 20, "score": 66} s1 := []map[string]int{m1, m2, m3, m4} // 排序后 fmt.Println("排序前s1: ", s1) // 先根据no排序,no一样的话再根据score排序 ———— 从小到大排序 sort.Slice(s1, func(i, j int) bool { if s1[i]["no"] == s1[j]["no"] { return s1[i]["score"] < s1[j]["score"] } return s1[i]["no"] < s1[j]["no"] }) // 排序后 fmt.Println("排序后s1: ", s1) /* 结果: 排序前s1: [map[no:21 score:90] map[no:21 score:80] map[no:25 score:100] map[no:20 score:66]] 排序后s1: [map[no:20 score:66] map[no:21 score:80] map[no:21 score:90] map[no:25 score:100]] */ }
Python中的实现
简单的按照value排序
dic = {'a': 21, 'b': 5, 'c': 3, 'd': 54, 'e': 74, 'f': 0}
# 按照value的大小倒序排序
new_lst = sorted(dic.items(), key=lambda d: d[1], reverse=True)
print("new_lst: ", new_lst)
# new_lst: [('e', 74), ('d', 54), ('a', 21), ('b', 5), ('c', 3), ('f', 0)]
# 重新构建字典
new_dic = {tu[0]: tu[1] for tu in new_lst}
print("new_dic: ", new_dic)
# new_dic: {'e': 74, 'd': 54, 'a': 21, 'b': 5, 'c': 3, 'f': 0}
列表里面嵌套字典按照字典的多个key排序
import pprint lst = [ {"level": 19, "star":21, "time": 9}, {"level": 29, "star":43, "time": 51}, {"level": 22, "star":55, "time": 43}, {"level": 22, "star":66, "time": 3}, {"level": 17, "star":20, "time": 12}, {"level": 17, "star":20, "time": 13}, ] """ 需求: level越大越靠前; level相同, star越大越靠前; level和star相同, time越小越靠前; """ print("lst0: ") pprint.pprint(lst) # 先按照time排序 默认是从小到大 lst.sort(key=lambda k:k["time"]) print("lst1: ") pprint.pprint(lst) # 再根据level跟star排序,从大到小 lst.sort(key=lambda k: (k["level"], k["star"]), reverse=True) print("lst2: ") pprint.pprint(lst) """ 结果: lst0: [{'level': 19, 'star': 21, 'time': 9}, {'level': 29, 'star': 43, 'time': 51}, {'level': 22, 'star': 55, 'time': 43}, {'level': 22, 'star': 66, 'time': 3}, {'level': 17, 'star': 20, 'time': 12}, {'level': 17, 'star': 20, 'time': 13}] lst1: [{'level': 22, 'star': 66, 'time': 3}, {'level': 19, 'star': 21, 'time': 9}, {'level': 17, 'star': 20, 'time': 12}, {'level': 17, 'star': 20, 'time': 13}, {'level': 22, 'star': 55, 'time': 43}, {'level': 29, 'star': 43, 'time': 51}] lst2: [{'level': 29, 'star': 43, 'time': 51}, {'level': 22, 'star': 66, 'time': 3}, {'level': 22, 'star': 55, 'time': 43}, {'level': 19, 'star': 21, 'time': 9}, {'level': 17, 'star': 20, 'time': 12}, {'level': 17, 'star': 20, 'time': 13}] """
