
线程 —— 基本概念、线程的基础操作(阻塞与延迟的理解)、多线程与多进程的效率差、数据共享问题、线程的其他方法
一个需要注意的点 —— CPU只管发指令,不管执行的顺序!

一:线程的概念
1、线程:轻型进程/轻量级进程
特点:
(1)、在同一个进程中的多个线程是可以共享一部分数据的!
(2)、线程的开启、销毁、切换都要比进程高效很多!
## 线程是进程中的一个单位
## 进程是计算机中最小的资源分配单位
## 线程是计算机中被CPU调度的最小单位
### 开启进程、关闭进程、切换进程都需要时间
### 你的电脑资源是有限的
### 开启过多的进程会导致PC崩溃
进程主要做:“数据隔离”
并发:同一时刻能够同时接收多个客户端的请求
2、这部分详见另外一篇:Python为什么不能实现“多个线程访问多核”
(1)多个进程是否可以利用多核/多CPU?##可以
(2)同一个进程的多个线程是否可以利用多核/多CPU?##可以——但Python中的多线程不能访问多个CPU其实是CPython解释器限制的——其他的Python解释器可以
————所以有人说python没有多线程~
消除GIL副作用的两种方案:
1.使用多进程,让多个核心都工作
2.使用其他语言编写的解释器,此时使用多线程,也能运行在多个核心上.

1、线程:轻型进程/轻量级进程
特点:
(1)、在同一个进程中的多个线程是可以共享一部分数据的!
(2)、线程的开启、销毁、切换都要比进程高效很多!
2、python中的多线程 ———— CPython解释器下的多线程不能访问多核!
## CPython解释器:有一个GIL锁(10:40分左右视频) ——
## 它是一个全局解释器锁
## 它导致了同一时刻只能有一个线程访问CPU
### Python中的多线程不能访问多个CPU其实是CPython解释器限制的(在数据安全面前效率不值一提!)
##——其他的Python解释器可以
### JPython与pypy解释器中的多线程是可以访问多核的!
3、利用多核——意味着多个CPU可以同时计算线程中的代码
## CPU负责计算
## IO操作 —— 不用CPU计算
## accept 负责从网络上读取数据
## open 调用操作系统的指令开启一个文件
## read
4、web框架:多进程对于web框架不重要,web框架都是多线程的,用不到多核!
二、线程的基础操作
#1、现在更推荐使用_thread模块(在Python2中叫thread模块)
#2、课上讲解的threading模块:
# 它的底层模块是thread,threading就是基于thread实现的。但是,越上层的模块“封装度”越好、功能越丰富。
#3.注意,先有的threading操作线程的模块(但是没有池的功能),后来才有的multiprocessing模块(实现了池的功能),后者完全模仿前者完成的。
#4.但是现在都用 concurrent.futures模块——来实现进程池与线程池!
2-1、开启线程的基本方法(函数方式、面向对象方式):
# 创建线程不需要在if __name__ == '__main__'下面执行:
# 在线程部分不需要通过import来为新的线程获取代码(开子进程需要),因为新的线程与之前的主线程共享同一段代码(全局变量也共享)。
# 不需要import也就意味着不存在在子线程中又重复一次创建线程的操作
# -*- coding:utf-8 -*- import os from threading import Thread def func(name): print('%s 开启,pid为:%s'%(name,os.getpid())) if __name__ == '__main__': t = Thread(target=func,args=('whw',)) t.start() print('主线程...',os.getpid())
结果为:
whw 开启,pid为:13904
主线程... 13904
********************************************
面向对象的方式
# -*- coding:utf-8 -*- import os import time from threading import Thread class MyThread(Thread): def __init__(self,name): super().__init__() self.name = name # 必须叫run def run(self): # # 阻塞0.5秒的话 会在主线程后打印下面内容 # time.sleep(0.5) print('%s is running...pid:%s'%(self.name,os.getpid())) time.sleep(1) print('%s is done...'%self.name) if __name__ == '__main__': t = MyThread('whw') # 注意是start方法 t.start() print('主线程.....')
