
ORM多表查询典型练习
表字段及关系


from django.db import models class AuthorDetail(models.Model): id = models.AutoField(primary_key=True) telephone = models.CharField(max_length=11) addr = models.CharField(max_length=50) class Author(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=12) age = models.IntegerField() gender = models.CharField(max_length=5,default='男') ad = models.OneToOneField(to='AuthorDetail',to_field='id',on_delete=models.CASCADE) class Publish(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=22) city = models.CharField(max_length=20) class Book(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=33) price = models.DecimalField(max_digits=8,decimal_places=2) ups = models.IntegerField(default=3) comments = models.IntegerField(default=1) publisher = models.ForeignKey(to='Publish',to_field='id',on_delete=models.CASCADE) authors = models.ManyToManyField(to='Author')
插入数据
def insert_data(request): # 作者详情 for i in range(1,10): AuthorDetail.objects.create(telephone='11%s'%i,addr='666%s'%i) #出版社 name_lst = ['苹果', '橘子', '樱桃', '西瓜', '橙子'] city_lst = ['北京', '上海', '成都', '包头', '呼和浩特'] obj_lst = [] for index,name in enumerate(name_lst): obj = Publish(name='%s出版社'%name,city=city_lst[index]) obj_lst.append(obj) Publish.objects.bulk_create(obj_lst) #作者 name_lst = ['whw', 'www', 'naruto', 'sasuke', 'sb','nb','yuri','kaka','aobama'] for index,name in enumerate(name_lst,1): #批量添加 Author.objects.create(name=name,age=18+index,ad_id=index) # 书籍 # 一对多添加记录—— # 也可以找到publish对象(pub_obj)~然后让Book的publisher=pub_obj # 但这种最常用 book1 = Book.objects.create(title='linux',price=12.23,publisher_id=1) book2 = Book.objects.create(title='python',price=22.23,publisher_id=5) book3 = Book.objects.create(title='go',price=223.13,publisher_id=3) book4 = Book.objects.create(title='ruby',price=112.23,publisher_id=2) book5 = Book.objects.create(title='java',price=31.23,publisher_id=4) book6 = Book.objects.create(title='cpp',price=14.23,publisher_id=1) book7 = Book.objects.create(title='c',price=56.23,publisher_id=2) book8 = Book.objects.create(title='rsb',price=51.23,publisher_id=5) book9 = Book.objects.create(title='xsd',price=12.23,publisher_id=3) book10 = Book.objects.create(title='lsi',price=6.23,publisher_id=1)
##多对多添加记录~~基于上面创建好的对象来的 ##这种最常用~因为从前端返回的数据很多都是放在列表中的 book1.authors.add(*[2,3]) book2.authors.add(*[9,3]) book3.authors.add(*[2,9]) book4.authors.add(*[2,3]) book5.authors.add(*[3]) book6.authors.add(*[6,2]) book7.authors.add(*[1,5,8]) book8.authors.add(*[4]) book9.authors.add(*[7,3]) book10.authors.add(*[1,6,3]) return HttpResponse('OJ8K')
基本查询的练习
def pr(request): # 一对多 # 红浪漫出版了哪些书 Publish.objects.filter(name='红浪漫出版社').values('book__title') Book.objects.fitler(publishs__name='红浪漫出版社').values('title') # 多对多 # python这本书是哪些作者写的 Book.objects.filter(title='python').values('authors__name') Author.objects.filter(book__title='python').values('name') #聚合查询 #查找所有书籍的平均价格及最高价格 ret = Book.objects.all().aggregate(avg_price=Avg('price'),max_price=Max('price')) print(ret) #F与Q查询 #点赞数大于评论数的书籍名称 ret = Book.objects.filter(ups__gt=F('comments')).values('title') print(ret) #查询点赞数小于100或者评论大于10的书籍名称 ret = Book.objects.filter(Q(ups__gt=100)|Q(comments__gt=10)).values('title') print(ret) #给价格小于10元的书籍的价格增加10元 Book.objects.filter(price__lt=10).update(price=F('price')+10) #分组查询 #每个作者出版过的书的平均价格 ret = Author.objects.values('name').annotate(avg_price=Avg('book__price')) print(ret) ret = Book.objects.values('authors__name').annotate(avg_price=Avg('price')) print(ret) return HttpResponse('OJ8K!')
