
关于Python的源文件编译看这一篇就够了
前提概要
Python解释器版本:3.6.8
操作系统:MacOS
编译源文件的必要性
在实际的项目部署时,为了保护源代码,我们通常会在部署项目之前将后端写好的py文件编译成pyc文件。
pyc文件是是一种二进制文件,是由py文件经过编译后生成的文件,是一种byte code。py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的虚拟机来执行的,这个是类似于JAVA或者.NET的虚拟机的概念。
pyc的内容,是跟python的版本相关的,不同版本编译后的pyc文件是不同的,py2编译的pyc文件,py3版本的python是无法执行的。
当然pyc文件也是可以反编译的,不同版本编译后的pyc文件是不同的,根据python源码中提供的opcode,可以根据pyc文件反编译出 py文件源码,不过你可以自己修改python的源代码中的opcode文件,重新编译 python从而防止不法分子的破解。
总之,编译源文件后再去部署项目可以十分有效的保护项目的源代码不被外人所窥视。
测试的项目
测试的项目目录结构如下:
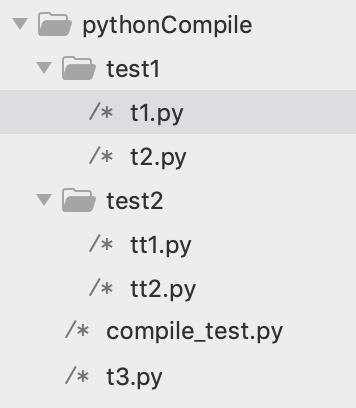
本文使用这个项目的目录结构作为测试的说明。


~/Desktop/pythonCompile
.
├── compile_test.py
├── t3.py
├── test1
│ ├── t1.py
│ └── t2.py
└── test2
├── tt1.py
└── tt2.py
python默认情况下做的编译
其实Python在模块导入的过程中会在当前脚本的项目的目录下自动生成一个名为__pycache__的目录,在这里面存放被导入模块的编译以后的pyc文件。
在上面的文件中我们做一下测试:
test1目录下的py文件的内容如下:
t1.py:
# -*- coding:utf-8 -*- def func1(): print("调用func1...")
t2.py
# -*- coding:utf-8 -*- from test1.t1 import func1 ret1 = func1() print("在t2中调用t1的函数后执行...")
test2目录下的py文件的内容如下:
tt1.py
# -*- coding:utf-8 -*- def func_tt1(): print("调用tt1.....")
tt2.py
# -*- coding:utf-8 -*- from test2.tt1 import func_tt1 func_tt1() print("调用tt1后执行...")
t3.py文件中的内容如下 —— 注意模块导入的操作
# -*- coding:utf-8 -*- import os import sys ### 将当前目录放在sys.path中才能正常导入模块 BASE_DIR = os.path.dirname(os.path.abspath(__file__)) sys.path.append(BASE_DIR) ### 测试 # 导入tt2会执行tt2中的内容 from test2 import tt2
然后我们执行一下t3.py,可以看到在test2中生成了__pycache__这个目录,让我们再看看目录中的内容:

也就是说,在默认情况下,其实Python就为我们做了优化:只要源文件不改变,生成默认的pyc文件后以后会执行编译好的pyc文件中的内容,这样大大提高了程序执行的效率!
手动生成pyc文件 ***
Python内置了两个模块来帮助我们编译py源文件,一个是py_compile(编译单个文件),另外一个是compileall(编译一个目录下所有的文件)。下面我们分别来介绍一下他们的使用。
编译单个文件
默认时的编译
注意操作前先把上面步骤中的两个__pycache__目录与目录下的文件删掉!