效果:
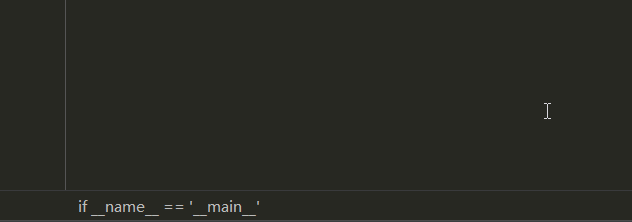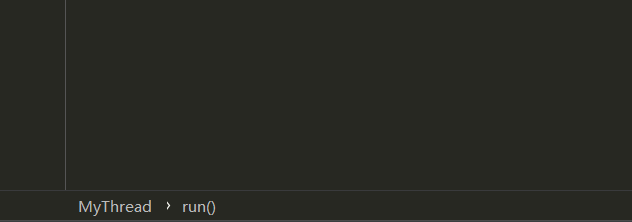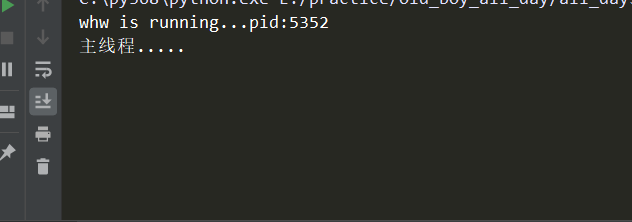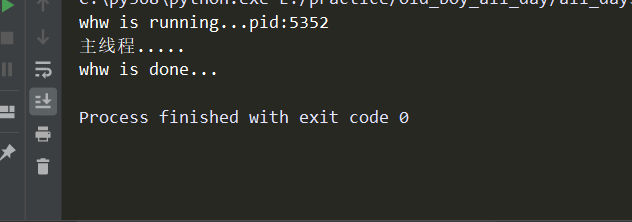
2-2、并发效果的多线程
# -*- coding:utf-8 -*- import time from threading import Thread def func(name): time.sleep(1) print('%s 开启了!'%name) if __name__ == '__main__': for i in range(1,6): t = Thread(target=func,args=('t-%s'%i,)) t.start()
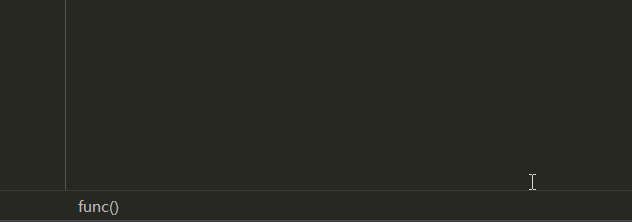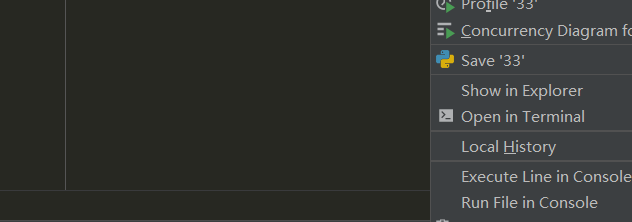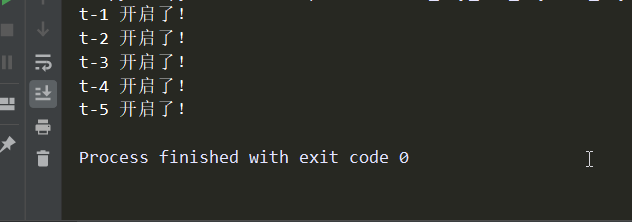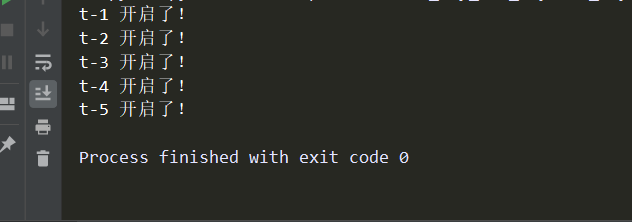
加上sleep的执行效果如下:

可以看到,程序执行的1秒后,所有线程同时都开启了!而且执行的顺序是不定的!因为我们在func里sleep了1秒,也就是程序“阻塞”了1秒,这样的话就不能确定谁先回到“就绪队列”中去(阻塞的话所有的子线程先去阻塞队列,当阻塞结束后它们都会再次进入就绪队列而后才会运行,而这个过程导致顺序乱了!),
所以执行的顺序肯定会不一样!如果去掉sleep 1秒,这样纯切换的话,程序在计算上是没问题的,因此会看起来是顺序执行的,
不加sleep的执行效果如下:
2-3、多线程与多进程的效率差
(1)启动100个子线程
# -*- coding:utf-8 -*- import time from threading import Thread def func(a): a += 1 if __name__ == '__main__': start = time.time() t_lis = [] for i in range(100): t = Thread(target=func,args=(1,)) t_lis.append(t) t.start() # 等待所有子线程结束 for i in t_lis: i.join() print('运行时间:%s'%(time.time()-start))
结果:
运行时间:0.01590561866760254
(2)启动100个子进程
# -*- coding:utf-8 -*- import time from multiprocessing import Process def func(a): a += 1 if __name__ == '__main__': start = time.time() p_lis = [] for i in range(100): p = Process(target=func,args=(1,)) p_lis.append(p) p.start() # 等待所有子进程运行完 for i in p_lis: i.join() print('运行时间:%s'%(time.time()-start))
结果为:
运行时间:3.272214651107788
我们可以看到:多线程的效率要远远高于多进程!
2-4、一个进程内的线程之间数据共享(主线程与子线程数据是共享的)
(1)默认情况下主线程先于子线程启动
# -*- coding:utf-8 -*- import time from threading import Thread def func(name): time.sleep(1) global num num += 1 print('%s:%s'%(name,num)) if __name__ == '__main__': num = 0 name_lis = ['whw','www','wah'] for i in name_lis: t = Thread(target=func,args=(i,)) t.start() # 主线程 print('主线程:',num)
执行效果如下:
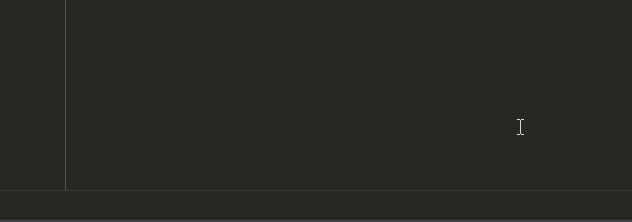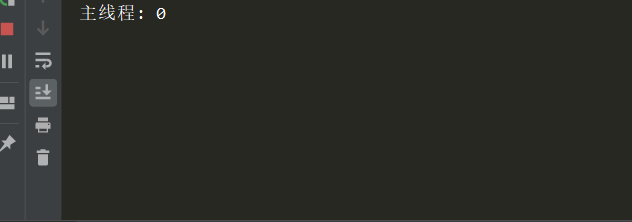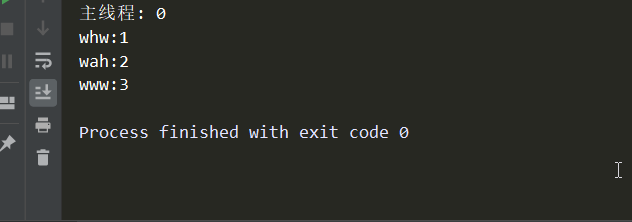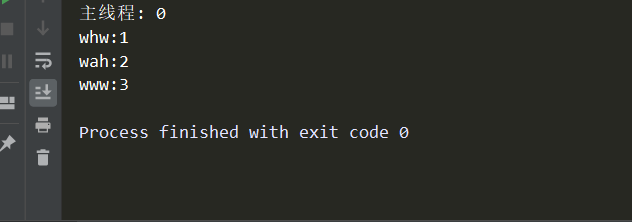
可以看到:由于所有的子线程都sleep了1秒,因此主线程先运行,拿到了num的第一个值0,由于程序阻塞了1秒钟,就绪队列中的顺序是不定的,因此打印出的name是乱序的;最重要的是,可以看出来,全局的num在线程之间是共享的!
也就是说:线程之间共享的是全局的数据!
