
线程2 —— enumerate方法、守护线程、线程锁、死锁现象(递归锁与互斥锁)、线程队列、进程池与线程池
一:threading的enumerate方法:返回正在运行的Thread对象列表
(1)正常的写法:
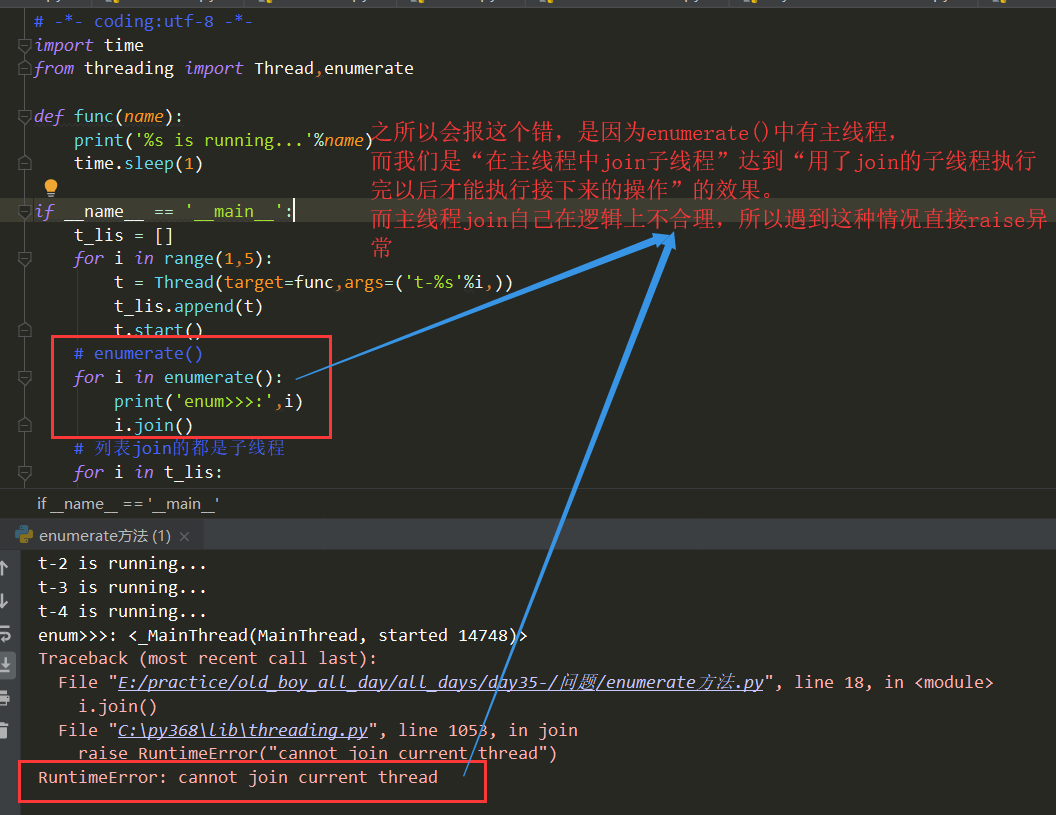
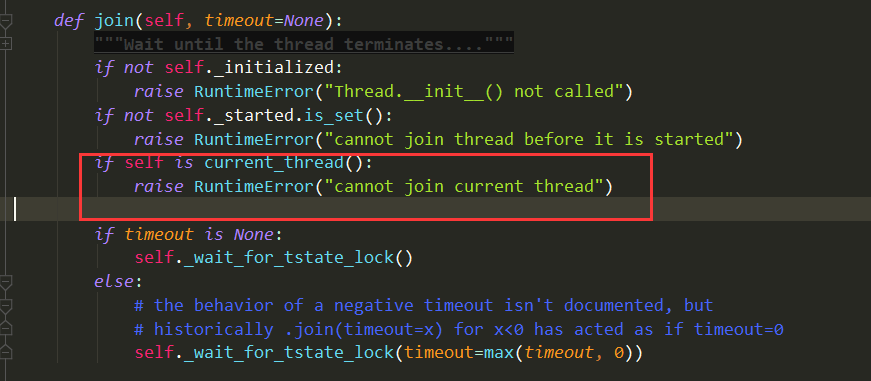
# -*- coding:utf-8 -*- import time from threading import Thread,enumerate def func(name): print('%s is running...'%name) time.sleep(1) if __name__ == '__main__': t_lis = [] for i in range(1,5): t = Thread(target=func,args=('t-%s'%i,)) t_lis.append(t) t.start() # enumerate() for i in enumerate(): print('enum>>>:',i) # 由于里面有主线程,不可以join主线程“自己本身”—— “自己等待自己运行完” # 因此如果遍历enumerate()去join的话程序会报错 # RuntimeError: cannot join current thread # i.join() # 列表join的都是子线程 for i in t_lis: print('lis>>>:', i) i.join() print('结束')
结果如下:
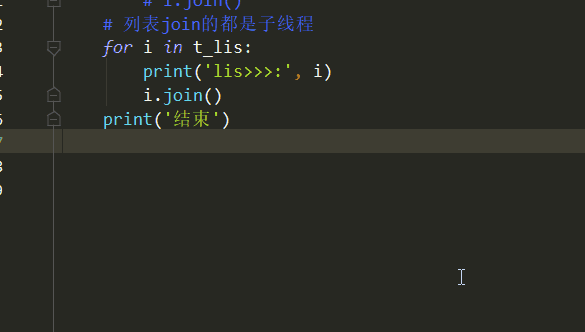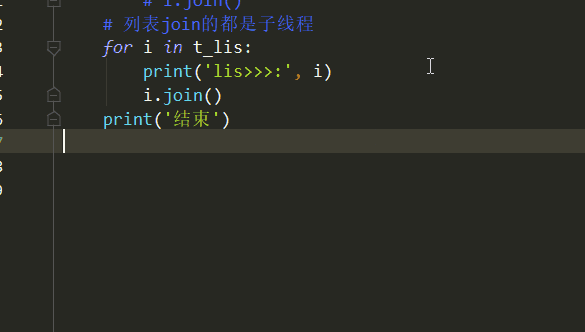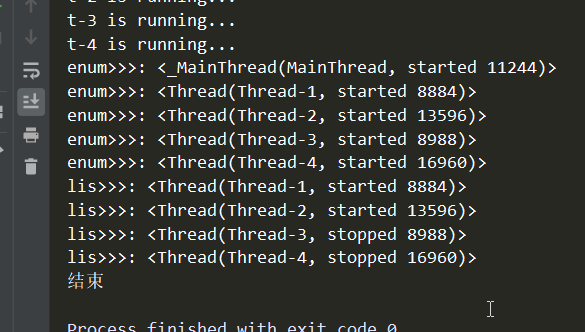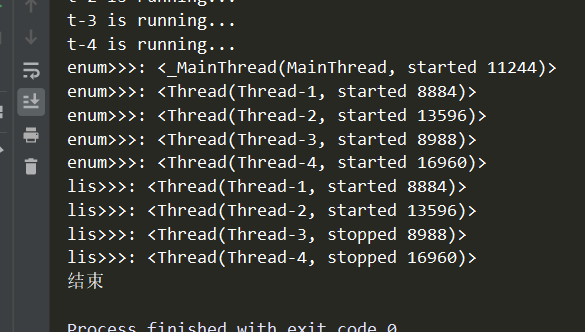
注意里面有主线程,因此不能遍历去join(把上面程序中遍历enumerate()中的i.join()放开的话会报错):
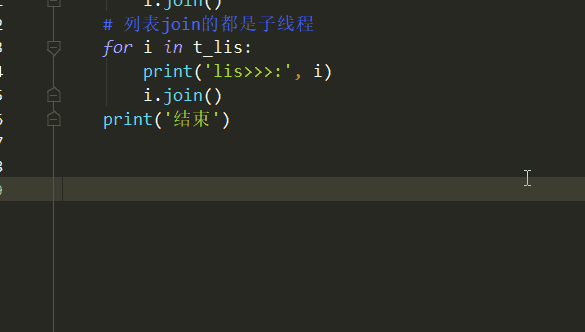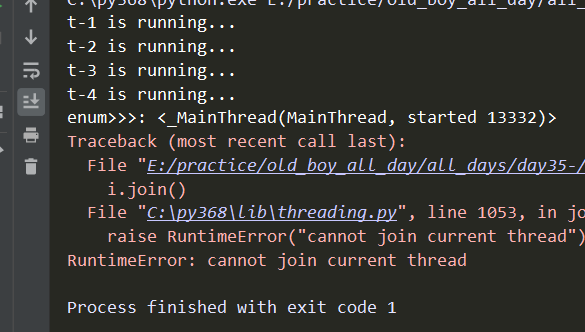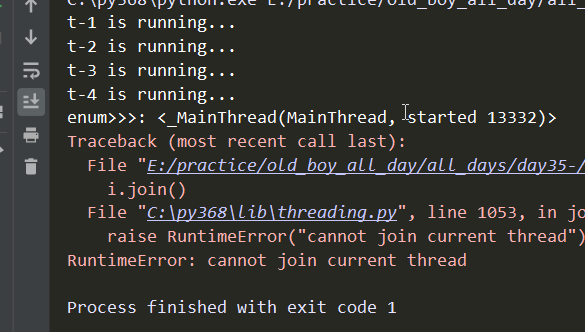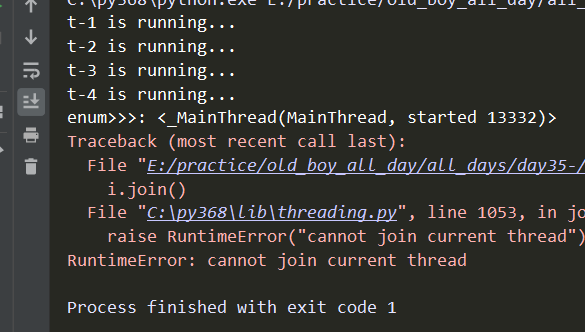
二、守护线程:守护线程会守护主线程与所有的子线程(认真理解~记住现象,理解本质! )
# -*- coding:utf-8 -*- import time from threading import Thread def daemon_func(): while 1: time.sleep(0.5) print('守护线程') def son_func(): print('start son') time.sleep(5) print('end son') if __name__ == '__main__': t = Thread(target=daemon_func) # 将t设置为守护线程 t.daemon = True t.start() # 开启另外一个子线程 Thread(target=son_func).start() time.sleep(3) print('主线程结束')
运行效果:

几个重要结论:
***(1)主线程会等待子线程的结束而结束
***(2)守护线程会守护主线程与所有的子线程 ———— 注意与守护进程不一样!守护进程守护的是主进程的代码!
***(3)进程会随着主线程的结束而结束
## 主线程需不需要回收子线程的资源?
## 线程资源属于进程的!进程结束了线程的资源自然被回收了!
## 主线程为什么要等待子线程的结束而结束?
## 主线程结束了意味着进程就结束了!所有子线程都会结束,要想让所有子线程顺利执行完,主线程必须等。
## 守护线程到底是怎么结束的?
## 是因为主线程结束了主进程也结束,守护线程因主进程的结束而结束。
三:线程锁(GIL与线程锁的关系)
# 1.GIL锁:保证线程同一时刻只能一个线程访问CPU,不可能有两个线程同时在CPU上执行指令
# 2.线程锁Lock:保证某一段代码在没有执行完毕之后,不可能有另一个线程也执行
即使Python解释器有GIL锁,但是仍然会产生数据的安全性问题:通过加锁(线程锁)来解决
## 在线程中也会出现数据不安全问题
##1、对全局变量进行修改
##2、对某个值 += -= *= /=
(1)下面数据类型已经写好的方法是绝对数据安全的!