在根目录下的compile_test.py文件中加入编译单个文件的代码:
import os import py_compile current_dir = os.path.dirname(os.path.abspath(__file__)) print(current_dir) ### 编译单个文件 t2_path = os.path.join(current_dir,"test1","t2.py") py_compile.compile(t2_path)
执行上面的代码后我们可以看到:默认情况下会在被编译文件的同目录下生成一个名为__pycache__的目录,里面存放着编译后的文件:
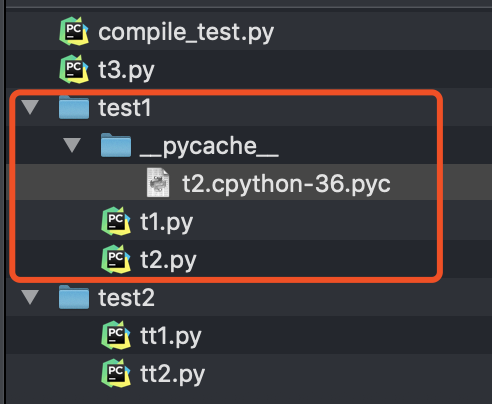
我们上面的代码编译的是t2.py,所以会看到上面的结果。
指定目录与文件名的编译方法
当然,我们可以看到上面这种编译方式不是很理想:一方面实际中我们想把编译后的文件与源文件放在一起,另外源文件编译后我们想把它删掉,以后直接用编译后的文件跑项目。
我们可以修改一下编译的代码:
import os import py_compile current_dir = os.path.dirname(__file__) print(current_dir) ### 编译单个文件 t2_path = os.path.join(current_dir,"test1","t2.py") # 指定cfile可以与源文件在一个目录而不是放在__pycache__目录,并且指定编译后文件的名字 py_compile.compile(t2_path,cfile="test1/t2.pyc")
在指定了cfle这个参数后,我们可以达到上面的需求:
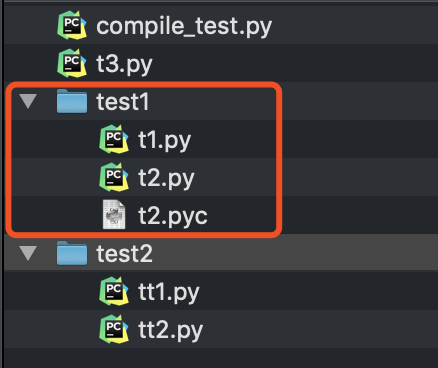
py_compile的compile方法的源码
这里把py_compile.compile的源码给大家看看,帮助大家理解:
def compile(file, cfile=None, dfile=None, doraise=False, optimize=-1): """Byte-compile one Python source file to Python bytecode. :param file: The source file name. :param cfile: The target byte compiled file name. When not given, this defaults to the PEP 3147/PEP 488 location. :param dfile: Purported file name, i.e. the file name that shows up in error messages. Defaults to the source file name. :param doraise: Flag indicating whether or not an exception should be raised when a compile error is found. If an exception occurs and this flag is set to False, a string indicating the nature of the exception will be printed, and the function will return to the caller. If an exception occurs and this flag is set to True, a PyCompileError exception will be raised. :param optimize: The optimization level for the compiler. Valid values are -1, 0, 1 and 2. A value of -1 means to use the optimization level of the current interpreter, as given by -O command line options. :return: Path to the resulting byte compiled file. Note that it isn't necessary to byte-compile Python modules for execution efficiency -- Python itself byte-compiles a module when it is loaded, and if it can, writes out the bytecode to the corresponding .pyc file. However, if a Python installation is shared between users, it is a good idea to byte-compile all modules upon installation, since other users may not be able to write in the source directories, and thus they won't be able to write the .pyc file, and then they would be byte-compiling every module each time it is loaded. This can slow down program start-up considerably. See compileall.py for a script/module that uses this module to byte-compile all installed files (or all files in selected directories). Do note that FileExistsError is raised if cfile ends up pointing at a non-regular file or symlink. Because the compilation uses a file renaming, the resulting file would be regular and thus not the same type of file as it was previously. """ if cfile is None: if optimize >= 0: optimization = optimize if optimize >= 1 else '' cfile = importlib.util.cache_from_source(file, optimization=optimization) else: cfile = importlib.util.cache_from_source(file) if os.path.islink(cfile): msg = ('{} is a symlink and will be changed into a regular file if ' 'import writes a byte-compiled file to it') raise FileExistsError(msg.format(cfile)) elif os.path.exists(cfile) and not os.path.isfile(cfile): msg = ('{} is a non-regular file and will be changed into a regular ' 'one if import writes a byte-compiled file to it') raise FileExistsError(msg.format(cfile)) loader = importlib.machinery.SourceFileLoader('<py_compile>', file) source_bytes = loader.get_data(file) try: code = loader.source_to_code(source_bytes, dfile or file, _optimize=optimize) except Exception as err: py_exc = PyCompileError(err.__class__, err, dfile or file) if doraise: raise py_exc else: sys.stderr.write(py_exc.msg + '\n') return try: dirname = os.path.dirname(cfile) if dirname: os.makedirs(dirname) except FileExistsError: pass source_stats = loader.path_stats(file) bytecode = importlib._bootstrap_external._code_to_bytecode( code, source_stats['mtime'], source_stats['size']) mode = importlib._bootstrap_external._calc_mode(file) importlib._bootstrap_external._write_atomic(cfile, bytecode, mode) return cfile
编译多个文件
注意操作前先把前面编译的文件删掉!
