
并发处理IO任务与MySQL中ON DUPLICATE KEY UPDATE的使用
背景
现在的项目做的是与某书对接的业务,使用三方的SDK,由于使用的是三方服务,所以业务中无法避免各种网络的IO(这里吐槽下老外的文档写的真的是混乱不堪 - -!)。
由于实时的数据存储在三方的数据库中,既有的定时任务是每天将实时数据同步到我们自己的数据库中去。但是随着项目的扩展以天为周期的同步任务已经无法满足既有业务的需求了。
因此新的需求是根据每10分钟的操作记录将更新后的最新的数据同步到我们自己本地的数据库中去。
实现这个需求的基本思路就是:根据SDK提供的方法获取所有账户在10分钟的操作记录的原始数据,然后再将这些源数据构建成合适的数据结构,最后存储到我们自己的数据库中。
中间构建数据的耗时可以忽略不计——平时刷了那么多题相信你对自己程序的时间复杂度与空间复杂度会有很好的掌控。
这个需求最需要优化的地方就是使用SDK获取原始数据的网络IO操作与将数据写入或更新本地数据库的操作。
处理SDK的问题我使用的是线程池;写入或更新数据使用ON DUPLICATE KEY UPDATE(注意这个语法只能在MySQL中执行)。
demo项目
我这边做了一个demo,项目的目录结构如下:
db_demo
├── config.py
├── db_conn.py
├── log.py
├── logs
│ └── my_log.log
├── run.py
└── utils.py
项目概述
config.py里面存放配置信息;db_conn.py封装了pymysql的操作;log.py封装了日志模块;utils.py里面有模拟IO耗时的函数与处理IO操作的函数;run.py是项目的启动文件,里面包含了普通方法与并发方法的对比。
数据库准备
记得在本地数据库中创建一个students的数据库,里面新建一个student表,表结构下:

注意这里我使用class_id做主键!这很重要!我们自己的数据库也没有使用id做主键,而是选用了其他的字段!
代码


# -*- coding:utf-8 -*- MySQLS = { 'student': { 'host': '127.0.0.1', 'user': 'root', 'password': '123', 'db': 'students', 'port': 3306, 'charset': 'utf8' } }
# -*- coding:utf-8 -*- import pymysql import logging import traceback class OperateMySQL(object): """operate mysql database""" def __init__(self, config): self.cursor = None self.db = None self.config = config def connection(self): self.db = pymysql.connect(**self.config) self.cursor = self.db.cursor() def insert_or_update(self, sql): try: self.cursor.execute(sql) self.db.commit() return 1 except Exception as error: # print(traceback.format_exc()) self.db.rollback() # 简单的日志处理 logging.error("=======ERROR=======\n%s\nsql:%s" % (error, sql)) raise def query(self, sql): try: self.cursor.execute(sql) results = self.cursor.fetchall() return results except Exception as error: # 简单的日志处理 logging.error("=======ERROR=======:\n%s\nsql:%s" % (error, sql)) raise def close(self): self.db.close()
# -*- coding:utf-8 -*- import os import logging class Log(object): __instance = None # 重写new方法实现单例模式 def __new__(cls, *args, **kwargs): if not cls.__instance: obj = object.__new__(cls) cls.__instance = obj return cls.__instance # 级别默认是DEBUG def __init__(self, log_path='logs/my_log.log', level=logging.DEBUG): # 如果之前没创建过 就新建一个logger对象,后面相同的实例共用一个logger对象 if 'logger' not in self.__dict__: logger = logging.getLogger() # 设置日志级别 logger.setLevel(level) # 格式化 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 创建文本输入对象与屏幕打印对象 fh = logging.FileHandler(log_path, encoding='utf-8') # ch = logging.StreamHandler() fh.setFormatter(formatter) # ch.setFormatter(formatter) logger.addHandler(fh) # logger.addHandler(ch) # 初始化logger属性 self.logger = logger # 为不同的日志级别设置输出方法 def debug(self,msg): return self.logger.debug(msg) def info(self,msg): return self.logger.info(msg) def warring(self,msg): return self.logger.warning(msg) def error(self,msg): return self.logger.error(msg) def critical(self,msg): return self.logger.critical(msg) # 单例 logger = Log()
# -*- coding:utf-8 -*- import time import random from datetime import datetime from log import logger from config import MySQLS from db_conn import OperateMySQL ### 根据class_id获取数据是一个耗时的任务! ———— 模拟实际中的耗时任务!!! def get_class_info(class_id): r = random.randint(2,4) time.sleep(r) # print("耗时...... {} 秒".format(r)) now = datetime.now() ret = dict( class_name=f"class_{class_id}", stu_id=random.randint(1,1000), inschool_datetime=now ) return ret ### 获取class信息并且批量更新或插入数据的操作 def change_db(class_id): db = OperateMySQL(MySQLS["student"]) # 开启连接 db.connection() ### 这是个耗时的操作!!! ret = get_class_info(class_id) # 赋值 class_name, stu_id, inschool_datetime = ret["class_name"], ret["stu_id"], ret["inschool_datetime"] # 模拟要往数据库中插入或修改的数据 —— insert与update的格式必须一样 change_lst = list() # 记得将datetime类型转换为str才能往数据库中写入! inup_lst = [class_id, class_name, stu_id, str(inschool_datetime)] change_lst.append(inup_lst) # 列表套列表的形式 ### 批量操作 insert或者update ——— ON DUPLICATE KEY UPDATE 前面的values是字符串形式的多个tuple if change_lst: str_values = "" ### 注意这里的处理!!!values 后面可以跟多条数据,并且是str的元组形式的数据!中间用逗号隔开 for index,lst in enumerate(change_lst,1): if index < len(change_lst): str_values += str(tuple(lst))+"," else: str_values += str(tuple(lst)) ### 批量插入或更新 change_sql = """ insert into student(class_id,class_name,stu_id,inschool_datetime) values {} ON DUPLICATE KEY UPDATE class_id=VALUES(class_id),class_name=VALUES(class_name),stu_id=VALUES(stu_id), inschool_datetime=VALUES(inschool_datetime) """.format(str_values) print(change_sql) db.insert_or_update(change_sql) # 记得关闭连接 db.close() logger.info("insert/update successfully!class_id:{}".format(class_id))
run.py:
# -*- coding:utf-8 -*- import time from multiprocessing import Pool from concurrent.futures import ThreadPoolExecutor,wait,as_completed from config import MySQLS from utils import change_db from db_conn import OperateMySQL class MySQLdb(object): def __enter__(self): self.stu_db = OperateMySQL(MySQLS["student"]) self.stu_db.connection() return self def __exit__(self, exc_type, exc_val, exc_tb): self.stu_db.close() ### 主函数 def main_func(): # with MySQLdb() as db: # stu_db = db.stu_db class_id_lst = ["01","02","03","04","05"] start = time.time() """ ### 1、普通方法 for class_id in class_id_lst: change_db(class_id) print("普通方法耗时:{}".format(time.time() - start)) # 普通方法耗时:16.037654161453247 """ ## 2、线程池 executor = ThreadPoolExecutor(max_workers=3) all_tasks = [executor.submit(change_db,class_id) for class_id in class_id_lst] ## 获取返回值 for future in as_completed(all_tasks): data = future.result() print("线程池耗时:{}".format(time.time() - start)) ## 线程池耗时:6.016145944595337 ### 注意IO操作多用线程池不用进程池,降低程序开销 """ # 3、进程池 pool = Pool() obj_lst = list() for class_id in class_id_lst: obj_lst.append(pool.apply_async(change_db, args=(class_id,))) pool.close() pool.join() print("进程池耗时:{}".format(time.time() - start)) # 进程池耗时:6.062030076980591 """ if __name__ == '__main__': main_func()
程序执行说明