list:pop append extend insert remove
dict:pop update
(2)但是能分解为几个操作的操作是不安全的:
lis[0] += 1
lis[0] -= 1
lis[0] *= 2
lis[0] /= 2
(3)list的pop/append方法与queue的put/get方法:
pop列表为空的时候会报错
get队列为空的时候会等待
四:死锁现象——解决方式:递归锁、互斥锁
死锁现象:
'''
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。
此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
'''
“吃面问题”
# -*- coding:utf-8 -*- from threading import Lock,Thread noodle_lock = Lock() fork_lock = Lock() def eat1(name): noodle_lock.acquire() print('%s 拿到面了'%name) fork_lock.acquire() print('%s 拿到叉子了' % name) print('%s 吃面'%name) fork_lock.release() print('放下叉子') noodle_lock.release() print('放下面') def eat2(name): fork_lock.acquire() print('%s 拿到叉子了' % name) noodle_lock.acquire() print('%s 拿到面了' % name) print('%s 吃面' % name) noodle_lock.release() print('放下面') fork_lock.release() print('放下叉子') Thread(target=eat1,args=('whw1',)).start() Thread(target=eat2,args=('whw2',)).start() Thread(target=eat1,args=('whw3',)).start()
#1、递归锁可以快速解决问题,但是效率比较低;互斥锁执行效率比较高,但是需要设计程序逻辑——比较复杂;
#2、实际中遇到问题的话先用递归锁快速解决,然后再研究程序逻辑,逐步用互斥锁解决。
(1)递归锁解决:(快速,但会导致程序效率变低)
# 注意 只要是两个及以上的锁交替使用,递归锁与互斥锁都有可能产生死锁!
#1、下面这种写法,用的是一把锁!一个Rlock实例化的对象,因此不会产生死锁
fork_lock = noodle_lock = RLock()
#2、下面这种写法,其实是两个锁(两个对象),交替使用的话会产生死锁
fork_lock = RLock()
noodle_lock = RLock()
递归锁的正确解决方法:
from threading import RLock,Thread # 设置成递归锁 fork_lock = noodle_lock = RLock() def eat1(name): noodle_lock.acquire() print('%s拿到面了'%name) fork_lock.acquire() print('%s拿到叉子了' % name) print('%s吃面'%name) fork_lock.release() print('%s放下叉子了' % name) noodle_lock.release() print('%s放下面了' % name) def eat2(name): fork_lock.acquire() print('%s拿到叉子了' % name) noodle_lock.acquire() print('%s拿到面了'%name) print('%s吃面'%name) noodle_lock.release() print('%s放下面了' % name) fork_lock.release() print('%s放下叉子了' % name) Thread(target=eat1,args = ('alex',)).start() Thread(target=eat2,args = ('wusir',)).start() Thread(target=eat1,args = ('baoyuan',)).start()
(2)互斥锁解决:(效率高,需要设计程序逻辑,解决问题慢)
from threading import Lock,Thread lock = Lock() def eat1(name): lock.acquire() print('%s拿到面了'%name) print('%s拿到叉子了' % name) print('%s吃面'%name) print('%s放下叉子了' % name) print('%s放下面了' % name) lock.release() def eat2(name): lock.acquire() print('%s拿到叉子了' % name) print('%s拿到面了'%name) print('%s吃面'%name) print('%s放下面了' % name) print('%s放下叉子了' % name) lock.release() Thread(target=eat1,args = ('alex',)).start() Thread(target=eat2,args = ('wusir',)).start() Thread(target=eat1,args = ('baoyuan',)).start()
关于递归锁的说明:
(1) 在单线程下,递归锁永远不会出现死锁现象;
(2)但是在多线程下如果这样赋值
noodle_lock = Rlock()
fork_lock = Rlock()
如果出现多个线程竞争一把锁的现象,也会出现死锁!