默认时的编译
默认不加参数的编译方法如下:
import os import compileall current_dir = os.path.dirname(__file__) print(current_dir) compile_dir = os.path.join(current_dir,"test2") ### 编译一个目录下的所有文件 compileall.compile_dir(compile_dir)
这样的话会在test2目录下生成默认的__pycache__存放编译文件的目录:

指定目录与文件名的编译方法
import os import compileall current_dir = os.path.dirname(__file__) print(current_dir) compile_dir = os.path.join(current_dir,"test2") ### 编译一个目录下的所有文件 # 指定legacy为True后生成的pyc文件会与当前文件放在同一个目录下并且后缀名字是原来的后缀名字加一个c compileall.compile_dir(compile_dir,legacy=True)
指定了legacy为True后我们可以看到在同目录下生成了对应名字的编译文件:
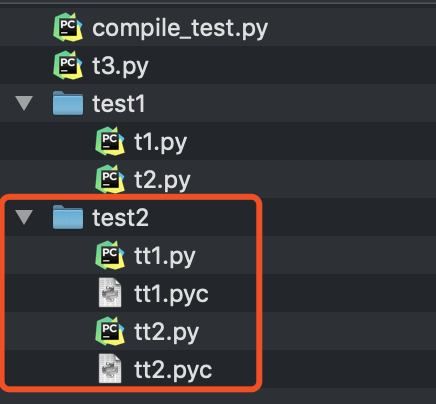
编译项目所有文件的方法
也很简单,直接把项目的目录放进去就好了:
import os import compileall current_dir = os.path.dirname(__file__) print(current_dir) ### 编译一个目录下的所有文件 # 指定legacy为True后生成的pyc文件会与当前文件放在同一个目录下并且后缀名字是原来的后缀名字加一个c compileall.compile_dir(current_dir,legacy=True)
结果如下:
compileall.compile_dir的源码
def compile_dir(dir, maxlevels=10, ddir=None, force=False, rx=None, quiet=0, legacy=False, optimize=-1, workers=1): """Byte-compile all modules in the given directory tree. Arguments (only dir is required): dir: the directory to byte-compile maxlevels: maximum recursion level (default 10) ddir: the directory that will be prepended to the path to the file as it is compiled into each byte-code file. force: if True, force compilation, even if timestamps are up-to-date quiet: full output with False or 0, errors only with 1, no output with 2 legacy: if True, produce legacy pyc paths instead of PEP 3147 paths optimize: optimization level or -1 for level of the interpreter workers: maximum number of parallel workers """ ProcessPoolExecutor = None if workers is not None: if workers < 0: raise ValueError('workers must be greater or equal to 0') elif workers != 1: try: # Only import when needed, as low resource platforms may # fail to import it from concurrent.futures import ProcessPoolExecutor except ImportError: workers = 1 files = _walk_dir(dir, quiet=quiet, maxlevels=maxlevels, ddir=ddir) success = True if workers is not None and workers != 1 and ProcessPoolExecutor is not None: workers = workers or None with ProcessPoolExecutor(max_workers=workers) as executor: results = executor.map(partial(compile_file, ddir=ddir, force=force, rx=rx, quiet=quiet, legacy=legacy, optimize=optimize), files) success = min(results, default=True) else: for file in files: if not compile_file(file, ddir, force, rx, quiet, legacy, optimize): success = False return success
脚本方式生成编译文件 ***
上面的方式仍然有点繁琐,我们可以使用脚本的方法,指定项目目录来生成编译文件:
默认情况
安装好Python解释器后直接运行即可:
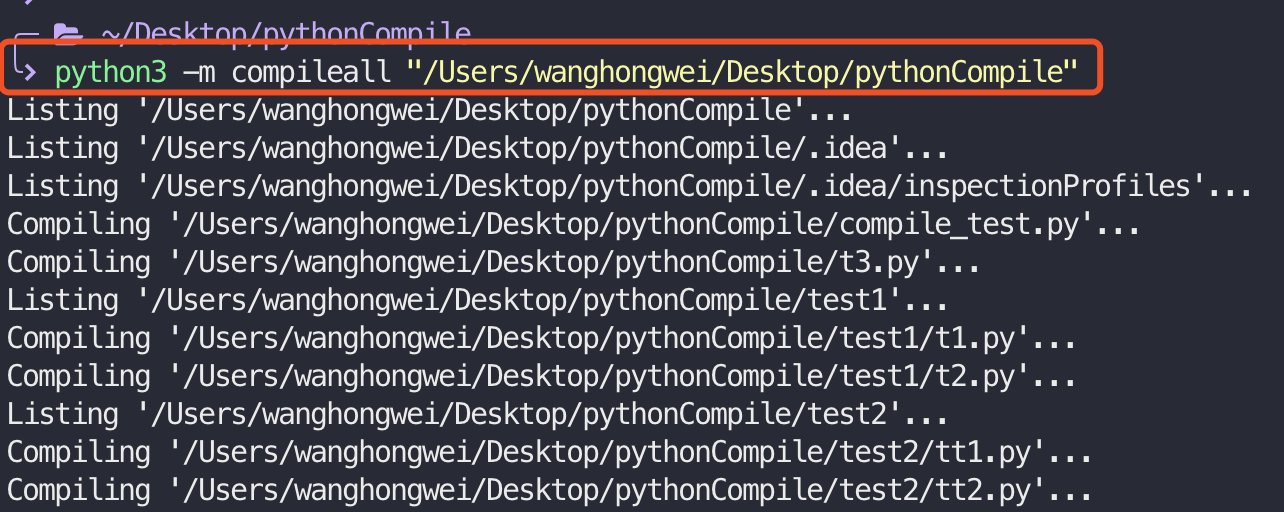
python3 -m compileall "需要编译的项目目录"
比如上面这个目录的编译过程:
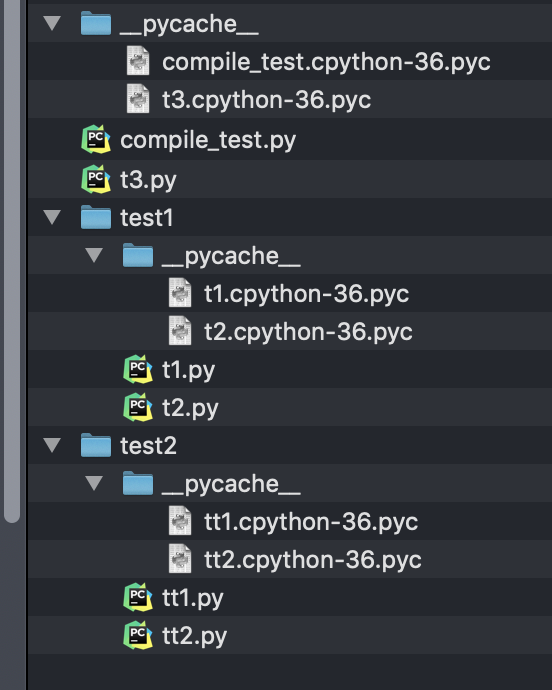
结果如下:
指定目录与文件名的方法
只需要加一个-b参数即可:
python3 -m compileall -b "需要编译的项目目录"
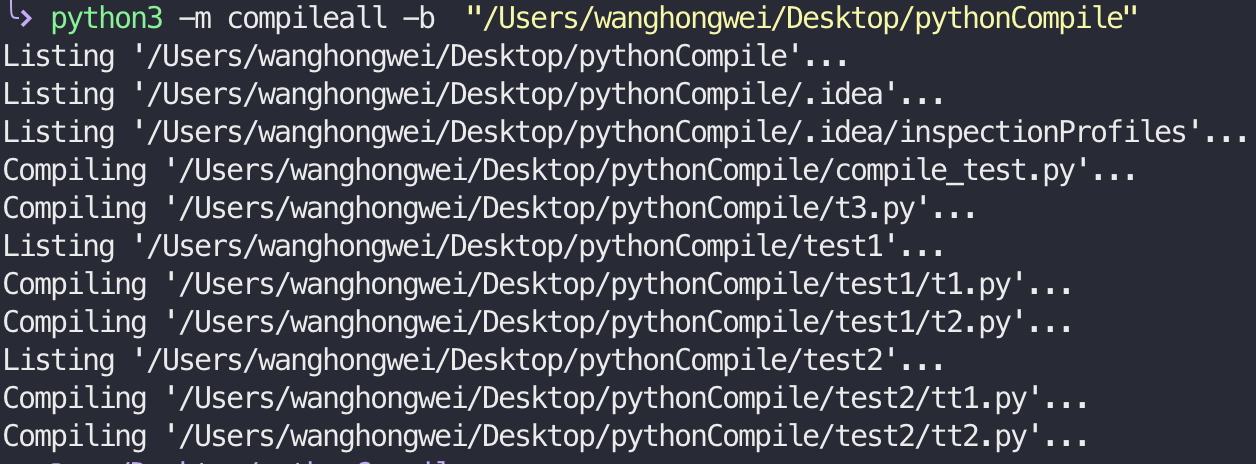
结果如下:
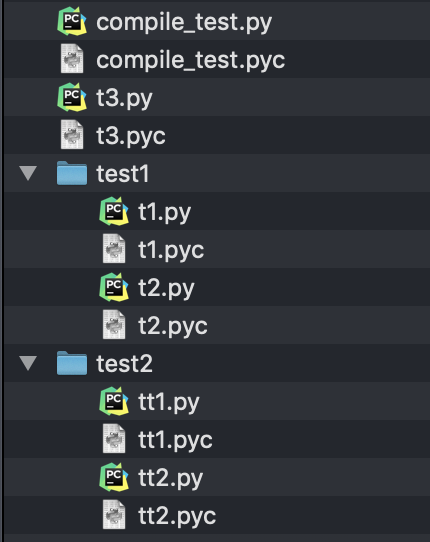
删除原来的py文件或者__pycache__目录:
在项目目录下执行:
find ./ -name "*.py" |xargs rm -rf
find ./ -name “__pycache__” |xargs rm -rf
结果如下:
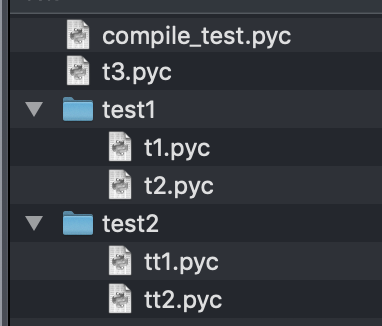
这样,线上部署的代码就不怕被偷窥了!
编译后的文件与源文件同时存在时的说明与测试 ***
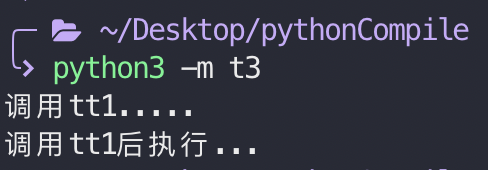
接下来我们测试一下编译后的结果。
在项目目录的下执行t3,可以看到还是能看到结果:
但是问题来了:如果我们把源py文件与编译后的pyc文件放在一起的话,而且二者的内容不一样会出现什么情况呢?
我们来测试一下,恢复test2目录中的tt2.py源文件,并且修改tt2.py中的内容!
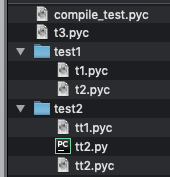
并且修改tt2.py文件中的内容如下:
print("修改tt2中的内容!!!")
然后运行一下看看效果:
我们可以看到:如果源文件与编译后的文件同时存在的话,在导入模块时会优先执行源文件中的内容!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号