几个经典的查询以及一个无法用ORM查询的例子
def search(request): # 1 查询每个作者的姓名以及出版的书的最高价格 ret = Author.objects.values('name').annotate(max_price=Max('book__price')) print(ret) # # # 2 查询作者id大于2作者的姓名以及出版的书的最高价格 # 两种效果一样 #方法一: ret = Author.objects.filter(id__gt=2).values('name').annotate(max_price=Max('book__price')) print(ret) #方法二: # 这个values取得是前面调用这个方法的表的所有字段值以及max_pirce的值,这也是为什么我们取关联数据的时候要加双划线的原因 ret = Author.objects.filter(id__gt=2).annotate(max_price=Max('book__price')).values('name','max_price') print(ret) # 3 查询作者id大于2或者作者年龄大于等于20岁的女作者的姓名以及出版的书的最高价格 # 方法一: ret = Author.objects.filter(Q(gender='女') & Q(Q(id__gt=2)|Q(age__gte=20))).values('name').annotate( max_price=Max('book__price')) print(ret) # 方法二: ret = Author.objects.filter(Q(id__gt=2) | Q(age__gte=20), gender='女').annotate( max_price=Max('book__price')).values('name', 'max_price') print(ret) # 4 查询每个作者出版的书的最高价格的平均值 ret = Author.objects.values('name').annotate(max_price=Max('book__price')).aggregate(Avg('max_price')) print(ret)# 字典:{'max_price__avg': 89.43} ret = Author.objects.values('id').annotate(max_price=Max('book__price')).aggregate(Avg('max_price')) print(ret)# 字典:{'max_price__avg': 89.43} ### 每个作者出版的所有书的价格以及最高价格的那本书的名称 #5 先找出:每个作者出版的所有书以及书的最高价格~然后进行数据处理 ret = Author.objects.values('name').annotate(titles=Concat('book__title'),max_price=Max('book__price')) print(ret) # import decimal # for dic in ret: # dic['max_price']=str(decimal.Decimal(dic['max_price']).quantize(decimal.Decimal('0.00'))) # # print(dic, '>>>', dic['max_price'],type(dic['max_price'])) # print(dic, '>>>', dic['titles'],type(dic['titles'])) # print(ret) #。。。。。。 # 6 每个作者出版的所有书的最高价格的那本书的名称(通过orm玩起来就是个死题,需要用原生sql) ''' -- 先连两次表 后按照作者分组 ''' ''' --第一种写法: select title,price from (select app01_author.id,app01_book.title,app01_book.price from app01_author INNER JOIN app01_book_authors on app01_author.id=app01_book_authors.author_id INNER JOIN app01_book on app01_book.id=app01_book_authors.book_id ORDER BY app01_book.price desc) as b GROUP BY id ''' ''' -- 第二种写法: select * from (select * from (select title,price,author_id from book_book inner join book_book_authors on book_book.id = book_book_authors.book_id )as t1 inner join book_author on t1.author_id=book_author.id group by name) as t2 order by t2.id ''' return HttpResponse('OJ8K')
连续跨表的几个练习
# 练习: 查询人民出版社出版过的所有书籍的名字以及作者的姓名 # 正向查询 queryResult=Book.objects .filter(publish__name="人民出版社") .values_list("title","authors__name") # 反向查询 queryResult=Publish.objects .filter(name="人民出版社") .values_list("book__title","book__authors__age","book__authors__name") # 练习: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称 # 方式1: queryResult=Book.objects .filter(authors__authorDetail__telephone__regex="151") .values_list("title","publish__name") # 方式2: ret=Author.objects .filter(authordetail__telephone__startswith="151") .values("book__title","book__publish__name")
sql_mode=only_full_group_by与分组的一个问题
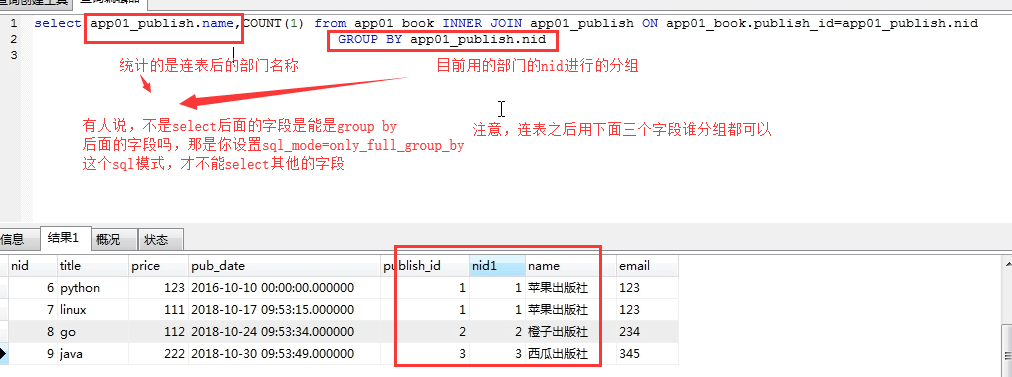
自定义类实现GROUNP_CONCAT的效果
具体过程见这个博客:https://www.cnblogs.com/paulwhw/p/10941150.html
def concat(request): # 单表:用publisher_id分组,找每个分组中的书籍名称 ret = Book.objects.values('publisher_id').annotate(titles=Concat('title')) print(ret) #<QuerySet [{'publisher_id': 21, 'titles': 'linux,cpp,lsi'}, {'publisher_id': 22, 'titles': 'ruby,c'}, # {'publisher_id': 23, 'titles': 'go,xsd'}, {'publisher_id': 24, 'titles': 'java'}, {'publisher_id': 25, 'titles': 'python,rsb'}]> #跨表:每个出版社出版的所有的书籍 #方法一:以publish表为基准去查 # ret = Publish.objects.values('name').annotate(titles=Concat('book__title')) ret = Publish.objects.values('name').annotate(titles=Concat('book__title')) print(ret) #<QuerySet [{'name': '樱桃出版社', 'titles': 'go,xsd'}, {'name': '橘子出版社', 'titles': 'ruby,c'}, # {'name': '橙子出版社', 'titles': 'python,rsb'}, {'name': '苹果出版社', 'titles': 'linux,cpp,lsi'}, {'name': '西瓜出版社', 'titles': 'java'}]> #方法二:以book表为基准去查 ret = Book.objects.values('publisher__name').annotate(titles=Concat('title')) print(ret) #<QuerySet [{'publisher__name': '樱桃出版社', 'titles': 'go,xsd'}, {'publisher__name': '橘子出版社', 'titles': 'ruby,c'}, # {'publisher__name': '橙子出版社', 'titles': 'python,rsb'}, {'publisher__name': '苹果出版社', 'titles': 'linux,cpp,lsi'}, # {'publisher__name': '西瓜出版社', 'titles': 'java'}]> return HttpResponse('Concat')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号