(3)多线程下应该这样写(实际上就是一把锁了):
fork_lock = noodle_lock = water_noodle_lock = Rlocl()
五:线程队列
队列的取值看这篇博客:put_nowait与get_nowait
(1)先进先出队列 FIFO
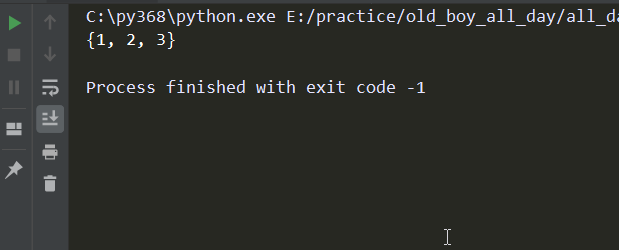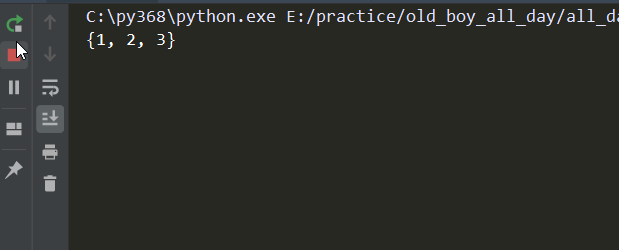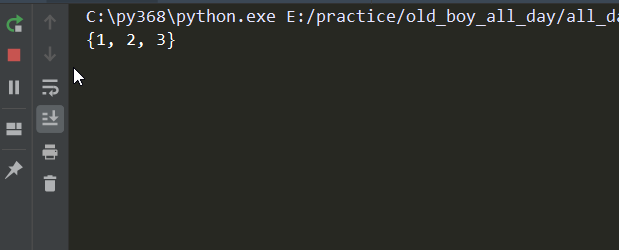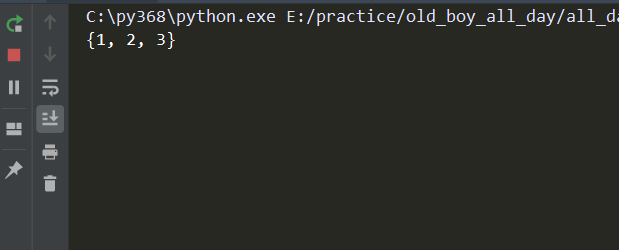
# -*- coding:utf-8 -*- from queue import Queue q = Queue() ''' 注意下面这些方法在多线程下都不准 # # 在多线程下都不准 # # q.empty() 判断是否为空 # # q.full() 判断是否为满 # # q.qsize() 队列的大小 ''' q.put({1,2,3}) print(q.get_nowait()) # 队列中没有值了,get方法不会报错,会一直等 print(q.get())
结果:
(2)后进先出队列 LIFO
# -*- coding:utf-8 -*- from queue import LifoQueue q = LifoQueue() q.put(123) q.put(456) q.put(789) print(q.get()) # 789 print(q.get()) # 456 print(q.get()) # 123
(3)优先级队列
# -*- coding:utf-8 -*- from queue import PriorityQueue pq = PriorityQueue() pq.put((100,'qwe')) pq.put((10,'aaa')) pq.put((66,'ghj')) print(pq.get()) print(pq.get()) print(pq.get())
结果:
(10, 'aaa') (66, 'ghj') (100, 'qwe')
六:进程池
'''
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。
当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好。
但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;
但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
'''
(1)简单的实现
# -*- coding:utf-8 -*- import os,time,random from concurrent.futures import ProcessPoolExecutor def func(name): print('name:%s,pid:%s'%(name,os.getpid())) time.sleep(random.random()) if __name__ == '__main__': pool = ProcessPoolExecutor(2) for i in range(1,6): # 注意这里直接按照顺序传参就可以了 pool.submit(func,'whw-%s'%i) # 阻塞 直到池中的任务都完成为止 # 关闭往里面提交数据的入口 # 所有任务执行完进程池才算借宿 # 效果:最后打印主 类似于join的功能 pool.shutdown(wait=True) print('主...')
效果:

(2)调用进程池对象的map方法:
# -*- coding:utf-8 -*- import os,time,random from concurrent.futures import ProcessPoolExecutor def func(name): print('name:%s,pid:%s'%(name,os.getpid())) time.sleep(random.random()) if __name__ == '__main__': pool = ProcessPoolExecutor(2) pool.map(func,range(1,6)) print('主...')