Golang中给切片中的结构体排序 ***
Go中的排序函数如下:
1. Slice() 不稳定排序
2. SliceStable() 稳定排序
3. SliceIsSorted() 判断是否已排序
package sort_tests import ( "fmt" "sort" "testing" ) type UserTask struct { Id int Name string Type string } // slice里面是 结构体,根据结构体的某个字段去排序 func TestSortStructSlice(t *testing.T) { userTask1 := UserTask{Id: 1, Name: "task1", Type: "type1"} userTask2 := UserTask{Id: 2, Name: "task2", Type: "type2"} userTask3 := UserTask{Id: 3, Name: "task3", Type: "type3"} userTask4 := UserTask{Id: 4, Name: "task4", Type: "type4"} userTask5 := UserTask{Id: 5, Name: "task5", Type: "type5"} mySlice := []UserTask{userTask4, userTask3, userTask1, userTask5, userTask2} fmt.Println("=========排序前:==========", mySlice) // [{4 task4 type4} {3 task3 type3} {1 task1 type1} {5 task5 type5} {2 task2 type2}] // 1、从小到大排序 不稳定排序 sort.Slice(mySlice, func(i, j int) bool { if mySlice[i].Id < mySlice[j].Id { return true } return false }) fmt.Println("=========不稳定排序(从小到大)后:=========", mySlice) // [{1 task1 type1} {2 task2 type2} {3 task3 type3} {4 task4 type4} {5 task5 type5}] // 2、判断是否是 从小到大排序 bLess := sort.SliceIsSorted(mySlice, func(i, j int) bool { if mySlice[i].Id < mySlice[i].Id { return true } return false }) fmt.Println("======是否是从小到大排序: ", bLess) // true // 3、从大到小排序 稳定排序 sort.SliceStable(mySlice, func(i, j int) bool { if mySlice[i].Id > mySlice[j].Id { return true } return false }) fmt.Println("=========稳定排序(从大到小)后:=========", mySlice) // [{5 task5 type5} {4 task4 type4} {3 task3 type3} {2 task2 type2} {1 task1 type1}] // 4、判断是否是 从大到小排序 bMore := sort.SliceIsSorted(mySlice, func(i, j int) bool { if mySlice[i].Id > mySlice[i].Id { return true } return false }) fmt.Println("======是否是从小到大排序: ", bMore) // true }
~~~
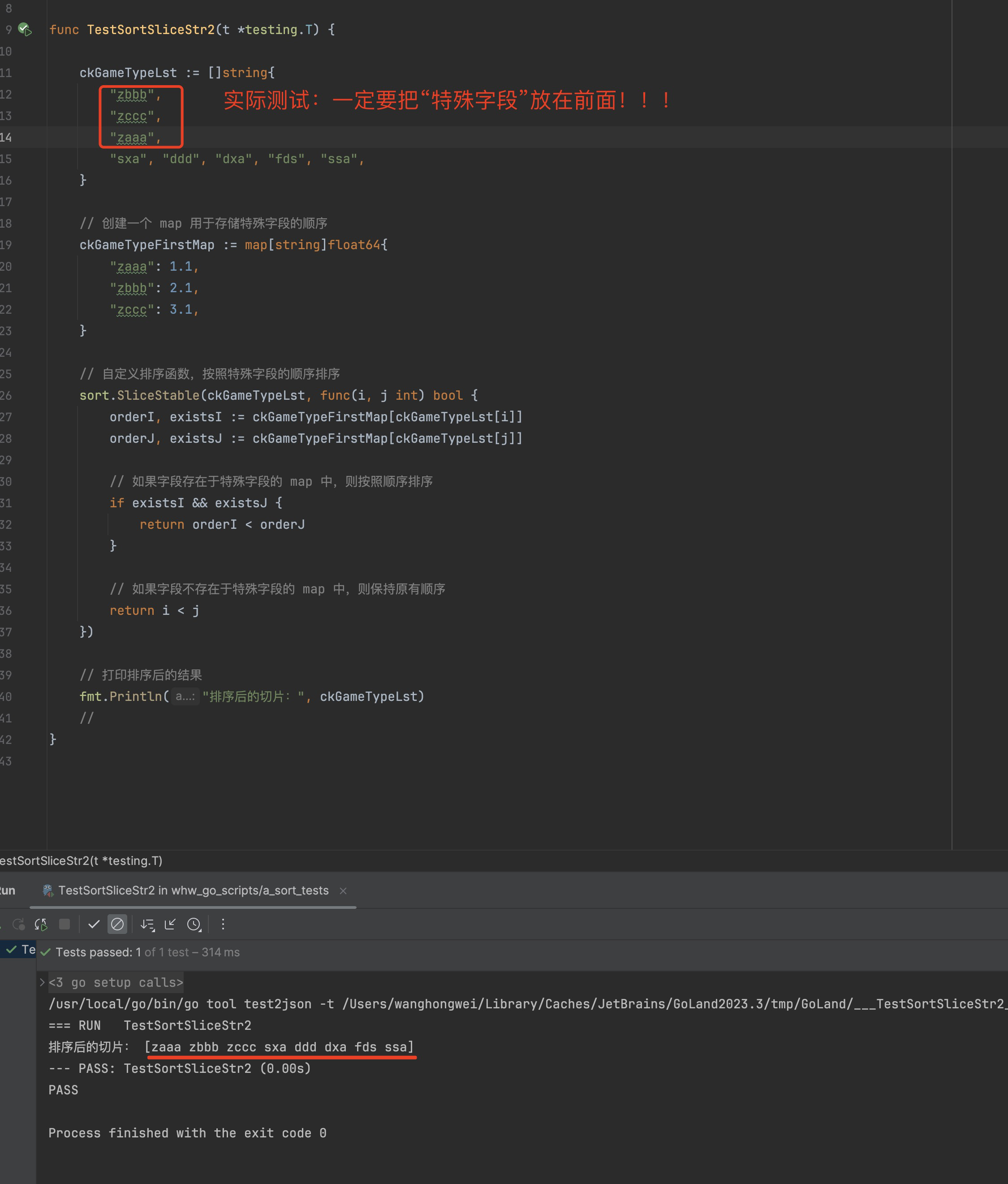
优先级特殊排序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号