(2)等待子线程执行完再执行主线程
# -*- coding:utf-8 -*- import time from threading import Thread def func(name): time.sleep(1) global num num += 1 print('%s:%s'%(name,num)) if __name__ == '__main__': num = 0 name_lis = ['whw','www','wah'] t_lis = [] for i in name_lis: t = Thread(target=func,args=(i,)) t_lis.append(t) t.start() # 等待所有子线程执行完 for i in t_lis: i.join() # 在执行主线程 给num自加1 num += 1 print('主线程:',num)
运行效果如下:
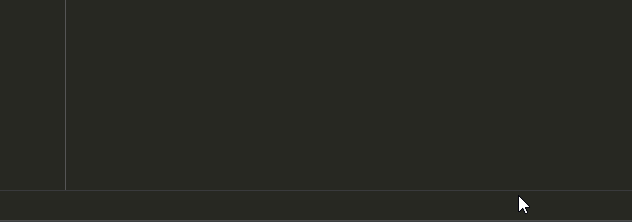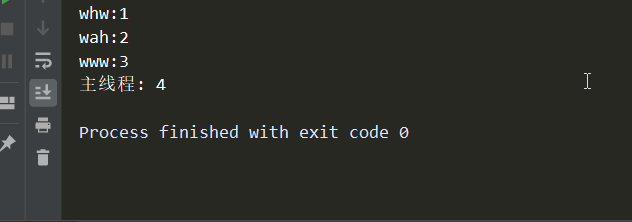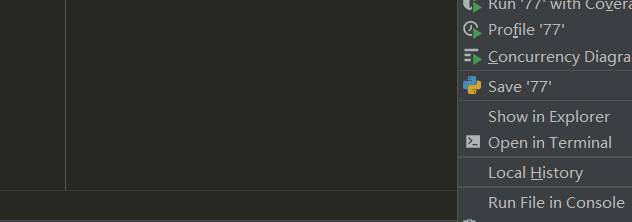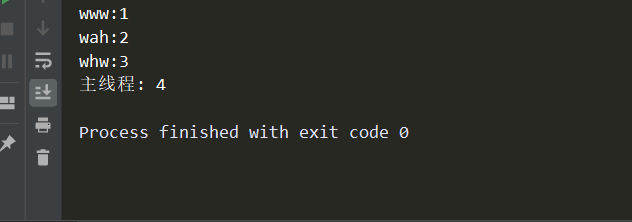
可以看到:程序阻塞了1秒后,name的顺序又乱了,本程序在主线程多加了一个给num自增1的过程,可以明显看到:join其实阻塞的是主线程,使用join方法的t对象仍然正常运行,而且“主线程必须等待这些被join的t结束后才能执行”
三、线程的其他方法
3-1、当前的线程对象:current_thread() currentThread = current_thread
(1)普通版本 —— 一个子线程与一个主线程
# -*- coding:utf-8 -*- import os from threading import Thread,current_thread def func(): t1 = current_thread() print('子线程名:%s,线程标识:%s,线程id:%s'%(t1.name,t1.ident,os.getpid())) if __name__ == '__main__': # 开启一个子线程 Thread(target=func).start() # 主线程 t2 = current_thread() print('主线程名:%s,线程标识:%s,线程id:%s' % (t2.name, t2.ident, os.getpid()))
结果为:
子线程名:Thread-1,线程标识:8036,线程id:14388
主线程名:MainThread,线程标识:7196,线程id:14388
注意,这里子线程先打印出来,是因为我们没有像上面的程序那样sleep 1秒,程序没有阻塞,子线程没有进入阻塞队列而是直接运行的,所以程序会看起来“按照顺序执行”!!!
(2-1)我们把main下面的Thread对象打印出来看看(不设置阻塞):

(2-2)人为设置阻塞 运行的顺序会变化


# -*- coding:utf-8 -*- import os import time from threading import Thread,current_thread def func(): time.sleep(1) t1 = current_thread() print('子线程名:%s,线程标识:%s,线程id:%s'%(t1.name,t1.ident,os.getpid())) if __name__ == '__main__': # 开启一个子线程 t_obj = Thread(target=func) t_obj.start() print('t_obj:',t_obj) print('----------------------') # 主线程 t2 = current_thread() print('主线程名:%s,线程标识:%s,线程id:%s' % (t2.name, t2.ident, os.getpid()))

结论:t_obj与t1其实是一个对象!