效果如下:
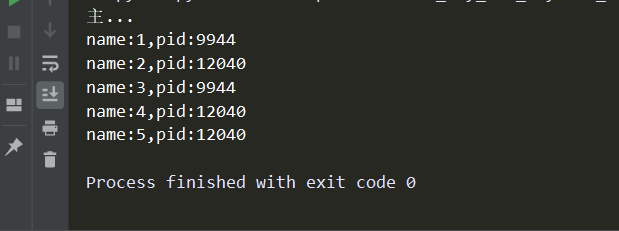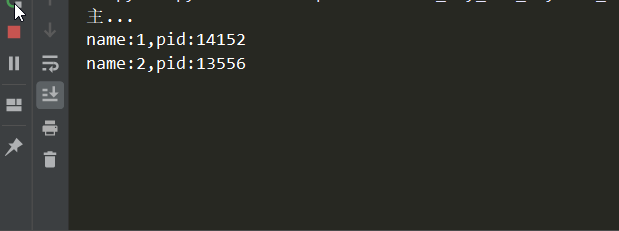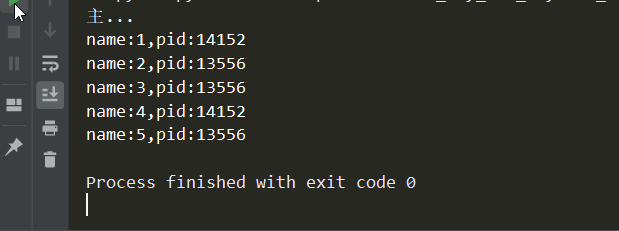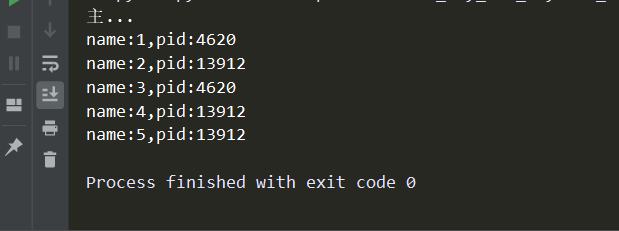
6-1:接收返回值
(1)普通方法
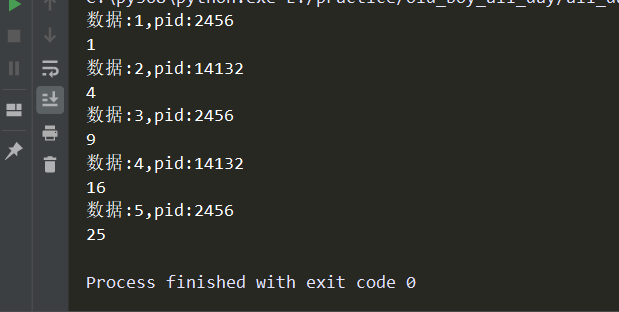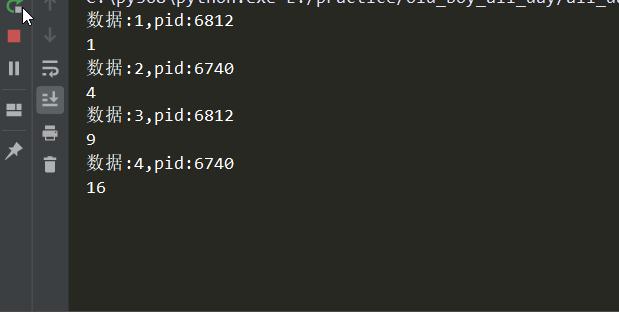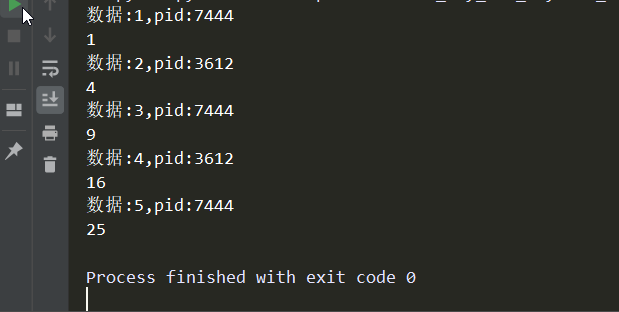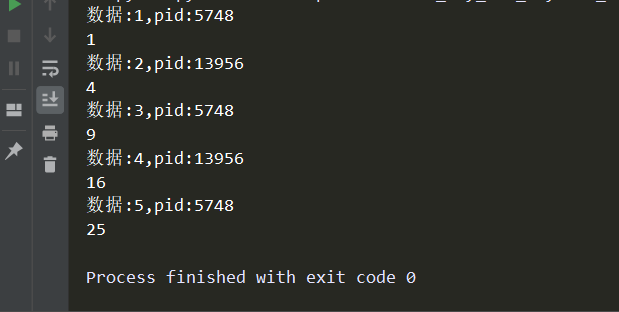
# -*- coding:utf-8 -*- import os,time from concurrent.futures import ProcessPoolExecutor def cal(i): time.sleep(0.3) print('数据:%s,pid:%s'%(i,os.getpid())) return i**2 if __name__ == '__main__': # 进程池对象 pool = ProcessPoolExecutor(2) # 接收返回值 ret_lis = [] for i in range(1,6): ret = pool.submit(cal,i) ret_lis.append(ret) # 取值 for i in ret_lis: print(i.result())
效果如下:
(2)对象的map方法:
# -*- coding:utf-8 -*- import os,time from concurrent.futures import ProcessPoolExecutor def cal(i): time.sleep(0.3) print('数据:%s,pid:%s'%(i,os.getpid())) return i**2 if __name__ == '__main__': # 进程池对象 pool = ProcessPoolExecutor(2) # 接收返回值 ret = pool.map(cal,range(1,6)) for i in ret: print(i)
效果如下:

我们可以看到,map方法的第一个参数为函数的内存地址,第二个为一个生成器,生成器的每个值当做参数赋值给了函数!
6-1:回调函数
'''
回调函数:
可以为进程/线程池内每个进程或者线程绑定一个函数,该函数在进程或线程的任务执行完毕后自动触发,并接收任务的返回值作为参数
——该函数称为回调函数
'''
***** 异步调用与回调机制
(1-1)同步调用:提交完任务后,就在原地等待任务执行完毕,拿到结果后再执行下一行代码——会导致程序串行执行
