
堆栈相关的几个练习——堆栈效率高于递归
一、三级菜单
数据结构如下:


menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, '汽车之家':{}, 'youku':{}, }, '上地':{ '百度':{}, }, }, '昌平':{ '沙河':{ '老男孩':{}, '北航':{}, }, '天通苑':{}, '回龙观':{}, }, '朝阳':{}, '东城':{}, }, '上海':{ '闵行':{ "人民广场":{ '炸鸡店':{} } }, '闸北':{ '火车站':{ '携程':{} } }, '浦东':{}, }, '山东':{}, }
from my_menu import menu lis = [menu] while lis: for i in lis[-1]: print(i) key = input('>>>:').strip() if not key:continue if lis[-1].get(key): lis.append(lis[-1][key]) elif key.upper() == 'Q': lis.clear() elif key.upper() == 'B': lis.pop()
效果:
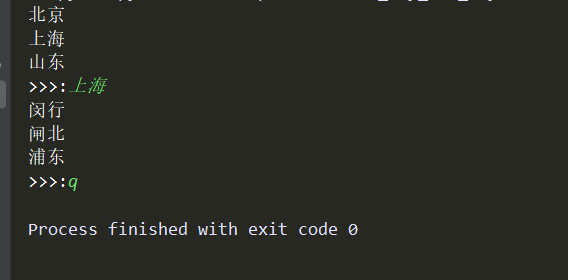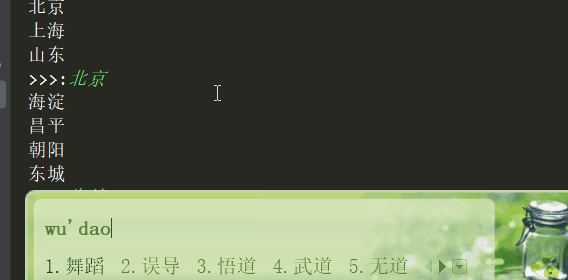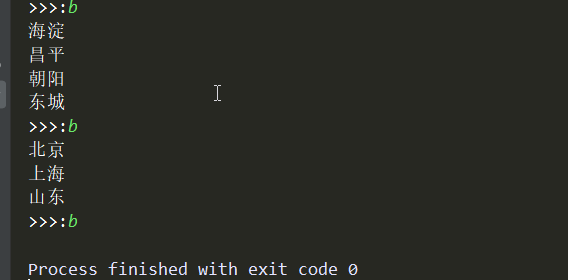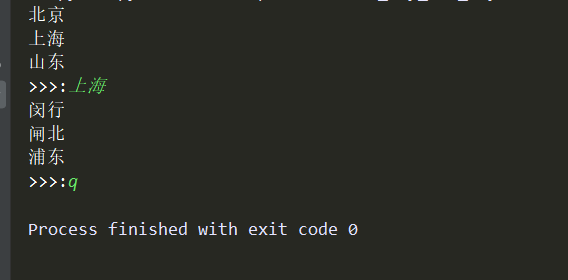
二、获取文件夹(包含文件)的大小
import os def get_file_size(path): count = 0 lis = [path] while lis: path = lis.pop() for f in os.listdir(path): sub_path = os.path.join(path,f) if os.path.isfile(sub_path): count += os.path.getsize(sub_path) elif os.path.isdir(sub_path): lis.append(sub_path) return count
三、清空或删除文件夹(里面有文件)
1、堆栈实现:
import os def remove_files(path): lis = [path] lst = [] while lis: path = lis.pop() for f in os.listdir(path): sub_path = os.path.join(path, f) if os.path.isfile(sub_path): os.remove(sub_path) elif os.path.isdir(sub_path): lis.append(sub_path) lst.append(sub_path) ## 把所有文件删完后,再处理里面的额空文件夹 ## 这里 倒序取 for f in lst[::-1]: os.rmdir(f) # 如果需要删除根文件夹的话 # os.rmdir(path)
2:递归实现
import os def clear_dir(path): if os.path.isdir(path): name_lst = os.listdir(path) for name in name_lst: son_path = os.path.join(path,name) if os.path.isfile(son_path): os.remove(son_path) elif os.path.isdir(son_path): clear_dir(son_path) os.rmdir(son_path)
四、返回指定字段及对应的字典
要求:从该结构数据中返回由指定的字 段和对应的值组成的字典。如果指定字段不存在,则跳过该字段。(字典还有 可能有n层)
数据结构如下:
data={ "time":"2016-08-05T13:13:05", "some_id":"ID1234", "grp1":{ "fld1":1, "fld2":2 }, "xxx2":{ "fld3":0, "fld5":0.4 }, "fld6":11, "fld7":7, "fld46":8 }
堆栈实现:
def select(data,fields): dic = {} field_lst = fields.split('|') lis = [data] while lis: data = lis.pop() for i in data: if i in field_lst: dic[i] = data[i] elif isinstance(data[i],dict): lis.append(data[i]) return dic if __name__ == '__main__': dic = select(data,'fld2|fld3|fld7|fld19') print(dic)
递归实现:
def sel(data,fields,ret_dic): field_lst = fields.split('|') for i in data: if i in field_lst: ret_dic[i] = data[i] elif type(data[i]) is dict: sel(data[i],fields,ret_dic) if __name__ == '__main__': ret_dic = {} sel(data,'fld2|fld3|fld7|fld19',ret_dic) print(ret_dic)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号