开启线程池处理网络IO的操作不用多说,相信玩多了爬虫的你对这块的内容已经了如指掌了。
这里着重说明一下 ON DUPLICATE KEY UPDATE的使用:
当你想要插入的数据在MySQL中没有相应的主键或唯一索引时,会执行insert操作;如果有对应的主键或唯一索引就会对这个主键或唯一索引对应的那一行数据执行update操作。
我们先来看一下,当数据库中没有要插入的class_id的情况会执行insert操作:

执行程序后:
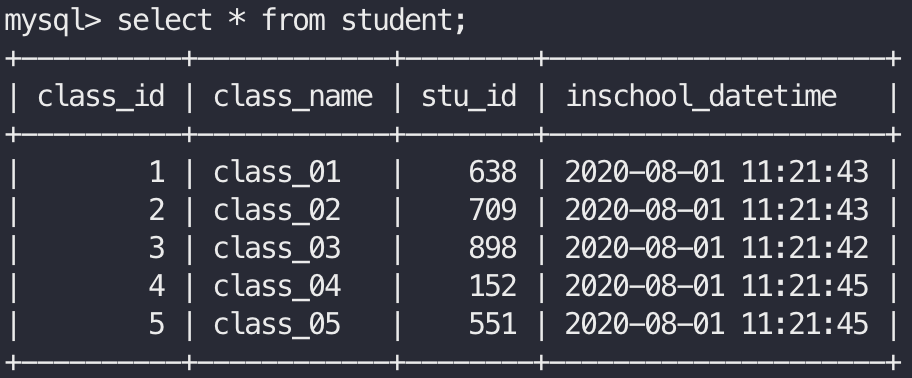
此时打印出的日志如下:
2020-08-01 11:21:41,632 - root - INFO - insert/update successfully!class_id:03 2020-08-01 11:21:42,632 - root - INFO - insert/update successfully!class_id:01 2020-08-01 11:21:42,633 - root - INFO - insert/update successfully!class_id:02 2020-08-01 11:21:44,636 - root - INFO - insert/update successfully!class_id:04 2020-08-01 11:21:44,637 - root - INFO - insert/update successfully!class_id:05
当数据库中有数据且想插入数据的class_id与原表中的值相同时会执行update操作(因为class_id是主键):
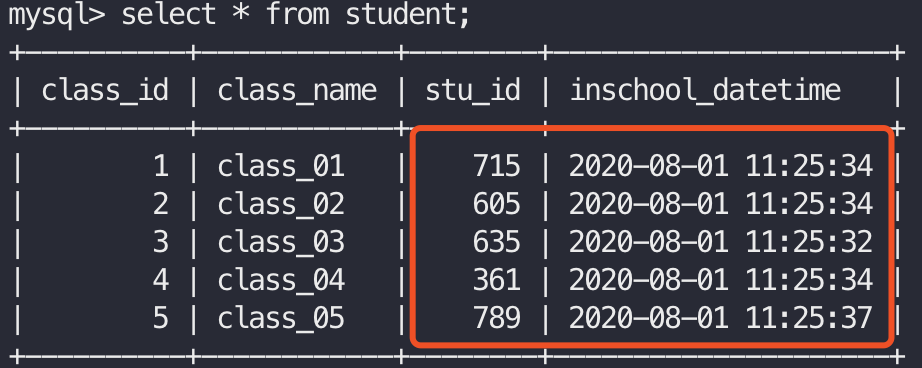
可以看到红框中的数据是执行了update操作的结果。
此时记录的日志如下:
2020-08-01 11:25:31,946 - root - INFO - insert/update successfully!class_id:03 2020-08-01 11:25:33,944 - root - INFO - insert/update successfully!class_id:01 2020-08-01 11:25:33,945 - root - INFO - insert/update successfully!class_id:02 2020-08-01 11:25:33,949 - root - INFO - insert/update successfully!class_id:04 2020-08-01 11:25:36,949 - root - INFO - insert/update successfully!class_id:05
关于ON DUPLICATE KEY UPDATE
程序中打印出的其中一条sql语句如下:
insert into student(class_id,class_name,stu_id,inschool_datetime) values ('02', 'class_02', 605, '2020-08-01 11:25:33.942122') ON DUPLICATE KEY UPDATE class_id=VALUES(class_id),class_name=VALUES(class_name),stu_id=VALUES(stu_id), inschool_datetime=VALUES(inschool_datetime)
其实后面的values还可以跟多个“元组”,就像这样:
insert into student(class_id,class_name,stu_id,inschool_datetime) values ('02', 'class_02', 605, '2020-08-01 11:25:33.942122'),
('04', 'class_04', 361, '2020-08-01 11:25:33.948145'),
('05', 'class_05', 789, '2020-08-01 11:25:36.947170') ON DUPLICATE KEY UPDATE class_id=VALUES(class_id),class_name=VALUES(class_name),stu_id=VALUES(stu_id), inschool_datetime=VALUES(inschool_datetime)
其实实际中跟多个“元组”的情况最多,请读者注意一下我在python代码中构建这条SQL语句的过程:
......... # 赋值 class_name, stu_id, inschool_datetime = ret["class_name"], ret["stu_id"], ret["inschool_datetime"] # 模拟要往数据库中插入或修改的数据 —— insert与update的格式必须一样 change_lst = list() # 记得将datetime类型转换为str才能往数据库中写入! inup_lst = [class_id, class_name, stu_id, str(inschool_datetime)] change_lst.append(inup_lst) # 列表套列表的形式 ### 批量操作 insert或者update ——— ON DUPLICATE KEY UPDATE 前面的values是字符串形式的多个tuple if change_lst: str_values = "" ### 注意这里的处理!!!values 后面可以跟多条数据,并且是str的元组形式的数据!中间用逗号隔开 for index,lst in enumerate(change_lst,1): if index < len(change_lst): str_values += str(tuple(lst))+"," else: str_values += str(tuple(lst)) ### 批量插入或更新 change_sql = """ insert into student(class_id,class_name,stu_id,inschool_datetime) values {} ON DUPLICATE KEY UPDATE class_id=VALUES(class_id),class_name=VALUES(class_name),stu_id=VALUES(stu_id), inschool_datetime=VALUES(inschool_datetime) """.format(str_values) print(change_sql) .........
~~~