# -*- coding:utf-8 -*- import time import random from concurrent.futures import ThreadPoolExecutor def run(name): print('%s is running'%name) time.sleep(0.3) ret = random.randint(1,10) return {'name':name,'ret':ret} def over(dic): name = dic['name'] ret = dic['res'] print('name:%s,ret:%s'%(name,ret)) if __name__ == '__main__': pool = ThreadPoolExecutor(2) res1 = pool.submit(run,'whw1').result() print(res1) res2 = pool.submit(run,'whw2').result() print(res2) res3 = pool.submit(run,'whw3').result() print(res3)
效果如下:

(1-2)异步调用-回调函数:提交完任务后,不在原地等待任务执行完毕。
# -*- coding:utf-8 -*- import time,random from concurrent.futures import ThreadPoolExecutor def run(name): print('%s is running'%name) time.sleep(0.3) ret = random.randint(1,10) return {'name':name,'ret':ret} def over(arg): # 注意这里的arg得用result取值! dic = arg.result() name = dic['name'] ret = dic['ret'] print('name:%s,ret:%s'%(name,ret)) if __name__ == '__main__': # 创建池对象 pool = ThreadPoolExecutor(2) for i in range(1,6): ret = pool.submit(run,i) ret.add_done_callback(over) ''' 也可以这样写: res1 = pool.submit(run,'whw1').add_done_callback(over) res2 = pool.submit(run,'whw2').add_done_callback(over) res3 = pool.submit(run,'whw3').add_done_callback(over) ''' ''' #也可以这样写: ret_l = [] for i in range(1,6): ret = pool.submit(run, i) ret_l.append(ret) for r in ret_l: over(r) '''
效果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号