关于这个结论有一个很经典的题:使用多线程的方式将列表lis=[1,2,3,4,5]中的每个值都计算器平方,并且将结果按照顺序返回:
代码:
# -*- coding:utf-8 -*- import time import random from threading import Thread,current_thread def func(i): # 如果设置在这里 相当于子线程运行之前程序阻塞 # 子线程会先进入阻塞队列,阻塞结束后再进入等待队列的顺序就乱了,因此结果会是乱的 # time.sleep(random.random()) t = current_thread() # t.ident是唯一的,作为键 dic[t.ident] = i**2 # 子线程运行完了 模拟下延迟 不影响结果 time.sleep(random.random()) if __name__ == '__main__': dic = {} lis = [1,2,3,4,5] tt_lis = [] for i in lis: tt = Thread(target=func,args=(i,)) tt_lis.append(tt) # 注意必须start! tt.start() print(dic) ## 等待所有子线程结束 for i in tt_lis: i.join() print(dic[i.ident]) #
结果:
{4380: 1, 3968: 4, 7252: 9, 12132: 16, 14972: 25}
1
4
9
16
25
说明:

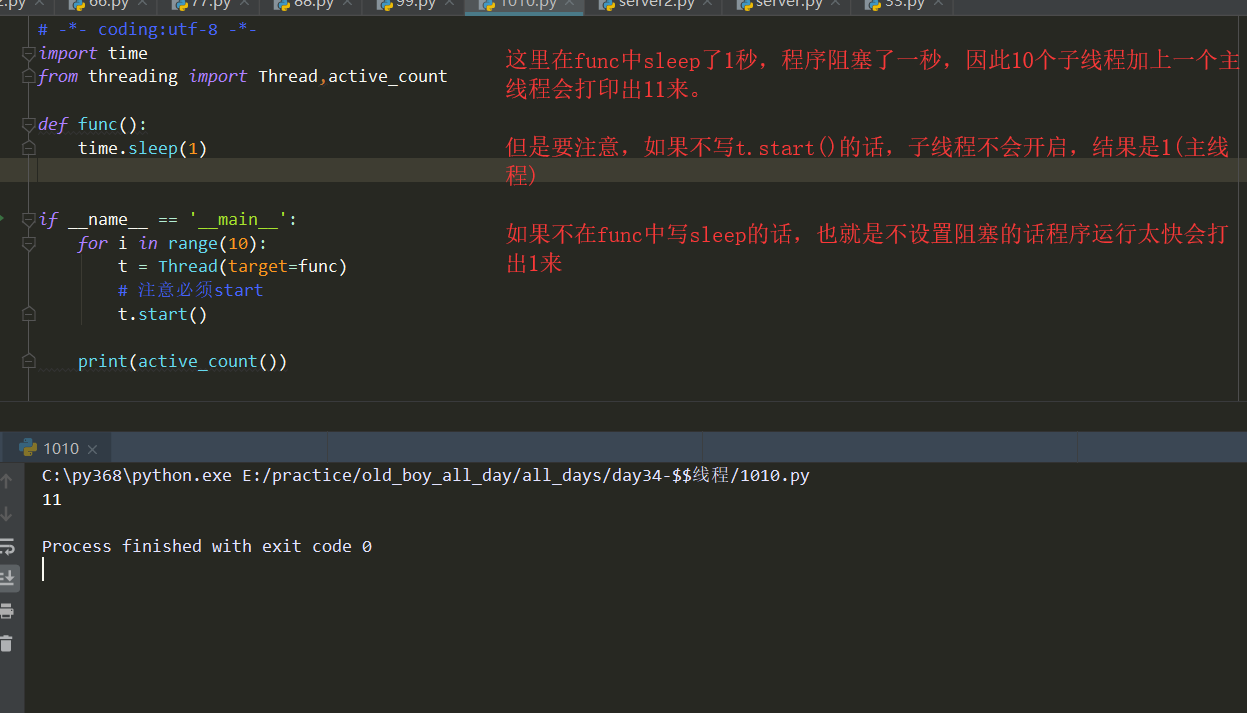
3-2、当前程序存活的线程对象:active_count() activeCount = active_count

 浙公网安备 33010602011771号
浙公网安备 33010602011771号