
列表与字典的几个进阶操作
小结几个有关列表与字典常见的几个简单用法:
1.zip()方法
(1)利用zip方法我们可以将两个相关的列表结合成一个由这两个列表中元素构成的“键值对”的字典:
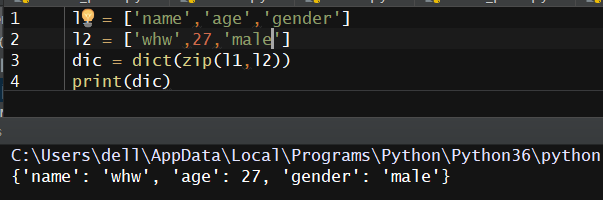
l1 = ['name','age','gender'] l2 = ['whw',27,'male'] dic = dict(zip(l1,l2))
结果如下:
(2)当然我们也可以做一个比较复杂的操作:
w.txt文件中有如下信息:
1,Alex Li,22,13651054608,IT,2013-04-01 2,Jack Wang,28,13451024608,HR,2015-01-07 3,Rain Wang,21,13451054608,IT,2017-04-01 4,Mack Qiao,44,15653354208,Sales,2016-02-01 5,Rachel Chen,23,13351024606,IT,2013-03-16 6,Eric Liu,19,18531054602,Marketing,2012-12-01 7,Chao Zhang,21,13235324334,Administration,2011-08-08 8,Kevin Chen,22,13151054603,Sales,2013-04-01 9,Shit Wen,20,13351024602,IT,2017-07-03 10,Shanshan Du,26,13698424612,Operation,2017-07-02
现在需要我们将这个数据转化为一个字典,这个字典的格式为:key值为文件中的名字,对应的value为新生成的一个字典,这个字典里面的键值对是新生成键值对应关系:
staff_table = {} field_list = ["num", "name", "age", "phone", "dept", "enroll_date"] def openfile(): staff_file = open("staffinfo.txt", 'r+', encoding='utf-8') for line in staff_file: line = line.strip().split(',') staff_table[line[1]] = dict(zip(field_list, line[:6]))
if __name__ == "__main__": openfile() print(staff_table)
结果为:
{'Alex Li': {'num': '1', 'name': 'Alex Li', 'age': '22', 'phone': '13651054608', 'dept': 'IT', 'enroll_date': '2013-04-01'},
'Jack Wang': {'num': '2', 'name': 'Jack Wang', 'age': '28', 'phone': '13451024608', 'dept': 'HR', 'enroll_date': '2015-01-07'},
'Rain Wang': {'num': '3', 'name': 'Rain Wang', 'age': '21', 'phone': '13451054608', 'dept': 'IT', 'enroll_date': '2017-04-01'},
'Mack Qiao': {'num': '4', 'name': 'Mack Qiao', 'age': '44', 'phone': '15653354208', 'dept': 'Sales', 'enroll_date': '2016-02-01'},
'Rachel Chen': {'num': '5', 'name': 'Rachel Chen', 'age': '23', 'phone': '13351024606', 'dept': 'IT', 'enroll_date': '2013-03-16'},
'Eric Liu': {'num': '6', 'name': 'Eric Liu', 'age': '19', 'phone': '18531054602', 'dept': 'Marketing', 'enroll_date': '2012-12-01'},
'Chao Zhang': {'num': '7', 'name': 'Chao Zhang', 'age': '21', 'phone': '13235324334', 'dept': 'Administration', 'enroll_date': '2011-08-08'},
'Kevin Chen': {'num': '8', 'name': 'Kevin Chen', 'age': '22', 'phone': '13151054603', 'dept': 'Sales', 'enroll_date': '2013-04-01'},
'Shit Wen': {'num': '9', 'name': 'Shit Wen', 'age': '20', 'phone': '13351024602', 'dept': 'IT', 'enroll_date': '2017-07-03'},
'Shanshan Du': {'num': '10', 'name': 'Shanshan Du', 'age': '26', 'phone': '13698424612', 'dept': 'Operation', 'enroll_date': '2017-07-02'}}
上面的例子很巧妙的利用了zip方法,将新的由key值组成的列表与每个line的切片(列表)构成一个新的字典。这个方法值得我们学习!
2.map()方法:
map()方法是利用一个函数操作列表,然后返回的是一个操作后的新列表,比如,我们要实现返回一个由数字组成的列表中各个元素平方的新列表:
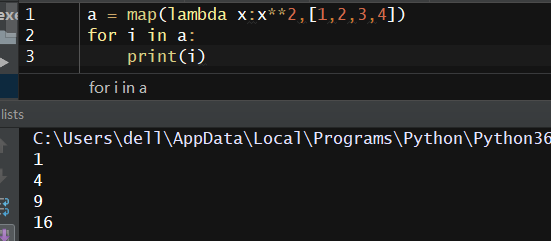
a = map(lambda x:x**2,[1,2,3,4])
这里需要注意的是:在python3中返回的是一个迭代器,所以我们需要这样取值:
2.1利用map方法规范英文名:首字母大写,后面的字母都小写:
(1)一个比较low的方式可以这样实现:
names = ['wanghw','wjwj','WFJK'] def format_name(name): return name[0].upper()+name[1:].lower() names_new = map(format_name,names) for i in names_new: print(i)
#在python3中也可以print(list(name_new))
结果为

(2)我们也可以利用python自带的capitalize方法:
names = ['wanghw','wjwj','WFJK'] def format_name(name): return name.capitalize() names_new = map(format_name,names) for i in names_new: print(i)
当然,也可以利用lambda方法可以节省代码:
names = ['wanghw','wjwj','WFJK'] names_new = map(lambda x:x.capitalize(),names) for i in names_new: print(i)
结果是完全一样的。
3.filter()方法:
filter()函数接受一个函数f与一个list,这个函数f的作用是对每个元素进行判断,返回True或者False。filter函数根据判断的结果自动过滤掉不符合条件的元素,返回由符合条件的元素组成的list。
比如,返回列表中的奇数,可以这样做:
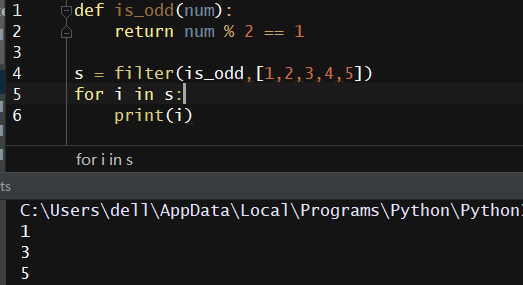
def is_odd(num): return num % 2 == 1 filter(is_odd,[1,2,3,4,5])
当然,filter在python3中返回的也是一个可迭代的对象,所以我们可以这样取值:
(1)我们可以利用filter函数过滤掉列表中值为None或者空字符:
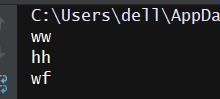
list1 = ['ww','hh','','',None,'wf'] def is_not_empty(s): return s and len(s.strip())>0 a = filter(is_not_empty,list1) for i in a: print(i)
结果为:
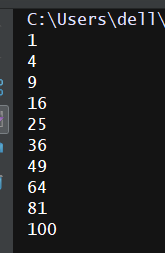
(2)利用filter过滤掉1--100中平方根为整数的数字
import math def func(num): return math.sqrt(num) and int(math.sqrt(num))==math.sqrt(num) a = filter(func,range(1,101)) for i in a: print(i)
结果为:
4.sorted()方法:
sorted方法用于排序操作。注意sort()方法仅能用于列表,而sorted()方法可以用于任何可迭代的对象,所以我们这里介绍一下sorted方法。sorted方法默认排序方式为升序。
值得注意的一点是,sorted方法是保留原来的数据的,比如我们要对a = [1,4,6,3,2]进行排序:
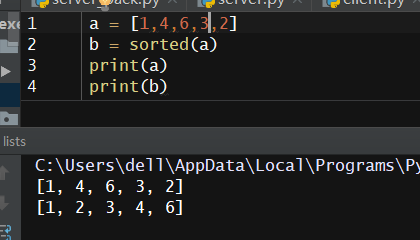
原来的列表a是不变的!
(1)对列表l = [('b',2),('a',1),('c',3)]按照数字排序:
l = [('b',2),('a',1),('c',3)] a = sorted(l,key=lambda x:x[1]) print(a)
结果为:
[('a', 1), ('b', 2), ('c', 3)]
(2)对列表students = [('w','A',15),('h','A',16),('j','A',25)]按照数字的降序排序
students = [('w','A',15),('h','A',16),('j','A',25)] a = sorted(students,key=lambda x:x[2],reverse=True) print(a)
结果为:
[('j', 'A', 25), ('h', 'A', 16), ('w', 'A', 15)]
需要注意的是,python3中sorter没有cmp,排序是按照key跟reverse来的:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号